Исчезающая выгода: почему прогресс LLM замедлился
Практически все известные большие языковые модели на сегодня (осень 2025 г.) основаны на архитектуре Transformer. О том, что такое архитектура модели, можно узнать в этом материале, а конкретно об архитектуре Transformer — здесь. Одним из главных достоинств этой архитектуры является ее масштабируемость. Другими словами, можно получить более качественную модель, просто увеличив ее размер и обучив на большем количестве данных.
Это редко встречаемое свойство архитектур. Часто масштабирование либо слишком сложно осуществить, либо оно не приводит к улучшениям, либо вообще негативно сказывается на модели.
Более того, для Transformer можно вывести формулы, которые показывают зависимость между размером модели/количеством обучающих данных и итоговым качеством модели. Эти формулы имеют практическое применение. Например, по ним можно рассчитать, каких размеров должны быть модель и обучающая выборка, чтобы достичь заранее заданного качества. Это полезно, поскольку обучение LLM требует огромного количества вычислений, стоимость которых составляет сотни миллионов долларов. Без этих формул исследователям пришлось бы подбирать нужную конфигурацию перебором, тратя много денег и времени. Эти формулы называются Scaling Laws (Законы масштабирования). Прочитать о них и том, как они выводятся, можно в нашем материале про языковые модели.
Другое важное знание, которое можно извлечь из этих формул, это темп роста качества модели с ростом ее размера и обучающих данных. С определенного момента темп роста качества снижается и дальнейшее наращивание размера модели и добавление данных ведут к diminishing returns (исчезающей выгоде). Другими словами, дальнейшее масштабирование модели Transformer становится невыгодным, поскольку возросшие затраты на вычисления не дают сопоставимого роста качества.
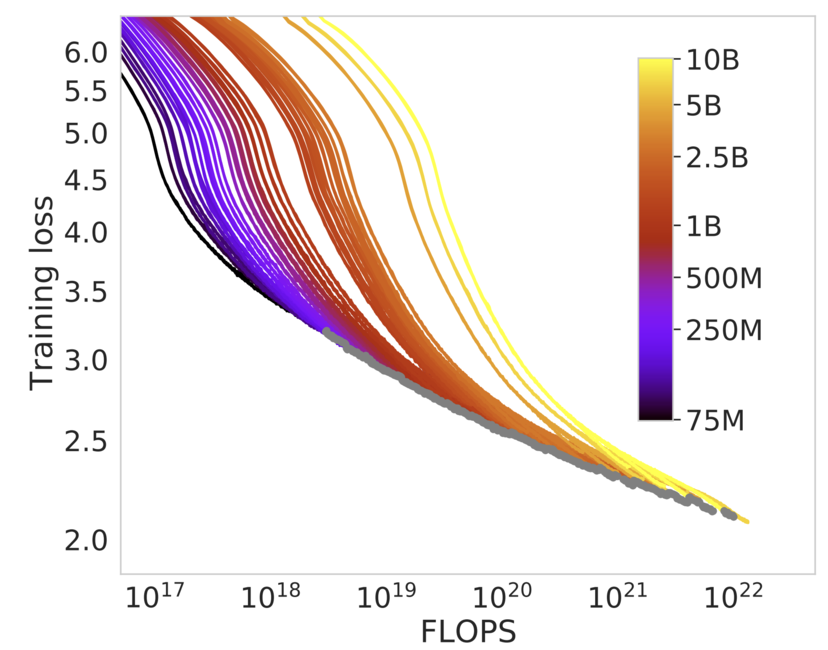
Демонстрация Scaling Laws. Каждая цветная кривая показывает, как уменьшается ошибка предсказания (training loss) у модели определенного размера (цветная шкала справа) по мере увеличения затраченных вычислений (FLOPS — операции с числами с плавающей запятой). Можно увидеть, что в начале ошибка стремительно падает даже при относительно небольшом масштабировании вычислений, но, начиная с ошибки 2.5, стократное увеличение вычислений уменьшает ошибку всего на 0.5 пункта. Источник: arxiv.org [1]
Судя по трендам развития LLM в период с 2023 по начало 2025 года, мы близки к этому моменту. Все LLM от ведущих компаний показывают в существующих тестах очень близкие результаты, а субъективная разница между разными поколениями LLM ощущается все меньше и меньше. Наглядный пример — резкий скачок в возможностях, который произошел с выходом GPT-4 по сравнению с GPT-3, и не столь драматическое различие между GPT-4 и GPT-5.
