Что такое именные группы и какие они бывают
Когда мы говорим, то произносим слова, которые так или иначе соотносятся с объектами реального мира. Начнем с того, какие бывают отношения между именной группой (ИГ) — грубо говоря, существительным и его зависимыми (Вася; красивый мальчик; забор с дырой посередине; дом, который построил Джек), — и тем, что она означает.
Лингвисты делят именные группы на определенные и неопределенные (здесь и далее используется перевод англоязычной терминологии; в русскоязычной литературе для описания референтности обычно используются другие термины [1]). Именная группа называется определенной, если слушатель знает или может восстановить из контекста, какой конкретно объект реальности она называет. Самый известный язык, грамматически различающий определенность, — английский, который использует неопределенный артикль a/an и определенный the.
Когда мы говорим по-английски Denis won a pool game; the game was easy (Денис выиграл партию в бильярд; эта партия была простой) — мы сначала знакомим адресата с именной группой pool game в контексте ситуации, а далее, уже зная, что адресат поймет, о какой партии идет речь, мы говорим the game. По сходной логике мы говорим the Earth (Земля) — она по определению единственна и отличать ее не от чего.

В то же время, именные группы бывают специфичными и неспецифичными. Именная группа называется специфичной, если явление действительности, которое она называет, в заданном контексте уникально определимо: другими словами, если в него можно «ткнуть пальцем».
Рассмотрим несколько примеров. Представьте, что вы подходите к охраннику в торговом центре. Вы обращаетесь к нему с одной из трех фраз:
- К вам только что заходили трое мужчин — я ищу высокого блондина. Вы не знаете, куда он дальше пошел? (ИГ высокий блондин — определенная, специфичная).
- Я ищу одного высокого блондина. Он, кажется, украл сумку и пять минут назад отсюда ушел. Можете посмотреть по камерам куда? (ИГ один высокий блондин специфичная, но не определенная: человек имеется в виду вполне конкретный, но слушатель не может из контекста восстановить, кто именно).
- Я ищу высокого блондина для съемок в новой рекламе — мне кажется, вы подходите, вот моя визитка (неопределенная неспецифичная).

Еще один пример. Представьте, что ваш друг ищет книгу. Он говорит:
- Я ищу книгу Маршака 1938 года издания… читал ее в детстве (ИГ книга Маршака […] — определенная и специфичная).
- Я ищу одну книгу… читал ее в детстве, там было про зверей (ИГ одна книга — специфичная, но не определенная: слушатель не может восстановить конкретную книгу из контекста).
- Я ищу хорошую книгу… чтоб объяснила моим детям, что такое хорошо (ИГ хорошая книга — неопределенная и неспецифичная).
Тестом на специфичность является, например, возможность употребить после ИГ личное местоимение, обозначающее ту же вещь, которую обозначала ИГ: пара предложений Женя вызовет нам такси. Оно серое звучит странно, поскольку Женя вызывает не конкретный единственный автомобиль по заказу, а какую-то абстрактную машину из множества, предоставляемых сервисом. Таким образом, ИГ такси выше неспецифична.
В скольких музеях побывал Артем: больше специфики о специфичности
Специфичность влияет на многое. Испанский различает специфичные и неспецифичные ИГ, используя разные грамматические средства в придаточных предложениях. В языке маори есть артикли têtahi и he для специфичных и неспецифичных употреблений ИГ. Но даже в языке, где формально это никак не различается, как в русском, специфичность — это не просто философское понятие, а тумблер, который меняет возможные прочтения предложения.
Рассмотрим предложение Артем ходит в музей каждую неделю. Первое прочтение, которое может прийти в голову, — это, скорее всего, «Каждую неделю Артем ходит в разные музеи». Однако при специфичном прочтении ИГ музей это предложение также может значить: «Каждую неделю Артем ходит в один и тот же музей» (например, у него там стажировка).

Два прочтения для фразы «Артем ходит в музей каждую неделю» с разной специфичностью именной группы «музей»
Условные придаточные также создают особый контекст для того, чтобы отметить специфичность. Предложение Если бы моя подруга приехала из Германии, я был бы рад можно произнести, имея в виду конкретную подругу из Германии, но оно также может быть произнесено при обсуждении гипотетической ситуации: например, когда у говорящего вообще нет подруги из Германии, но он удивляется, что его собеседник в аналогичной ситуации не прыгает до потолка.
Больше неопределенности: именные группы с неопределенными местоимениями
В роли ИГ могут выступать не только существительные, но и местоимения. Наверняка, большинство читателей слышало в школе в том или ином виде правило о написании кое-, -либо, -то и -нибудь через дефис с их основой. Именно такие местоимения, как, например, кое-кто, почему-то, что-либо, где-нибудь традиционно называются неопределенными.
