BERT или Bidirectional Encoder Representations from Transformers — это нейросеть от Google, показавшая несколько лучших результатов в решении многих NLP-задач: от ответов на вопросы до машинного перевода. Код модели выложен в открытый доступ, также есть несколько версий BERT, весь список которых можно найти на официальной странице.
Модели BERT были уже предобучены на больших наборах данных (причем не только на английском), и разработчики могут скачать и встроить в свои проекты по обработке естественного языка уже готовый инструмент, не тратя время на обучение нейросети с нуля. Саму нейросеть можно запустить как на локальном компьютере, так и на бесплатном серверном GPU на Google Colab.
Что такое эмбеддинги и бенчмарки
Языковая модель работает с текстом, а компьютер «понимает» только числа. Чтобы подать компьютеру числа вместо текста, люди придумали делить текст на токены («символы» по-английски) и кодировать их. Токеном может быть буква, слог или целое слово (обычно берут самые частотные слова, буквы и «значимые» слоги ing, ed, un и т.д). То, как закодирован токен, называют «эмбеддингом», потому что его как бы «укладывают» (to embed — вставлять, встраивать) в числовое пространство. Для получения эмбеддинга тоже нужны хитрые алгоритмы вроде GLoVe, ELMo или word2vec, просто пронумеровать слова по алфавиту не выйдет (хотя можно сделать и это).
Таким образом, эмбеддинг токена — числовое обозначение слова, слога или буквы.
Языковая модель принимает на вход эмбеддинги токенов и выдает результат в зависимости от задачи. Существует стандартный набор задач, который нужно выполнить на стандартном наборе данных, чтобы доказать, что ваша нейросеть круто справляется с пониманием текста. Пример задачи — выдать 1, если в двух разных вопросах на Quora спрашивают одно и то же, выдать 0 — если нет. Стандартные задачи называются в NLP бенчмарками («ориентир», «отметка» по-английски). BERT тестировали на наборах бенчмарков GLUE — «Оценка общего понимания языка», SQuAD и SWAG — мы расскажем о них подробнее. Задача на определение одинаковых по смыслу вопросов с Quora как раз входит в набор из 9 задач GLUE.
Чтобы нейросеть выполняла полезное дело, сначала нужно ее обучить. Часто «обучить» — значит дать нейросети фальшивое задание, которое не пригодится в реальной жизни, но на нем удобно заполнить и скорректировать нужные «матрицы весов». Ради получения весов ведется все обучение.
Веса выглядят как числа, влияющие на важность данных для системы, в каком-то смысле ее «память». На веса умножаются те или иные кусочки обработанных данных: если вес нейрона велик, значит, его группа пикселей важна для распознавания котика.
Обычный код написан раз и навсегда (и только другой человек может изменить его), а нейросеть с каждой попыткой выполнить задачу немного адаптирует часть своего кода, конкретнее — корректирует веса из матриц. Если веса подобраны хорошо, нейросеть расставит приоритеты и «научится, куда смотреть», чтобы распознать на пиксельной картинке двойку или девятку.
Это важно: нейросеть не может придумать новый алгоритм своей работы, но может «подогнать» числа в алгоритме, чтобы задача выполнялась с минимальным промахом. При этом ей вообще не важно, что это за задача с точки зрения человека. А выученные на тренировке числа потом можно будет использовать в реальных задачах.
Обучение с учителем и без учителя, самообучение
В зависимости от конечной цели используют либо машинное обучение с учителем (supervised learning), либо без него (unsupervised learning).
Чаще всего используют именно supervised learning, так как этот подход гораздо легче. Обучение с учителем предполагает, что машина учится по выбранным (чаще всего людьми) данным. Часть данных, которые получает машина в процессе, уже помечены как принадлежащие к определенному классу. Эта принадлежность называется «лейбл» или «ярлык» данных. «Ярлык» запоминается, и, уже исходя из него, машина обучается дальнейшему прогнозу ярлыков для новых данных.
Именно из-за маркированных данных метод носит и второе название — обучение по размеченным данным. Подход чаще всего используют для задач по типу классификации и регрессии.
Обучение без учителя или unsupervised learning означает, что машина сама должна понять зависимость, закономерность и группировку данных, среди которых нет помеченных как «правильный ответ». Иными словами, данные не маркированы вручную, отсюда и понятие обучения «без учителя». Чаще всего результаты такого обучения непредсказуемы, но этот подход позволяет работать над решением более сложных задач, таких, как кластеризация и поиск ассоциативных правил.