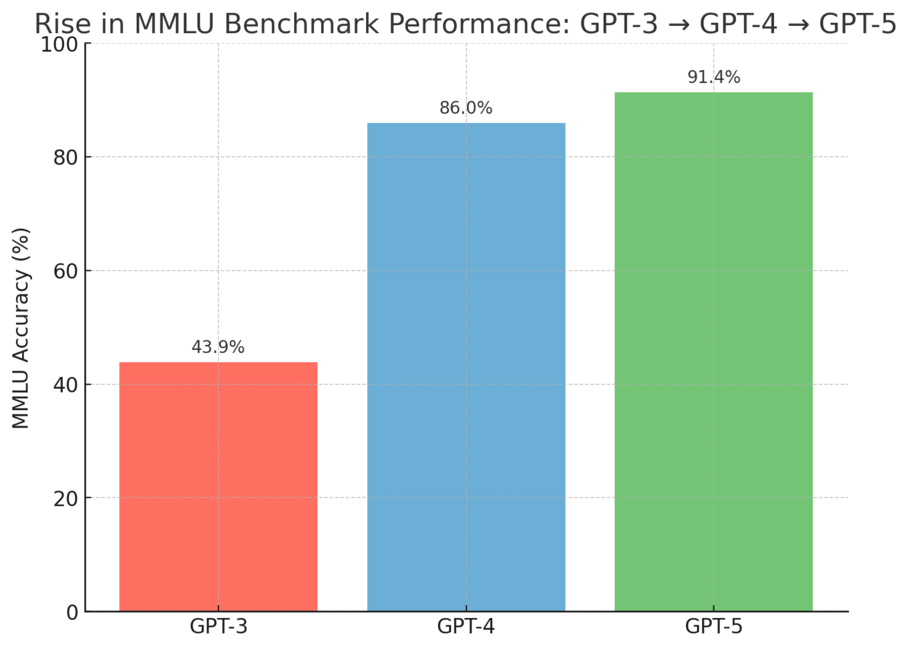
Пример: рост качества моделей на бенчмарке MMLU (Massive Multitask Language Understanding). Источники данных: [2, 3]
Новая парадигма: масштабируем вычисления во время генерации
Исследователи понимают это фундаментальное ограничение Transformer и пытаются его преодолеть. Масштабирование размера обучающей выборки и самой модели влияет только на стадию обучения модели и, как было описано ранее, со временем перестает приносить значимый прирост в качестве.
Долгое время почти не рассматривали другой путь — существенное увеличение вычислений на этапе работы модели, то есть при генерации ответа.
Независимо от сложности запроса, модели сразу начинали отвечать и использовали варьируемое, но все же в небольших пределах, количество вычислений. Поэтому исследователи решили научить модель динамически тратить больше вычислительных ресурсов во время ответа. Такой подход получил название Test-Time Compute Scaling. Test-time в названии подчеркивает, что масштабирование происходит именно на этапе тестирования (генерации ответа), а не на стадии обучения (train-time).
Количество вычислений, которые тратят модели Transformer во время ответа, линейно зависит от длины ответа: то есть количество вычислений равно длине ответа, умноженной на константу. Поэтому одним из способов «позволить» модели использовать больше ресурсов во время ответа — научить ее генерировать более длинные тексты. При этом длина ответа должна положительно влиять на качество, иначе ресурсы будут потрачены зря. Можно обучить модель генерировать не только сам ответ, но и процесс рассуждения: разбиение исходной задачи на подзадачи, планирование решения, промежуточные вычисления, перепроверку предыдущих выкладок и т. д. Такой текст, предшествующий финальному ответу, можно сравнить с человеческими рассуждениями при решении задачи. Увеличивать количество вычислений во время генерации можно и другими способами, однако в рамках этой статьи они не рассматриваются.
Также желательно иметь настройку длины рассуждений: больше рассуждений — выше качество ответа, меньше рассуждений — быстрее ответ.
Таким образом, рассуждающие языковые модели — это языковые модели, способные генерировать текст нетривиальной длины, предшествующий финальному ответу и существенно повышающий его качество.
