
«Только никакой Википедии в источниках», — наверняка говорили вам в школе или на первом курсе университета, а за пять минут до дедлайна вы находили себя копирующим ссылки оттуда. Другой пример: куда вы направляетесь, когда внезапно в три часа ночи ну очень нужно узнать список самых известных кошек мира? На самом деле, существует целая база данных на основе Википедии и других её проектов: Wikibooks, MediaWiki, Wikisource, Wikiquote… Иными словами, всё, что вы могли бы найти в интернете с добавлением «вики», теперь собрано в одном месте.
А зачем нужна какая-то общая база? Чем это вообще отличается от Википедии? Чем эти Викиданные так удобны? Разберёмся в этой статье.
Систематизация в Wikidata
Давайте посмотрим, как выглядит обычная страница в Википедии:
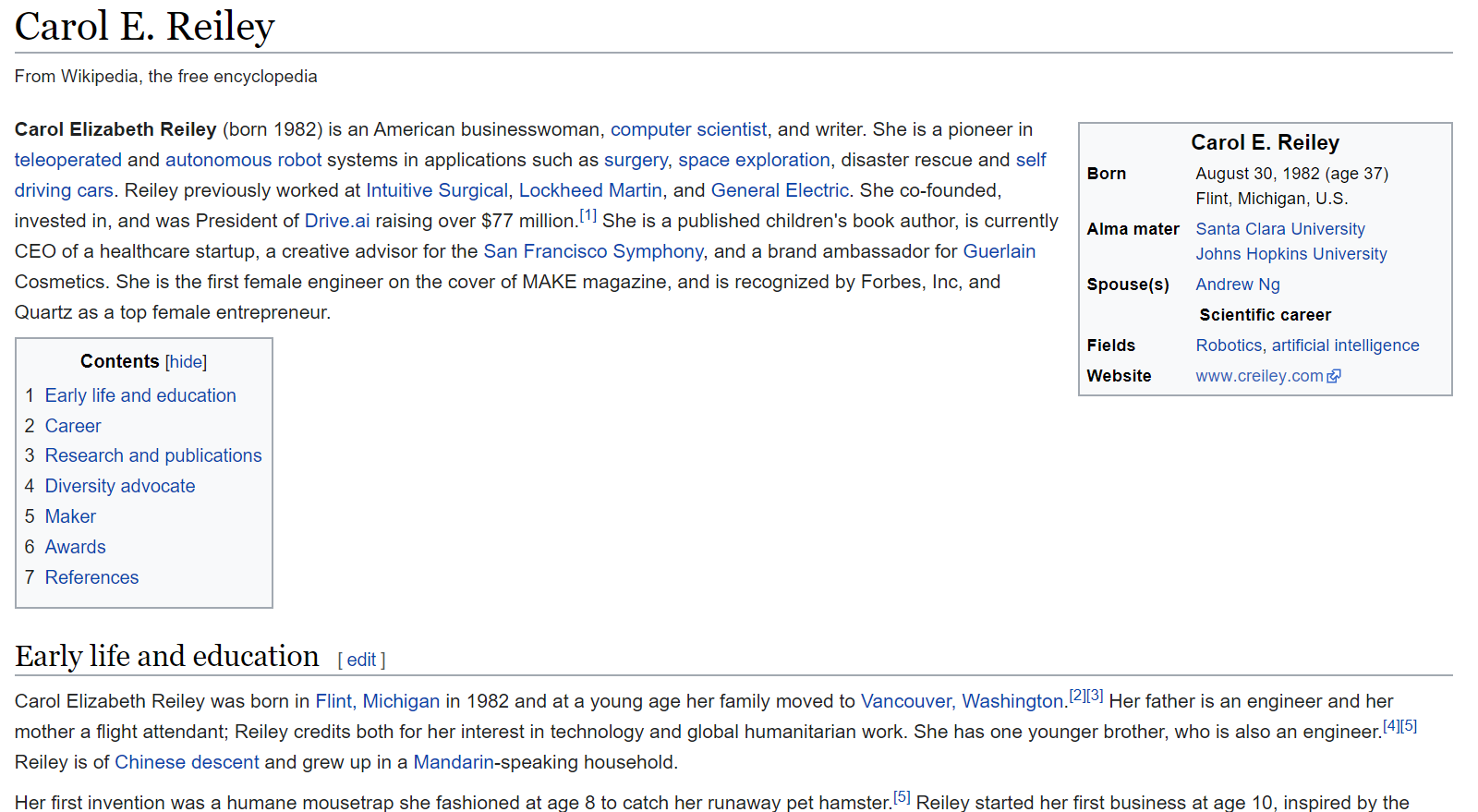
А теперь — как в Викиданных:
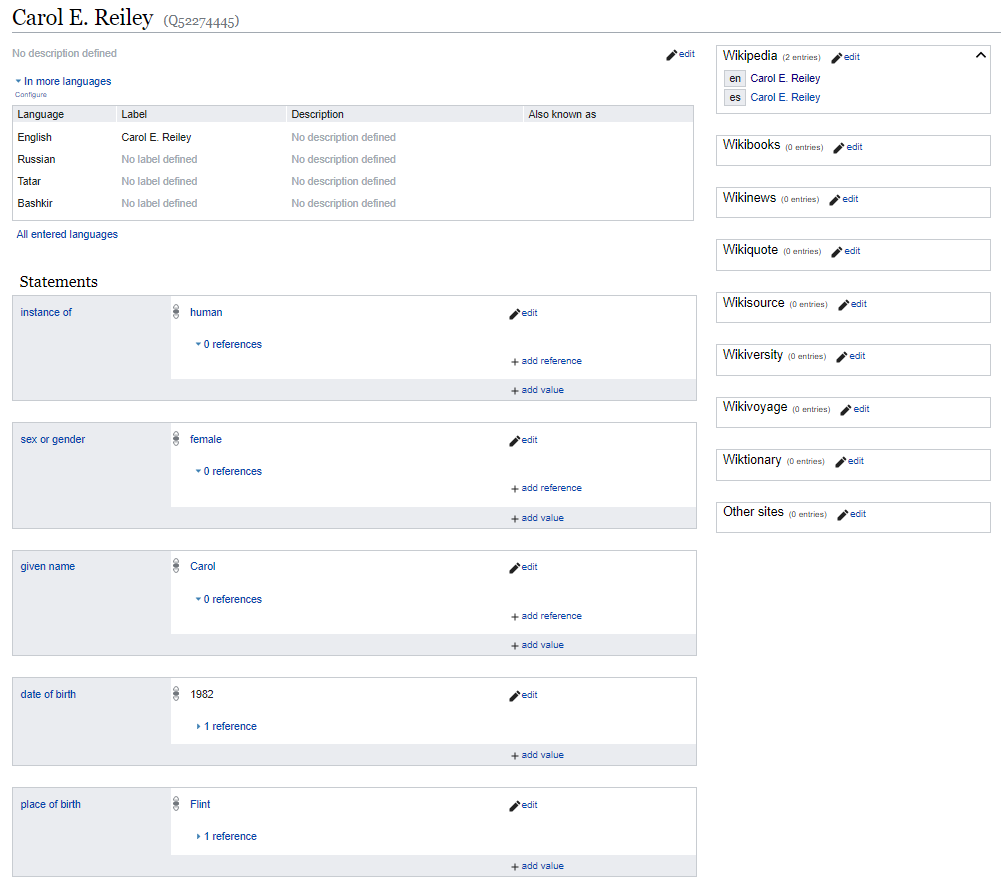
Викиданные кажутся более организованными — хотя бы визуально. Вместо длинного текста основная информация вынесена в таблицы.
Конечно, когда в три часа ночи нужно утолить праздный интерес, не имеет значения, в каком формате представлены данные. Гораздо сложнее работать с большим и слабо структурированным текстом, когда исследование масштабное и серьёзное, а объём информации — вовсе не одна статья.
