
Мода и компьютерные науки
Анализ трендов является одной из актуальных тем в исследовании моды, и он интересует не только стилистов, но и учёных. Например, исследователи в области компьютерных наук разрабатывают алгоритмы, которые могли бы предсказывать будущие тенденции или оценивать долгосрочные тренды [1], [2], [3]. Основная цель таких работ — помочь производителям одежды более эффективно планировать новые коллекции и совершенствовать рекомендательные системы в интернет-магазинах. Чтобы добиться этой цели, исследователи создают базы данных изображений, аннотируя различные аспекты, такие как цвет, ткань, форма, текстура [4], [5], [6]. Эти данные становятся основой для алгоритмов, которые могут предсказывать предпочтения потребителей и выявлять новые тренды.
Однако у учёных может быть и другая, менее прикладная, задача: изучать моду как социальное явление. Мода служит формой самовыражения, которая подвержена воздействию различных факторов, включая культуру, экономическую ситуацию, исторические события, социальный статус, коммьюнити [7]. Авторы одного из подобных исследований собрали базу данных изображений с 1990 по 2009 год, чтобы изучить как винтажная мода повлияла на модные стили с 2000 по 2014 год [2].
Однако люди, входящие в состав разных сообществ, имеют свои характерные модные стили. Более того, каждое такое сообщество может занимать определённую территорию. Примером может служить модный стиль токийского квартала Сибуя, который стал популярен среди девушек благодаря тому, что они часто посещают торговые центры, расположенные здесь. Изображения, сгруппированные по десятилетиям, не показывают, как люди выбирают стили в своей жизни. Для таких исследований нужны базы данных изображений повседневной одежды с аннотациями по местоположению на уровне улиц. Именно для этого создана база CAT STREET.

Магазины и торговые центры в окрестностях станции Сибуя. Источник: Mapple.net
Как создавался CAT STREET
На ранних этапах исследования модных трендов учёные вручную анализировали характеристики вечерней одежды, используя модные журналы XIX–XX вв. [9], [10], [11]. Однако, помимо того, что данные работы фокусировались на определённом виде нарядов, они были очень трудоёмкими и требовали много времени. Чтобы улучшить ситуацию, в исследовании Сатоси Такахаси (Satoshi Takahashi), Кэйко Ямагути (Keiko Yamaguchi) и Асука Ватанабэ (Asuka Watanabe) [12] предлагается использовать машинное обучение. Этот подход позволяет алгоритмам анализировать данные и имитировать ручные процессы обработки на основе примеров, что делает анализ модных трендов более точным, эффективным и значительно упрощает работу с большими цифровыми архивами. Так была создана база данных CAT STREET.
Исследователи сами собирали фотографии (с 1980 по 2017 г.) уличной моды на торговых улицах Токио, таких как Харадзюку и Сибуя. Также они включили в исследование фотографии, сделанные в 1970-х годах сторонней организацией, с метками по месяцам. Здесь стоит отметить, что фотографии 1970-х гг. с временными метками по фону соотносились с фотографиями 1980-х гг. с метками по улицам. Таким образом, с добавлением тегов база данных охватывает период с 1970 по 2017 год.
Авторов интересовала только женская мода, поэтому они вручную классифицировали изображения по полу, оставив только фотографии женщин. Некоторые снимки 1970-х годов были чёрно-белыми, поэтому все фотографии были переведены в градации серого для унификации цветового тона.
Так как фотографии уличной моды часто содержат много шума, что затрудняет точное определение комбинаций одежды, авторы также сделали предобработку изображений с использованием алгоритма OpenPose [13]. Это помогло им определить очертания силуэтов. Они удалили часть фонов и обрезали головы субъектов.
Результатом работы стала база данных CAT STREET, которая содержит 14 688 изображений с модных улиц Токио, отражающих реальную повседневную моду женщин между 1970 и 2017 годами.

Обзор данных CAT STREET. Источник [12]
Как проводилось исследование
Модель кластеризации стилей моды
В качестве обучающей выборки была выбрана база FashionStyle14 [14], состоящая из 14 классов стилей (признаны экспертами как представители современных модных тенденций 2017 г.) и примерно 13 тысяч изображений. Модель кластеризации позволила измерить долю каждого стиля в разные годы и выявить, когда начали набирать популярность разные стили.

