
Современные гуманитарные исследования все чаще обращаются к большим массивам текстов как к основному источнику знаний о жизни общества. Если раньше такими источниками были письма, газеты и интервью, то сегодня на смену им пришли цифровые платформы — прежде всего, социальные сети и мессенджеры (подробнее об этом в первом выпуске блога Дмитрия Пронина). Именно здесь язык существует в своей «естественной среде»: формируется спонтанно, без редактуры, отражает эмоции, реакции и динамику событий в реальном времени.
Для журналистики, социологии, политологии и других прикладных дисциплин это открывает уникальные возможности. Исследователь может количественно оценить медиасреду вокруг конкретной фигуры, будь то политик, предприниматель или инфлюенсер. Это позволяет проследить, какие темы и формулировки доминируют в обсуждениях, что меняется после громких высказываний или событий. Более того, появляется возможность фиксировать реакцию аудитории на социальные и политические инициативы, выявлять тренды и сдвиги в общественном настроении.
Особую роль в этом контексте играет мессенджер Telegram — один из крупнейших коммуникационных сервисов, объединяющий на 2025 год более 1 млрд пользователей (по месячному пользованию, MAU) по всему миру. Он служит площадкой для разнообразных медиа: от официальных СМИ и политических каналов до локальных сообществ и анонимных микроблогов. Это делает Telegram ценным источником эмпирических данных для изучения языка и дискурса.
