
Недавно мы рассказывали о том, как преподавателю регламентировать использование ИИ на занятиях. Сегодня покажем, как работает инструмент, помогающий соблюдать академическую честность.
ИИ-плагиат: новая проблема образования
Искусственный интеллект (ИИ) применяется в образовании для автоматизации оценки письменных работ, реализации индивидуального подхода в обучении, внедрения инклюзивного образования и др. [4, 7, 13]. Однако в его использовании есть и некоторые риски, например, чрезмерная зависимость студентов от ИИ при выполнении заданий и, как следствие, снижение качества и эффективности обучения. Доступность ИИ-помощника лишает учащихся практики создания текста, во время которой они приобретают навыки критического мышления, учатся рассуждать и формулировать мысли. Становится понятно, что нужно разграничивать ситуации, в которых использование ИИ одобряется, и те, в которых задание должно быть выполнено самостоятельно. Так, возникает необходимость в создании инструмента, который определит ИИ-текст в работах учащихся. Уже существуют сервисы, которые опознают ИИ-текст: GPTZero, Originality.AI, Copyleaks, Grammarly’s AI content detector, Turnitin’s AI writing detector и др.
Но как они работают?
Ловля читеров до и после появления LLM
Еще до появления LLM возникла потребность определять оригинальность текста. Изначально шла борьба против традиционных форм плагиата, то есть копирования и минимального перефразирования опубликованных текстов, онлайн-материалов или предшествующих работ самого студента. Методы детекции плагиата были эффективны, однако многое изменилось с появлением LLM. Прежде при определении оригинальности текста он сопоставлялся с уже существующими работами, составляющими датасет. ИИ-сгенерированное эссе — это оригинальный композит, который не включен ни в один датасет. При работе с ИИ-текстами требуется иная методология, ориентированная на узнавание лингвистических нюансов, по которым различаются академический текст, созданный человеком, и эссе, сгенерированное ИИ.
Подходы для обнаружения ИИ-текста
Добавление водяных знаков
Добавление водяных знаков на ИИ-работы внесло бы однозначность в определение источников текстов. Однако в условиях реального мира этот метод ИИ-детекции нежизнеспособен: требовалось бы достичь согласия между всеми разработчиками LLM. Люди бы так или иначе пользовались ресурсами, которые стирают водяные знаки с ИИ-текстов.
Данные о процессе письма
Человеку во время написания текста свойственны определенные поведенческие паттерны: нерегулярное нажатие клавиш, паузы и всплески активности, возвращение к предыдущим частям. ИИ-текст, как правило, просто копируется и вставляется. С помощью систем прокторинга можно отслеживать поведение пишущего и выявлять, как создан текст. Но, конечно, это не помогает опознать текст, который дошел до нас в готовом виде и не содержит этих следов.
Поиск сходств
Описанные выше методы подходят для идентификации текста, целиком сгенерированного ИИ. Однако часто пользователи редактируют и дополняют ИИ-текст, в результате чего получается гибрид. Выявлять процент текста, написанного ИИ, можно с помощью поиска сходств. Так как темы эссе известны заранее, можно создавать большой пул эссе для каждого промпта, то есть для каждой темы (например, 200 эссе на одну тему). Затем эссе студентов сопоставляется с полученным пулом. По такому принципу работает детектор GPTCollider [8].
Использование ИИ-моделей для поиска следов ИИ
С помощью fine-tuning модели-трансформеры на подготовленных датасетах обучаются выявлять ИИ-текст. Они тренируются определять паттерны, свойственные ИИ-эссе. Ниже подробно описан эксперимент, в котором было протестировано несколько моделей.
«Ты должен был бороться со злом, а не примкнуть к нему!»

Понять, написан ли текст ИИ или человеком, можно с помощью моделей, основанных на трансформерной архитектуре, таких как BERT (Bidirectional Encoder Representations from Transformers) и GPT (Generative Pre-trained Transformer). Из всех протестированных моделей BERT показала наивысшую точность и наибольшую скорость выполнения задачи.
Использовать трансформеры — трудная задача. LLM тренировались на огромных датасетах, чтобы идеально имитировать человеческое письмо. А теперь им нужно распознать почерк ИИ, который научился мимикрировать под человека. Однако существуют некоторые паттерны, которые используются моделями NLP и которые способны считывать другие специально натренированные модели-трансформеры. Чтобы справиться с такой задачей, исследователи использовали «тонкую настройку» (fine-tuning) pre-trained модели-трансформера. Благодаря pre-training модель получает общие представления о языке, а затем fine-tuning адаптирует модель под конкретную задачу.
