
Введение
«Системный Блокъ» уже выпускал гайды по стилометрическому пакету Stylo: самый базовый (там же рассказано, как установить язык программирования R, среду разработки RStudio и сам пакет Stylo) и более продвинутый. В этом материале мы расскажем ещё об одной стилометрической функции — oppose(), которая используется для сравнения двух корпусов и поиска наиболее явных различий между их лексическими составами.
Назначение функции oppose()
Oppose() выполняет контрастивный анализ текстов или корпусов. Она выявляет слова двух видов:
- более характерные для одного корпуса по сравнению с другим;
- наоборот, присутствующие в другом корпусе и совсем не характерные для первого.
Также при работе с oppose() может использоваться третий корпус (тестовый), если нужно:
- проверить точность результата;
- определить, на какой из двух корпусов он больше похож.
Тем не менее код запустится и без тестового сета.
Стоп… Мы же уже умеем искать «ключевые слова»!
Да, «Системный Блокъ» выпустил гайд по программе AntConc, с помощью которой можно найти слова, «необычно частотные в одном корпусе по сравнению с другим» [3]. Но в случае с oppose() и его основной метрикой zeta речь не идёт о простом подсчёте частотностей zeta.
Oppose() делит тексты на фрагменты заранее заданной длины и вычисляет пропорцию встречаемости слова в этих фрагментах. Таким образом учитывается не только частотность, но и особенности распределения (distribution) слова. Если у вас есть очень длинный текст, но его самое частотное слово нигде больше не встречается — оно (в идеале) не будет отмечено как характерное для всего корпуса.
Подробнее о вычислениях oppose() можно почитать в документации (там же есть ссылки на дополнительную литературу) и how to. А узнать больше о статистических мерах для сравнения корпусов — здесь.
Подготовка к исследованию
По традиции сначала надо подготовить несколько папок с исследуемыми текстами. Primary_set — первый корпус, secondary_set — второй. Третий сет нужно положить в папку test_set. В него могут входить тексты, как-либо похожие на первые два корпуса (тех же авторов / того же жанра и т. п.) — для верификации результатов; или произведения, которые только предстоит отнести к первому или второму сету.
Так в Windows будут выглядеть папки для контрастивного анализа
Например, если вы хотите найти различия между женскими и мужскими текстами, выполните следующие шаги:
- положите женские тексты в папку primary_set;
- мужские — в secondary_set;
- положите другие тексты в test_set (если захотите его использовать).
Сами тексты стоит назвать так же, как и для функции stylo(): один тип текстов — одна приставка, другой — другая. Примерный шаблон:
type1_title1
type1_title2
…
type2_title1
type2_title2
… и так далее.
Непосредственно перед запуском функции нужно загрузить саму библиотеку (или установить её):
library(stylo)Запуск и интерфейс
Функция oppose() запускается так же, как и stylo(): прописываем команду, нажимаем enter, и на экране появляется графический интерфейс.
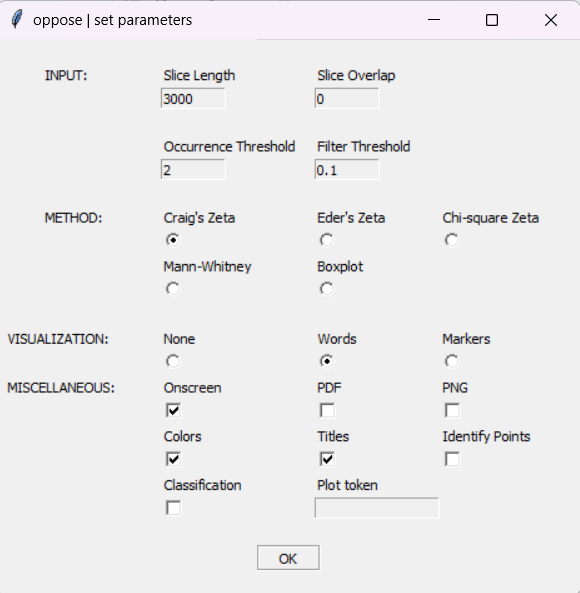
Графический интерфейс функции Stylo oppose(), дефолтные настройки
Итак, что мы имеем:
INPUT
Настройки того, что подаётся на вход функции.
