
Введение
Стилометрия ― это метод количественного анализа текста, основанный на подсчёте служебных слов, который часто используется для установления авторства. «Системный Блокъ» уже писал, как развивался этот инструмент, делал подборку исследований на его основе и пытался обнаружить индивидуальный стиль переводчика. На этот раз мы приготовили подробную инструкцию, как изучать тексты с несколькими авторскими сигналами. Нам потребуется Stylo — библиотека языка программирования R — и программная среда R Studio.
Если вы ещё не знаете, какие возможности есть у Stylo и как начать работу с этой библиотекой, прочитайте наше руководство для начинающих.
Зачем нужна функция rolling.classify
Представьте, что у вас есть текст, написанный (хотя бы предположительно) несколькими людьми. Как узнать, какие его части точно принадлежат тому или иному автору, если об этом нет никаких данных? Или как проверить, повлиял ли один автор на другого? Для этого в библиотеке Stylo и существует функция rolling.classify(). С её помощью можно изучать даже литературные мистификации.
В основе её работы лежит алгоритм, который обучается на корпусе текстов предполагаемых авторов. Затем он разбивает изначальный текст на части и определяет, кому какая принадлежит. Метод обучения, например, Delta, можно выбрать. Все варианты описаны в документации к библиотеке, а также доступны при вводе команды
?rolling.classify«Игрушечный» пример
Попробуем провести эксперимент сами. Возьмём текст, отрывки которого функция должна атрибутировать безошибочно, — ведь он искусственно составлен из отрывков «Драмы на охоте» А. П. Чехова и «Жизни Арсеньева» И. А. Бунина.
Собранное «произведение» (которое вы можете найти здесь) состоит из четырёх частей:
- первой половины «Драмы на охоте» (~ 26939 слов);
- первой книги «Жизни Арсеньева» (~ 14964 слов);
- второй половины «Драмы на охоте» (~ 26250 слов);
- второй книги «Жизни Арсеньева» (~ 15571 слов).
Подготовка к исследованию
Как уже было сказано, кроме исходного текста нам понадобится корпус работ каждого предполагаемого автора. Эта коллекция не обязательно должна быть большой, но в каждом файле должно быть не менее пяти тысяч слов, так как Stylo плохо работает с короткими текстами. Корпус нужно положить в папку с названием reference_set, а исследуемое произведение — в папку test_set. Формат файлов — txt. Обязательно проверьте, чтобы у них была одинаковая кодировка!
Так в Windows будут выглядеть папки для стилометрического эксперимента
Для гайда мы взяли некоторые рассказы Бунина (отсюда и отсюда) и Чехова из библиотеки Максима Мошкова. В собранных текстах мы удалили комментарии и предисловия, поменяли кодировку на UTF-8. Папки с подготовленными документами можно найти здесь.
Запуск функции в R Studio
Для начала вам потребуется запустить R Studio, установить и вызвать библиотеку Stylo:
install.packages("stylo")library(stylo)Теперь укажите путь к директории, в которой лежат подготовленные папки:
setwd("путь к файлу")Далее можно запускать функцию. Важное замечание: у неё нет графического интерфейса, как у stylo().
Вот такое окошко при запуске функции не появится
Вам придётся писать код вручную. Введите название функции rolling.classify() и пропишите параметры. Для начала попробуем вот так:
rolling.classify(training.corpus.dir = "reference_set", test.corpus.dir = "test_set", write.png.file = TRUE, classification.method = "delta", mfw = 1500, corpus.lang="Other", slice.size = 5000)Что это значит? Пройдёмся по параметрам:
- training.corpus.dir и test.corpus.dir отвечают за местонахождение наших папок с текстами;
- write.png.file представляет результаты (график) в виде картинки в формате .png;
- classification.method позволяет выбрать метод машинного обучения;
- mfw (most frequent words) устанавливает количество частотных слов;
- corpus.lang задаёт язык текстов; по умолчанию функция работает с текстами на латинице, поэтому для русского языка нужно вписать «Other»;
- slice.size разбивает тексты на отрывки с определённым количеством слов; по умолчанию граница равна 5000.
У функции есть и другие параметры. Чтобы узнать о них больше, введите уже упомянутую команду:
?rolling.classifyИнтерпретация результатов стилометрии
После запуска функции на выходе получается диаграмма. Найти её можно в той же директории, куда мы положили корпус и сам текст. Кроме того, здесь же сохраняется список самых частотных слов реферативного* (то есть того, с которым мы сравниваем наш материал) корпуса, таблица с их частотностью в формате txt и частотность по отрезкам текста.