Идея заставлять модель рассуждать «вслух» возникла еще до того, как развитие LLM замедлилось. Еще в 2022 году было обнаружено, что если попросить LLM в запросе «думать по шагам» (think step-by-step), то модель будет генерировать небольшие цепочки «рассуждений», которые значительно повышают качество ответов. Важно отметить, что модели не обучали навыку рассуждений специально: он приобретался автоматически за счет использования огромных обучающий выборок. Например, в интернете можно встретить много пошаговых разборов математических задач с ответом в конце. Скорее всего, LLM запоминают этот паттерн во время обучения и воспроизводят его, когда в промте есть слова-триггеры, например, «думай пошагово». Этот механизм похож на модель человеческого мышления «Система 1, Система 2». Система 1 позволяет человеку автоматически реагировать и отвечать на вопросы, однако часто ошибается, в то время как Система 2 тратит когнитивные усилия на более тщательное продумывание ответа.

Пример работы Chain-of-Thought промтинга. Черным выделен текст условия задачи, красным — добавки к запросам на каждом шаге, зеленым — ответы модели. Источник: sysblok.ru
Данная техника промтинга получила название Chain-of-Thought. Подробнее мы рассказывали о ней в наших материалах о том, как рассуждения помогают LLM и как использовать эту технику на практике. Рассуждающие языковые модели можно рассматривать как логичное развитие/масштабирование подхода Chain-of-Thought.
Получилось ли у исследователей решить проблему diminishing returns? Однозначно ответить сложно: область рассуждающих LLM только появилась и активно развивается. Однако уже сейчас можно сказать, что использование рассуждений в некоторых случаях действительно эффективнее масштабирования вычислений во время обучения. По словам генерального директора Anthropic, одной из главных ИИ-лабораторий, компании только начали вкладываться в обучение рассуждающих моделей. Затраты на это пока невелики, но такой подход уже приносит существенный рост качества, поэтому компании стремятся его масштабировать.
Как обучить языковую модель рассуждать?
Рассуждение — нетривиальный и долгий процесс. Из-за этого сложно собирать качественные рассуждения вручную (особенно в большом объеме) и автоматизировать этот процесс тоже не так просто. Поэтому в основном используют два метода обучения:
- генерация цепочек рассуждений существующими моделями и обучение на них,
- использование методов обучения с подкреплением (Reinforcement Learning, RL). Об RL мы рассказывали ранее в этом материале.
Первый метод
Выше мы рассказывали о способности моделей генерировать короткие промежуточные рассуждения с помощью техники промтинга Chain-of-Thought. Рассмотрим, как эта техника позволяет собирать синтетические (т. е. нечеловеческие) данные для обучения.
1. Собираем набор промтов. К примеру, промтами могут быть условия математических задач. Помимо самих условий, у нас должны быть верные ответы к задачам.
2. С помощью Chain-of-Thought промтинга генерируем цепочки рассуждений для всех промтов из нашего набора и извлекаем финальные ответы.
3. Фильтруем полученные цепочки рассуждения, сверяя ответы с верными. Если ответ верный, то цепочка тоже верная (что на самом деле не всегда так), если ответ неверный, то цепочка отбрасывается.
В конце остается дообучить нашу модель на отфильтрованных цепочках рассужденией.
Мы получим модель, которая умеет генерировать относительно короткие рассуждения для конкретного типа задач. Стоит отметить, что фильтровать данные можно, не только сверяя полученный и верный ответы. Есть множество задач, где верный ответ сложно получить заранее. Например, в задаче перевода не всегда есть качественный перевод от специалиста-человека. В подобных случаях можно использовать LLM как оценщик ответов по заранее заданным критериям.
У этого способа есть очевидный недостаток: мы ограничены способностями модели, которую используем для генерации обучающих данных.
Второй метод
Этот метод более сложный и вычислительно затратный, но имеет ряд преимуществ.
Процесс обучения упрощенно выглядит так:
1. Собираем промты для обучения, а также определяем алгоритм оценки результата. Например, для математических задач с численным ответом даем оценку 1, если ответ правильный, и 0, если нет. А для задач, где ответ нельзя просто сверить с верным, можно использовать LLM как оценщик.
2. На каждом шаге обучения просим модель сгенерировать промежуточные рассуждения и ответ. При этом рассуждения и ответ должны быть расположены в специально выделенных местах сгенерированного текста. Например, промт может выглядеть так:
Реши следующую задачу: {Текст условия задачи}. Перед финальным ответом помести все свои рассуждения между тегами “<think>” и </think>”, а финальный ответ между тегами “<answer>” и </answer>”.