В 1997 году в книге Indefinite pronouns немецкий лингвист Мартин Хаспельмат написал о том, что в разных языках мира неопределенные местоимения выражают разные наборы значений — в том числе те, которые традиционно по-русски неопределенными не называются.

Обложка книги Мартина Хаспельмата Indefinite pronouns
Эта работа представляет собой пример типологического исследования. Лингвистическая типология — область лингвистики, занимающаяся сравнительным изучением языков независимо от их степени родства. Типология часто изучает разнообразие того или иного явления в человеческих языках: как бывает можно, а как уже нельзя.
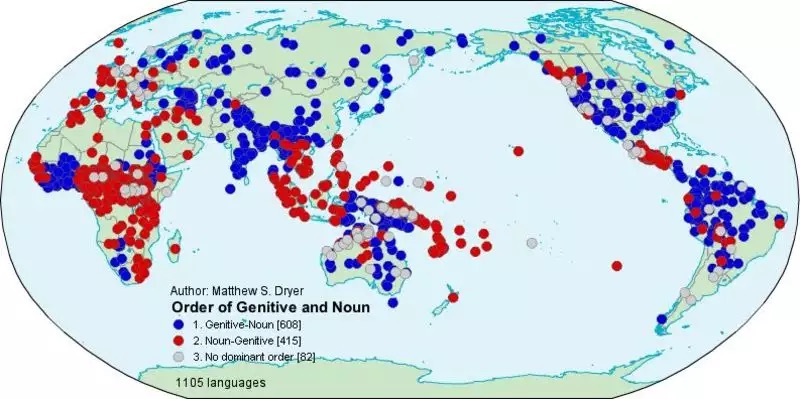
Карта (не семантическая, а обычная географическая) распространения разных вариантов порядка слов в именной группе из существительного и дополнения в генитиве (родительном падеже), напр., «группа студентов». Типичный объект типологического исследования
«Священным Граалем» типологии является нахождение универсалий: характеристик, присущих всем языкам без исключения, или наоборот, чего-то, что ни в одном естественном языке не встречается. Но такое находится крайне редко. Чаще типологи формулируют так называемые импликационные универсалии. Это утверждения вида «Если для языка X верно A, то для него верно B». Чтобы представить такие универсалии наглядно, используются семантические карты.
Что такое семантическая карта
На семантическую карту наносятся те признаки, которые различаются у данного явления в разных языках. Например, если в языке X творительный падеж может обозначать время (работать ночью), среду (идти лесом) и инструмент (копать лопатой), а в языке Y — только время и среду, то на карту будет нанесено значение «инструмент», потому что теперь мы знаем, что оно может отражать минимальное различие между двумя языками.
Те значения, которые больше похожи друг на друга, оказываются на карте ближе друг к другу, а значения с наибольшими различиями оказываются на максимальном расстоянии и визуально. Например, ниже иллюстрация из книги Хаспельмата, где верхние три рисунка — допустимые варианты группировки значений на карте, а нижние два — недопустимые.
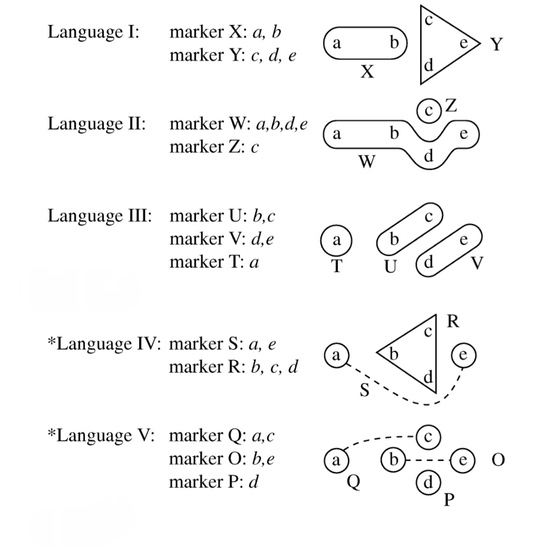
Примеры допустимых и недопустимых группировок на семантической карте. Источник: [2]
Семантические карты — это мощный инструмент для предсказаний: если значения a, b и c расположены на карте в ряд в таком порядке, значит, она утверждает, что ни в одном языке мира не найдется такого показателя, который объединит значения a и c, но не будет при этом выражать значение b.
