
Предварительное замечание: ни издание «Системный Блокъ», ни автор статьи не аффилированы с какими-либо СМИ, тексты которых стали материалом для данного корпусного исследования. При этом мы подчёркиваем, что анализировались не столько тексты, сколько декомпозированные множества слов и словосочетаний. Статья не содержит ни одной прямой цитаты и/или ссылки на материалы каких-либо нежелательных организаций.
Главный канон журналистики — объективность. Но даже самое беспристрастное медиа выражает себя через текст и формирует собственный дискурс. Например, разной длиной новости, структурой предложений, а главное, выбором или невыбором определённых слов. Перефразируя известную цитату британского языковеда Джона Руперта Фёрса — «Слово можно узнать по его окружению» (англ. You shall know the word by the company it keeps), — мы можем сказать, что СМИ можно узнать по используемым словам (англ. You shall know the media by the words they use).
Вы, наверное, могли заметить, что российские СМИ в последние годы разделились на две категории. Одну из них можно условно назвать «официальными», «государственными» или «провластными». Другая — это необходимый в любом обществе (но невозможный при некоторых политических режимах) кластер независимых СМИ.
Что происходит с этими СМИ в России — вопрос, который выходит за рамки нашего материала. Однако мы утверждаем, что они всё ещё существуют. В данной статье мы будем называть их «либеральными», а также «альтернативными» — имея в виду, что в большинстве случаев они выражают точку зрения, альтернативную риторике властей.
Исследование «на минималках»
Отказавшись от амбициозной задачи проанализировать весь ландшафт российских СМИ в период с августа 2020 до августа 2023 (т. е. полтора года до 24 февраля 2022 и полтора года после), мы решили выбрать и сравнить между собой одно государственное и одно либеральное медиа. При этом было важно, чтобы оба СМИ:
- действовали в масштабах всей страны (поэтому не подходили региональные издания);
- публиковали новости примерно с равной частотой;
- имели сопоставимую среднюю длину сообщения (чтобы не сравнивать лонгриды с твитами);
- освещали похожий круг явлений (т. е. помимо событий, которые были в центре внимания последние полтора года, в обоих СМИ присутствуют упоминания землетрясения в Турции, крупных происшествий в городах России, спортивных соревнований и т. д.).
Поскольку важный для нас период составил примерно 18 месяцев (за точку отсчёта мы взяли 24 февраля 2022 года), нам показалось интересным отложить такой же «отрезок» на временной оси в обратную сторону и взять публикации этих же СМИ за полтора года «до» — начиная с августа 2020 года. Таким образом, у нас получились четыре датасета, которые мы случайным образом (не имея в виду ничего конкретного) обозначили как ria_before, ria_after, mdz_before, mdz_after.