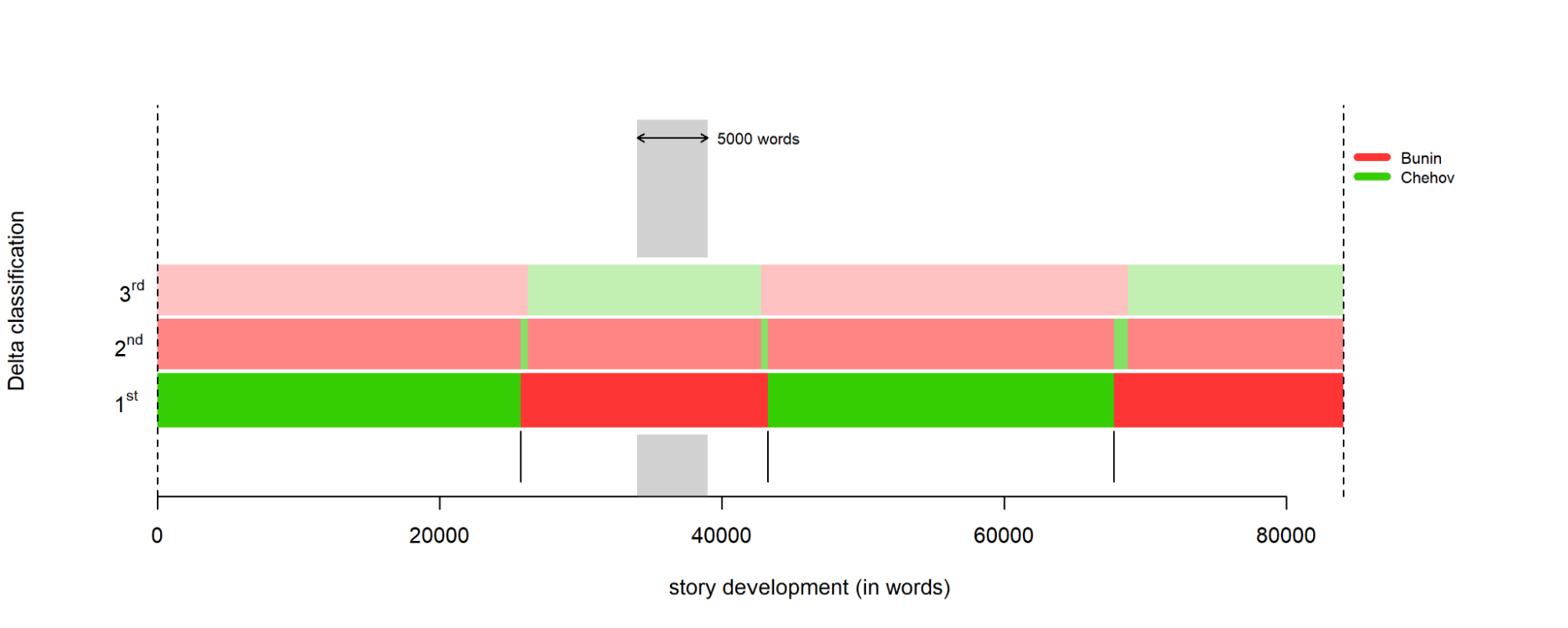
Диаграмма с разбитым на отрывки текстом и авторской атрибуцией
Три полосы на диаграмме показывают варианты атрибуции текстов. Смотрим на нижнюю (самую яркую) полосу — она отражает наиболее вероятное разбиение отрывков по авторам. Красным отмечены те из них, которые алгоритм приписывает Бунину, зелёным — Чехову. Вкрапления цветов означают смешение стилей. Числа на нижней оси разбивают текст на отрывки по 20 тысяч слов, а серый столбик показывает, какое расстояние на графике составляет наша граница в пять тысяч слов.
Получилось достаточно точно: отрывки, опознанные как чеховские и бунинские, совпадают с их местоположением в нашем сборном тексте, а их длина близка к размеру исходных фрагментов.
Ради эксперимента, попробуем поменять параметры функции (количество самых частотных слов, метод машинного обучения) и посмотреть, что получится.