Что было сделано?
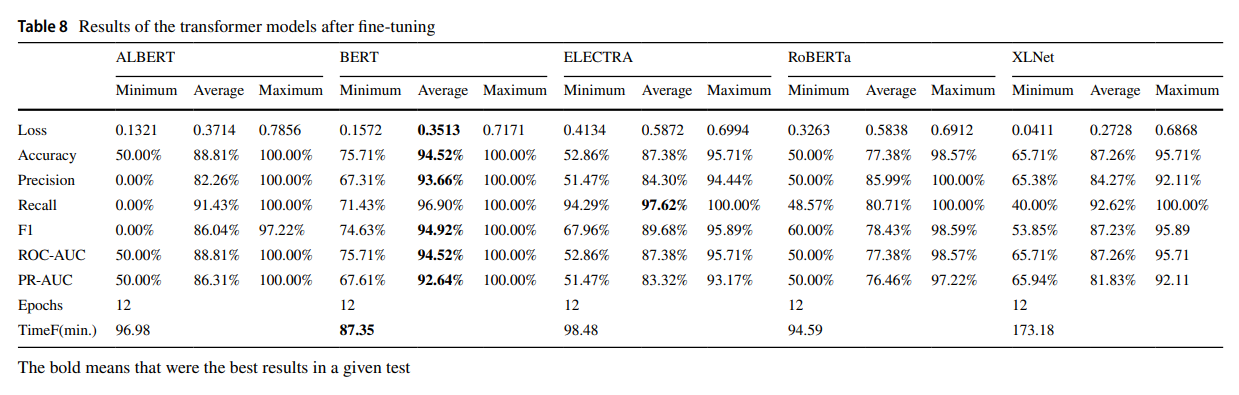
Для обучения модели подготовили тренировочный датасет. Он состоит из 200 текстов на английском языке, написанных как людьми, так и ИИ. Корпус человеческих текстов состоит из аннотаций научных работ, собранных в Scimago с использованием ключевого слова leadership. Для получения итогового датасета рандомно выбрали несколько аннотаций 2023 года из разных исследовательских областей. Для ИИ-текстов использовали аннотации, сгенерированные по названию реально существующих работ, для создания текстов использовали модель GPT-3.5 от OpenAI (GPT-5 появилась после публикации статьи). Такое решение позволило исключить различия в темах между текстами и улучшить качество обучения модели. Теперь она фокусировалась не на разных темах, а на разных стилях. При обработке данных убрали все лишние пробелы, ненужные знаки (запятые, скобки, цифры) и пр. Это сделали для того, чтобы модель уловила значимые различия, а не выявляла ложные закономерности. Однако удаление стоп-слов (например, a, the, is) и стемминг (приведения словоформы к основе) авторы работы не использовали. Дело в том, что при распределении текстов на сгенерированные ИИ и написанные людьми важную роль играют исходные состав и структура фразы. Удаление стоп-слов и стемминг могут разрушить контекстуальную целостность и привести к тому, что тексты ИИ и человека будут неразличимы.
После этого решили попробовать, как работает pre-trained модель без fine-tuning. Оказалось, что очень плохо. Полученные результаты можно назвать случайными. Именно благодаря fine-tuning система работает лучше и точнее.