Примеры изображений FashionStyle14 и примеры изображений в CAT STREET, классифицированные по различным стилям с использованием модели кластеризации стилей. Источник [12]
Затем были обучены четыре структуры глубокого обучения (DL) в качестве вариантов для модели кластеризации моды: InceptionResNetV2 [15], Xception [16], ResNet50 [17] и VGG19 [18]. В качестве начальных весов они использовали веса, обученные на ImageNet [19], и дообучили их на FashionStyle14, применяя алгоритм стохастического градиентного спуска с коэффициентом обучения 10⁻⁴. Для дообучения использовался метод k-кратной перекрёстной проверки с k, равным 5.
Что такое алгоритм стохастического градиентного спуска (SGD)
Алгоритм стохастического градиентного спуска (SGD) — это метод, который используется для обучения нейронных сетей. Его цель — минимизировать ошибку модели, обновляя её параметры на основе данных. Представьте, что вы ищете самый низкий холм в тумане. Вы не смотрите на всю местность, а делаете маленькие шажочки, чтобы нащупать холмики, и смотрите под ноги, просто чтобы понимать, туда ли ты идёшь. Если да, вы продолжаете идти в этом направлении, а если нет, меняете его. Коэффициент обучения как раз и определяет, насколько большие шаги вам нужно делать. Если шаги слишком большие, то можно «перепрыгнуть» холм, пропустить нужный. А вот если шаги маленькие, нужно будет много времени, чтобы добраться до цели. В нашем случае значение 10 в минус 4 степени показывает, что шаги очень маленькие. Собственно поэтому модель так аккуратно настраивает свои параметры, не «перепрыгивая» слишком далеко.
Что такое метод k-кратной перекрёстной проверки (k-fold cross-validation)
Метод k-кратной перекрёстной проверки (k-fold cross-validation) — это способ оценки качества модели на разных поднаборах данных. Пятикратная проверка означает: (a) имеющиеся данные делятся на пять равных частей (или fold), (b) модель обучается пять раз, при этом каждый раз она использует 4/5 для обучения и 1/5 для тестирования. Так каждый сегмент данных используется для проверки модели, что позволяет получить более надёжную оценку её производительности, (c) результаты тестирования по всем пяти запускам объединяются, и берётся среднее значение метрик, чтобы оценить, как хорошо модель работает в целом.
В результате InceptionResNetV2 показала наивысшие F1-меры среди структур глубокого обучения для большинства модных стилей. Её точность составила 0,787, что выше эталонной точности 0,72. Поэтому исследователи выбрали InceptionResNetV2 в качестве модели кластеризации модных стилей в этом исследовании.
Что такое F1-мера
F1-мера — это метрика, используемая для оценки качества модели, особенно в задачах классификации. Она комбинирует два важных показателя: точность (precision) и полноту (recall). Точность показывает, сколько из всех предсказанных положительных случаев действительно являются положительными. Полнота показывает, сколько из всех реальных положительных случаев было правильно предсказано моделью. Таким образом, F1-мера принимает значения от 0 до 1, где 1 означает идеальное качество (максимальная точность и полнота), а 0 — полное отсутствие качества.
Модные стили в CAT STREET
Полученную модель кластеризации исследователи применили к архиву CAT STREET. Она состояла из пяти отдельных моделей, так как использовалась пятерная перекрёстная проверка при обучении нейронной сети, о которой говорилось ранее. Каждая из пяти моделей оценивала долю определённого стиля для изображения. Чтобы проверить, насколько надежны эти модели в воспроизведении долей стилей, исследователи проанализировали временные корреляции между пятью моделями. На графике ниже показаны средние коэффициенты корреляции для модных стилей. Большинство стилей имеют высокие коэффициенты корреляции, превышающие 0,8, и стандартные ошибки небольшие. Однако некоторые стили, такие как Dressy, Feminine и Gal, показали низкие корреляции, так как изначально имели маленькие доли.