Представьте, что вы хотите сделать маленькое исследование, посвящённое названию городов. Или написать тред в твиттере обо всех программистках — при стандартном использовании Википедии (или других ресурсов) для этого понадобится найти список всех программисток, просмотреть страницу каждой из них, выписать оттуда даты, достижения или ещё какую-нибудь информацию. При использовании Викиданных вам нужно всего три вещи: лёгкое понимание, как работают Викиданные (которые вы приобретёте к концу этой статьи), и названия двух «свойств» — sex or gender (пол или гендер) и occupation (род деятельности), или statements. Каждый statement строится по модели субъект > свойство > значение, и значением, как и в Википедии, может быть другой объект. Посмотрим:
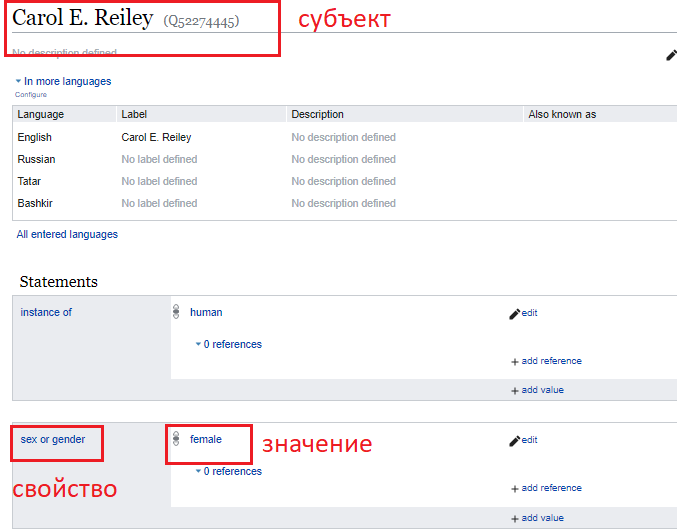
Для поиска мы задаём значения свойств, а результат поиска — список страниц каждой из программисток (страница одной из них будет называться item). Вы сами можете настраивать, какие из других её свойств (например, date of birth) необходимо отобразить, об этом — ниже.
Как пользоваться Wikidata
Теперь перейдём к реализации нашей задачи. Для этого нужно открыть специальный поисковик https://query.wikidata.org/ или послать туда запрос через wikidatapi или pywikibot (как видно из названия, это интерфейс для Python). Давайте воспользуемся первым вариантом. Перед нами такая страница:
Язык SPARQL
Как видим, запрос от нас требуется на SPARQL — специальном языке запросов, который использует Wikidata (и многие другие базы знаний, восходящие к идее «семантического веба»). Мы можем написать запрос сами или выбрать один из примеров (вкладка «Примеры» сверху) и отредактировать его для себя.
Разберёмся, как выглядит стандартный запрос, а потом попробуем составить свой. Код состоит из двух частей: template, который описывает запрос в целом (какие переменные искать), выбирать из всех или только определённые — например «самый большой», и variables — в них помещаются сами значения переменных, которые надо искать, а после этого мы можем настроить, что именно будет выводиться как результат.

Где учиться и искать примеры
Кратко почитать про запросы от самих Викиданных через помощник (о котором мы поговорим позже) можно здесь, а более подробно — здесь. Лучше всего учиться писать SPARQL-запросы по примерам — их можно найти во множестве на странице Wikidata:SPARQL query service/queries/examplesу.
Можно пользоваться шпаргалкой.