В этой статье вы узнаете, как извлекать и структурировать данные из Telegram для анализа.
Как выгрузить отдельные Telegram-каналы?
Сначала рассмотрим, как можно работать с отдельными каналами. Сперва нам понадобится компьютер с установленным приложением Telegram Desktop.
Запустите Telegram Desktop, перейдите в интересующий вас канал и нажмите на три точки в правом верхнем углу. В выпадающем меню выберите пункт «Экспорт истории чата».
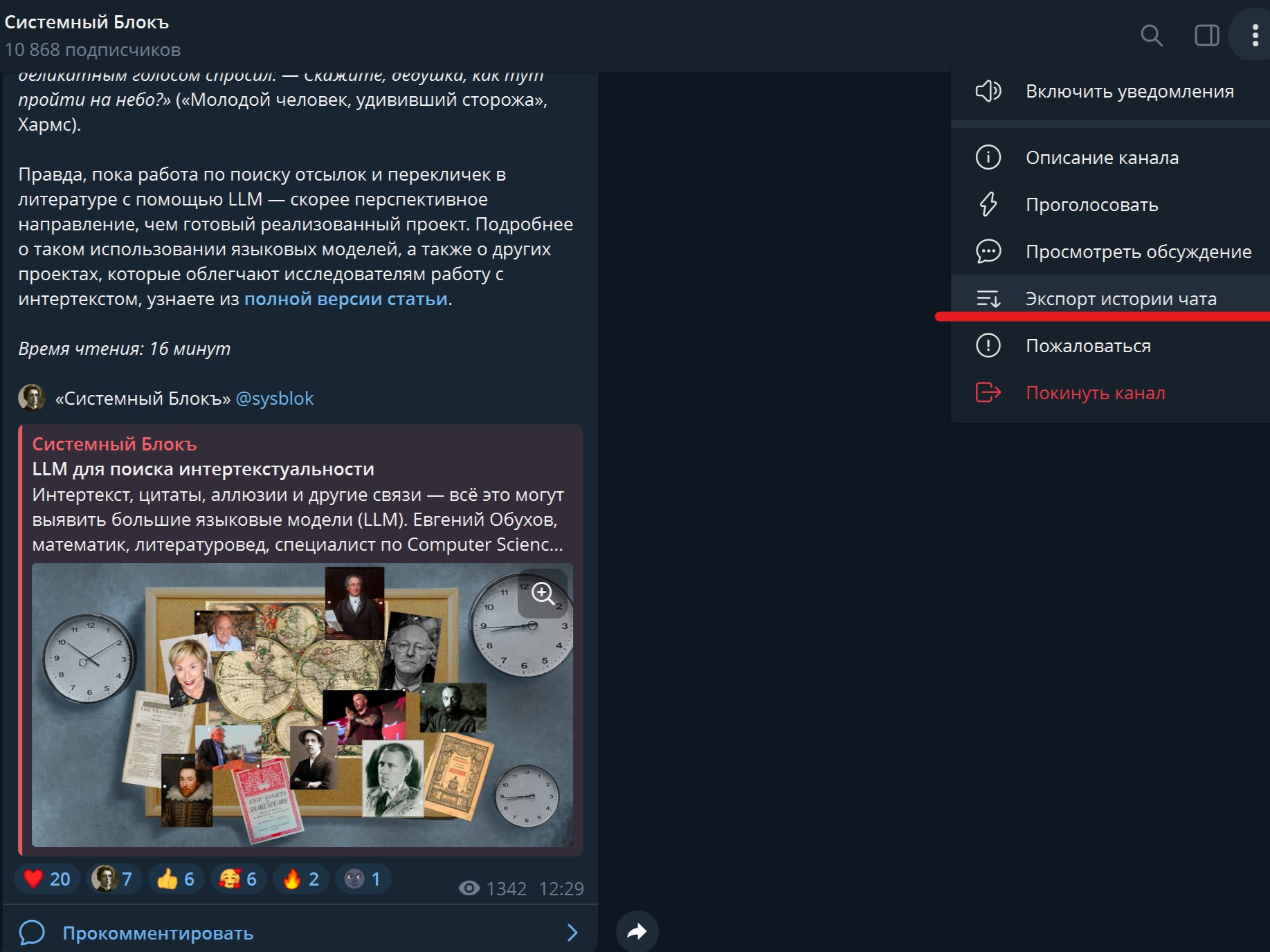
Рис. 1. Кнопка «Экспорт истории чата»
Перед вами появится окно с настройками. Снимите галочки с изображений, файлов, голосовых и прочих вложений. Нас интересует только текст. Внизу выберите формат данных JSON — он простой и гибкий и при этом универсально машиночитаемый, Python понимает JSON. Укажите путь, по которому нужно сохранить данные, и нажмите «Экспортировать».
Для пользователей Apple и MacOS: учтите, что опция отсутствует в той версии Telegram Desktop, которая доступна в AppStore. Чтобы воспользоваться ею, установите версию приложения с сайта самого Telegram.
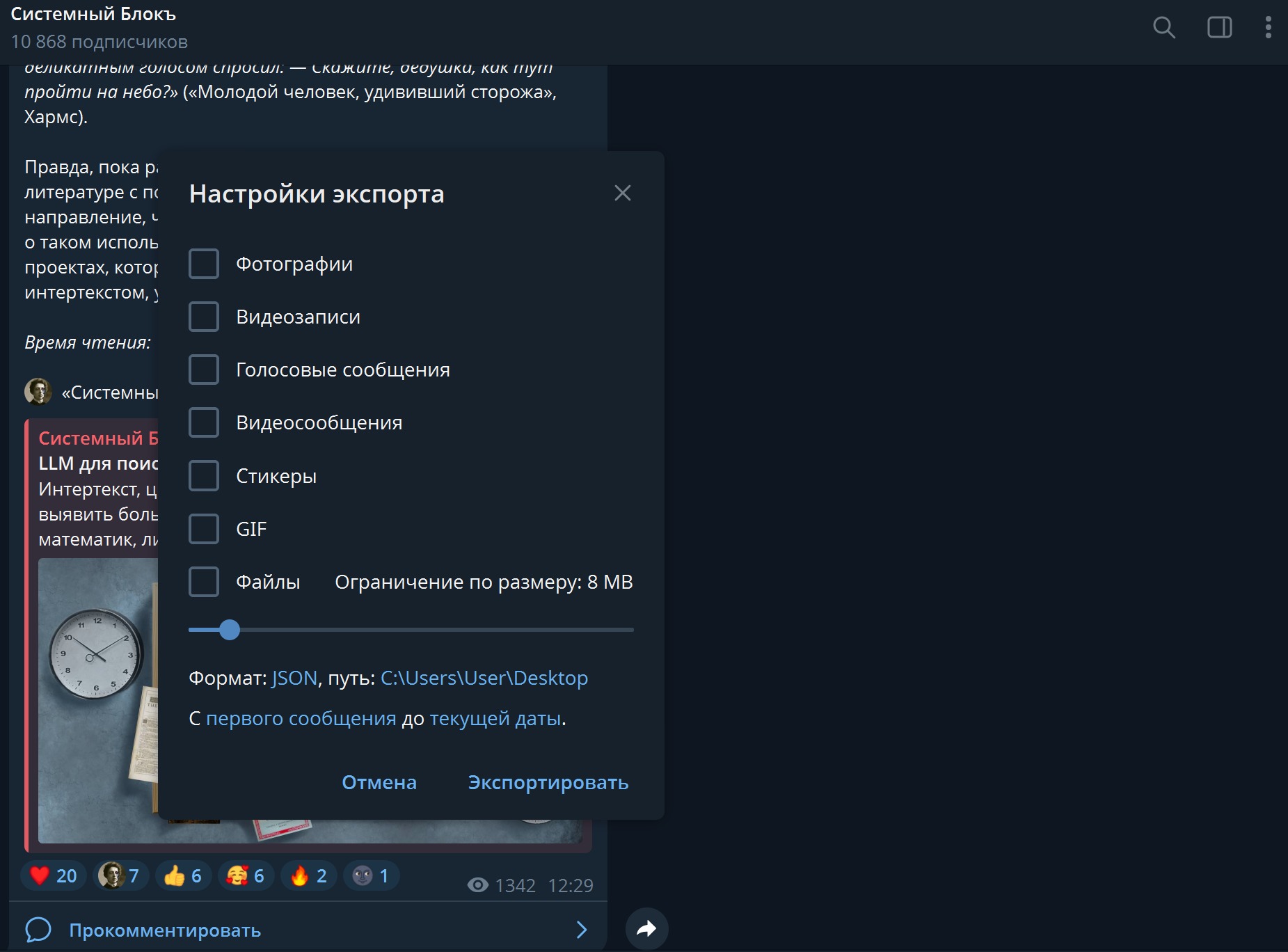
Рис. 2. Окно настроек экспорта
Через несколько минут (в зависимости от объема) Telegram создаст папку с названием вроде ChatExport_2025-06-18. В этой папке будет лежать файл result.json, именно он нам и нужен.
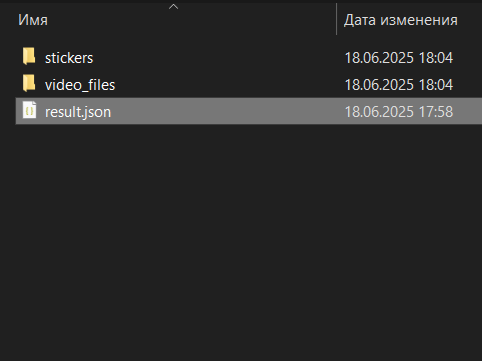
Рис. 3. Содержимое папки с результатами выгрузки истории чата
