
Недавно мы рассказывали о роботе, который дважды победил человека в дебатах. Теперь разберемся, как машина научилась быть убедительным оппонентом.
В чём сложность?
Роботы научились обыгрывать людей в го, но задача освоить человеческий язык, вести дискуссии и убеждать долгое время оставалась не по зубам искусственному интеллекту .
Причина — многогранность и неоднозначность живого языка, который с трудом поддается строгому описанию. Значения слов существуют не сами по себе, а в контексте. Число контекстов, в которых слово может встречаться, очень велико. Слова, которые, казалось бы, ничем не связаны, в одном предложении могут стать синонимами или антонимами. Так у Блока в строке «Мильоны — вас. Нас — тьмы, и тьмы, и тьмы» оказывается, что «мильоны» — это, конечно, немало, но «тьмы» — существенно больше «мильонов».
Тексты из Википедии, а тем более научные тексты, более конкретны и однозначны, чем лирика. Однако и в них смыслы образуются в контексте: в одном предложении мы ссылаемся на то, что сказано в другом, заменяем целые фразы одним местоимением и многое выражаем имплицитно — не говорим, но подразумеваем, что собеседник нас поймет.
Чтобы по-настоящему понять содержание одной статьи Википедии, нужно определить смысловые отношения слов на уровнях предложения, абзаца, раздела, статьи целиком. А ведь это только одна из сложностей на пути создания железного Цицерона. Пока искусственный интеллект не умеет извлекать и анализировать содержание текстов так, как это делает человек.
Что же сделали в IBM?
Разработчики Project Debator и не пытались научить машину «понимать» содержание текстов. Робот должен был лишь точно извлекать высказывания на заданную тему и находить качественные аргументы за и против по определенным характеристикам.
Из этого следует, что у железного оратора нет своей позиции: он может как защищать утверждение, так и опровергать его. В IBM считают, что в этом их разработка даёт фору человеку, ведь наше восприятие и способность к анализу и аргументации часто страдают от когнитивных искажений и предубеждений.
Итак, что же мы увидим под капотом Project Debator? Как и любой современный ИИ, он представляет собой комплекс алгоритмов и нейронных сетей, решающих конкретные задачи.
Распознавание речи
Этим занимается алгоритм «Watson Speech to Text». Программа преобразует звучащую речь в письменную, чтобы затем ИИ мог выделить ключевые понятия и определить тезис оппонента.

О чём мы будем говорить?
Сначала Project Debater анализирует тему дискуссии: членит компоненты, из которого она состоит, и выделяет основной концепт (предмет дебата). Дальше по основному концепту подыскиваются статьи из Википедии, по которым извлекаются синонимы и отсеиваются внешне схожие, но отличающиеся по содержанию понятия.
Например, если тема дебатов — «Брак в наше время устарел», при помощи инструмента викификации машина отсеет статьи, содержащие понятие «однополый брак», дискуссии о котором широко представлены в базе данных.
Определив основной концепт, уточнив и ограничив поиск набором синонимичных понятий, Project Debater ищет содержащие их высказывания. Чтобы найти такие утверждения, а не просто упоминания, фразы подбираются по заданному шаблону:
«that» + основной концепт (набор, полученный при викификации) + лексика высказывания
Чтобы находить лексику высказывания, Project Debater сравнивает предложения, в которых основной концепт встречается после слова-маркера «that», и остальные предложения, в которых оно упоминается. Так он узнаёт, что чаще встречается в высказывании и что, скорее всего, в нём быть не должно.

«За» или «против»?
Когда все высказывания отобраны, машине нужно понять, какие из них «за», а какие — «против». Для этого подбираются сигнальные фразы для объекта дискуссии и выявляется тональность высказываний. ИИ оценивает эмоциональную окрашенность слов, в которых встречаются важные для дискуссии понятия.
Например, предложения в поддержку свободы слова будут содержать критику цензуры и положительную окраску в контексте свободы дискуссий.
Искусство отрицать
Чтобы оспаривать своего оппонента, робот должен уметь опровергать его утверждения.В хорошей дискуссии обойтись фразой «это не так» не получится. Главная сложность — понимать, когда отрицать уместно.