Помимо обучения с учителем и без него часто для решения NLP задач в машинном обучении используют метод self-supervised learning (самообучение). Такой подход является чем-то промежуточным между двумя описанными ранее. В самообучении используются полностью неразмеченные произвольные данные, что отличает этот метод от обучения с учителем. Часть информации от сети скрыта. Она сама должна предсказать скрытую часть, используя все доступные ей данные.
Этот подход в машинном обучении используется для представления слов в знакомом многим алгоритме word2vec. Берется любой неразмеченный корпус с текстами, и на его основе создается задача с метками. К примеру, предсказание слова по рядом стоящим с ним другим словам. На выходе получаем векторные представления слов, которые можно использовать уже дальше, для решения других, более сложных задач.
Предобучение и дообучение нейросети
В сложных нейросетях обучение разбивается на две части — «предобучение» и «дообучение» («тонкая настройка», fine-tuning). Это как бакалавриат и магистратура для нейросети — на первом этапе надо потратить много ресурсов и времени, чтобы дать какие-то «общие знания», на втором можно тренироваться решать конкретную задачу.
Предобучение — это фундаментально и дорого. Нужно много разных данных, матрицы весов случайные или вовсе пустые, их нужно заполнить чем-то осмысленным. «Дообучить» (или «тонко настроить) нейросеть проще. Популярный и простой метод — обнулить финальный слой весов и натренировать нейросеть на новом, меньшем наборе данных, заставив ее выполнять новую задачу (не ту, что брали на предобучение).
В случае с BERT это было так: сначала модель долго учили угадывать, что за слово пропущено в предложении и следуют ли эти два предложения друг за другом, а потом дали новые данные, новый, пустой слой нейронов и попросили понять, какие вопросы с Quora — про одно и то же. Процедуру дообучения меняют в зависимости от задачи и типа нейросети, выше описана только очень общая идея.
Чем BERT отличается от предшественников
Новшество BERTа — в основном в способе предобучения. Более ранние архитектуры, чтобы обучиться, выполняли задачу генерации текста — то есть предсказывали, какое слово вероятнее всего будет стоять следующим, учитывая все слова до него. На решение нейросети влияли только слова слева (так работает, например, Трансформер от OpenAI), такие нейросети называются однонаправленными. Человек так не делает, мы смотрим обычно на все предложение разом.
Чтобы решить проблему, придумали двунаправленные нейросети. Вкратце — две одинаковые нейросети работают параллельно, одна предсказывает слова слева направо, другая — справа налево. Потом результат обеих сетей просто «склеивается». Эта идея лежит в основе модели ELMo. Двунаправленная нейросеть на ряде задач справляется лучше, чем однонаправленная, но это тоже не совсем то, что хочется видеть: у нас как бы получается две «одноглазые» модели, каждая из которых не знает, что делает другая.
Поэтому BERT предобучается на «маскированной языковой модели». Ее суть в том, что нужно предсказать слово не в конце предложения, а где-то посередине: не «человек пошел в магазин за ???», а «человек пошел в ??? за молоком». Маскированной модель называется потому, что искомый токен заменяется токеном [MASK].
Такой подход к обучению позволил сделать то, чего нельзя было сделать в Трансформере: подать на вход (и учесть) все части фразы, а не только слова слева или справа. Потому что открыть все предложение в однонаправленном Трансформере — значит дать готовый ответ системе, которая пытается угадать, что было дальше: так она ничему не научится. (О том, как работают трансформеры, мы писали здесь). С новым методом обучения достигается «глубокая двунаправленность», когда модель на самом деле смотрит в обе стороны, а не склеивает отдельные представления о контексте слева и справа.