Slice length — размер фрагментов (в словах), на которые будут разрезаны тексты.
Slice overlap — параметр наложения фрагментов друг на друга. Если выбрать slice length 5000, а slice overlap 100, первый отрывок будет включать 1–5000-е слово, второй — 4900–9900-е и т. д. Здесь не стоит выбирать слишком маленькие числа, иначе всё зависнет 🙂
Occurrence threshold — слова, с частотностью ниже указанного в этом параметре числа, будут отсекаться.
Filter threshold — граница статистической значимости. Чем выше этот параметр, тем меньше слов будет отобрано в результате. См. подробнее тут.
METHOD
Способ, которым будет рассчитываться контраст между текстами. Если для вас все эти слова выглядят, как абракадабра, посмотрите сайт Zeta and Company. Там рассказано о мерах, используемых для сравнения корпусов (текстов) и, в частности, о зете и её вариантах, на которых основываются расчёты oppose(). Под популярным объяснением можно найти библиографические ссылки на научные статьи, в частности — на оригинальную статью Дж. Бёрроуза про зету [4].
VISUALIZATION
Выбор того, что будет визуализироваться, и нужна ли визуализация вообще.
Words — слова, (не)предпочитаемые в корпусах. Функция буквально изобразит список самых статистически значимых слов со степенью этой значимости.
Markers — график, который покажет стилистическую схожесть всех получившихся фрагментов. Кружками будут обозначены фрагменты первого корпуса, треугольниками — второго, крестиками — тестового (при наличии).На практике обе визуализации покажем ниже.
MISCELLANEOUS