Напишем код на python для обработки полученного JSON-файла:
import pandas as pd
# Загружаем JSON-файл
# (укажите полный путь до result.json, если он не в одной папке с кодом)
df = pd.read_json("result.json")
# Раскрываем содержимое колонки messages
messages = pd.json_normalize(df["messages"])
# Оставляем только сообщения с типом 'message'
messages = messages[messages["type"] == "message"]
# Функция, которая поможет корректно выгрузить сообщения
def get_text(row):
parts = []
if isinstance(row["text"], list):
for item in row["text"]:
if isinstance(item, dict) and "text" in item:
parts.append(item["text"])
elif pd.notnull(row["text"]):
parts.append(str(row["text"]))
if pd.notnull(row.get("caption", None)):
parts.append(str(row["caption"]))
return "\n".join(parts).strip()
# Применим эту функцию к DataFrame
messages["text"] = messages.apply(get_text, axis=1)
# Оставляем только строки, где текст не пустой
messages = messages[messages["text"] != ""]
# Оставляем только нужные колонки
result = messages[["date", "text"]]
# Сохраняем в Excel
result.to_excel("result.xlsx", index=False)Теперь в нашей таблице result.xlsx хранятся сообщения из Telegram в удобном для анализа виде. Эти данные можно изучать прямо в Excel: искать слова и выражения, фильтровать сообщения, выделять интересующие фрагменты. При необходимости таблицу можно снова открыть в Python с помощью библиотеки pandas и функции read_excel, чтобы применить более гибкие инструменты анализа.