Карта неопределенных местоимений
Мартин Хаспельмат предложил карту значений неопределенных местоимений. Значения, соединенные отрезком, считаются соседними:
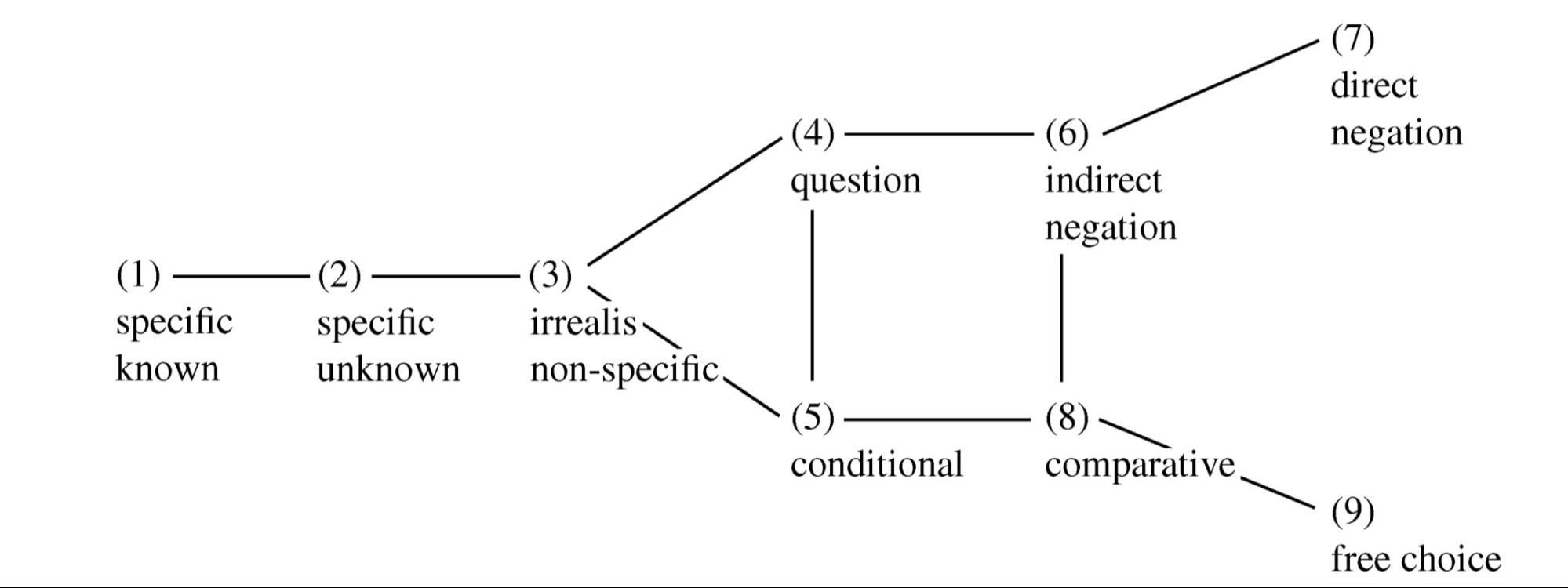
Семантическая карта неопределенных местоимений. Источник: [2]
Пройдемся по каждому из девяти приведенных значений.
1. Specific known (SK) — специфичные, известные говорящему. Пример: Я тебе кое-что купил. Угадай что. Русское кое- маркирует неопределенные местоимения, отсылающие к конкретному объекту реального мира, который говорящий мог бы назвать его именем, но по прагматическим причинам решает так не делать (считает это неважным, играет в игру, приглашает догадаться, назовет дальше…).
2. Specific Unknown (SU) — специфичные, неизвестные говорящему. Пример: Тебя кто-то звал, но я не успел увидеть кто. Такие местоимения отсылают к столь же конкретному объекту, как SK, но говорящий не знает, что именно это за объект.
3. Irrealis non-specific (IR) — ирреальные неспецифичные. Пример: Поиграй во что-нибудь другое. Ирреальными они называются, потому что употребляются в ирреальных контекстах: в будущем времени, повелительном наклонении, пожеланиях, вероятностных утверждениях (с выражениями вроде «может быть», «возможно» и т. п.) — их все объединяет то, что на такие высказывания бессмысленно ответить Это ложь. Собственно, значения (4, 5, 9) на карте — частные случаи неспецифичных контекстов.
4. Question (Q) — этот признак показывает, может ли неопределенное местоимение быть употреблено в вопросе (Ты что-нибудь прочитал за месяц?). Вопросы прагматически очень близки к повелительному наклонению: по сути, вопрос — это просьба предоставить информацию. Это родство можно заметить на письме через вариативность пунктуации (Предложение Давай послушаем что-нибудь по дороге может кончаться и вопросительным, и восклицательным знаком). Неудивительно, что они расположены на карте так близко к IR, выражающемуся, в частности, повелительным наклонением.
5. Conditional (CD) — этот признак показывает, может ли неопределенное местоимение употребляться в условном придаточном предложении. Пример: Если что-нибудь получится, будет хорошо.