Дополнительные настройки визуализации.
NB! В графическом интерфейсе нет возможности выбрать язык. При желании работать с текстами на кириллице, нужно прописать дополнительно перед запуском функции:
oppose(corpus.lang="Other")А ещё, если вы — «профи», можно отключить графический интерфейс и прописать все настройки вручную:
oppose(corpus.lang="Other", gui=FALSE, slice.length= ...)… но в гайде остановимся на уровне «hello, world!»
Пример эксперимента
Попробуем сами! Сравним романы Тургенева «Накануне» и «Дворянское гнездо» с «Обрывом» и «Обыкновенной историей» Гончарова. В тестовый набор текстов пойдут «Рудин» и «Обломов». Мы их взяли на royallib [5], подготовили и положили в папку на гитхабе.
Визуализация по словам
На первом этапе выведем на экран слова, которые отличают два корпуса друг от друга. Выбираем настройки:
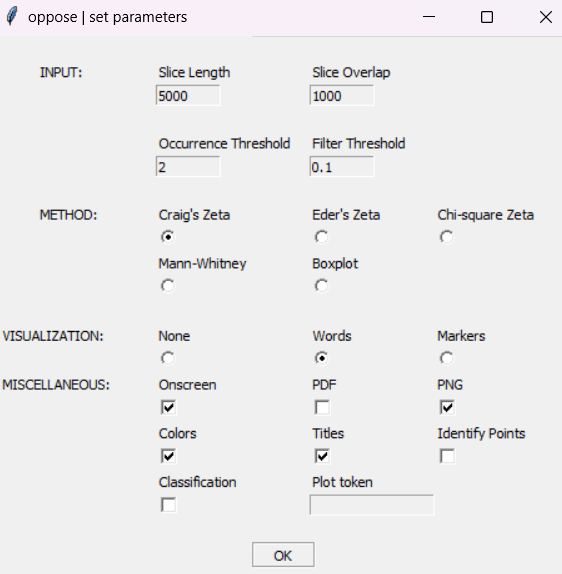
Графический интерфейс oppose(), настройки для эксперимента 1
Получается такой график (он перевёрнут, чтобы было удобнее смотреть):
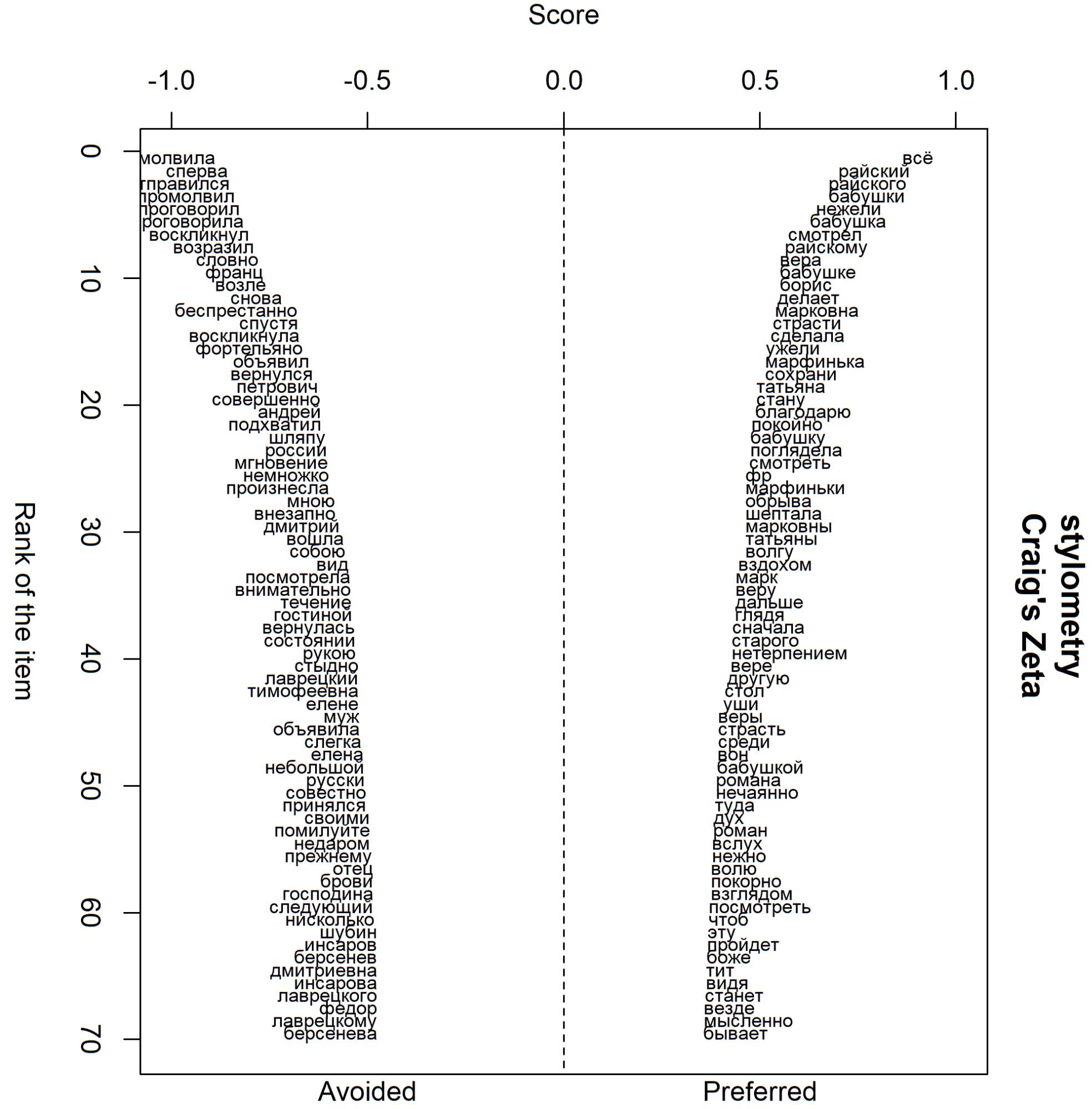
Результаты контрастивного анализа, визуализация по словам
В левой части находятся слова, которые отличают романы Тургенева от произведений Гончарова, в правой — наоборот. Зета измеряется в интервале от 0 до 1, эти границы представлены вверху. Слова ранжированы на основе расчётов зеты. Проще говоря, второй корпус от первого статистически сильнее всего отличает слово «молвила», а первый от второго — «всё». Затем следуют слова, которые отличают корпуса немного слабее и далее до конца списков avoided и preferred.