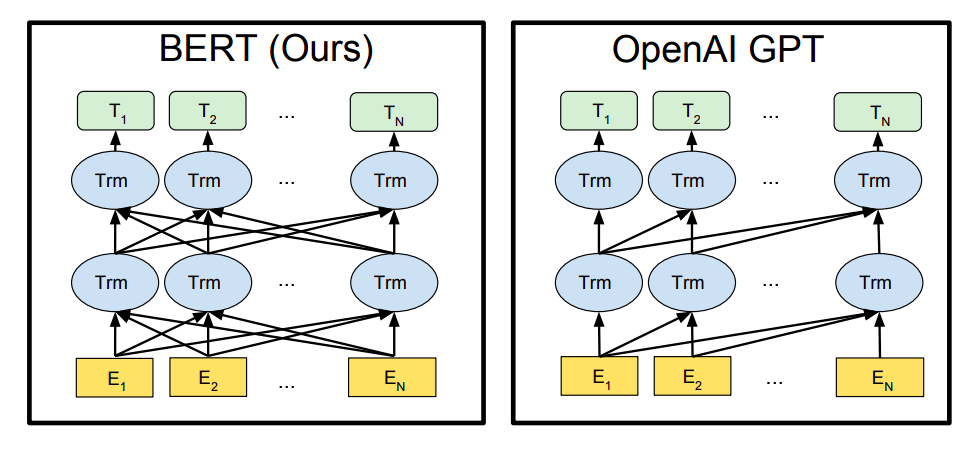
«Под капотом» у BERT — механизм внимания, нарочно сделанный похожим на свой аналог в Трансформере GPT, чтобы было проще сравнивать результаты. Архитектуры похожи: если сильно упрощать, то BERT — это такой «трансформер», у которого увеличили число и размеры слоев, убрали декодирующую часть и научили смотреть на контекст в обе стороны. Внимание простого трансформера всегда направлено на токены слева от данного (слова справа заменяются особым словом [MASK], что обнуляет вес внимания). BERT же «маскирует» только то, что нужно предсказать, значит, внимание направлено на все токены входной последовательности — и слева, и справа.
Механизм внимания умеет подбирать множители, увеличивающие вес значимых слов в контексте. Это сильно повышает точность решений нейросети. Ранее мы рассказывали про работу этого механизма.
Предобучение BERT в деталях
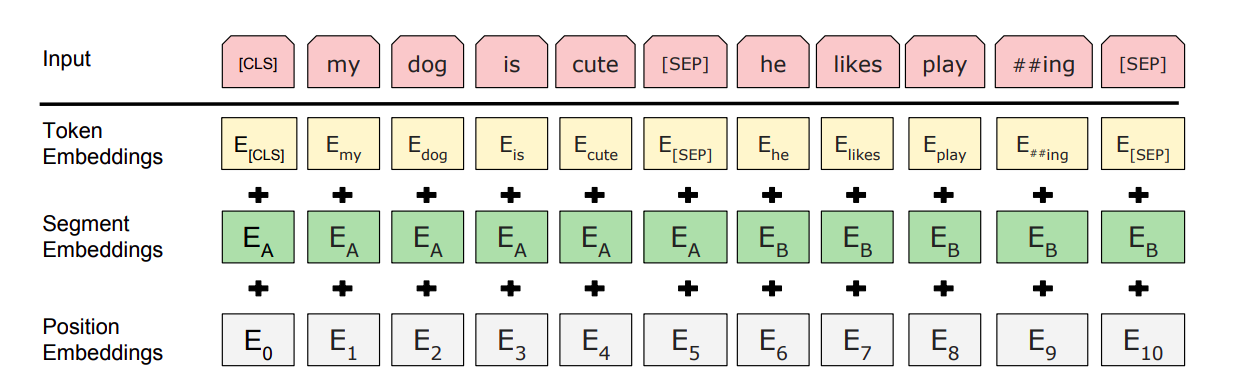
Кроме угадывания слова в середине предложения, во время предобучения BERT дополнительно должен «сказать», следует ли второе предложение тренировочного примера за первым. Каждый тренировочный пример состоит из двух предложений с пропущенными словами, а задача, которая ставится BERT — угадать, какие слова пропущены (выдать их числовой код) и сказать, подходит ли второе предложение к первому. Для этого к начальному эмбеддингу слова прибавляются сегментный и позиционный эмбеддинги.
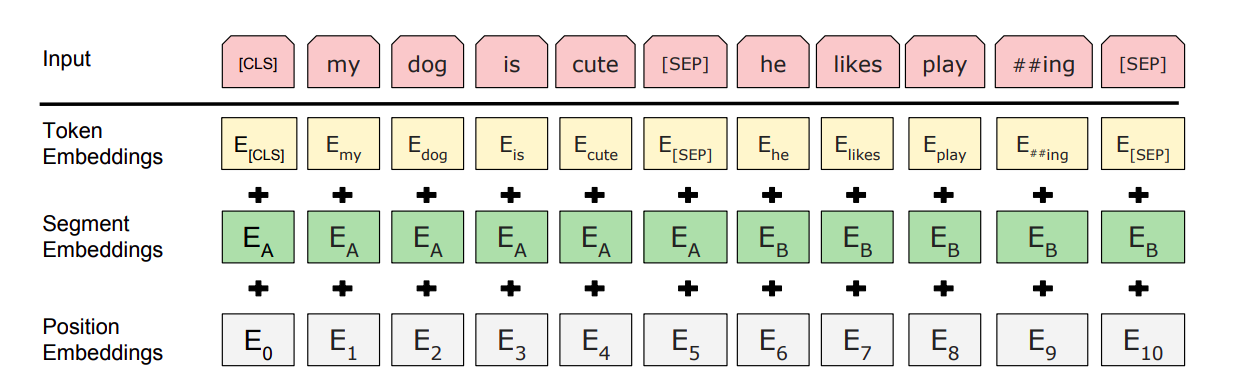
Желтый начальный эмбеддинг слова — число, ID токена из системы WordPiece. В словаре WordPiece, который выбрали создатели BERTa, 30 тысяч токенов. Среди них — буквы, самые популярные слова английского и отдельные слоги.