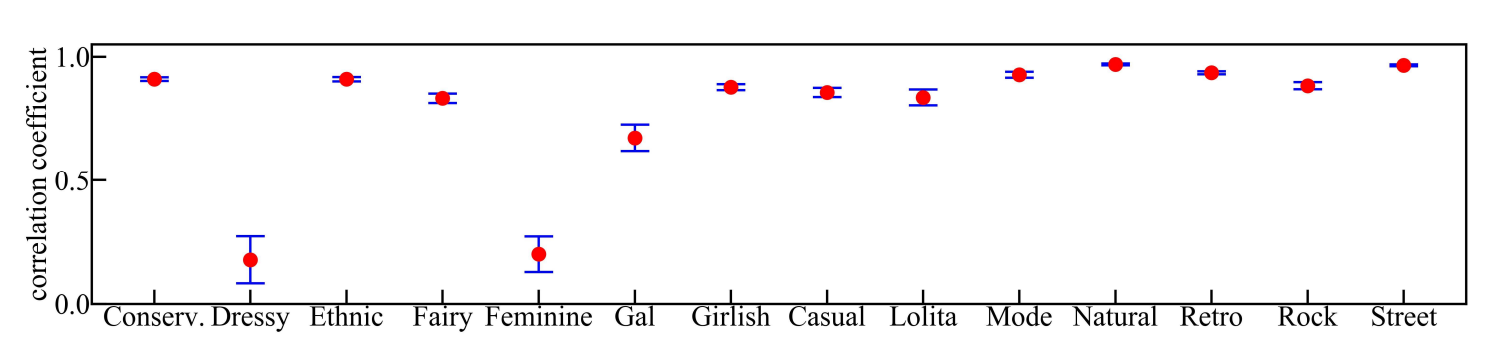
Средние коэффициенты корреляции среди пяти моделей для стилей моды. Conserv. — это сокращение от Conservative (рус. «консервативный, старомодный»). Источник [12]
Эти результаты подтверждают, что модель кластеризации модных стилей является надёжным инструментом для анализа временных паттернов присутствия каждого стиля. На графике ниже представлены средние значения долей стилей за период с 1970 по 2017 год. Так как не было изображений за 1997 и 2009 годы, исследователи заменили нули средними значениями соседних показателей и использовали трёхлетнее скользящее среднее.

Средние значения долей стилей с 1970 по 2017 г. Источник [12]
Как социальные факторы влияют на моду и стиль
Социальные и экономические условия влияют на формирование социальной идентичности и на способы её выражения, в том числе в стилях одежды. Иногда люди хотят повысить свой социальный статус и покупают качественные вещи от люксовых брендов как символ богатства.
Чтобы проверить, есть ли связь между внешними обстоятельствами и долгосрочными изменениями в модных стилях, авторы изучили, как экономические условия влияют на стиль Conservative. Он характеризуется классическими элементами одежды, качественными материалами и сдержанными цветами, такими как чёрный, тёмно-синий и серый. Он акцентирует внимание на элегантности и простоте, часто включая офисную одежду, строгие силуэты и предметы роскоши.
Исследователи использовали данные о доле Conservative в качестве зависимой переменной и провели однофакторный анализ дисперсии (ANOVA), который позволил оценить, как меняется доля стиля в разные экономические периоды в Японии. Также, чтобы проверить связь между средней долей Conservative и темпами роста валового внутреннего продукта (ВВП) в Японии, была применена векторная авторегрессионная (VAR) модель. Для VAR модели использовались данные с 1970 по 2008 год. Результаты анализа показали, что средние доли Conservative различаются в периоды экономических спадов и подъёмов: когда экономика растёт, люди чаще выбирают стиль Conservative.
Что такое однофакторный анализ дисперсии (ANOVA)
Однофакторный анализ дисперсии (ANOVA) — это статистический метод, который позволяет сравнивать средние значения между двумя или более группами. Он помогает определить, есть ли значимые различия между группами по определённой переменной. Например, ANOVA может показать, как различные экономические условия влияют на долю определённого модного стиля.
Что такое авторегрессионная (VAR) модель
Авторегрессионная (VAR) модель — это статистический инструмент, который анализирует взаимосвязь между несколькими временными рядами. Она помогает понять, как изменения в одной переменной (например, в ВВП) могут влиять на другие переменные (например, долю стиля Conservative) с течением времени. VAR модель учитывает, что значения переменных зависят не только от текущих факторов, но и от их прошлых значений.