Наш подход можно отнести к методике «дальнего чтения»: не читая все тексты корпусов, мы попытались количественными методами выделить в них интересные черты. При близком рассмотрении эти черты не видны, но при анализе большого объёма данных становятся заметными.
Сбор и предобработка корпусов
Все четыре корпуса составили примерно 7,5 миллионов слов. Однако их распределение неравномерно. После февраля 2022 года провластное медиа выпустило меньше новостей, чем за то же время «до», хотя средняя длина новости немного возросла. Альтернативное СМИ, наоборот, опубликовало в два раза больше новостей и почти в три раза больше текста по сравнению с первым периодом (наименьший датасет). В итоге этот корпус стал самым объёмным — 2,8 млн слов (и было бы ещё больше, если бы мы не очистили каждый пост от одной обязательной надписи, которую вы наверняка хорошо знаете). Количественный состав корпусов хорошо виден на иллюстрации:
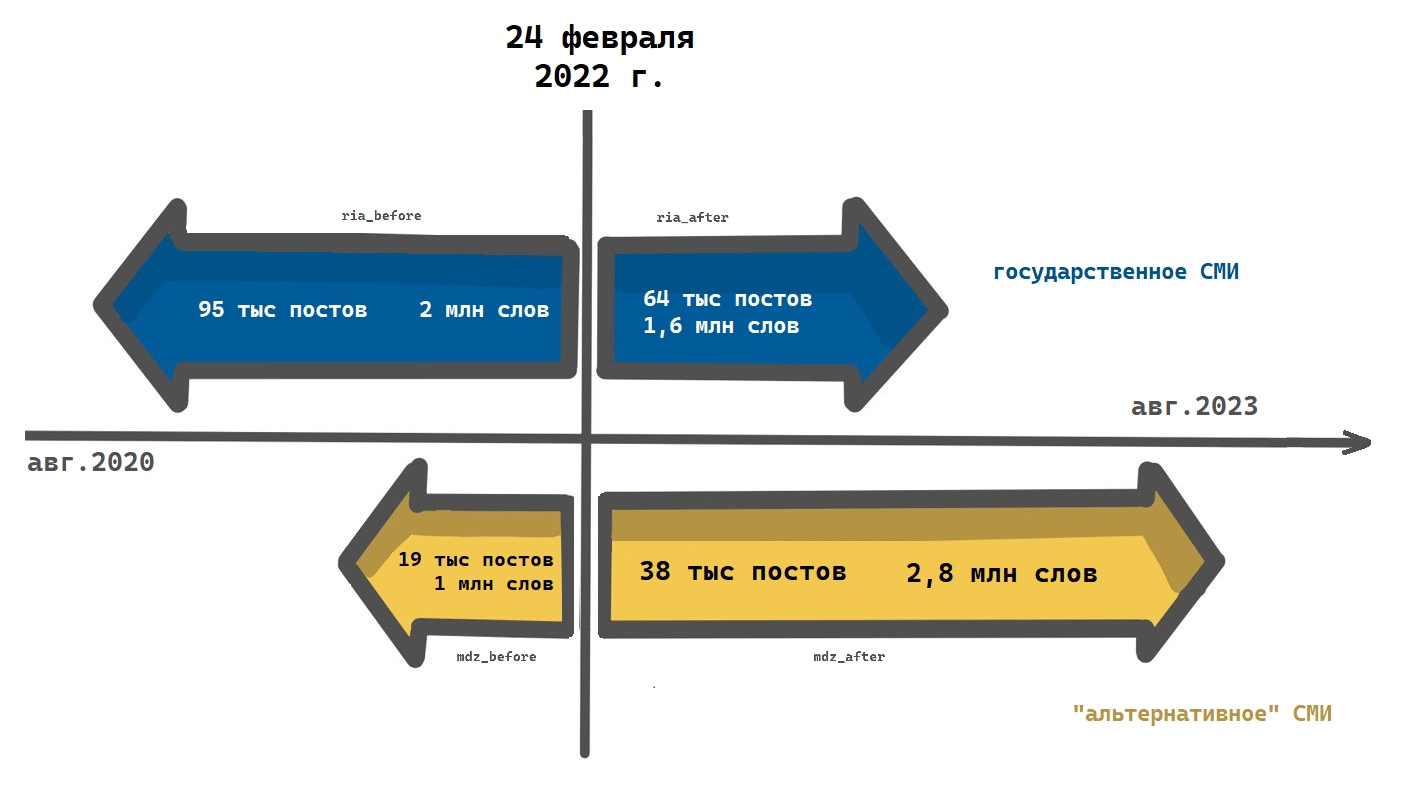
Все четыре корпуса мы получили путём выгрузки json-файлов из соответствующих телеграм-каналов (Telegram позволяет делать это свободно). Затем провели очистку каждого из корпусов:
• с помощью средств pandas сократили датасеты до csv-файлов с тремя колонками: id сообщения, дата (в формате datetime) и текст (одна новость — одна строка в csv-файле);
• удалили лишнюю разметку, дубликаты и пустые строки.
Затем провели лингвистическую обработку, записывая данные в файлы txt:
• перевели тексты в нижний регистр функцией .lower();
• удалили цифры, знаки препинания и латиницу с помощью регулярных выражений;
• удалили стоп-слова, воспользовавшись библиотекой nltk и добавив несколько служебных слов, которые не входят в nltk.corpus stopwords;
• выполнили лемматизацию (т.е. привели словоформу к лемме — начальной форме слова) с помощью библиотеки pymystem;
• для каждого лемматизированного корпуса создали отдельный файл с леммами и фразами, воспользовавшись функцией word2phrases библиотеки word2vec. Данная функция объединяет частотные биграммы в одну фразу: например, ‘вооруженный_сила’ или ‘санкция_против’.
После этого можно было переходить к первой части исследования — составлению модели bag-of-words с помощью python-класса Counter. Мы добавили в список индексы (позицию в списке встречаемости по убыванию) и частотные биграммы из word2phrases. Это позволило получить более адекватную картину распределения токенов.
