
BERT — система машинного обучения с открытым исходным кодом для обработки естественного языка (NLP). В одной из статей «Системный Блокъ» уже рассказывал о ее особенностях. BERT разработана для того, чтобы помочь компьютерам понять смысл неоднозначных формулировок в тексте, используя окружающий текст для определения контекста.
Для качественного обучения такой языковой модели необходим большой корпус текстов. Если же для языка невозможно собрать достаточный по объему корпус, то обучение языковой модели становится проблематичным. Такие языки называются малоресурсными.
Но если при обучении модели использовать не только тексты на малоресурсном языке, но и тексты на распространенных языках (например, английском, французском), то качество модели на малоресурсном языке будет выше, чем у модели, обученной только на нём. Модели, использующие данный подход, называются мультиязычными (multilingual), и они пользуются большой популярностью для решения задач на малоресурсных языках.
В статье «Multilingual BERT has an accent: Evaluating English influences on fluency in multilingual models» [1] авторы описывают явление, которое, тем не менее, часто ухудшает работу мультиязычных моделей — грамматические структуры из высокоресурсных языков как бы перетекают в малоресурсные. Подобно людям, не являющимся носителями языка, мультиязычные модели склонны использовать структуры родного (превалирующего) языка, нежели структуры, свойственные иностранному (малоресурсному) языку.
О, Вы из Англии?
В эксперименте, который разбирается в статье, исследователи анализируют корпус, в котором преобладает английский язык. Также в нем присутствуют греческий и испанский, выбранные в качестве малоресурсных языков (строго говоря, это не совсем корректно, поскольку для этих языков существует достаточно данных для обучения отдельной модели). И в греческом и в испанском один и тот же смысл можно выразить двумя разными грамматическими структурами, одна из которых похожа на структуру, характерную для английского языка, а другая присутствует только в этом языке и отлична от английской
На изображении ниже авторы демонстрируют примеры таких конструкций. Для каждого предложения приведен подстрочный перевод на английский: слева — конструкции, специфичные английскому, справа — характерные только для рассматриваемого языка. Авторы отмечают, что для примера специально подобрали предложения значительно короче тех, что в среднем встречаются в выборке.
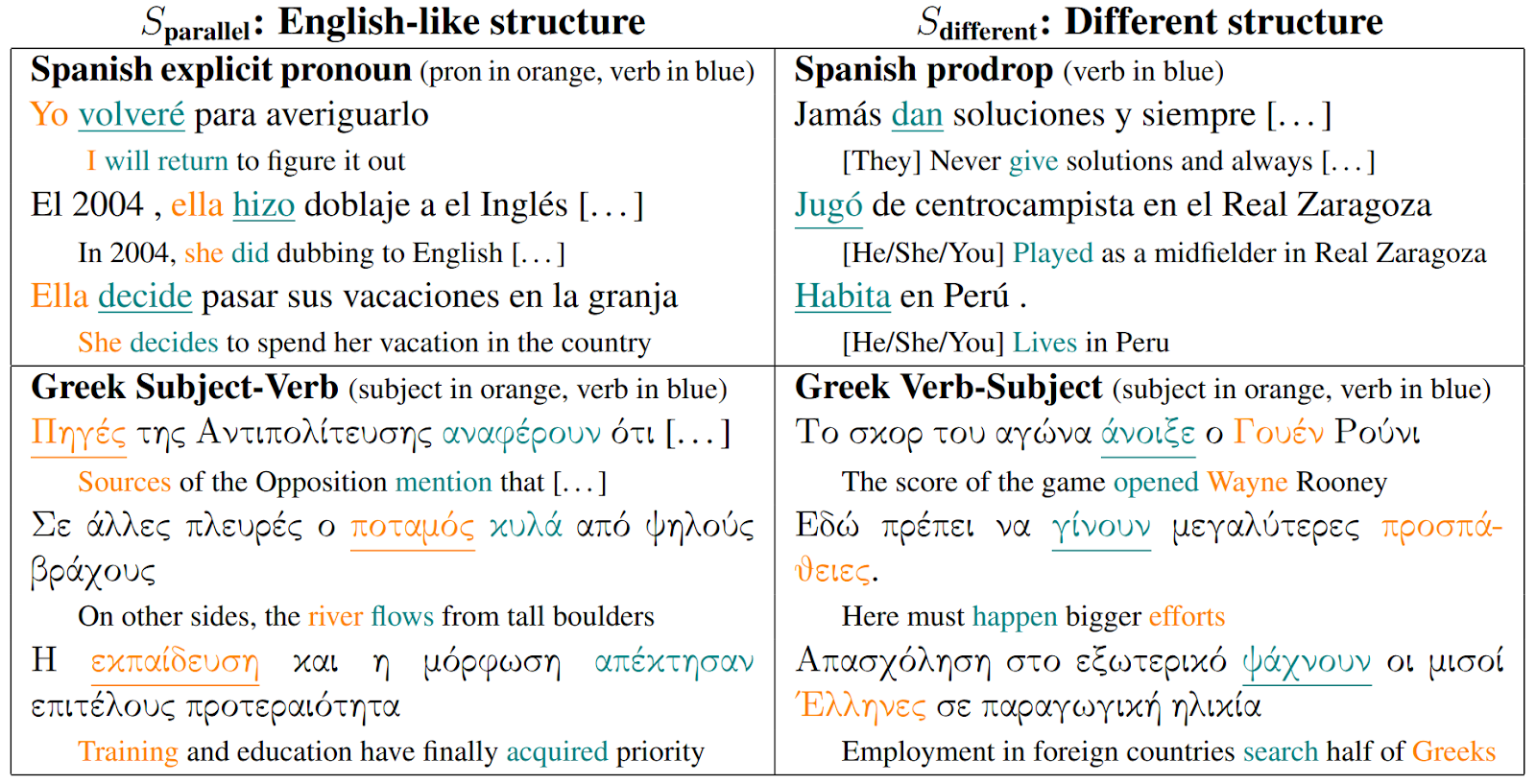
В рамках исследования авторы статьи замеряли, насколько часто мультиязычные модели синтезируют в текстах те или иные структуры первого и второго типа. Обнаружилось, что такие модели предпочитают использовать более «английскую» конструкцию, даже если с точки зрения рассматриваемого языка это не совсем благозвучно. Модели, обученные на одном языке, таких ошибок не совершают, и чаще подбирают грамматическую конструкцию так же, как ее подобрал бы носитель языка.