Как возникают и распространяются модные стили внутри города
В Токио есть две знаковые улицы, ориентированные на моду: Харадзюку и Сибуя. Они расположены близко друг к другу, но на этих улицах мы можем увидеть разные модные тренды. Например, один из характерных модных стилей Харадзюку — Каваии-кэй (Kawaii-kei) [21], который подчеркивает миловидность и игривость, включает яркие цвета, пышные юбки и забавные аксессуары, часто вдохновлённые аниме и мультяшными персонажами.
Одним из характерных модных стилей Сибуи является Gal, представляющий собой слегка сексуальную моду «девчонки по соседству» (slightly sexy homegirl fashion) [20].
Исследователи сравнили повседневные модные стили на этих улицах с помощью CAT STREET, чтобы понять, как они возникают и распространяются.
Например, на графике ниже демонстрируется стиль Fairy (рус. «фея»), который появился в Харадзюку в конце 2000-х и исчез в начале 2010-х. Этот стиль включает пышные платья, напоминающие фей. Хорошо заметно, что он проник и в район Сибуя, но пользовался гораздо меньшей популярностью.
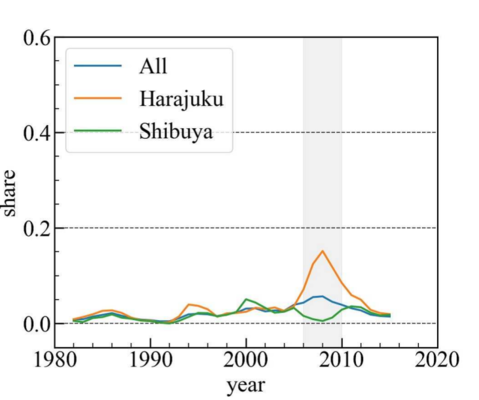
Проявление стиля Fairy на улицах Токио. Источник [12]
На следующем изображении представлены примеры стиля Gal, который возник в 1995-1996 гг. одновременно и в Харадзюку, и в Сибуя благодаря поп-певице Намиэ Амуро. Анализ показал, что в Сибуя он сохранился, а в Харадзюку исчез и вернулся в 2012 году с небольшими изменениями.

Четыре фотографии слева были сделаны в 1995–1996 гг. на Харадзюку (i, ii) и на Сибуе (iii, vi). Фотографии сняты в 2000-х гг. на Харадзюку (v, vi) и на Сибуе (vii, viii). Источник [12]

Проявление стиля Gal на улицах Токио. Источник [12]
Ещё один пример — интерес к ретро-стилю. Он имеет много подстилей, в зависимости от эпохи (мода 60-х, 70-х и 80-х). На графике ниже можно заметить небольшие подъёмы в начале 1980-х и конце 1990-х, которые указывают на возрождение моды. Исследователи отметили, что необходимо больше данных, чтобы выяснить, какие именно подстили появились в эти периоды.
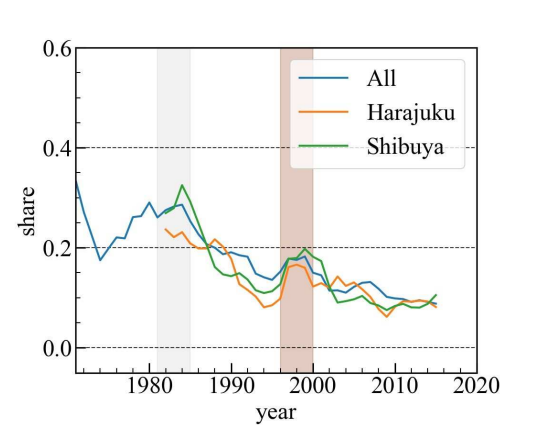
Проявление ретро-стиля на улицах Токио. Источник [12]
Чем полезно исследование моды
Исследование повседневной моды в Японии значительно продвинулось благодаря созданию цифрового архива CAT STREET. Этот ресурс дает возможность изучать историю уличного стиля Токио и использует машинное обучение для анализа трендов. С его помощью удалось подтвердить, что экономические условия влияют на характер стиля одежды, а также обнаружить отличия между разными сообществами.
