
Чем отличаются Digital Humanities (DH) от традиционных гуманитарных дисциплин? Прежде всего — стремлением к единому методологическому пространству: исследователи, независимо от страны и языка изучаемой культуры, используют схожие методы и решают похожие задачи. Такие методы, как сетевой анализ, стилометрия, геокодирование, методы NLP или компьютерного зрения применяются цифровыми гуманитарными исследователями по всему миру для самых .
Хотя культурный, языковой и политический контекст всегда влияет на гуманитарные исследования, в DH принцип интероперабельности (interoperability) — способность систем и данных к взаимодействию — стал фундаментальной ценностью, унаследованной из философии открытого кода и сетевых протоколов. Юная исследовательская сфера генетически связана с компьютерными науками, ориентированными на универсальные алгоритмические решения.
Примеров множество. Европейские и американские исследователи в течение нескольких десятилетий последовательно выстраивают сложную экосистему стандартов (TEI для кодирования текстов, LOD для связанных данных, IIIF для изображений), преодолевающую границы между проектами, институциями и национальными школами. Насколько универсальна эта парадигма? Находит ли она отклик за пределами западного академического мира?
Наша исследовательская группа из Болонского университета отправилась в Пекин по приглашению университетского исследовательского центра Digital Humanities. Мы представляли проект LeggoManzoni — цифровое издание романа Алессандро Мандзони «Обрученные» с комментариями и переводами.
Центр Digital Humanities в Пекинском университете открылся в 2020 году под руководством профессоров Qi Su и Jun Wang. Основной целью центра является создание инфраструктуры для исследований китайского культурного наследия. Хотя центр находится на начальном этапе развития, нам рассказали о трех ключевых направлениях, над которыми работают студенты университета.
1. Shidian Ancient Books: распознавание древнекитайских текстов
Платформа Shidian Ancient Books, разработанная совместно с ByteDance (создателем TikTok), решает фундаментальную задачу: создание полнотекстовых цифровых копий древнекитайских текстов. Иероглифическая письменность с ее вариативностью начертаний и многочисленными стилями каллиграфии представляет вызов иного порядка, чем распознавание алфавитных систем.
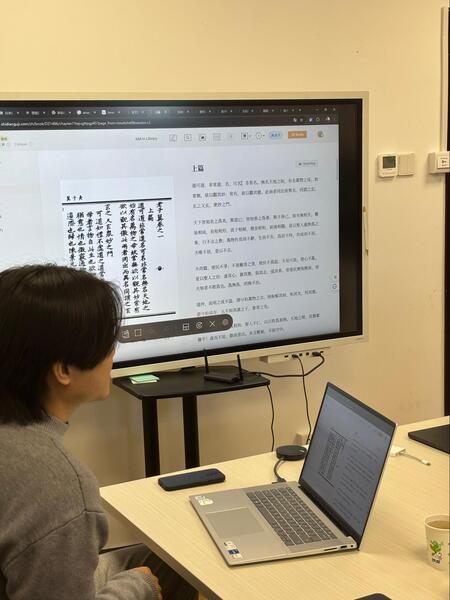
Демонстрация работы OCR на документе с китайскими иероглифами (в тексте использованы фотографии из архива участников группы)
Парадоксально, что большинство из 10 тысяч книг (от династии Сун до начала XX века) были предоставлены американской библиотечной системой HathiTrust, а не оцифрованы в самом Китае.
Технически Shidian впечатляет: нейронная сеть, обученная на тысячах образцов древней каллиграфии, интерфейс с параллельным отображением оригинала и распознанного текста, интеллектуальная подсветка проблемных участков. Точность распознавания достигает 95% для хорошо сохранившихся текстов и 85% для поврежденных. Такой уровень автоматизации трансформирует саму природу филологической работы с древними китайскими текстами.
Платформа открыта для китайских пользователей: можно загрузить свой собственный документ и распознать его с помощью модели.
2. Аннотирование текстов: платформа Wuyidian
Платформа 吾与点 (Wuyidian), разработанная Пекинской компанией Wendian Yidu Technology под научным руководством университетского центра, представляет собой интеллектуальную систему обработки древних книг. Она автоматически извлекает из текстов нужные пользователю отношения с помощью LLM (при этом используется не только нашумевшая китайская модель DeepSeek, как можно было бы подумать, но и OpenAI и Anthropic).