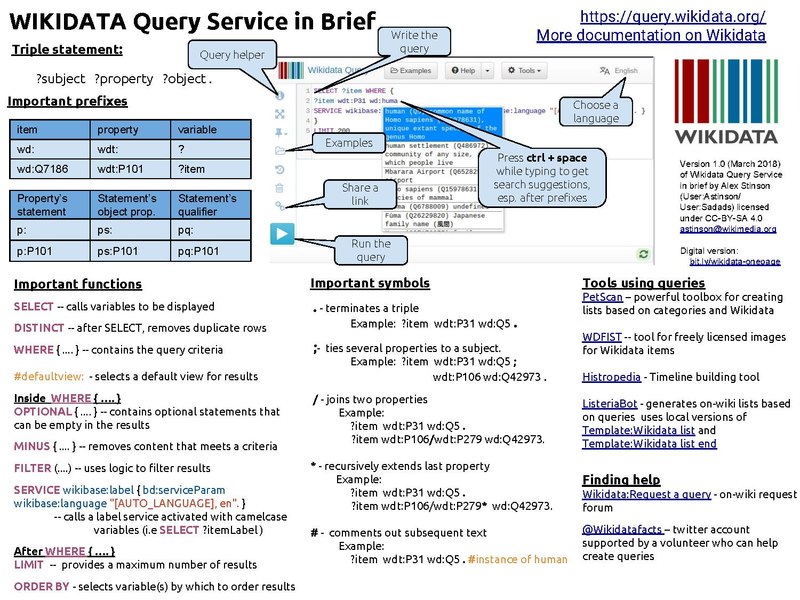
На этой картинке у каждого типа данных (item-statement) есть свои обозначения, и каждому значению присвоен свой код.
На самом деле, совсем не обязательно запоминать все функции и буквы самостоятельно, в Викиданные встроен помощник по запросам (значок i в правом меню), где мы можем на любом языке (доступном в Викиданных, русский — один из таких) сформировать наш запрос.
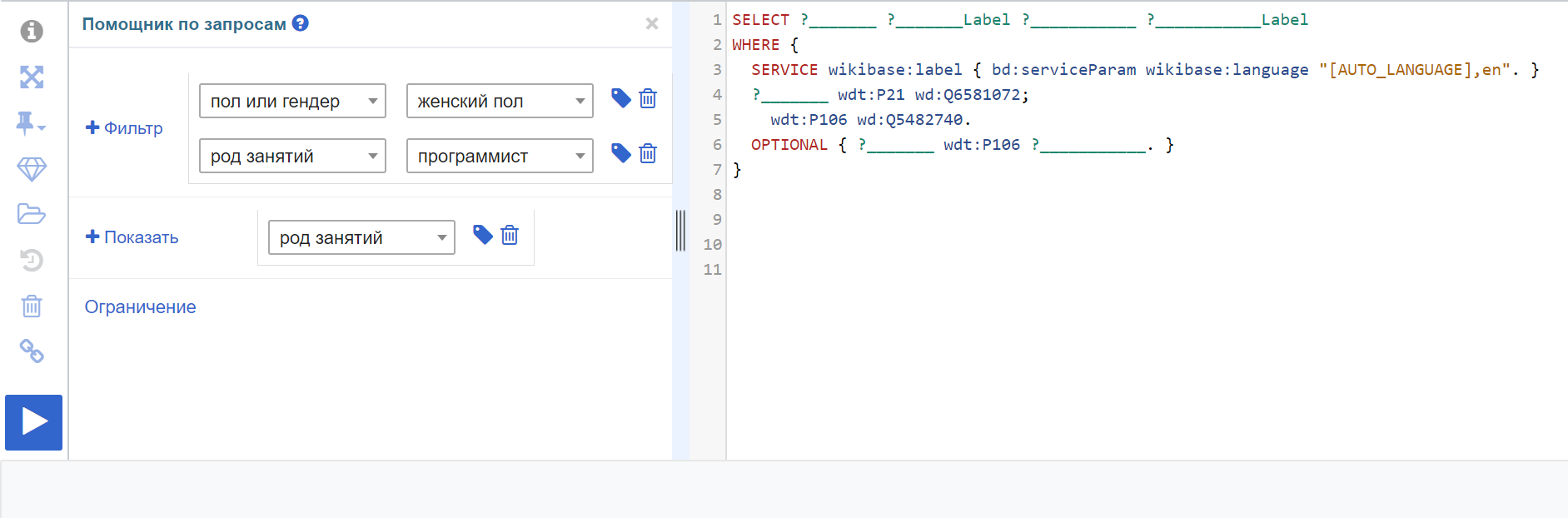
Не забывайте нажать на кнопку компиляции. Если результатов 0, не расстраивайтесь сразу, попробуйте ещё: возможно, вы выбрали не ту категорию (например, «женщины» вместо «женский пол»).