CAT STREET позволяет исследователям изучать ещё не решенные вопросы, используя другие количественные методы анализа, такие как кластеризация, чтобы выявить модные стили, которые присутствуют в повседневной жизни людей. Этот архив может помочь расширить исследования моды в области компьютерных наук и других дисциплинах.
Источники
- Al-Halah Z., Stiefelhagen R., Grauman K. Fashion forward: Forecasting visual style in fashion // In Proceedings of the IEEE International Conference on Computer Vision. 2017. Pp. 388–397.
- Vittayakorn S., Yamaguchi K., Berg A. C., Berg T. L. Runway to realway: Visual analysis of fashion // IEEE Winter Conference on Applications of Computer Vision. 2015. Pp. 951–958.
- Matzen K., Bala K., Snavely N. Streetstyle: Exploring world-wide clothing styles from millions of photos //arXiv preprint arXiv:1706.01869. 2017.
- Yamaguchi K. et al. Parsing clothing in fashion photographs // 2012 IEEE Conference on Computer vision and pattern recognition. IEEE, 2012. Pp. 3570–3577.
- Kiapour M. H. et al. Hipster wars: Discovering elements of fashion styles // Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I 13. Springer International Publishing, 2014. Pp. 472–488.
- Takagi M. et al. What makes a style: Experimental analysis of fashion prediction // Proceedings of the IEEE International Conference on Computer Vision Workshops. 2017. Pp. 2247–2253.
- Lancioni R. A. A brief note on the history of fashion //Journal of the Academy of Marketing Science. 1973. Vol. 1. Issue 2. Pp. 128–131.
- Dhanorkar S. 8 unusual indicators to gauge economic health around the world [Электронный ресурс] // The Economic Times. 20.04.2015. URL: https://economictimes.indiatimes.com/news/economy/indicators/8-unusual-indicators-to-gauge-economic-health-around-the-world/articleshow/46967683.cms?from=mdr (дата обращения 17.10.2024).
- Kroeber A. L. On the principle of order in civilization as exemplified by changes of fashion // American Anthropologist. 1919. Vol. 21. Issue 3. Pp. 235–263.
- Belleau B. D. Cyclical fashion movement: Women’s day dresses: 1860–1980 // Clothing and textiles research journal. 1987. Vol. 5. Issue 2. Pp. 15–20. DOI: https://doi.org/10.1177/0887302X8700500203.
- Lowe E. D. Quantitative analysis of fashion change: A critical review //Home Economics Research Journal. 1993. Vol. 21. Issue 3. Pp. 280–306. DOI: https://doi.org/10.1177/0046777493213004.
- Takahashi S., Yamaguchi K., Watanabe A. A Novel Approach to Analyze Fashion Digital Library from Humanities [Электронный ресурс] // International Conference on Asian Digital Libraries. Cham : Springer International Publishing, 2021. Pp. 179–194.URL: https://arxiv.org/abs/2107.08351v2 (дата обращения 17.10.2024).
- Cao Z. et al. Realtime multi-person 2d pose estimation using part affinity fields // Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. Pp. 7291–7299.
- FashionStyle14 [Электронный ресурс]: https://esslab.jp/~ess/en/data/fashionstyle14/.
- Szegedy C. et al. Inception-v4, inception-resnet and the impact of residual connections on learning // Proceedings of the AAAI conference on artificial intelligence. 2017. Vol. 31. Issue 1.
- Chollet F. Xception: Deep learning with depthwise separable convolutions // Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. Pp. 1251–1258.
- He K. et al. Deep residual learning for image recognition //Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. Pp. 770–778.
- Simonyan K., Zisserman A. Very deep convolutional networks for large-scale image recognition // arXiv preprint arXiv:1409.1556. 2014.
- Russakovsky O. et al. Imagenet large scale visual recognition challenge // International journal of computer vision. 2015. Vol. 115. Pp. 211–252. DOI: https://doi.org/doi.org/10.1007/s11263-015-0816-y.
- Yoshimura S. The Fashion Logos. Tokyo, Senken Shinbun Co., Ltd., 2019.