NB! На график выводятся не все слова. Проверьте директорию, в которой лежат папки с текстами — там должны появиться несколько txt- файлов, название которых идентичны колонкам на графике. Кстати, вы можете их редактировать и использовать кастомные списки в следующих этапах анализа.
Что даёт этот график / списки слов? При наших настройках, получается, что у Тургенева персонажи больше говорят (формы глаголов промолвить, воскликнуть, возразить), а у Гончарова — смотрят (формы слов поглядеть, смотреть, посмотреть, взгляд). Ещё, конечно, в качестве «контрастных» всплывают наименования персонажей (Лаврецкий, Елена, отец vs Райский, бабушка и др.) — это само по себе ничего не даёт, но показывает, что метод в целом работает примерно так, как мы ожидали. При необходимости вы можете заранее отфильтровать имена.
А ещё чем больше разных произведений в корпусе — тем меньше шансов, что в списки отличающих слов попадут конкретные имена. Т. е. если вы будете сравнивать, к примеру, корпус исторических романов с корпусом романов остросоциальных, то имён должно быть меньше.
Визуализация маркеров
Теперь посмотрим, как сгруппируются фрагменты. Эта операция чем-то похожа на классификацию с помощью stylo(), но график получается другим.
Настройки оставим теми же, но визуализацию заменим на маркеры:
Графический интерфейс oppose(), настройки для эксперимента 2
Получается такой график:
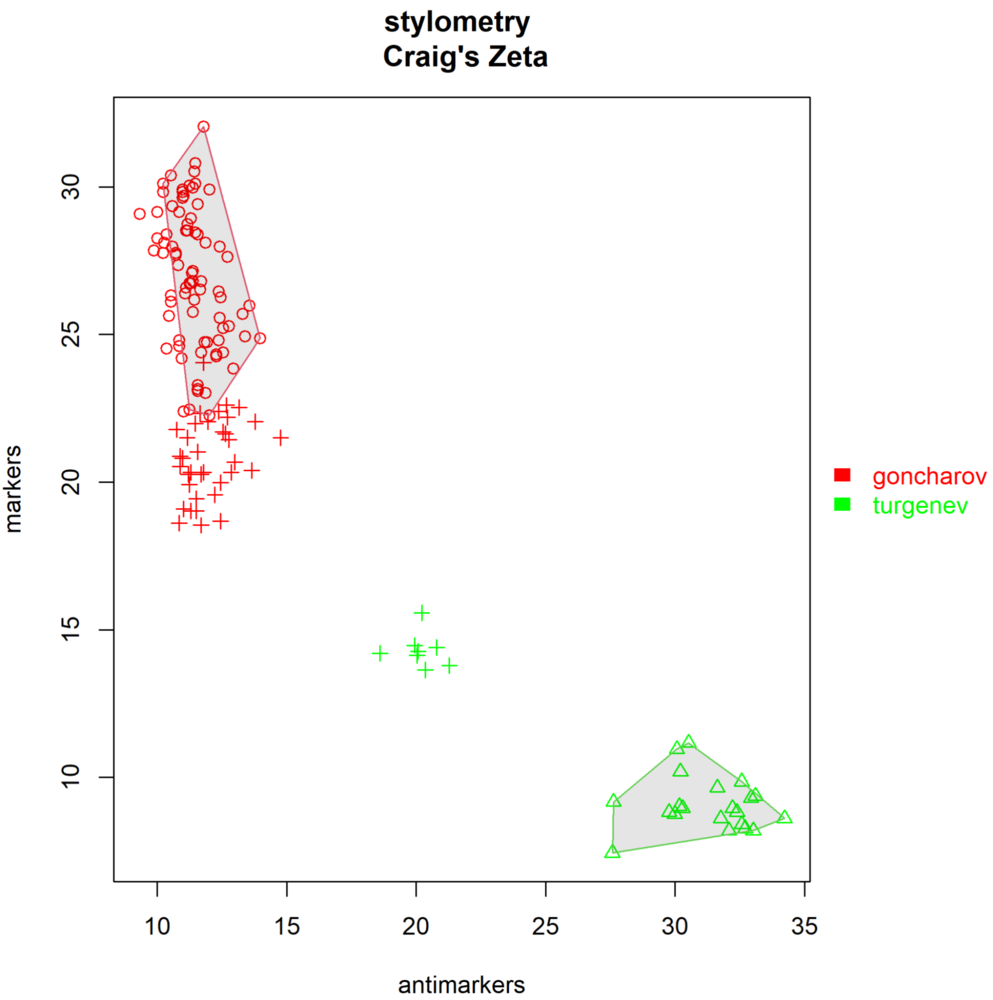
Результаты контрастивного анализа, визуализация по маркерам
Напоминаем: кружочки — все фрагменты по 5000 слов корпуса Гончарова из папки primary_set (т. е. «Обыкновенная история» и «Обрыв»), треугольнички — все фрагменты корпуса Тургенева из папки secondary_set (т. е. «Дворянское гнездо» и «Накануне»), а крестики — все тестовые тексты из test_set (красные крестики — тестовый Гончаров, т. е. «Обломов», зелёные крестики — тестовый Тургенев, т. е. «Рудин»). Как видно, в таком эксперименте и с нашими настройкам романы Гончарова пересекаются друг с другом (обратите внимание на один крестик среди кружочков), а вот романы Тургенева — немного различаются. «Рудин» из test_set находится ближе к Гончаровскому кластеру, чем «Дворянское гнездо» и «Накануне», хотя и всё равно хорошо отличим от них по распределению частотностей в zeta.