Эксперименты с параметрами
Для начала попробуем тот же метод delta, но с mfw = 300:
rolling.classify(training.corpus.dir = "reference_set",
test.corpus.dir = "test_set", write.png.file = TRUE, classification.method = "delta", mfw = 300, corpus.lang="Other", slice.size = 5000)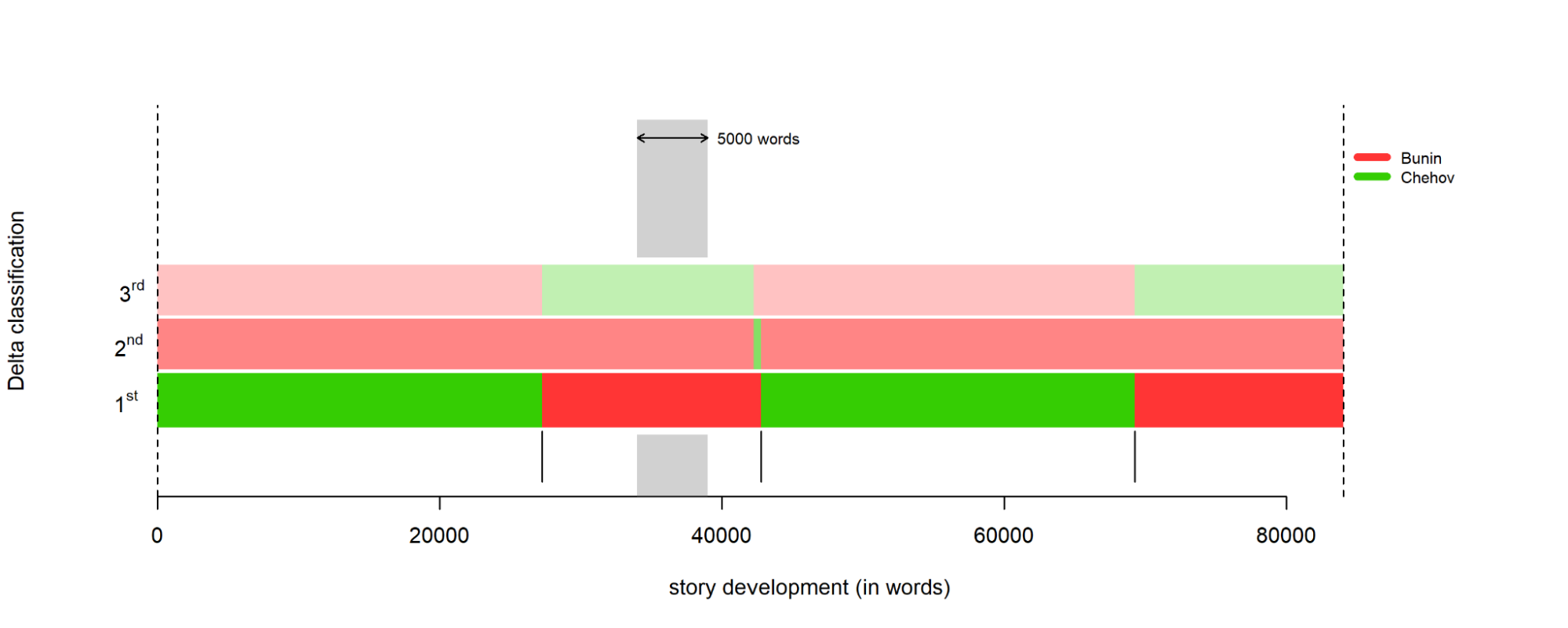
Итоговая диаграмма с параметром mfw = 300
Как видим, изменения затронули только вторую полосу, один из менее вероятных вариантов разбиения.