6. Indirect negation (IN) — этот признак показывает, может ли неопределенное местоимение употребляться в контекстах непрямого отрицания. Это такое логическое отрицание, которое не выражено никаким показателем собственно отрицания в рамках клаузы. Примеры: Руслан защитил диплом без каких бы то ни было замечаний. Катерина выиграла стипендию в отсутствие каких-либо реальных конкурентов. Возможна также ситуация, в которой показатель отрицания есть — просто не в той же клаузе, что наше неопределенное местоимение, а во внешней. Примеры: [Я не думаю, [что кто-нибудь придет]]. [Нельзя, [чтобы кто-либо остался недоволен]].
7. Direct negation (DN) — этот признак показывает, может ли местоимение использоваться при отрицании в рамках одной с ним клаузы. Примеры: Полковнику никто не пишет. Я не вижу в этом каких-либо проблем.
8. Comparative (CP) — этот признак показывает, может ли местоимение использоваться внутри стандарта сравнения — того, с чем мы что-то сравниваем, — так, чтобы значение было похоже на «чем все». Примеры: Он играет лучше, чем кто бы то ни было. Он сдает задачи быстрее, чем кто-либо на занятии успевает открыть рот.
9. Free choice (FC) — местоимения свободного выбора. Пример: Ты можешь гулять сколько угодно. Любой студент это знает.
Рассмотрим, как выглядит, по версии Хаспельмата, карта показателей неопределенности для местоимений русского языка. Карта не совсем полная: например, нет серии местоимений на не- (некто, нечто), а -либо не покрывает прямое отрицание, но такие частные неточности, к сожалению, являются распространенной проблемой в типологической работе — сложно учесть все при работе с десятками языков.
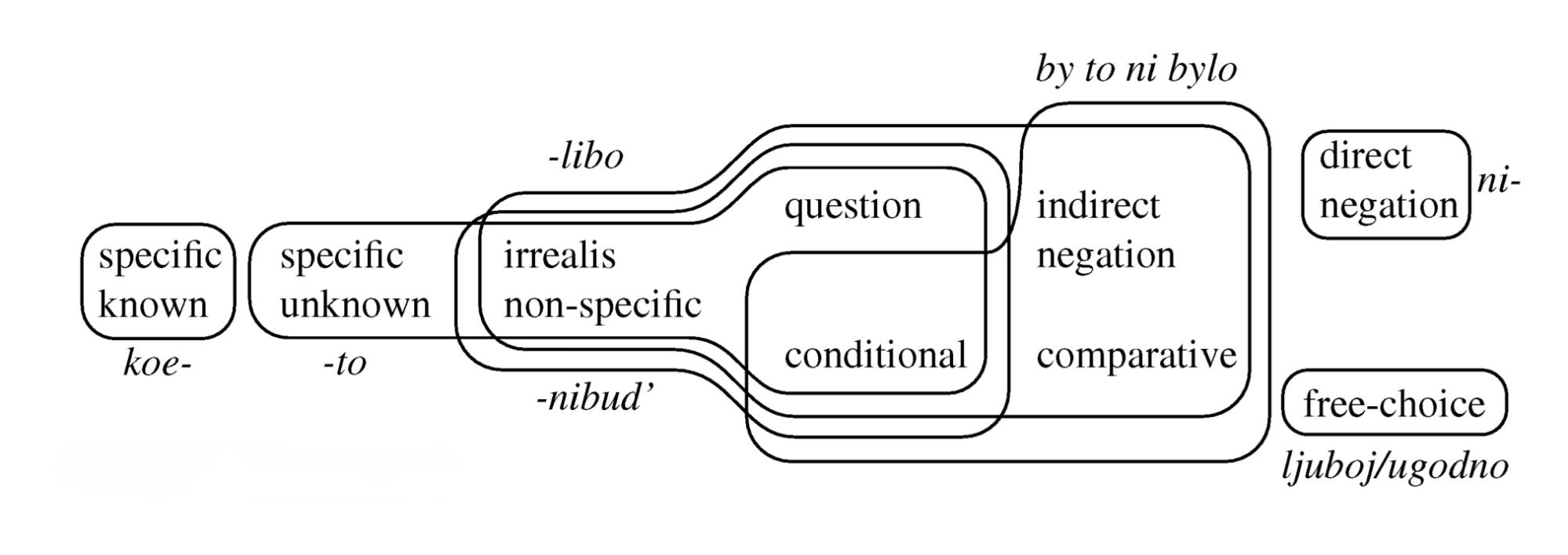
Система неопределенных местоимений русского языка. Источник: [2]
Помимо выделенных Хаспельматом зон, на употребление неопределенных местоимений влияют и другие факторы. Один из интереснейших примеров — ожидания говорящего от ответа на задаваемый им вопрос. Сравним: местоимения что-то и что-нибудь в целом прекрасно употребляются в русскоязычных вопросах (Я что-то пропустил? Ты купил что-нибудь к чаю?). Но в кабинет к вызвавшему вас начальнику вы зайдете именно со словами Вы что-то хотели? — поскольку это фактически риторический вопрос, на который вы ожидаете получить утвердительный ответ. Так, утвердительные ожидания склоняют нас к маркерам из более «левых» зон на карте, а отрицательные — из более «правых».