Как исследователи обнаружили акцент
Сначала авторы нашли в греческим и испанском конструкции, которые могут быть выражены двумя грамматическими структурами, и сформировали из них выборки. Выборки не связаны друг с другом, то есть это не перефразированные предложения. Авторы отмечают, что предложения взяты из настоящих источников, потому что в этой задаче важны нюансы использования языка в естественной речи.
Для каждой конструкции было выбрано одно слово, которое характеризует ее тип наилучшим образом. В примере ниже выделены те слова, которые точно встретятся в тексте, если будет использована конструкция такого типа — и точно не встретятся, если модель сделает выбор в пользу другой конструкции. Такой специфический способ обнаружения конструкции в тексте обусловлен архитектурой используемых моделей: модель не может оценить правдоподобие целого предложения, но может оценить правдоподобие (вероятность употребления) конкретного слова в определённом месте в предложении.
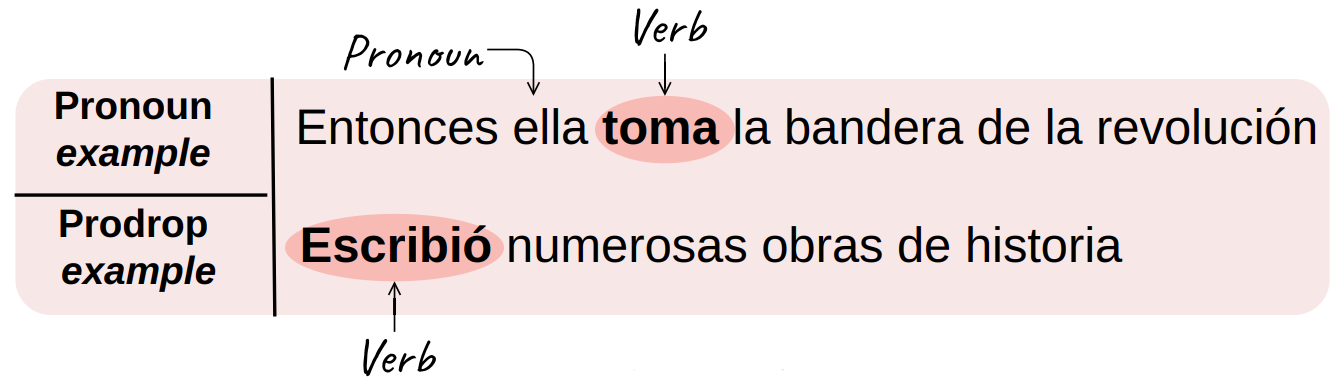
После этого авторы использовали две модели: одну мультиязычную, а другую обученную на одном исследуемом языке, и сравнили вероятности употребления в тексте того или иного слова, характерного для конструкций. Обнаружилось, что различия между предпочтениями моделей в их выборе статистически значимо: мультиязычная модель тяготеет к использованию структур, похожих на английские, в то время как модель, обученная на одном языке, чаще использует структуры, специфические для этого языка.
Как акцент можно «исправить»
На проблему, описываемую в статье, обращали внимание и раньше. Например, были предложения обучать мультиязычные модели так, чтобы в данных для их обучения были только грамматически близкие друг к другу языки — или, как минимум, чтобы грамматически отличный от остальных язык не доминировал в выборке [2]. Также можно дообучать модель под конкретный язык, для которого она будет использоваться, то есть брать готовую мультиязычную модель и обучать ее дополнительно с помощью выборки на интересующем языке. Конечно, можно просто увеличить обучающую выборку — и хотя этот метод нельзя назвать изящным, он также улучшит качество модели.
Источники
[1] Papadimitriou, Isabel, Kezia Lopez, and Dan Jurafsky. «Multilingual BERT has an accent: Evaluating English influences on fluency in multilingual models.» arXiv preprint arXiv:2210.05619 (2022).
[2] Ogueji, Kelechi, Yuxin Zhu, and Jimmy Lin. «Small data? no problem! exploring the viability of pretrained multilingual language models for low-resourced languages.» Proceedings of the 1st Workshop on Multilingual Representation Learning. 2021.