Теперь используем метод опорных векторов (SVM). Почитать о нём подробнее можно здесь. Код:
rolling.classify(training.corpus.dir = "reference_set", test.corpus.dir = "test_set", write.png.file = TRUE, classification.method = "svm", mfw = 1000, corpus.lang="Other", slice.size = 5000)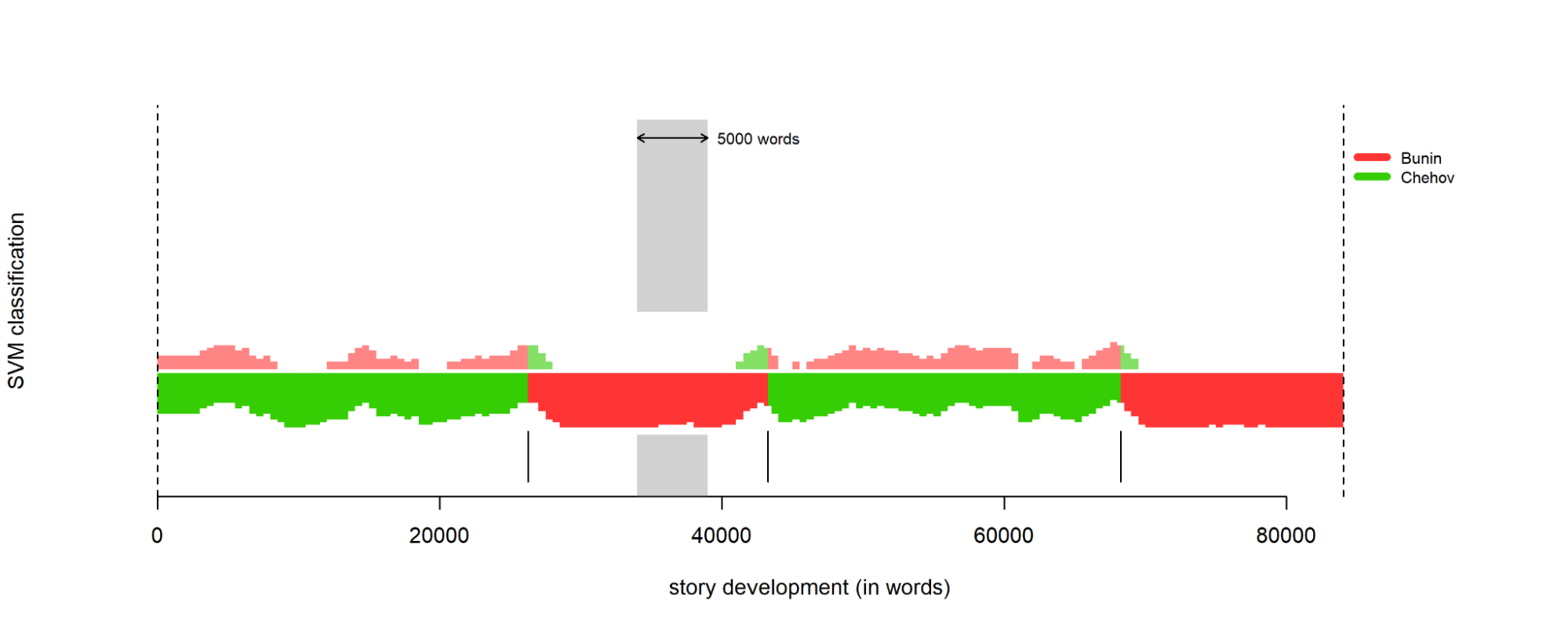
Итоговая диаграмма на основе метода опорных векторов
График выглядит по-другому. Теперь у него есть только одна полоса с небольшими бледными отклонениями — менее правдоподобными вариантами. Разбиение такое же хорошее, как и в предыдущих вариантах.