Классификация Мартина Хаспельмата, не будучи идеальной или безошибочной, является, однако, фундаментальной: она легла в основу многих дальнейших исследований, в том числе с использованием компьютерных методов. Одно из них, которое мы рассмотрим далее, показывает, почему эта классификация, тем не менее, очень значима.
Зачем нужна модель Хаспельмата: лингвистические эксперименты с неопределенными местоимениями
В современной лингвистике существует идея о том, что естественные языки, как минимум в некоторых областях, стремятся к оптимальности передачи информации, то есть ищут баланс между информативностью сообщения и сложностью понимания этого сообщения слушателем.
В статье 2022 года Милица Денич и ее коллеги рассматривают неопределенные местоимения в системе, основанной на карте М. Хаспельмата, чтобы ответить на вопрос, оптимально ли их использование в естественных языках [3].

Лингвистка Милица Денич. Источник
Системы неопределенных местоимений в языках мира сильно варьируются, но варьирование это неслучайное, поскольку Хаспельмату удалось найти закономерности и построить карту. Не стремление ли к оптимальности тогда движет этой вариативностью и ограничивает ее?
Для начала исследователи модифицируют карту Хаспельмата, сводя его девять видов неопределенных местоимений к шести типам значений (их назвали ароматами, видимо, по аналогии с кварками). Мы не будем углубляться в значения этих ароматов и скажем только, что функции Хаспельмата (1), (2), (3) и (9) переносятся каждая в свой аромат отдельно, а оставшиеся центральные функции (4–8) делятся по определенным правилам между двумя оставшимися ароматами negative polarity и negative indefinite по семантике (поскольку у Хаспельмата это деление было основано на синтаксических контекстах). Читателя, заинтересованного в более подробном описании ароматов или в более формальных определениях сложности и информативности, вводимых далее, и более полной информации о методологии их вычисления, мы направляем к оригинальной статье, приведенной в списке литературы.
Далее они вводят пять бинарных показателей, с помощью которых возможно описать любое сочетание шести ароматов, которые могло бы выражать неопределенное местоимение. Эти пять показателей следующие:
- Известность говорящему (K).
- Специфичность (S).
- Выражение конечной точки шкалы (SE, scalar endpoint) — это используется для описания примеров вроде Мэри может решить любую задачу (то есть, даже самую сложную) и, наоборот, Джон принял мою работу без каких бы то ни было замечаний (то есть, самых мелких), которые вводят шкалы «сложные задачи > средние задачи > легкие задачи» и «серьезные замечания > обычные замечания > мелкие замечания» и выбирают на них крайние, экстремальные значения.
- Выражение переворота шкалы (R, reversal) — подгруппа п. 3, включающая в себя примеры вроде примера про Джона, которые отсылают к самой низкой точке шкалы, а не к самой высокой.
- Отрицательность (N).
Сложность неопределенного маркера c(i) определяется как количество показателей, необходимое для однозначного определения данного маркера.
Сложность языка C(L) (языком в этой статье для краткости называют систему его неопределенных местоимений) в таком случае будет равна сумме сложностей всех неопределенных показателей, в нем присутствующих C(L) = Σic(i), i∊L.