На этом этапе уже можно начать работать с текстом, например, выделить ключевые слова, оценить плотность публикаций по времени и среднюю длину сообщений, построить вероятностные модели встречаемости слов, провести тональный анализ или тематическое моделирование.
Таким образом, экспорт истории чата Telegram позволяет работать с отдельными каналами (или даже с вашей личной перепиской) как с текстовыми корпусами. Однако во многих исследованиях этого недостаточно. Если мы хотим получить более полную и статистически значимую картину, необходимо расширить масштаб — выйти за рамки одного канала и охватить большее количество источников.
Здесь возникает ключевая проблема: в Telegram отсутствует полноценный поиск по существующим каналам и группам, как, например, в VK. Попасть в большинство из них можно только по прямой ссылке. Это затрудняет построение выборки и делает невозможным простой сбор большого массива данных.
Как выгрузить множество Telegram-каналов?
Чтобы понять, как выгрузить множество каналов разом, сначала нужно разобраться с тем, как выгрузить хотя бы один канал полностью в автоматическом режиме. В этом нам поможет python с его библиотекой pyrogram, разработанной специально для взаимодействия с Telegram.
Сначала установим эту библиотеку через командную строку:
pip install pyrogram tgcryptoТеперь для взаимодействия с Telegram нам нужно получить ключи доступа. Перейдите на официальный сайт мессенджера и авторизуйтесь, введя свой номер телефона. Вам придет сообщение в Telegram с кодом для входа. После авторизации станет доступен раздел API Development tools: откройте его, создайте новое приложение, получите и сохраните ваши api_id и api_hash. Если не получилось, обратитесь к гайду, где процесс создания приложения и получения ключей описан более подробно.
Напишем функцию, которая позволит нам автоматизировать выгрузку:
# Импортируем необходимые библиотеки
from pyrogram import Client
from pyrogram.errors import FloodWait, ChannelPrivate # Обрабатываем частые ошибки при работе с Telegram
import pandas as pd # Для создания и сохранения таблиц
import os # Для работы с файлами и папками
import datetime # Для работы с датами
import time # Для задержки в случае ошибки
from tqdm import tqdm # Для отображения прогресса в цикле
# Указываем данные для подключения к Telegram API
api_id = 'ВАШ_API_ID'
api_hash = 'ВАШ_API_HASH'
# Создаем Telegram-клиент с именем сессии "my_session"
# При первом запуске вас попросят ввести номер телефона и код из Telegram
app = Client("my_session", api_id=api_id, api_hash=api_hash)
# Функция для парсинга одного Telegram-канала
def parse_channel(channel_link, cutoff_date):
posts = [] # сюда будут собираться сообщения (дата и текст)
found_links = [] # сюда будут собираться ссылки на другие каналы
# Открываем сессию Telegram-клиента
with app:
# Получаем историю сообщений указанного канала
for message in app.get_chat_history(channel_link):
# Получаем дату публикации сообщения
message_date = message.date.date()
# Если сообщение старше указанной даты - прекращаем цикл
if message_date < cutoff_date:
break
# Если в сообщении есть текст - сохраняем его
if message.text:
posts.append({
'date': message.date.strftime('%d.%m.%Y'),
'text': message.text
})
# Сохраняем подпись к изображению или документу
elif message.caption:
posts.append({
'date': message.date.strftime('%d.%m.%Y'),
'text': message.caption
})
# Сохраняем репосты и метаданные групп, из которых они сделаны
if message.forward_from_chat:
found_links.append({
'username': message.forward_from_chat.username,
'title': message.forward_from_chat.title
})
# Создаем таблицу pandas из собранных сообщений, удаляя дубли
posts_df = pd.DataFrame(posts).drop_duplicates(ignore_index=True)
# Создаем таблицу pandas из найденных ссылок, удаляя дубли
links_df = pd.DataFrame(found_links).drop_duplicates(ignore_index=True)
# Возвращаем две таблицы: с сообщениями и с найденными каналами
return posts_df, links_dfТеперь снова выгрузим Telegram-канал «Системного Блока» и сохраним полученный DataFrame в формате Excel.