Проверка полученных результатов
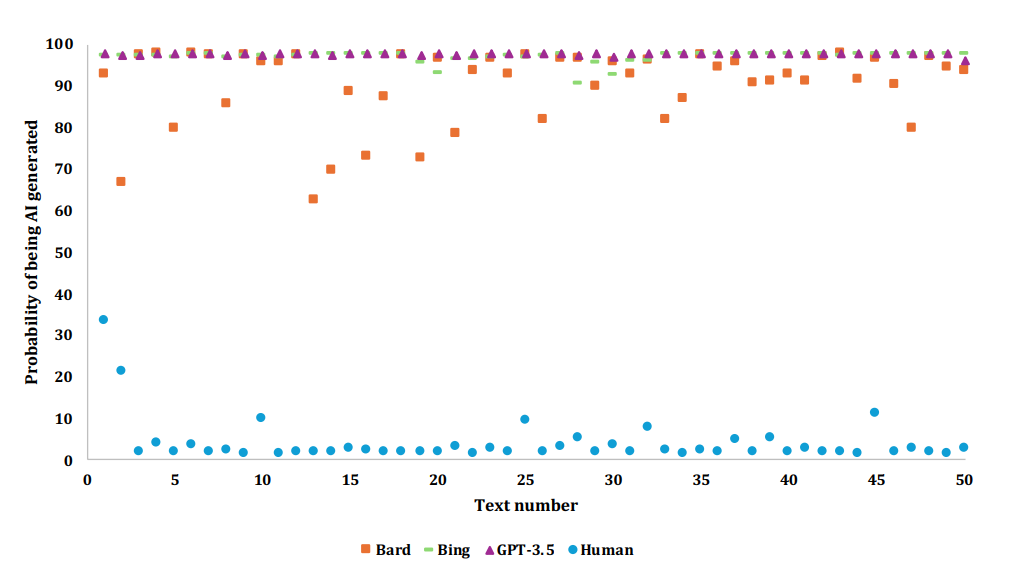
Для проверки эффективности BERT составили новый датасет из 150 текстов. Среди них были как извлеченные из Scopus за 2023 год аннотации с ключевым словом machine learning, так и сгенерированные аннотации к тем же найденным статьям. Для генерации использовались три модели: ChatGPT (разработана OpenAI, используется GPT-3.5), Bing (разработана Microsoft, используется GPT-4) и Bard (разработана Google, ее следующие поколения сейчас известны как Gemini). Со своей задачей трансформер справился успешно, однако стоит отметить, что удался эксперимент, проведенный в «чистых лабораторных условиях». Получим ли мы такой же результат в реальном мире при решении необработанной задачи?
BERT лучше всех определяет ИИ-текст, но…
При разработке модели исследователи учитывали реальный сценарий ее использования, чтобы сделать ее user-friendly: во-первых, модель будут использовать преподаватели или небольшие группы проверяющих на ежедневной основе, поэтому она должна работать на персональном компьютере небольшой мощности. Во-вторых, модель позволяет целиком анализировать PDF-документ, что может вносить некоторую неточность. Стоит учитывать, что не весь текст, а лишь его фрагменты могут быть сгенерированы ИИ. И все же, несмотря на все сложности, при дообучении модель-трансформер BERT на момент эксперимента отлично справлялась с тем, чтобы отличать текст, написанный человеком, от текста, сгенерированного ИИ.
Изобретение трансформера стало огромным сдвигом в области NLP, однако при всей эффективности у модели остается пара недостатков: она плохо адаптируется к новым типам текстов и новым генеративным моделям. Если трансформер был дообучен на аннотациях университетских работ и GPT-3.5, то при анализе школьных эссе, сгенерированных другой моделью, он может ошибаться. Важно понимать, что BERT верно классифицировала не 100% текстов. В любом случае работа с ИИ в образовании требует от нас осторожности.
А что появилось после BERT?
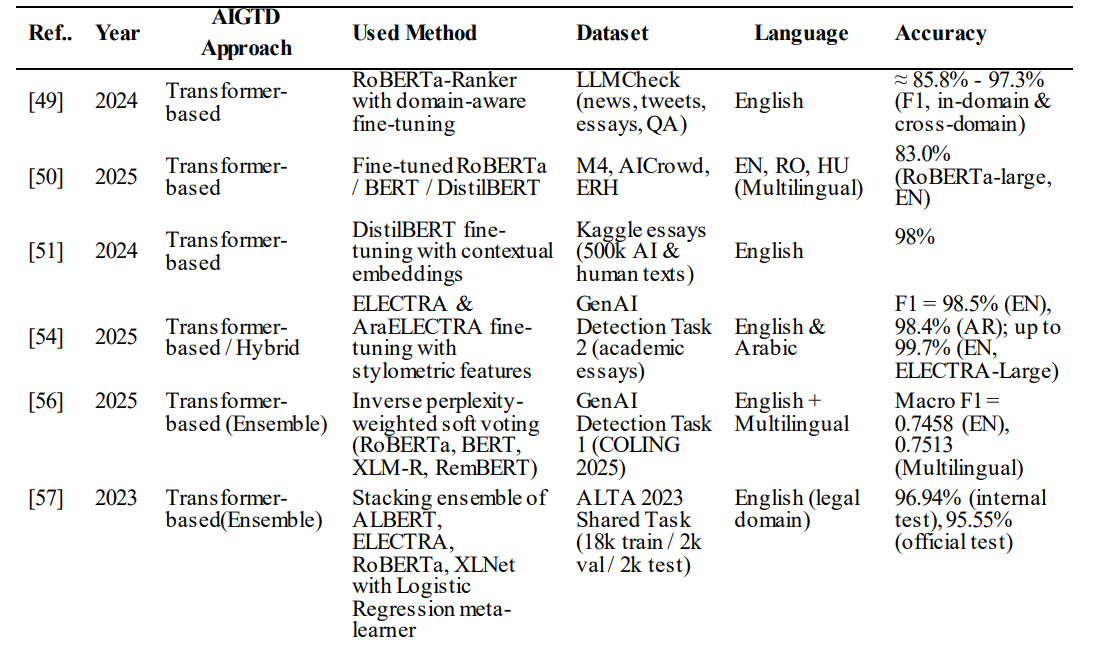
В исследовании 2026 года [2] представлены результаты дообучения на расширенном датасете RODICA моделей BERT, RoBERTa и DistilBERT. BERT идентифицирует ИИ-текст с высокой точностью. Эффективно справляется с задачей классификатор RoBERTa-Ranker, дообученная версия RoBERTa. RoBERTa дала более точные показатели для одноязычной классификации. DistilBERT лучше работает с разными языками. Сравнение результатов различных моделей-трансформеров представлено в таблице.