Результат для каждого корпуса выглядит примерно так:
(891, ‘протест’, 337)
(892, ‘санкт_петербург’, 337)
(893, ‘специальный_военный’, 336)
(894, ‘угрожать’, 336)
(895, ‘запорожский’, 335)
(896, ‘платформа’, 335)
(897, ‘журналистка’, 334)
(898, ‘интерес’, 334)
(899, ‘метр’, 334)
(900, ‘склад’, 334)
(901, ‘вертолет’, 333)
(902, ‘должность’, 333)
(903, ‘коллега’, 333)
(904, ‘контракт’, 333)
(905, ‘округ’, 333)
(906, ‘столица’, 333)
(907, ‘возбуждать_уголовный’, 332)
(908, ‘задача’, 332)
(909, ‘задержанный’, 332)
Фрагмент результата
Первый элемент каждого кортежа — это «рейтинг» частотности, а третий — абсолютная частота в конкретном корпусе.
Первые результаты: приготовьтесь сказать «Спасибо, кэп!»
Посмотрим на 25 самых частотных слов, начиная с 24 февраля 2022 года, и сравним результаты для провластного и либерального медиа. В таблице они расположены по убыванию, справа указана абсолютная частота в каждом корпусе.

Оранжевым цветом мы выделили слова, уникальные для каждого из списков. Одной из строк было название самого СМИ (у госмедиа оно занимало шестое место), её мы удалили в целях анонимизации. Стрелка вверх или вниз указывает, что слово находится более чем на три пункта выше/ниже, чем в другом списке.
Из всех слов, выделенных оранжевым цветом, в каждой колонке есть только одно слово, которое не попало ни в «топ-25», ни в «топ-250» корпуса-«конкурента». Для первого списка это «МИД».
Первый и, пожалуй, самый очевидный результат, который мы получили, заключается в том, что корпусы обоих медиа содержат очень большой процент совпадающих токенов. Кроме того, выбранное нами либеральное медиа часто цитирует официальное: даже само название исследуемого провластного СМИ встретилось за полтора года более 1000 раз.
Но в обратную сторону почему-то «не работает»: госмедиа упоминает изучаемое нами либеральное СМИ всего семь раз и не как источник информации. Однако даже «одностороннее» взаимное цитирование приводит к смешению состава корпусов.
Границы языка есть границы мира?
Чем больше совпадает состав корпусов, тем важнее различия в частотности и сочетаемости определённых слов. Эти различия показывают, какие явления и события в большей или меньшей степени формируют картину мира читателей каждого медиа. Как говорил один из героев «Generation “П”»: «В наше время люди узнают о том, что они думают, по телевизору». Эта цитата актуальна и сегодня, с поправкой на то, что для многих телевизор сменился новостными интернет-изданиями.
Мы утверждаем, что особенно важно посмотреть на нулевое употребление в выборках, по сравнению с сопоставимыми датасетами. В отличие от низкой частотности нулевая встречаемость говорит о полном отрицании какого-либо явления и исключении его из дискурса (особенно на фоне нормальной частоты в других корпусах). Поэтому важно найти слова, которые отсутствуют в конкретных датасетах: как в «либеральном», так и в «официальном», а также слова, которые раньше упоминались, а затем полностью исчезли из новостной повестки — для этого понадобятся корпуса «до».
Напишем две несложные функции на python для сравнения двух корпусов и поиска уникальных лемм и биграмм (для выделения биграмм используется модуль nltk и соответствующая функция: from nltk.util import ngrams). Приведём некоторые из токенов, уникальные для либерального медиа (корпус после февраля 2022, частота не ниже 5 токенов на миллион, в порядке убывания частотности).