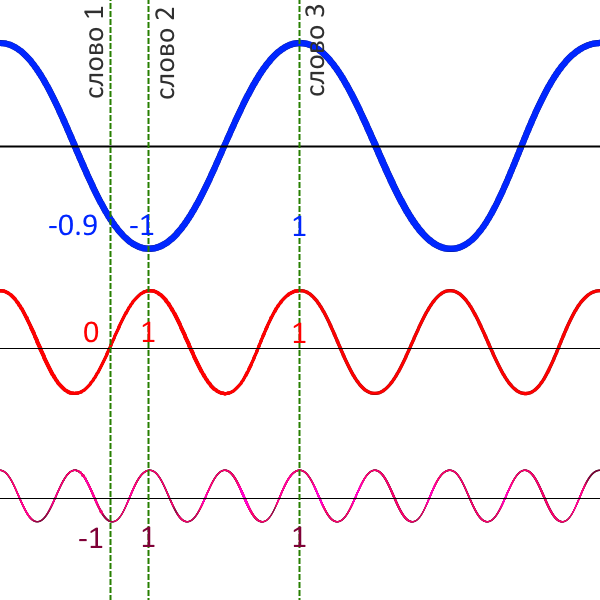
К каждому начальному эмбеддингу прибавляется еще число, означающее, что слово стоит в первом или втором предложении (segment embedding), а также третье число — позиционный эмбеддинг, показывающий, насколько далеко два слова стоят друг от друга. Последнее нужно потому, что трансформер (лежащий в основе BERT) принимает весь тренировочный пример целиком и работает со словами параллельно. Для модели нет «прошлого контекста». Он бывает в рекуррентной нейросети, где следующий шаг нельзя сделать без предыдущего, (про рекуррентные нейросети мы писали здесь), но трансформер — не рекуррентная архитектура. BERT нужен позиционный вектор — набор из «быстрых» и «медленных» синусоид, меняющих свое значение с каждым токеном. Если у двух слов разные значения быстрых графиков, но одинаковые — медленных, значит, они рядом. Если разные значения у медленных графиков, значит, слова стоят далеко друг от друга.
Перед предложениями стоит токен [CLS] — «классифицирующий токен»: предсказывая его, нейросеть угадывает, связаны ли между собой предложения из примера (то есть определяет их в класс «связанных» или «не связанных»). Сами предложения разделяются токеном [SEP], и внутри них некоторые слова заменяются токеном [MASK] — нейросеть должна предсказать самое вероятное слово на этом месте.
Маскированная языковая модель — компромисс: она не должна маскировать слишком много слов (если всё замаскировать, не останется контекста, на котором можно учиться) или слишком мало (тогда нужно показывать слишком много тренировочных примеров). Обычно решают заменять 15% слов «маской», эти слова выбираются случайно.
Важно: задача предобучения — это не задача из реального мира. Настоящая задача решается на дообучении нейросети, и в реальности не существует слова [MASK]. Чтобы модель не искала всюду только его, из всех выбранных на замену слов действительно маскируют (меняют на [MASK]) 80%, еще 10% слов меняют на случайное слово и 10% оставляют без изменений.
Как работает дообучение BERT
Идея файнтьюнинга, или тонкой настройки, или дообучения нейросети строится на том, что «базовые» знания (то есть матрицы весов), полученные на решении общих задач, помогают лучше решать новые, более узкие задания. Этот принцип — трансферное обучение — сильно продвинул NLP: о том, как к нему пришли и почему он должен работать, Системный Блокъ расскажет в отдельной статье.