Источники
- Akgun S., Greenhow C. Artificial intelligence in education: Addressing ethical challenges in K-12 settings // AI Ethics. 2022. Vol. 2. P. 431–440. DOI: 10.1007/s43681-021-00096-7.
- Alethary A., Aliwy A. A Systematic Review of AI-Generated Text Detection: Approaches, Tools, and Datasets // Al-Salam Journal for Engineering and Technology. 2026. Vol. 5. N. 1. P. 145–165.
- Campino J. Unleashing the transformers: NLP models detect AI writing in education // Journal of Computers in Education. 2025. Vol. 12. N. 2. P. 645–673. DOI: 10.1007/s40692-024-00325-y.
- Chen L., Chen P., Lin Z. Artificial Intelligence in Education: A Review // IEEE Access. 2020. Vol. 8. P. 75264–75278. DOI: 10.1109/ACCESS.2020.2988510.
- Clark K., Luong M.-T., Le Q. V., Manning C. D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators // ICLR 2020. DOI: 10.48550/arXiv.2003.10555.
- Devlin J., Chang M.-W., Lee K., Toutanova K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding // Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technology. 2019. Vol. 1. P. 4171–4186. DOI: 10.18653/v1/N19-1423.
- Dimitriadou E., Lanitis A. A critical evaluation, challenges, and future perspectives of using artificial intelligence and emerging technologies in smart classrooms // Smart Learning Environments. 2023. Vol. 10. Article number: 12. DOI: 10.1186/s40561-023-00231-3.
- Hao J., Fauss M. Detecting AI-generated texts from mixed human-written and AI-generated essays in writing test. 2024. US Patent Submission # 011948-1913-888.
- Hao J. Detecting AI-Generated Essays in Writing Assessment: Responsible Use and Generalizability Across LLMs. 2026. DOI: 10.35542/osf.io/76nck_v1.
- Lan Z., Chen M., Goodman S., Gimpel K., Sharma P., Soricut R. ALBERT: a lite BERT for self-supervised learning of language representations // ICLR 2020. DOI: 10.48550/arXiv.1909.11942.
- Liang W., Yuksekgonul M., Mao Y., Wu E., Zou J. GPT detectors are biased against non-native English writers // Cell Press. 2021. Vol. 4. Issue 7. DOI: 10.1016/j.patter.2023.100779 — статья основана на исследовании 2021 года, но, несмотря на то, что сейчас модели LLM усовершенствовались, она все еще актуальна для тех, кто хочет разобраться в принципе детекции ИИ-текста в академических эссе.
- Liu Y., Ott M., Goyal N., Du J., Joshi M., Chen D., Stoyanov V. RoBERTa: a robustly optimized BERT pretraining approach. 2019. DOI: 10.48550/arXiv.1907.11692.
- Xu W., Ouyang F. The application of AI technologies in STEM education: a systematic review from 2011 to 2021 // International Journal of STEM Education. 2022. Vol. 9. N. 59. DOI: 10.1186/s40594-022-00377-5.
- Yang Z., Dai Z., Yang Y., Carbonell J., Salakhutdinov R., Le Q. V. XLNet: Generalized Autoregressive Pretraining for Language Understanding // 33rd Conference on Neural Information Processing Systems. 2019. DOI: 10.48550/arXiv.1906.08237.