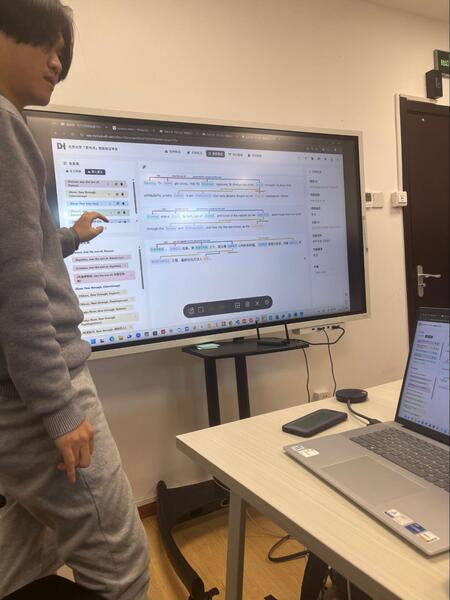
Пример аннотации текстов. Слева цветом выделены границы и типы распознанных сущностей, справа отображение связей между ними в тексте
В настоящее время платформа в основном применяется для извлечения именованных сущностей из исторических текстов, как описано в недавней академической публикации в журнале Digital Scholarship in the Humanities. Однако потенциал системы значительно шире — благодаря взаимодействию с языковыми моделями, спектр извлекаемых отношений может быть чрезвычайно разнообразным. Система позволяет:
- автоматически идентифицировать имена исторических личностей, географические названия и другие сущности,
- выявлять отношения между ними (родственные, административные, политические).
- формировать онтологии и графы знаний,
- преобразовывать нарративные тексты в структурированные базы данных.
Например, можно проанализировать династийную хронику и выделить все упоминания должностных лиц, их титулов, сфер ответственности и взаимосвязей и сохранить в структурированном формате. Для китайской филологии, веками развивавшейся в парадигме комментирования, это эпистемологическая революция.
Особенно важна способность платформы работать с классическим языком вэньянь и автоматически сегментировать древние тексты на предложения и слова. Поддерживается экспорт данных в различные международные форматы (CSV, JSON, RDF-триплеты), что теоретически обеспечивает совместимость с глобальными цифровыми проектами. Однако для Linked Open Data система опирается на локальную китайскую «Энциклопедию» в качестве авторитетного источника, а не на широко используемые в западных DH-проектах ресурсы вроде Wikidata или «Библиотеки Конгресса». Это отражает специфику китайского подхода — создание самодостаточной цифровой экосистемы с собственными стандартами и авторитетными источниками.
3. Видео на основе иллюстраций к древним книгам

Скриншоты приложения для визуализации историй
Проект анимации классических книжных иллюстраций поднимает вопрос о переосмыслении наследия. В эпоху TikTok и компьютерных игр статичные изображения из культового китайского романа «Сон в красном тереме» рискуют остаться непрочитанными культурными кодами. Но что происходит при их оживлении?
Алгоритмы компьютерного зрения сегментируют оригинальные иллюстрации, создают трехмерные модели с сохранением стилистики, а системы анимации, учитывающие китайскую эстетику движения, оживляют их. Особенно интересной частью проекта является работа с элементами стиля династии Сун, характеризующегося насыщенной цветовой палитрой и глубокой детализацией. Например, одна из демонстрируемых картин изображает более сотни фигур в сложной композиции — превращение такого многофигурного статичного изображения в анимированную сцену требует не только технического мастерства, но и глубокого понимания культурного контекста.
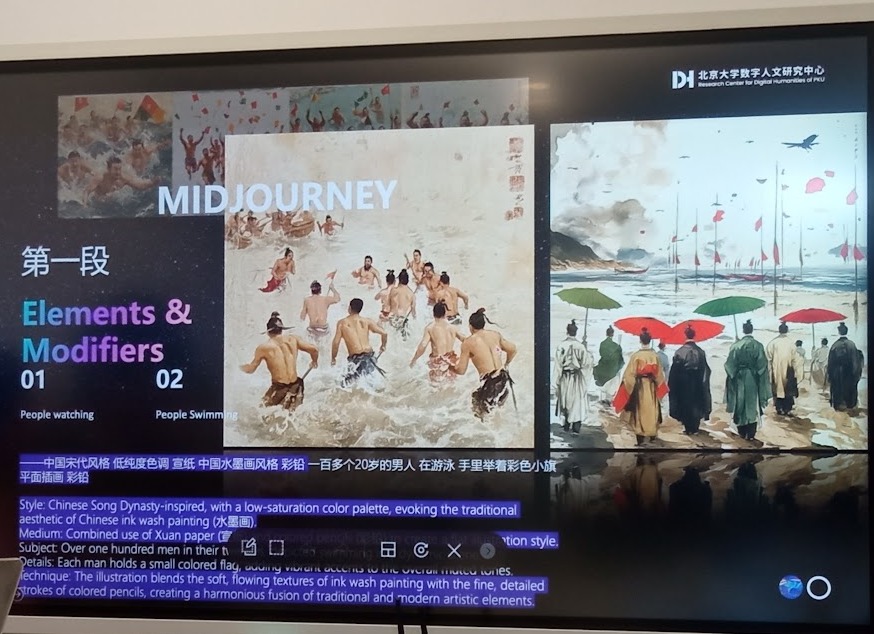
Имитация стиля классических китайских иллюстраций с помощью промта для Midjourney
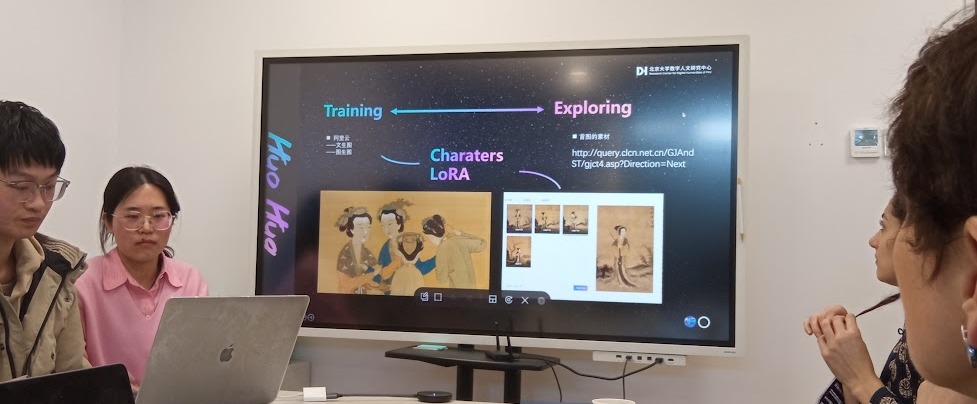
Модели для генерации изображений специально дообучают генерировать отдельных персонажей