# Выбираем дату, начиная с которой будут выгружаться сообщения
cutoff_date = datetime.datetime.strptime("01.01.2019", "%d.%m.%Y").date()
# Производим выгрузку
posts_df, links_df = parse_channel(channel_link='sysblok', cutoff_date=cutoff_date)
posts_df.to_excel('sysblok.xlsx', index=False)Обратим внимание на то, что функция parse_channel возвращает две переменных: posts_df — DataFrame с постами самого канала, а также links_df — таблицу со ссылками на каналы, из которых были сделаны репосты. Так, например, на момент написания этого предложения «Системный Блокъ» ссылался на канал Татьяны Шавриной Kali Novskaya (rybolos_channel) и канал проекта «Пишу тебе» (pishuteberu).
Этими ссылками можно воспользоваться, чтобы запустить «цепную реакцию» (т. е. рекурсивное выкачивание новых каналов, поиск репостов и далее по кругу)! Если повторить описанную выше операцию с Kali Novskaya и «Пишу тебе», мы также с большой вероятностью найдем репосты и таким образом получим ссылки на несколько новых каналов. С ними затем можно будет проделать все то же самое.
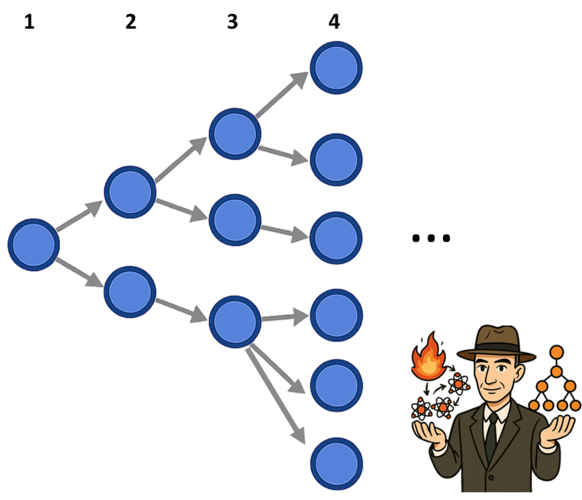
Рис. 4. Рекурсивное расширение нашего поиска позволяет находить по ссылкам и выгружать всё новые и новые каналы — так мы получаем доступ к практически неограниченным объемам данных
Теоретически, если среднее число новых, неизвестных до этого ссылок на каждой итерации будет больше одной (часто так и происходит), «цепная реакция» выгрузки данных остановится только тогда, когда скачает весь Telegram.
В реальности, разумеется, будут существовать каналы, на которые никто никогда не ссылался, или циклы-острова, за пределы которых цепная реакция не вырвется. Анализ подобных случаев — тема для отдельной статьи.