SPARQL и ChatGPT
Ещё, конечно, писать SPARQL-запросы умеет ChatGPT и подобные ей большие языковые модели. Эти модели иногда галлюцинируют и выдумывают несуществующие wikidata-идентификаторы для классов и объектов, но сам синтаксис запроса им обычно удаётся хорошо — приходится лишь поправить несколько конкретных ID. Вот пример генерации SPARQL-запроса в ChatGPT: мы попросили выдать всех женщин-программисток, рождённых после 1950 года.

Этот запрос ChatGPT написала без очевидных ошибок, он работает и действительно выдает ожидаемый результат.
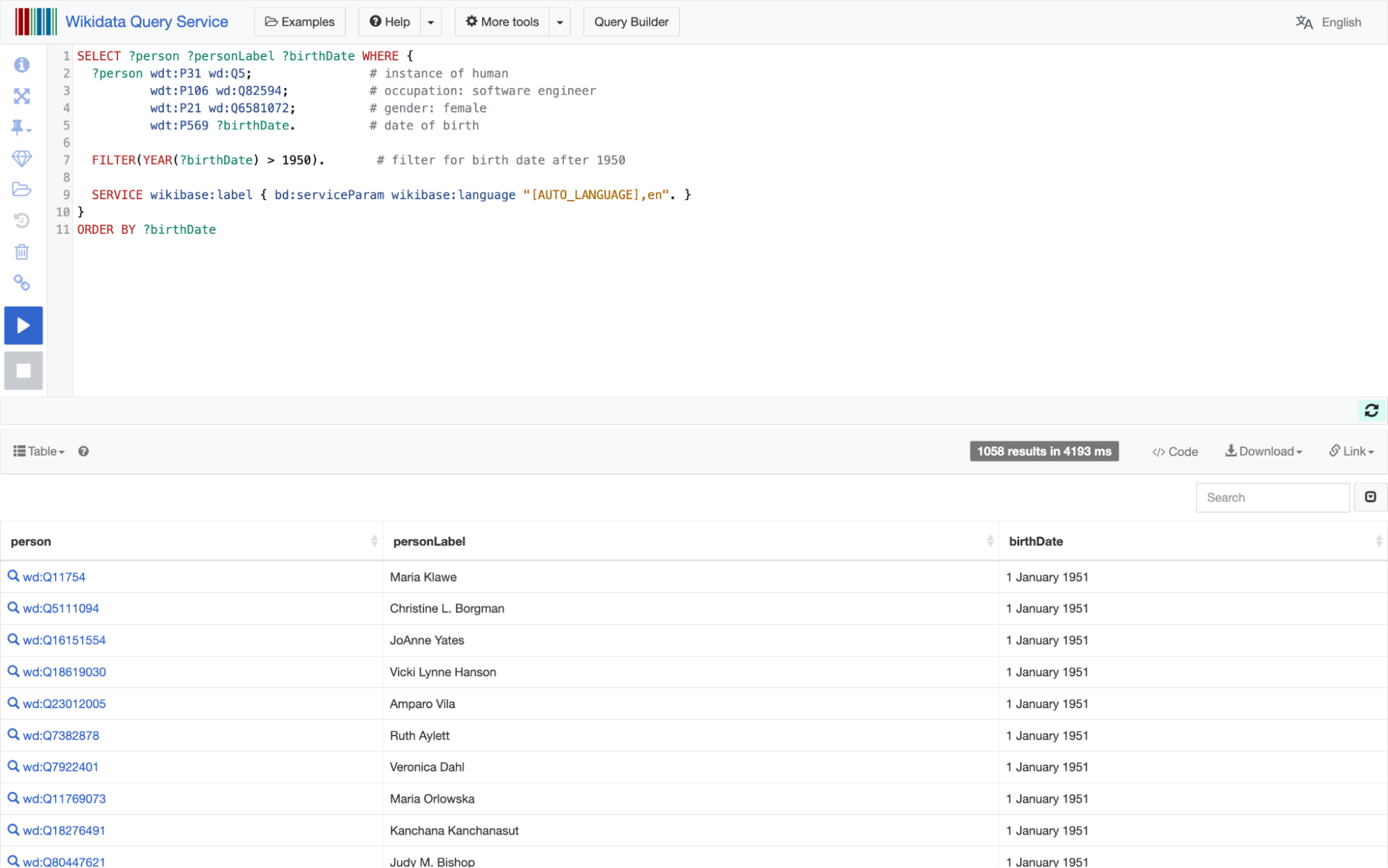
Выдача результатов SPARQL-запроса
Посмотрим на результаты, предварительно настроив отображение рода деятельности в «Показать». По два столбца, первые из которых — item, то есть аналог персональной вики-страницы женщины, вторые — значение statement, двадцать женщин-программистов, но, как мы видим, среди них не только программистки, ещё и преподавательницы и даже поэтессы. Такое происходит из-за того, что среди занятий указано не только programmer: возможно, их образование связано с технической специальностью.