Корректный с точки зрения промта ответ будет выглядеть следующим образом:
<think>Рассуждения модели касательно задачи, например, промежуточные вычисления</think>
<answer>Число – ответ на данную задачу</answer>
3. Далее для ответа модели считается оценка (она же «награда» в терминах обучения с подкреплением). Оценка составляется, исходя из следования формату ответа и правильности ответа.
Например, критерии формата могут быть следующими:
- 0 баллов, если нет блока <think></think> и/или блока <answer></answer>, или оба из них пустые
- 1 балл, если есть один не пустой блок
- 2 балла, если оба блока не пустые и при этом внутри <answer></answer> находится число, а не текст
Если модель соблюла формат ответ, то финальная оценка — это сумма баллов за формат и за правильность ответа, рассчитанных по алгоритму из пункта 1. Например, если модель соблюла формат и получила верный итоговый ответ, то оценка равна: 2 + 1 = 3 балла. Если же модель не последовала данному ей шаблону ответа, то даже за правильный ответ дополнительные баллы даваться не будут.
4. С помощью математических методов на основе входных данных и оценки из пункта 3 обновляем модель таким образом, чтобы награды на следующих шагах были выше. Для простоты изложения мы опустим детали этих методов.
5. Повторяем шаги 1-4 N раз.
В отличие от первого метода, когда модель обучается на фиксированных данных, второй подход итеративный. Модель генерирует ответы и учится на них, постепенно улучшая качество. Множество работ показало, что второй метод дает более высокие и надежные результаты. На данный момент второй метод используется практически всеми разработчиками рассуждающих моделей.
Первую успешную рассуждающую модель выпустила компания OpenAI, она получила название o1. О деталях ее создания известно мало, в частности, неизвестно, как именно ее обучали рассуждать. Через несколько месяцев компания Deepseek смогла создать большую рассуждающую языковую модель DeepSeek R1. Компания выложила в открытый доступ как саму модель, так и статью, детально описывающую масштабируемый способ обучения рассуждению. Это позволило open-source разработчикам создавать свои собственные рассуждающие модели.
Проблемы и ограничения рассуждающих моделей
У этого типа моделей есть большой ряд проблем, которые пока не научились решать.
1. Модели избыточно много рассуждают. Например, в случае простых вопросов они могут выдавать несколько страниц рассуждений. Лишние рассуждения увеличивают время ожидания ответа, зря тратят ресурсы и порой «сбивают модель с толку», тем самым приводя ее к ложным ответам. Периодически модели не могут остановиться и генерируют бесконечный текст.
2. Рассуждения не всегда осмысленные. Часто модели генерируют несвязный, нелогичный текст или переходят с одного языка на другой. Например, команда DeepSeek часто наблюдала переход с английского на китайский в текстах рассуждений. Попытки делать рассуждения моноязычными привели к снижению качества финальных ответов. Причины такого поведения модели можно частично объяснить особенностями второго метода обучения, описанного выше.
3. Рассуждения не всегда отражают действительные механизмы работы модели.
Например, Anthropic выяснили, что если в промте указать ответ на вопрос, то часто модель подгоняет свои рассуждения к данному ей ответу, но не будет явно указывать, что взяла ответ из промта. Эта проблема особенно актуальна с точки зрения безопасности и интерпретируемости: рассуждения модели не помогают понять ее «поведение» и решения. Поэтому стоит воспринимать рассуждения моделей лишь как вспомогательный текст, а не реальный «ход мыслей», объясняющий финальный ответ.
4. Естественный язык не является оптимальным языком для рассуждений. Во-первых, плотность информации в естественных языках относительно не высокая. Во-вторых, процесс рассуждения у людей предшествует формулированию мысли посредством языка. Поэтому уже сейчас некоторые исследователи пытаются научить языковые модели выражать рассуждения не на естественных языках, а с помощью последовательности неинтерпретируемых векторов (наборов чисел).
Источники
- Hoffmann, J. et al. (2022) ‘Training Compute-Optimal Large Language Models’. Available at: https://arxiv.org/abs/2203.15556.
- Hendrycks, Dan; Burns, Collin; Basart, Steven; Zou, Andy; Mazeika, Mantas; Song, Dawn; Steinhardt, Jacob (2021). «Measuring Massive Multitask Language Understanding». ICLR. arXiv:2009.03300
- Datura, E. (2025) ‘Why MMLU Remains the Most Honest AI Benchmark in 2025’, Graphlogic, 7 September. Available at: http://10.1.18.16:8080/blog/ai-trends-insights/mmlu-benchmark-llm-language-understanding/ (Accessed: 13 September 2025).