Реализуем описанный «цепной» алгоритм на практике. Сначала создадим следующие файлы и папки в папке проекта:

Поместим в файл parser.py функцию для автоматической выгрузки и код ниже, реализующий один шаг «цепной реакции» (рекурсии):
# Загрузка ссылок на каналы из файла
channels_df = pd.read_excel('tg_links.xlsx')
channel_links = channels_df['link'].tolist()
# Проверка уже загруженных каналов
downloaded_channels = [os.path.splitext(file)[0] for file in os.listdir('data')]
cutoff_date = datetime.datetime.strptime("01.01.2020", "%d.%m.%Y").date()
new_channels = []
for link in tqdm(channel_links):
if link not in downloaded_channels:
try:
posts_df, links_df = parse_channel(link, cutoff_date)
# Сохраняем сообщения канала в JSON
posts_df.to_json(f'data/{link}.json',
force_ascii=False, indent=2)
# Сохраняем найденные ссылки сразу в удобном формате CSV
if not links_df.empty:
links_df.to_csv(f'reserved_links/{link}_found_links.csv',
index=False, encoding='utf-8')
new_channels.extend(links_df.to_dict('records'))
print(f'Канал {link} обработан. Сообщений: {len(posts_df)}, найдено ссылок: {len(links_df)}.')
except ChannelPrivate:
print(f"Канал {link} приватный, пропускаем.")
except FloodWait as e:
print(f"Превышено количество запросов, ждем {e.value} секунд.")
time.sleep(e.value)
except Exception as e:
print(f"Неизвестная ошибка при обработке канала {link}: {e}")
else:
print(f'Канал {link} уже загружен.')
# Добавляем новые найденные каналы в таблицу и сохраняем
if new_channels:
new_channels_df = pd.DataFrame(new_channels)
updated_channels_df = pd.concat([channels_df, new_channels_df.rename(columns={'username':'link', 'title':'name'})])
updated_channels_df.drop_duplicates(subset='link', inplace=True, ignore_index=True)
updated_channels_df.to_excel('tg_links.xlsx', index=False)
print("Обработка завершена, таблица ссылок обновлена.")Перед запуском обязательно создайте Excel таблицу tg_links.xlsx или скачайте ее шаблон по ссылке. Для корректной работы алгоритма таблица должна иметь всего два столбца с названиями link и name.

Рис. 5. Столбцы в таблице tg_links.xlsx
После запуска алгоритм совершает один шаг «цепной реакции»: он загружает все Telegram-каналы, указанные в исходной таблице, и ищет в них упоминания других каналов. Все найденные ссылки сохраняются в ту же таблицу tg_links.xlsx, расширяя таким образом исследуемую сеть.
Каждый загруженный канал сохраняется в формате JSON в папке data, текст постов становится доступен для дальнейшего анализа. С помощью стандартных инструментов, таких как библиотека pandas в Python, эти данные можно использовать, например, для построения частотных таблиц, графов упоминаний или временных рядов на основе сообщений.
Что с этим делать?
Благодаря механизму «цепной реакции» можно собрать базу данных из тысяч каналов, связанных между собой упоминаниями, — фактически сформировать фрагмент медиасреды с ее внутренними связями и динамикой.
Такая база может служить основой для широкого спектра исследований. Вы можете:
- анализировать лексику и семантику, выявляя доминирующие темы, термины и тональность в разных сегментах Telegram;
- отслеживать изменения во времени — как меняется повестка, какие слова выходят на первый план в контексте событий;
- исследовать стилистику и авторскую манеру, например, сравнивая речь официальных каналов и независимых микроблогов;
- строить графы влияния, показывающие, какие каналы цитируются чаще и как распространяется информация;
- изучать реакции аудитории на конкретные события, инициативы или фигуры.
Вооружившись документацией pyrogram, можно расширить функционал алгоритма, например, выгружать только каналы с определенным числом подписчиков, скачивать комментарии к постам (которые редко бывают действительно информативными из-за обилия рекламных ботов) или даже сохранять прикрепленные картинки и видео.
Источники: Документация pyrogram. URL: https://docs.pyrogram.org (дата обращения 30.06.2025).