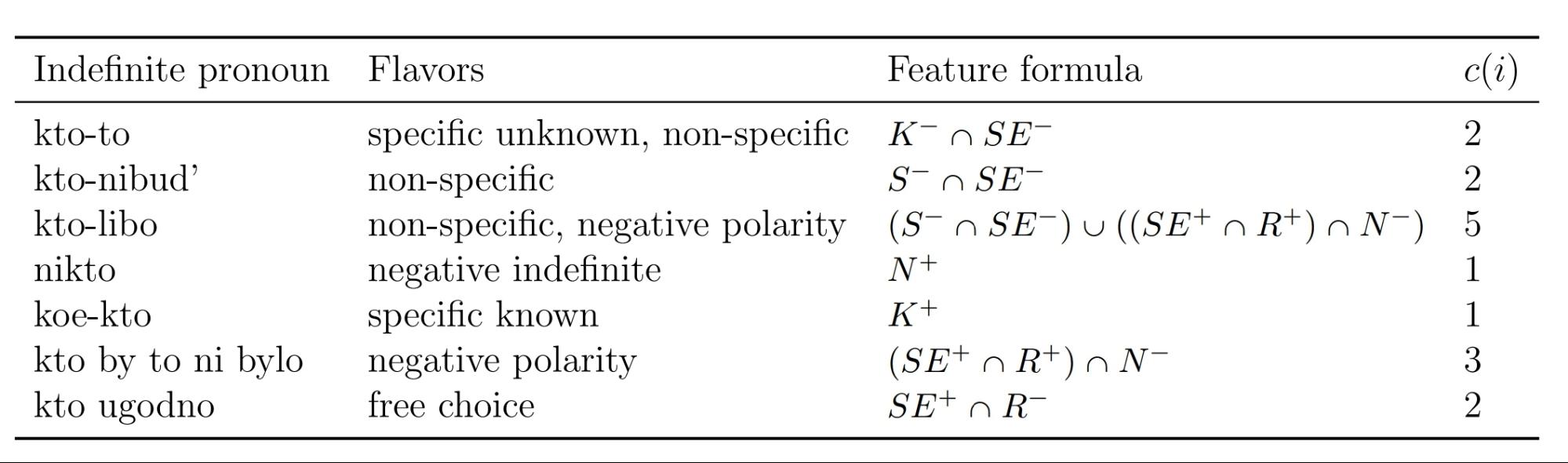
Сложность всех неопределенных местоимений русского языка. Источник: [3]
Теперь определим информативность. Пусть говорящий хочет выразить аромат f. В его языке есть неопределенное местоимение i, которое способно выражать аромат f. Всего в его языке есть p неопределенных местоимений, способных выразить аромат f. Тогда шанс того, что говорящий выберет для этого местоимение i, равен 1/p (например, как видно в таблице выше, аромат non-specific в русском умеют выражать три местоимения — значит, шанс, что среди них говорящий выберет «кто-то» — 1/3). При этом местоимение i способно выражать q ароматов. Тогда шанс того, что слушающий правильно поймет говорящего, — 1/q (у «кто-то» два возможных аромата — specific unknown и non-specific — значит, шанс, что его поймут как non-specific, равен 1/2).
Тогда информативностью языка L I(L) называется сумма умноженных на специальные коэффициенты произведений вероятностей 1/p и 1/q для всех существующих в данном языке пар «местоимение — его аромат». Эти коэффициенты зависят от вероятности употребления местоимения с определенным ароматом в речи.
Частотность употребления в речи местоимений по их аромату. Источник: [4]
Эксперимент №1: в поисках порога информативности
В рамках эксперимента было сгенерировано 10 000 искусственных «языков». Под языками в этих экспериментах подразумеваются наборы неопределенных местоимений (в данном случае только онтологической категории ЧЕЛОВЕК, то есть, например, кто-то и никто, но не что-то или нигде).
Каждый из языков состоял минимум из одного и максимум из семи неопределенных местоимений (таковы крайние значения в выборке М. Хаспельмата). Каждому из этих местоимений была присвоена одна из 63 (26-1) комбинаторно возможных комбинаций ароматов (за исключением той, согласно которой неопределенное местоимение не выражает ни одного аромата).
Из этих 10 000 сгенерированных псевдоязыков отобрали 479, которые совпадали с 40 естественными языками в выборке Хаспельмата по двум показателям: пересечению (overlap) и покрытию (coverage). Пересечение показывает, сколько разных неопределенных показателей в данном языке в среднем может выражать один аромат. Покрытие отражает то, сколько ароматов из шести может быть выражено в данном языке (выражаются хотя бы одним неопределенным маркером). Эти показатели позволяют доказать, что разница между случайно сгенерированными языками и естественными языками не объясняется тривиальными причинами: тем, что в случайных языках оказалось больше слов, чьи значения пересекаются, или тем, что в случайных языках оказалось больше значений, которые не выражаются ни одним показателем.
Далее был построен Парето-фронт оптимальности выбранных языков по показателям сложности и информативности.
Парето-оптимальное состояние
Состояние системы называется Парето-оптимальным, если один элемент системы не может быть улучшен без того, чтобы ухудшить другой. Парето-фронт — это кривая на графике, обозначающая множество точек, соответствующих Парето-оптимальным состояниям.
Чтобы нарисовать такую кривую, авторы пытались достичь состояний, при которых в языке нельзя улучшить информативность, не повысив при этом сложность, и наоборот. Добились они этого следующим образом: сначала сгенерировали 2000 новых случайных языков. Затем удалили все, кроме наиболее оптимальных, и из наиболее оптимальных породили новые небольшим количеством (1–3) перестановок (удаление неопределенного маркера, его добавление или его замена). Эту операцию повторили 100 раз, и из сотого поколения были выбраны самые оптимальные языки. К ним были добавлены самые оптимальные из 40 естественных языков выборки Хаспельмата и 497 ранее сгенерированных случайных языков. По точкам, обозначающим эти языки, и была проведена усредненная кривая на графике зависимости сложности языка от его коммуникативной стоимости (величина, обратная информативности) — Парето-фронт.