Итак, читатели провластного СМИ ни разу за полтора года не прочитали следующие слова, фамилии и фразы:
Униграммы: [‘оккупационный’, ‘шизо’, ‘шахед’, ‘политзаключенный’, ‘провластный’, ‘скочиленко’, ‘спецприемник’, ‘авторитарный’, ‘режиссерка’, ‘сталинский’, ‘немцов’, ‘боинг’, ‘наемничество’, ‘путинизм’, ‘агора’, ‘гордеева’, ‘новояз’, ‘гомосексуальность’, ‘феминистский’, ‘автократ’, ‘деоккупированный’, ‘оруэлл’, ‘антиутопия’, ‘карцер’, ‘интеллигенция’];
Биграммы: [‘условие_война’, ‘антивоенный_акция’, ‘антивоенный_позиция’, ‘независимый_сми’, ‘правозащитный_проект’, ‘называть_война’, ‘открытый_источник’, ‘погибать_война’, ‘жестокость_насилие’, ‘команда_навальный’, ‘путинский_режим’, ‘антивоенный_высказывание’, ‘штаб_навальный’, ‘написать_донос’, ‘иранский_дрон’, ‘сексуализированный_насилие’, ‘независимый_медиа’, ‘антивоенный_митинг’, ‘депортация_ребенок’, ‘гаага_выдавать’, ‘жопа_президент’];
[‘честный_выборы’, ‘авторка’, ‘постпутинский’, ‘абьюз’] и другие единицы тоже ни разу не встретились в государственном СМИ. Но они реже употреблялись и в либеральном (от 2 до 5 на миллион токенов). В эту же группу отнесём слова и биграммы, которые употребляются в госмедиа, но имеют частоту менее 1 на млн (как правило, одно употребление). При этом в «либеральном» корпусе их в десятки и даже сотни раз больше. Например, [‘овд_инфо’, ‘нет_война’, ‘полномасштабный_вторжение’, ‘против_война’, феминизм’, ‘автократия’, ‘тоталитаризм’].
Теперь выведем слова и фразы, которые употребляются в госмедиа после 24 февраля 2022 года, но не встречаются в альтернативном СМИ (встречаемость выше 5 токенов на миллион, в порядке убывания частоты).
Униграммы: [‘манифестация’, ‘метеобюро’, ‘арктический’, ‘кусковой’, ‘плодоовощной’, ‘гидрометцентр’, ‘противорадарный’, ‘нелегал’, ‘гололедица’, ‘дебошир’, ‘пеплопад’];
Некоторые биграммы: [‘выявлять_заражение’, ‘скончаться_человек’, ‘университет_хопкинс’, ‘заражение_сша’, ‘операция_обстановка’, ‘госпитализировать_сутки’, ‘скончаться_выздоравливать’, ‘заражать_скончаться’, ‘главное_минобороны’, ‘день_спецоперация’, ‘центр_фобос’, ‘уничтожать_боевик’, ‘спецоперация_август’, ‘оон_террористический’, ‘спецоперация_октябрь’, ‘боец_днр’, ‘московский_зоопарк’, ‘мыло_руб’, ‘зерновой_вопрос’, ‘снаряд_натовский’, ‘украинский_урегулирование’, ‘бумага_руб’, ‘гречка_руб’, ‘стратегический_ракетоносец’, ‘солдат_танк’, ‘уничтожать_группа’, ‘район_спецоперация’, ‘провокация_киев’, ‘шеф_пентагон’, ‘запад_заявлять’, ‘стратегический_стабильность’, ‘плодоовощной_продукция’, ‘ликвидировать_украинский’, ‘уничтожать_солдат’, ‘туристический_кешбэк’, ‘запад_наносить’, ‘ядовитый_облако’, ‘накачивать_киев’, ‘недельный_дефляция’].
Трудно поверить, но даже в «новом» датасете самые частотные из них касаются коронавируса. Исследуемое нами государственное медиа публиковало эти данные по 31 декабря 2022 года.
Попробуем также взглянуть на единицы, которые использовались в официальном СМИ с августа 2020 по февраль 2022, но затем полностью исчезли. Вот некоторые из них:
[‘антипрививочник’, ‘провластный’, ‘спецприемник’, ‘конфиденциальность’, ‘немцов’, ‘разбогатеть’, ‘блокчейн’, ‘политзаключенный’], [‘коронавирус_динамика’, ‘ситуация_навальный’, ‘прививка_коронавирус’, ‘отрицательный_пцр’, ‘штаб_навальный’, ‘задерживать_минск’, ‘навальный_сообщать’, ‘эксперт_воз’, ‘вакцинация_спутник’, ‘пункт_вакцинация’, ‘военный_переворот’, ‘несогласованный_митинг’, ‘санкция_навальный’, ‘аппарат_ивл’, защита_навальный’, ‘мосгорсуд_сообщать’, ‘ситуация_мигрант’, ‘англоязычный_соцмедиа’, ‘тур_турция’, ‘умный_голосование’, ‘участие_несанкционированный’, ‘дворец_геленджик’].