Заключение
Мы познакомились с ещё одним способом сравнения текстов. Следующим шагом можно поэкспериментировать с настройками, лемматизировать тексты и поизучать статистические меры, которые используются для контрастивного анализа.
А ещё советуем почитать подборку статей о стилометрии 🙂
Источники
- Package Stylo [Документация к библиотеке] // Cran. URL: https://cran.r-project.org/web/packages/stylo/stylo.pdf (дата обращения: 26.04.2024).
- Eder M., Rybicki J. and M. Kestemont. Stylo: a Package for stylometric analyses. [Электронный ресурс] // Computational stylistics group. 19.08.2019. URL: https://github.com/computationalstylistics/stylo_howto/blob/master/stylo_howto.pdf (дата обращения: 26.04.2024).
- Anthony L. AntConc (4.2.4) [Электронный ресурс]. Tokyo, Japan: Waseda University, 2023. URL: https://www.laurenceanthony.net/software.html (дата обращения: 26.04.2024).
- Burrows J. All the Way Through: Testing for Authorship in Different Frequency Strata. In: Literary and Linguistic Computing 22.1, 2007. Pp. 27–47.
- Электронная библиотека Royallib.com: https://royallib.com/ (дата обращения: 26.04.2024).
Полезные ссылки
- Скоринкин Д. Попрактикуемся в стилометрии [Электронный ресурс] // Github.com. 31.01.2023 URL: https://github.com/dhhse/distantreading/blob/main/stylometry/stylometry_practice.md (дата обращения: 26.04.2024).
- Eder M., Rybicki J. and Kestemont M. Stylometry with R: a package for computational text analysis [Электронный ресурс] // R Journal. 2016. № 8(1). Pp. 107-121. URL: https://journal.r-project.org/archive/2016/RJ-2016-007/index.html (дата обращения: 26.04.2024).
- Селеверстов В. Как провести корпусное исследование? Помогите! [Электронный ресурс] // Системный Блокъ. 06.08.2019 URL: https://sysblok.ru/knowhow/kak-provesti-korpusnoe-issledovanie-pomogite/ (дата обращения: 26.04.2024).
- Zeta and Company — об известных мерах, использующихся для сравнения текстов и корпусов со ссылками на оригинальные работы и научные исследования.