Для дообучения (файнтьюнинга) в BERT не нужно стирать «часть памяти» модели. Вместо этого «поверх» модели добавляют новый слой нейронов. Его матрицы весов заполнены случайными числами, и нужно настроить их так, чтобы на новой задаче ошибка была минимальной. При этом все предыдущие слои уже натренированы на учебной задаче.
Новые тренировочные данные подаются в старом формате: это возможно благодаря гибкости трансформерной архитектуры.
Формат данных для предобучения, напомним — два предложения с пропущенными словами, их нужно восстановить. Еще надо догадаться, связано ли второе предложение с первым, для этого BERT предсказывает значение служебного токена [CLS].
Наступает этап дообучения. Простой пример новой задачи — понять, как связаны два предложения: противоречат друг другу, подтверждают или нейтральны (это тоже бенчмарк, он называется MNLI).
Новый слой нейронов имеет тот же формат, что старые: на нем есть токен C (классифицирующий) — предсказывая его, модель предсказывает, как связаны между собой предложения (определяет их в класс противоречащих, взаимно подтверждающих или нейтральных). Если сильно упростить, нейросеть как бы смотрит на свое предсказание о том, следуют ли эти два предложения друг за другом (о нем говорит токен [CLS] с этапа предобучения) и на эмбеддинги слов. Вся эта информация подсказывает, как нужно классифицировать предложения в новой задаче.
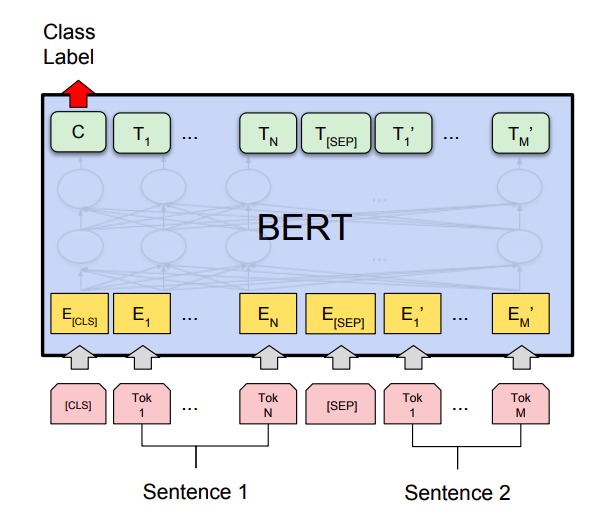
Предсказанием токена С решаются задачи классификации пар предложений, на которых проверяли BERT. Задачи бывают разными: QQP — задача на определение одинаковых по смыслу вопросов с Quora (вопросы классифицируются как «одинаковые» и «не одинаковые»). QNLI — задача, где модель должна правильно ответить, содержит ли пара предложений вопрос и подходящий к нему ответ (классы «содержит» — «не содержит»). Задача SWAG — это выбор логически подходящего продолжения к заданной фразе (предлагается четыре варианта).
В каждом случае формат новых данных подстраивают под формат данных предобучения. Например, в SWAG конструируется четыре входных предложения, каждое из которых состоит из заданной начальной фразы и одного из четырех продолжений. Задача BERT сводится к предсказанию токена классификации С: тот тренировочный пример, где его значение максимально, выбирается как пара логически связанных фраз. В свою очередь С предсказывается на основе токена CLS, который модель научилась предсказывать на предобучении.
Бывают задачи, когда нужно не классифицировать два предложения и связь между ними, а как-то классифицировать одно предложение.
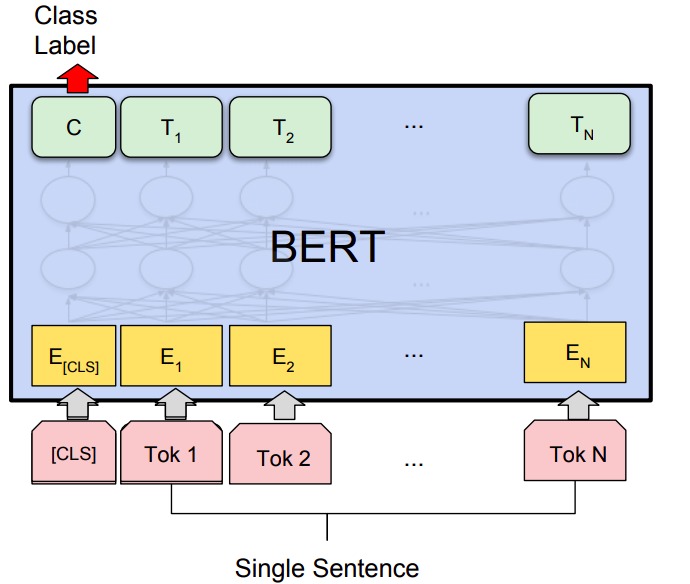
Так работает задача SST-2: по заданному предложению из рецензий к фильмам нужно определить его эмоциональную окраску. Или задача CoLA, где нужно угадать, является ли данное предложение «лингвистически приемлемой» английской фразой.