Цветом выделены униграммы, которые совпадают с «новым» корпусом либерального СМИ. Интересно, что в «старом» корпусе государственного медиа они ещё встречались.
Почему так важно пополнять и сохранять корпусы
Теперь немного расскажем о языковых явлениях, которые отсутствовали в корпусах «до», но появились «после». Если бы кто-то из нас провёл полтора года в анабиозе или на Марсе, сейчас он бы с изумлением смотрел на сочетания ‘денацификация’, ‘волна_мобилизация’, ‘специальный_военный’, ‘антивоенный_протестный’, ‘дискредитация_армия’, ‘зерновой_сделка’, ‘основатель_чвк’ и многие другие.
Тем не менее набор этих новых для корпуса единиц мгновенно погрузил бы его в безрадостную картину текущей реальности. В этом сила корпусов как отражения языка в каждый момент времени, а значит, и как «среза» меняющихся реалий. Поэтому так важно своевременно и беспристрастно пополнять языковые корпусы, в том числе из новостных СМИ.
Между тем, в Национальный корпус русского языка пока не включены никакие данные после 2021 года, и мы сомневаемся, что там найдётся место «альтернативным» медиа. Поэтому мы призываем читателей по мере сил участвовать в сборе актуальных корпусов, чтобы помочь в сохранении и изучении текстов.
Продолжаем искать отличия
Также мы нашли множество слов и фраз, для которых встречаемость резко — иногда в десятки и даже сотни раз — различна от корпуса к корпусу. Следующая функция, которую мы создали (назовём ее get_difference), сравнивает два корпуса и записывает в файл единицы, максимально далеко отстоящие друг от друга по частотности.
Зададим условие: среди униграмм и биграмм, которые вошли в первые 1000 позиций по встречаемости в том или другом корпусе, выведем такие, которые максимально отстоят друг от друга (не менее чем на 300 пунктов). Для тех, кто захочет проверить, повторить или расширить наше исследование, приведём пример, как может выглядеть код такой функции (в конце статьи дадим ссылки на все упоминаемые скрипты):
Сравним корпус госмедиа и альтернативного СМИ после 24 февраля 2022 года. Как известно, одна картинка лучше тысячи слов (а две — ещё лучше). Поэтому мы объединим полученные списки с ранее найденными уникальными токенами каждого корпуса и на их основе выведем результат в виде «облака слов». Для этого используем matplotlib wordcloud с методом generate_from_frequencies().