Далее на этот график авторы нанесли все 497 случайных языков и все 40 естественных — и получили следующее изображение:
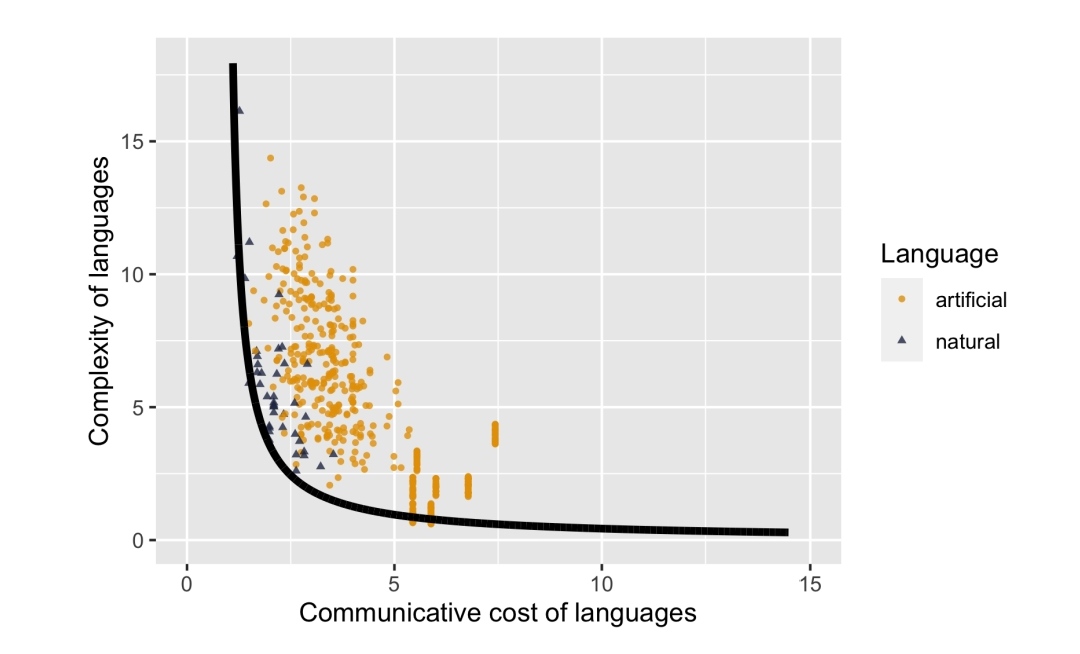
Распределение естественных и искусственных языков по соотношению их сложности и коммуникативной стоимости. Источник: [3]
Естественные языки (синие треугольники) лежат гораздо ближе к Парето-фронту, чем случайно сгенерированные (желтые круги): медианное расстояние естественного языка до Парето-фронта М1 = 0,48, тогда как медианное расстояние искусственного языка М2 = 1,55; вероятность получения такого результата случайно p < 0,001. Следовательно, естественные языки более оптимальны с точки зрения соотношения сложности и информативности, чем искусственно сгенерированные.
Естественные языки более оптимальны с точки зрения соотношения сложности и информативности, чем искусственно сгенерированные
А вот коммуникативная стоимость (величина, обратная информативности) у всех естественных языков довольно низкая, из чего авторы заключают, что есть некоторая минимальная степень информативности, которую естественные языки не готовы нарушать, даже при том, что язык может остаться Парето-оптимальным.
Эксперимент №2: связь с законами Хаспельмата
В результате первого эксперимента было обнаружено, что естественные языки стремятся к оптимизации размена информативности и сложности в своих системах неопределенных местоимений. Но связано ли это стремление к оптимизации с тем, что естественные языки не нарушают правила расположения неопределенных маркеров на семантической карте?