А вот, что будет, если применить метод ближайших сжатых центроидов (NSC):
rolling.classify(training.corpus.dir = "reference_set", test.corpus.dir = "test_set", write.png.file = TRUE, classification.method = "nsc", mfw = 250, corpus.lang="Other", slice.size = 5000)
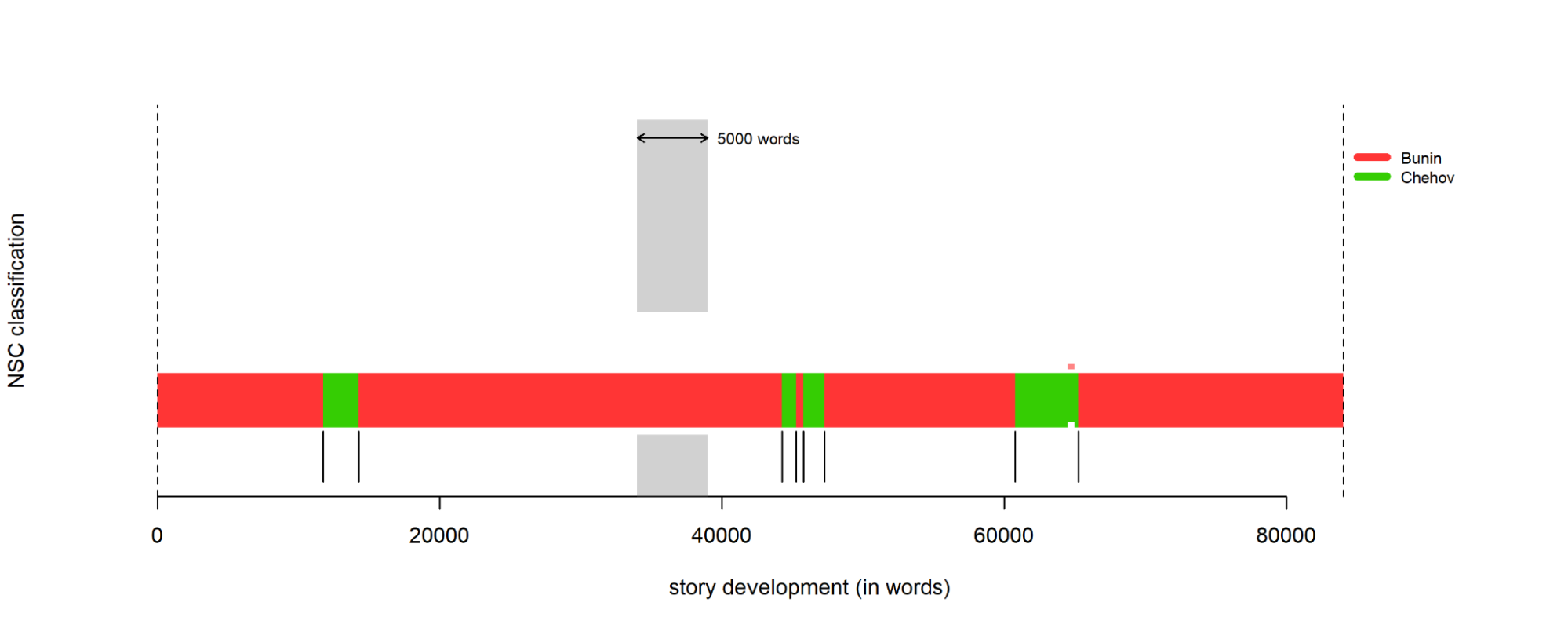
Итоговая диаграмма на основе метода ближайших сжатых центроидов
Тут вообще всё грустно, поэтому для нашей задачи этот метод не подходит.
Заключение
В этом тьюториале мы смотрели, получится ли подтвердить результат, когда границы соавторства заранее известны. Нам сразу удалось найти подходящие для текстов настройки. Однако в реальности исследователи работают с текстами, где они не уверены в границах соавторства или не знают их вовсе. Тогда стоит пробовать разные параметры функции и совмещать количественный анализ с качественным. Например, пристально читать отрывки, которые алгоритм приписывает авторам, или обращаться к литературоведческим работам, в которых можно найти подтверждение найденным закономерностям.
*реферативный, или референсный (reference) — корпус, с которым сравнивается целевой (фокусный) корпус или текст (в нашем случае — искусственный текст Чехова и Бунина)
Источники
- Package Stylo [Документация к библиотеке] // Cran. URL: https://cran.r-project.org/web/packages/stylo/stylo.pdf (дата обращения: 21.12.2023).
- Brownlee J. Nearest Shrunken Centroids With Python [Электронный ресурс] // Machine Learning Mastery. 19.06.2020. URL: https://machinelearningmastery.com/nearest-shrunken-centroids-with-python (дата обращения: 21.12.2023).
Что ещё почитать?
- Скоринкин Д. Попрактикуемся в стилометрии [Электронный ресурс] // Github.com. 31.01.2023 URL: https://github.com/dhhse/distantreading/blob/main/stylometry/stylometry_practice.md (дата обращения 21.12.2023).
- Eder M. Testing Rolling Stylometry [Электронный ресурс] // Computational stylistics group. 08.10.2014. URL: /https://computationalstylistics.github.io/blog/rolling_stylometry/ (дата обращения 21.12.2023).
- Eder M., Rybicki J. and Kestemont M. Stylometry with R: a package for computational text analysis [Электронный ресурс] // R Journal. 2016. № 8(1). Pp. 107-121. URL: https://journal.r-project.org/archive/2016/RJ-2016-007/index.html (дата обращения 21.12.2023).