Такое ощущение, что на этих визуализациях представлены две совершенно разные языковые реальности. Несмотря на то что большинство токенов в корпусах совпадают, мы выделили и визуализировали важные отличия.
Покажи мне свой контекст
Для быстрого сравнения конкретного слова или биграммы по всем четырём корпусам мы решили создать небольшую функцию «портрет слова». Эта функция выводит частоту какого-либо слова в каждом из четырёх корпусов, а также контекст для одного корпуса, который нам особенно интересен (он передаётся в функцию в качестве аргумента). Всё это будет работать примерно так:
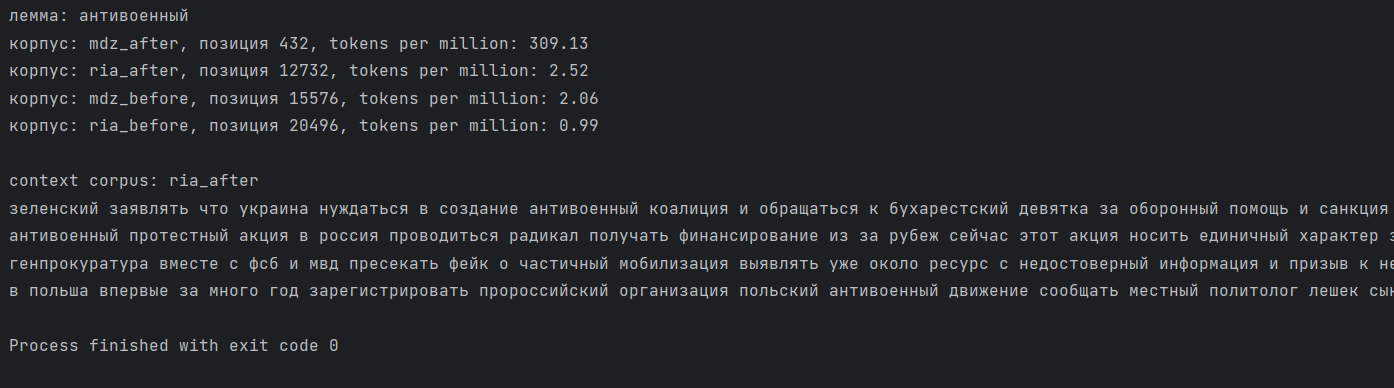
Или так:
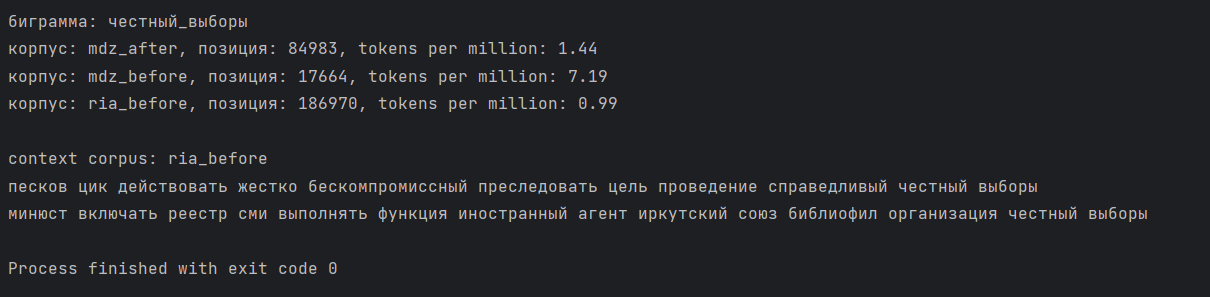
С помощью данной функции, к примеру, можно понять, что после 24 февраля 2022 года в либеральном СМИ (по сравнению с госмедиа) в 5 раз чаще упоминается ‘преследование’, в 4 раза чаще ‘репрессивный’, ‘яшин’, ‘цензура’, в 3 раза чаще ‘дискредитация’.
В тот же период в государственном медиа по сравнению с либеральным в тридцать раз реже упоминается ‘правозащитный_организация’, в четырнадцать раз реже ‘навальный’ (хотя в корпусе «до» упоминалось лишь в четыре раза реже, чем в либеральном), в четыре раза реже ‘свобода’, в три раза реже ‘либеральный’, ‘нко’, ‘гражданский_общество’ и ‘самоуправление’ (последние два понятия в «старых» корпусах представлены одинаково для провластного и альтернативного СМИ), в полтора раза реже ‘мобилизация’.
Зато в четыре раза чаще употребляется ‘рост_экономика’, в три раза чаще ‘высокоточный’ и ‘принимать_закон’, в два раза чаще ‘перспективный’, ‘улучшение’, ‘достижение’, ‘хлопок’. По сравнению с периодом «до» в обоих корпусах в среднем в пять раз чаще упоминается биграмма ‘смертный_казнь’.
Иногда результаты частотности сильно отличаются от ожидаемых. Например, мы предполагаем, что частота некоторых слов и словосочетаний в официальных СМИ будет почти нулевой. Если же эти слова и фразы всё-таки встречаются в госмедиа, то необходимо смотреть на контекст, в котором они употребляются. Проиллюстрируем на примере биграммы ‘акция_протест’:
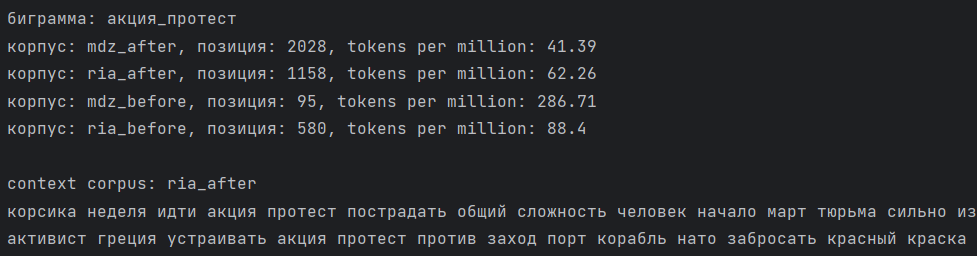
Наибольшее число употреблений этой биграммы мы обнаружили в «либеральном» корпусе с августа 2020 по февраль 2022 года. В современном корпусе альтернативного медиа встречаемость, напротив, оказалась наименьшей: государственное СМИ и «до», и «после» упоминает ‘акция_протест’ чаще. Хотя, казалось бы, должно быть наоборот.