Для ответа на этот вопрос авторы статьи сгенерировали еще 10 000 искусственных языков, неопределенные местоимения в половине из которых были распределены по карте, согласно универсалиям Хаспельмата (т. н. Haspel-ok языки), а в другой половине — случайным образом (т. н. Not Haspel-ok языки). Во всех этих языках, так же как и в первом эксперименте, было от 1 до 7 неопределенных местоимений, и так же как и в первом эксперименте, две выборки уравняли по показателям пересечения и покрытия (после этого Not Haspel-ok языков осталось 2881). После этого методом, аналогичным первому эксперименту, на графике зависимости сложности от коммуникативной стоимости был нарисован Парето-фронт. Затем на графике были размещены точки, обозначающие 5000 Haspel-ok и 2881 отобранных Not Haspel-ok языков. Вот что получилось:
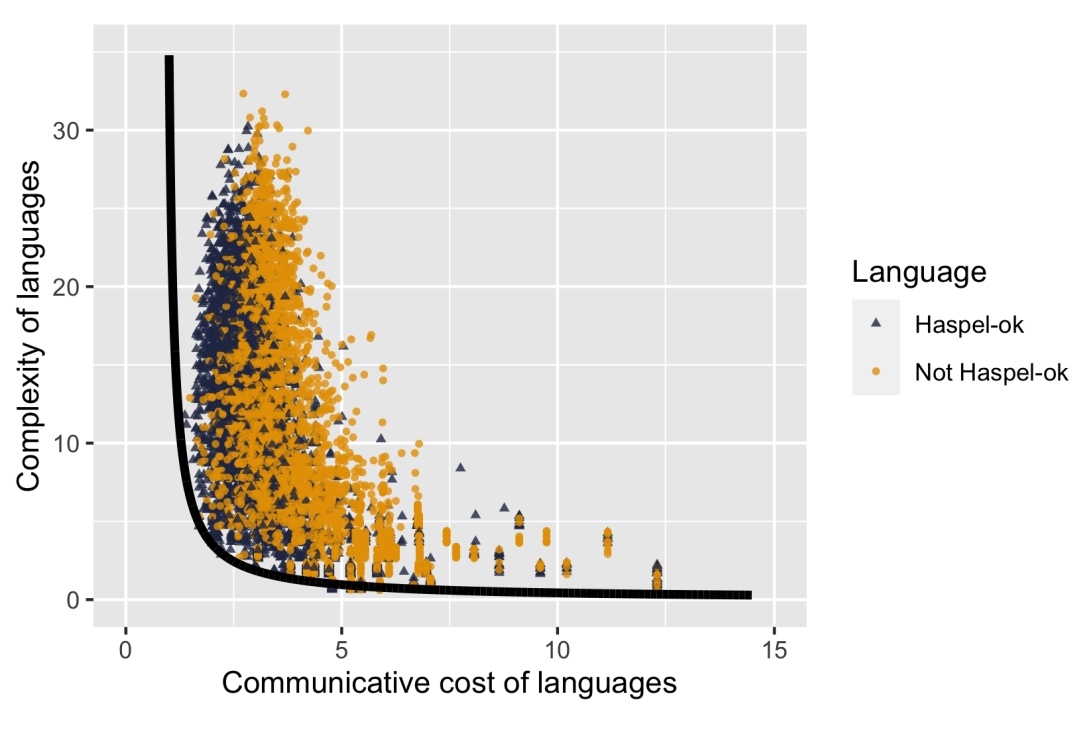
Распределение Haspel-ok и Not Haspel-ok языков по соотношению их сложности и коммуникативной стоимости. Источник: [3]
Как можно заметить, Haspel-ok языки лежат значительно ближе к Парето-фронту, чем Not Haspel-ok языки (M1 = 1,61; M2 = 2,26; p < 0,001). Это позволяет говорить, что успешность естественных языков в стремлении к оптимальности коррелирует с тем, что они соблюдают универсалии Хаспельмата. Остается ответить всего на два вопроса: почему и что это нам дает?
По сути, универсалии Хаспельмата — это ограничения на то, между какими наборами значений язык позволяет существовать неоднозначности, а между какими — уже нет. Еще сам Хаспельмат неформально объяснял ограничения, накладываемые своей семантической картой, тем, что одни значения могут объединяться с другими, потому что они близки, а другие не могут сочетаться, потому что они слишком фундаментально разные.
Универсалии Хаспельмата — это ограничения на то, между какими наборами значений язык позволяет существовать неоднозначности, а между какими — уже нет
Теперь, применив к этому массиву данных компьютерные методы и сравнив естественные языки с искусственными, можно утверждать: карта Хаспельмата выглядит так неслучайно. Его универсалии (или, как минимум, некоторые из них) — это способ для человеческого языка оптимизировать баланс между сложностью сообщения и его информативностью. И таким образом, неопределенные местоимения, встают в один ряд с, например, названиями цветов и показателями родства — как еще одна категория, которая показывает стремление естественных языков к оптимальности передачи информации.
Источники
- Падучева Е. В. Референциальный статус именной группы // Русская корпусная грамматика [Электронный ресурс]. — Режим доступа: http://rusgram.ru. — 2017.
- Haspelmath M. Indefinite pronouns. — Oxford University Press, 1997. — 380 p.
- Denić M., Steinert‐Threlkeld S., Szymanik J. Indefinite Pronouns Optimize the Simplicity/Informativeness Trade‐Off // Cognitive Science. — 2022. — Т. 46. — №. 5. — С. e13142
- Beekhuizen B., Watson J. and Stevenson S. Semantic typology and parallel corpora: Something about indefinite pronouns. In: 39th Annual Conference of the Cognitive Science Society (CogSci). — 2017. — pp. 112–117.