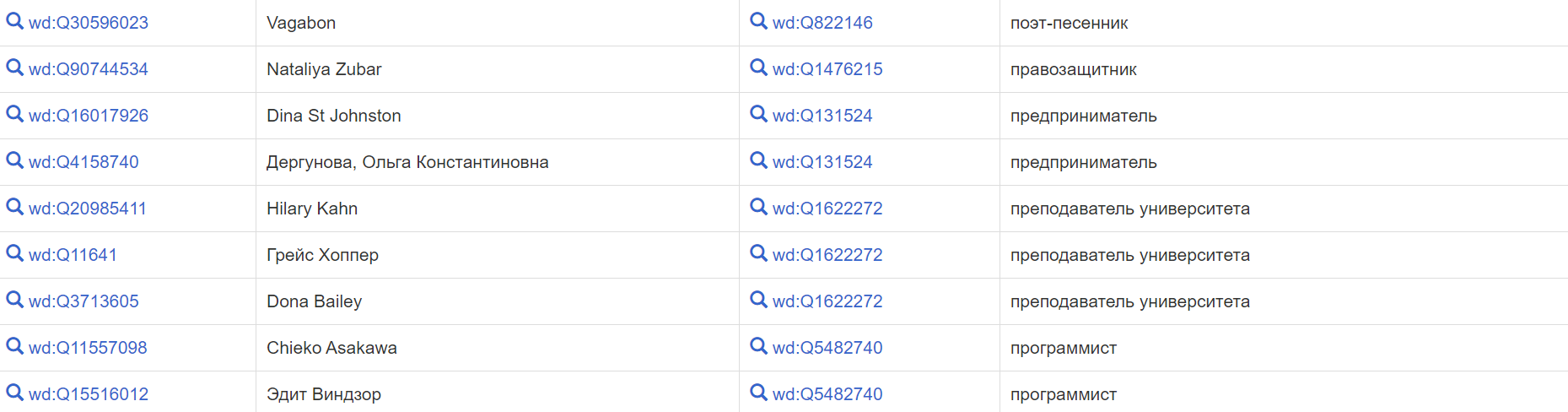
Теперь попросим выводить результаты с фотографиями: «Показать»/show — image, а затем найдем image grid в выборе просмотра (иконка с глазом, при смене просматриваемого, соответственно, меняется):
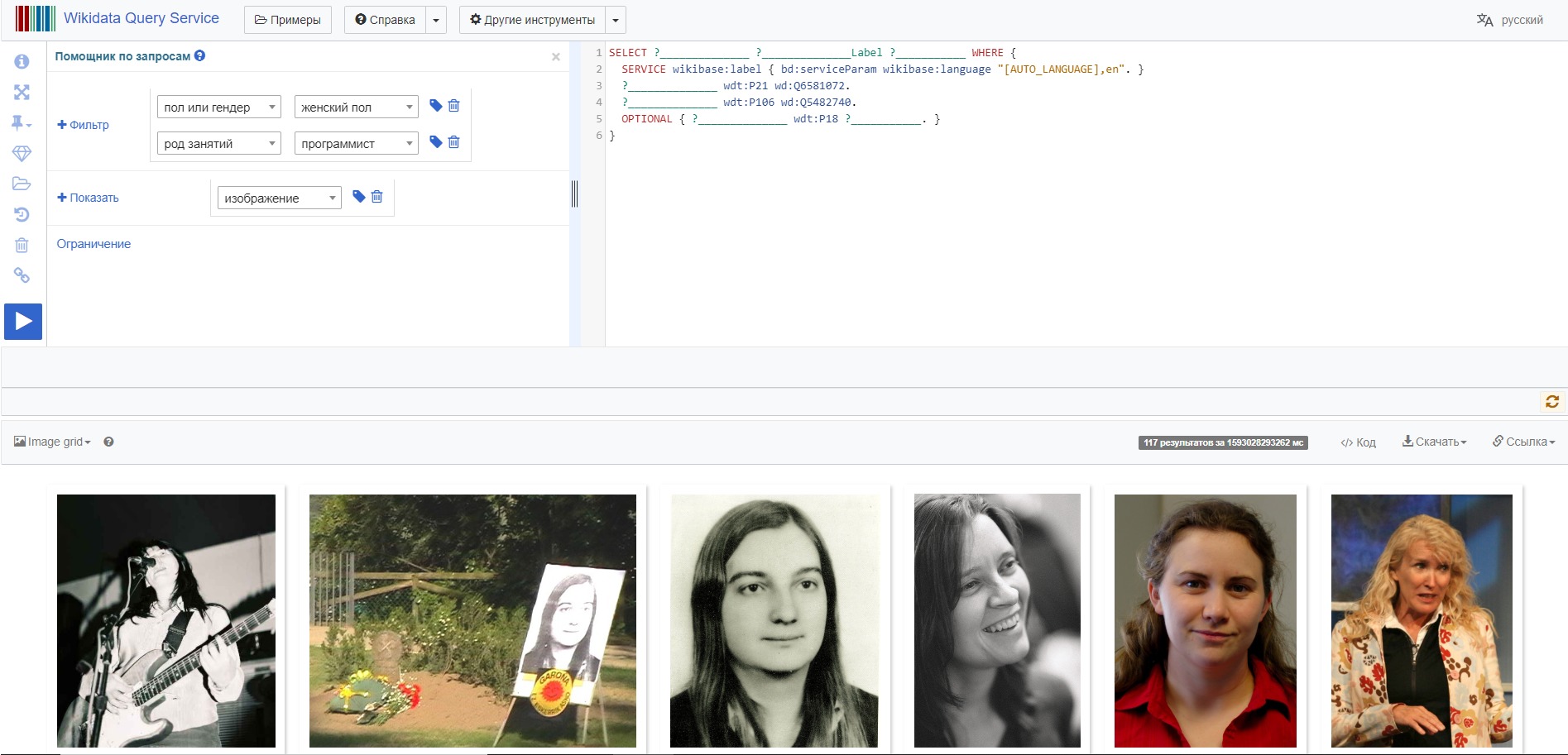
Любые результаты мы можем сохранить в один из представленных форматов, в том числе и в json (с которым весьма удобно работать в Python):
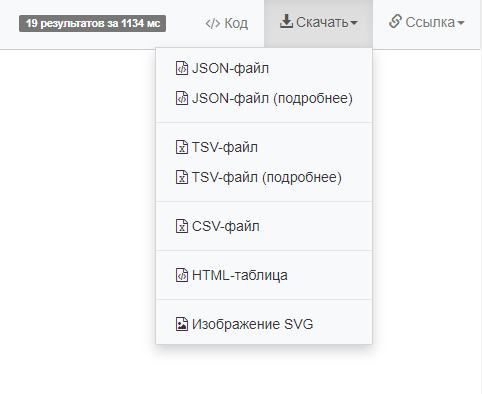
Можно скопировать прямую ссылку на результаты, а можно на запрос (через «код») в формате языка программирования (их на выбор тоже немало):
Наконец, при желании (и доступном типе данных) можно построить граф (собственный конструктор) или диаграмму (их множество разных типов) прямо там. Вот, например, tree map населения Европы по странам в 1960 г.:

А вот тут и тут можно найти реальные исследования, основанные на Викиданных.