Исследовательский центр Пекинского университета развивает и другие проекты, связанные с китайским культурным наследием:
- 《永乐大典》高清影像数据库系统 — база данных изображений из «Энциклопедии Юнлэ», крупнейшей энциклопедии в истории Китая (1408 г.),
- 《国家珍贵古籍名录》系统 — система каталогизации национального реестра ценных древних книг, разработанная совместно с Национальной библиотекой Китая,
- 文献满分分析平台 — платформа для глубокого анализа исторических текстов, объединяющая методы обработки естественного языка и традиционной филологии,
- 《论语》文本复用可视化平台 — система визуализации текстовых заимствований «Аналектов Конфуция», показывающая циркуляцию конфуцианских цитат в разных текстах на протяжении столетий,
- 观澜——宋代生活场景可视化 — «Гуаньлань» — проект визуализации повседневных сцен из жизни эпохи Сун (960–1279 гг.), реконструирующий бытовые и социальные практики на основе исторических описаний,
- 经籍指掌——中国历代典籍目录分析系统 — аналитическая система каталогов китайских исторических библиографий, позволяющая проследить эволюцию классификации знаний в Китае,
- «宋元学案»知识图谱系统 — система построения графов знаний на основе «Академических случаев эпох Сун и Юань» — важного исторического сочинения о развитии философских школ,
- 中国历史人物资料库WEB检索系统 — веб-система поиска по базе данных исторических личностей Китая, интегрирующая биографические сведения из различных источников,
- 中国古代历史人物迁徙可视化 — визуализация миграций исторических личностей древнего Китая, отображающая географическую мобильность интеллектуальной и политической элиты,
Проектная логика vs. инфраструктурная модель
В Европе DH-исследования устроены в основном на проектной основе: как правило, они отталкиваются от конкретного корпуса материалов (будь то произведения отдельного автора, архив определенной эпохи или коллекция артефактов), для работы с которым адаптируются, модифицируются или создаются цифровые инструменты. Методологические обобщения и технологические стандарты возникают постепенно, в результате обмена опытом между множеством локальных инициатив и независимых исследовательских центров. Стоит, однако, отметить и значимые исключения из этой тенденции — европейские проекты инфраструктурного характера, такие как Transkribus (платформа для автоматизированного распознавания исторических рукописей), eScriptorium (фреймворк с открытым кодом для транскрипции манускриптов) или EVT (инструмент для создания цифровых изданий на основе XML/TEI).
В Пекине мы увидели обратную логику: первоочередной целью нового исследовательского центра стало создание мощной централизованной инфраструктуры, основы для будущих проектов. Колоссальные масштабы китайского культурного наследия делают эту стратегию не просто предпочтительной, но необходимой — без создания унифицированных платформ для оцифровки, распознавания, анализа и визуализации данных работа с десятками тысяч древних текстов и миллионами исторических документов была бы практически невозможна.
Исключительно эффективной в этом случае оказывается тесная интеграция с технологическим сектором: крупные компании (ByteDance, Wendian Yidu Technology) предоставляют для проектов центра как вычислительные мощности, так и экспертизу в области машинного обучения и разработки.