Посмотрим на контекст фразы в провластном медиа и обнаружим, что в мире за этот период проходило множество разнообразных ‘акция_протест’:
• париж накануне первый тур президентский выборы проходить акция протест
• москва здание представительство ес проходить акция протест против антироссийский политика европейский власть
• шествие требование отставка пашинян проходить ереван
• вена проходить акция протест требование снижать цена обеспечивать дома тепло
• акция протест центр рим участник критиковать политика правительство связывать поставка оружие киев санкция против рф
• сотня житель дублин выходить акция протест против размещение украинский беженец
• тбилиси проходить антизападный акция протест
• британия набирать сила антимонархический акция протест главный причина вскрываться последний время
В либеральном медиа эта биграмма отсылает к другим событиям. Эти события перестали происходить ещё в самом начале периода, который охватывает корпус. Значит, упоминаний не может быть так же много, как в провластном СМИ, — этим и объясняется разница в частотности.
Сочетаемость слов хорошо помогает увидеть корпусный инструмент Sketch Engine. Воспользовавшись данным инструментом, мы изучили употребление леммы ‘свобода’ и узнали, что в либеральном СМИ она гораздо чаще используется в словосочетаниях типа «сущ. + сущ в род. п.» в разных вариантах. Помимо «лишения» и «ограничения» также употребляется «подавление свободы», «защита свободы», «идея свободы» и «ценность свободы».
Наряду со «свободой слова» и «свободой передвижения» упоминается свобода «прессы», «СМИ», «информации», «выражения», «совести». В официальном СМИ большинство этих контекстов отсутствует, однако есть разнообразие глагольных словосочетаний: свободу в госмедиа «приносят», «продвигают», «уважают», «ненавидят», «обретают» и даже «скандируют».
Из примеров видно, что при анализе корпусов ключевую роль играют контекст и сочетаемость. Тем не менее иногда возникает ощущение некоего «зазеркалья». Например, в поисках употребления фразы «права и свободы» в госмедиа встречаем: «Роскомнадзор объявил о начале ограничения доступа к Facebook [запрещён в РФ] — он признан причастным к нарушению прав и свобод россиян» (внимательный читатель заметит неразрешённую синтаксическую неоднозначность местоимения «он»).
Зачем всё это?

Это граффити на несколько часов появилось в Комсомольске-на-Амуре 26 апреля 2022 года. Художник изобразил экран метафорического компьютера, где в «Загрузках» можно увидеть, среди прочего, «Военную операцию», «Тоталитаризм», «Пропаганду» и «Репрессии», а в «Удалённых» — «Счастливое будущее», «Гражданские права», «Свободу слова» и «Честные выборы». Это немного напоминает результаты, которые мы получили, сравнив корпусы СМИ.
Может показаться, что в российских СМИ происходит примерно то же, что и на этой картинке. Этому способствует цензура, самоцензура и, конечно, последовательное закрытие и лишение легальности независимых медиа. Поэтому важно обращать внимание на такую «отмену понятий» и доказывать её количественными методами.
В этот материал, конечно, поместились не все «находки». Некоторые из них мы не можем опубликовать по юридическим причинам (например, вы могли заметить, что цитаты постов приводятся только из государственного медиа).
Если вы хотите повторить, дополнить или опровергнуть наши выводы, но не хотите писать код, то можете воспользоваться нашими заготовками. Мы выложили в открытый доступ код скрипта для предобработки данных, выгруженных из телеграм-каналов (возможно, его придется немного изменить, если ваши данные имеют другую структуру). Там же вы найдёте код функций на python, которые упоминаются в статье.
Помимо скриптов на python можно воспользоваться корпусным менеджером Sketch Engine, если у вас есть к нему доступ (мы подробно писали о нём здесь). Для работы с корпусами такого большого объёма, как в нашем исследовании (7,5 млн слов), в режиме академического доступа, а именно в нём работают все важные функции, нужно оплатить стоимость подписки 16,5 евро в месяц.
Также напоминаем, что хранение и тем более распространение датасетов, содержащих тексты некоторых СМИ, может быть признано незаконным. Будьте осторожны и берегите себя.