Бывают задачи, решаемые на уровне отдельных токенов: в них нужно предсказать не токен классификации предложения, а, например, токен начала и конца ответа на заданный вопрос. Так работает задача SQuAD, в которой дан вопрос и абзац текста, где предположительно может быть ответ на вопрос. Задача нейросети — определить, на каком токене начинается и заканчивается конкретный ответ.
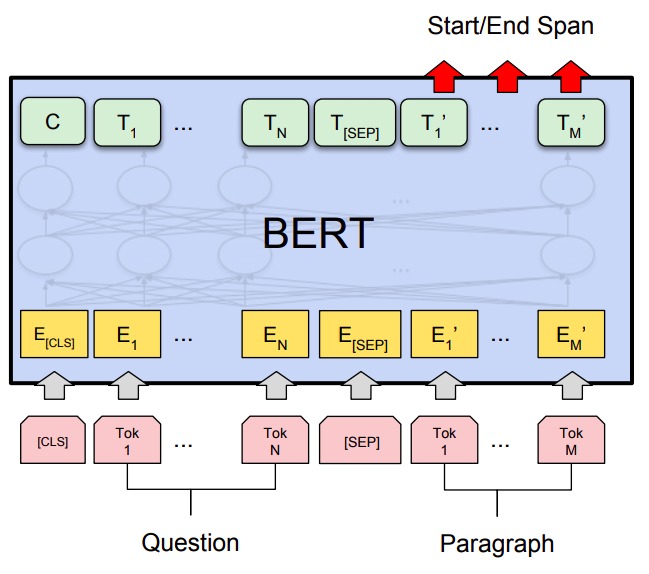
Четвертый и последний тип задач — задачи классификации токенов в отдельном предложении. Так работает CoNLL-2003 NER: в задаче каждое слово нужно классифицировать как имя собственное или имя нарицательное (другими словами, извлечь именованные сущности).
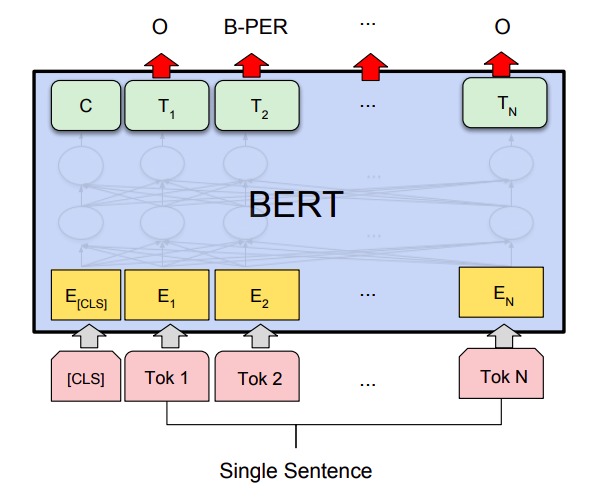
Чтобы задача была совместима с методом разбиения на токены WordPiece (где иногда токеном бывает слог или буква), каждому токену по первой букве присваивается метка, где Х означает — «не делать предсказание».

Где используется BERT
BERT используется в поисковой системе Google: поначалу эта модель работала только для английского языка, позже ее добавили в поиск и на других языках. В Яндексе BERT обучили находить опечатки и ошибки в заголовках новостей. Технологии, основанные на BERT, также могут использоваться для модерации текстов, например, отзывов и комментариев, поиска ответов на юридические вопросы, облегчения работы с документооборотом. Использование BERT и схожих технологий меняет подходы к SEO-оптимизации сайтов: поскольку поисковик теперь умеет понимать более разговорные, «живые» тексты, а значит, можно больше не перенасыщать текст громоздкими описаниями с ключевыми словами. Лаборатория DeepPavlov выпустила модель RuBERT, обученную на текстах русской Википедии, Conversational RuBERT, обученную на текстах с Пикабу, dirty и других социальных медиа, а также модель SlavicBERT, натренированную на русских новостных текстах и на чешской, болгарской, польской и русской Википедии.