Скажем, дано высказывание: «Положительная дискриминация имеет нежелательные побочные эффекты в дополнение к её неспособности достичь своих целей. Процесс отбора не должен основываться на своевольных и неуместных критериях».
Примитивная система автоматического отрицания могла бы сделать эту фразу следующей: «Положительная дискриминация имеет желательные побочные эффекты в дополнение к её неспособности достичь своих целей. Процесс отбора должен основываться на своевольных и неуместных критериях».
Такие аргументы превратили бы робота в безумного монстра. Разработчики IBM нашли выход, применив логистическую регрессию* с 19 параметрами. Среди них длина предложения, наличие определенных слов и конструкций, тональность слов. Взяв большой корпус, учёные сравнили частоту найденного аргумента и фразы, которая получается в результате его отрицания. Если последняя встречается значительно реже, то велика вероятность, что отрицательное предложение бессмысленно.
Как ИИ подружили с Аристотелем
Всё, чему научился Project Debater, было бы бесполезно, если бы машина не умела отбирать самые убедительные аргументы из тысяч найденных.
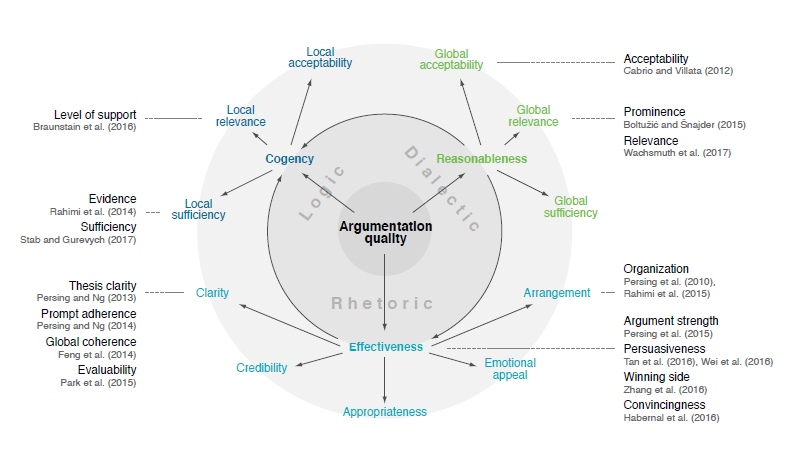
Для оценки качества аргумента разработчики выделили три главных параметра: логичность, риторическая составляющая и обоснованность.
Логичность
Насколько аргумент поддерживает высказывание, насколько он достаточен и сконцентрирован на тематически важных понятиях.
Риторика
В качестве основы для определения риторической составляющей команда из IBM взяла труды Аристотеля. Помимо важности слова в искусстве убеждать, он уделял внимание степени доверия, которое вызывает высказывание, и его эмоциональное влияние. Чтобы оценить этот параметр, исследователи решили учесть организацию аргумента, его связность, воздействие на публику.
Обоснованность
Настоящей целью оратора должна быть не победа в споре, а достижение истины или, если быть более точным, решение разногласий. Находить лучшие, наиболее разумные решения запутанных проблем — основная задача Project Debater. Поэтому разработчики постарались учесть и те признаки, которые оценивают обоснованность аргумента.
Project Debator учится превосходить людей
Робот обучается спорить на данных, отобранных и ранжированных командой исследователей. Критерии качественного аргумента выявляются на базе тысяч студенческих эссе, получивших отличные оценки.
Пока Project Debator нельзя назвать настоящим искусственным интеллектом. Но перерабатывая десятки трудов ученых разных лет и эпох, железный оратор делает первые шаги к тому, чтобы освоить все знания и опыт, накопленные человечеством.
Узнать подробности о том, как устроен Project Debater, можно здесь.
Источник: Watson Speech To Text
*Корпус — отобранная и размеченная специальным образом база данных.
*Логистическая регрессия — статистическая модель, которая помогает предсказать вероятность того или иного события на основе множества признаков.

