Введение
В эпоху искусственного интеллекта многие задаются вопросами: что если бы компьютеры могли самостоятельно исследовать окружающий мир, экспериментировать и корректировать свои действия на основе реального опыта?
На самом деле такой подход уже давно существует и активно развивается. Он называется обучением с подкреплением (от англ. Reinforcement Learning, сокращённо RL), и его принципы очень похожи на то, как мы, люди, учимся в реальном мире. В этом методе модель начинает «жизнь» без предварительных знаний о своей среде и, подобно ребёнку, находит оптимальные действия методом проб и ошибок.
RL-исследования позволили совершить прорыв в машинном обучении. Одна из самых впечатляющих его демонстраций — программа от компании Google Deep Mind, AlphaGo, которая смогла обыграть Ли Седоля, мирового чемпиона в игре го. Долгое время считалось, что компьютеры не могут победить человека в этой древней настольной игре из-за её глубокой стратегической сложности и огромного количества комбинаций ходов. Это стало возможно благодаря методам обучения с подкреплением, которые позволили машине реагировать на изменения на игровом поле и постоянно совершенствовать собственные стратегии.

Доска для игры в го — пример стратегической сложности с более чем 10^170 возможными позициями, что превосходит их количество в шахматах. Источник: https://fortune.com/2016/01/27/google-deepmind-chinese-go/
Что же стоит за успехом? Эта статья открывает серию материалов, посвящённую обучению с подкреплением. Мы начнём с разбора основ и постепенно перейдём к более сложным вопросам, чтобы понять, как именно устроено обучение с подкреплением и почему оно играет одну из ключевых ролей в развитии машинного обучения.
Основные понятия обучения с подкреплением
В основе обучения с подкреплением лежат несколько ключевых понятий: окружение, состояние, aгент, действие, награда. Эти понятия формируют фундамент, на котором строится процесс обучения.
Окружение — это среда, в которой действует агент. Оно может быть как физическим (например, комната для робота-пылесоса или тестовый полигон для машины с автопилотом), так и виртуальным (среда, в которой существует персонаж компьютерной игры). Окружение описывается состоянием, которое предоставляет информацию о том, что сейчас происходит вокруг агента.
Состояние — это описание окружения в момент времени, понятное компьютеру. Например, в игре «змейка» состояние может быть описано как таблица чисел, где каждая клетка обозначает либо пустоту, либо часть змейки, либо еду.
Агент — это сущность, выполняющая действия в окружении. Агент может быть программой, роботом, нейросетью. Агент совершает действия на основе информации о состоянии окружения. Действия могут менять состояние окружения. Цель агента — действовать таким образом, чтобы максимизировать суммарную награду.
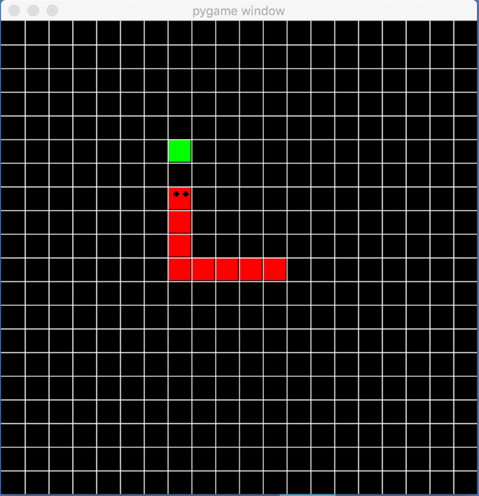
Игра «змейка». Источник: medium.com
В контексте той же игры «змейка» действиями могут быть движение вверх, вниз, влево или вправо.
Награда — это сигнал от окружения, который оценивает эффективность действий агента. Награды могут быть положительными, если действия агента приближают его к цели, и отрицательными, если действия отдаляют от неё (но не всегда — в некоторых случаях награда бывает только неотрицательной). Награды неявно указывают агенту, как ему нужно действовать.
Каждое действие агента влияет на окружение и будущие награды, поэтому выбор действия — ключевой элемент в обучении с подкреплением. Агент решает, как поступить дальше, опираясь на свой план, который направлен на достижение наилучших результатов и называется политикой. Важно выбирать действия, которые помогут максимизировать общее количество наград. Хотя агент и не «думает» в привычном нам смысле, он применяет свою политику для выбора следующих шагов.
Обучение с подкреплением: шаг за шагом
Механизм обучения с подкреплением можно разбить на пять основных этапов. Представим такой контекст: нашему компьютеру «дали задание» — сыграть с человеком партию в шахматы. Цель для агента — обыграть человека, то есть дойти до конца шахматной доски. Поставленной задачи агент будет достигать с помощью пяти шагов:
- Компьютер анализирует доску — это его окружение. Положение фигур на доске определяет состояние окружения. Каждое новое состояние окружения требует от агента определённого действия (хода).
- Компьютер, основываясь на текущей стратегии, совершает действие (делает ход). В начале обучения выбор действий может быть случайным, но со временем по мере «накопления» опыта компьютер начинает делать более «обдуманные» и стратегические ходы.
- Действие агента изменяет положение фигур на доске или, другими словами, меняет состояние окружения.
- После сделанного хода компьютер получает обратную связь (награду). Если ход приводит к улучшению позиции или взятию фигуры противника, это может рассматриваться как положительная награда. Если же ход приводит к потере фигуры или ухудшению позиции, обратная связь будет отрицательной.
- Агент анализирует результаты своих действий и обновляет стратегию, чтобы улучшить будущие результаты. Это похоже на то, как шахматист продумывает свой следующий шаг, основываясь на ходах соперника и текущем состоянии доски. Как именно происходит обновление стратегии, мы поговорим немного позже — во второй статье, посвящённой RL.
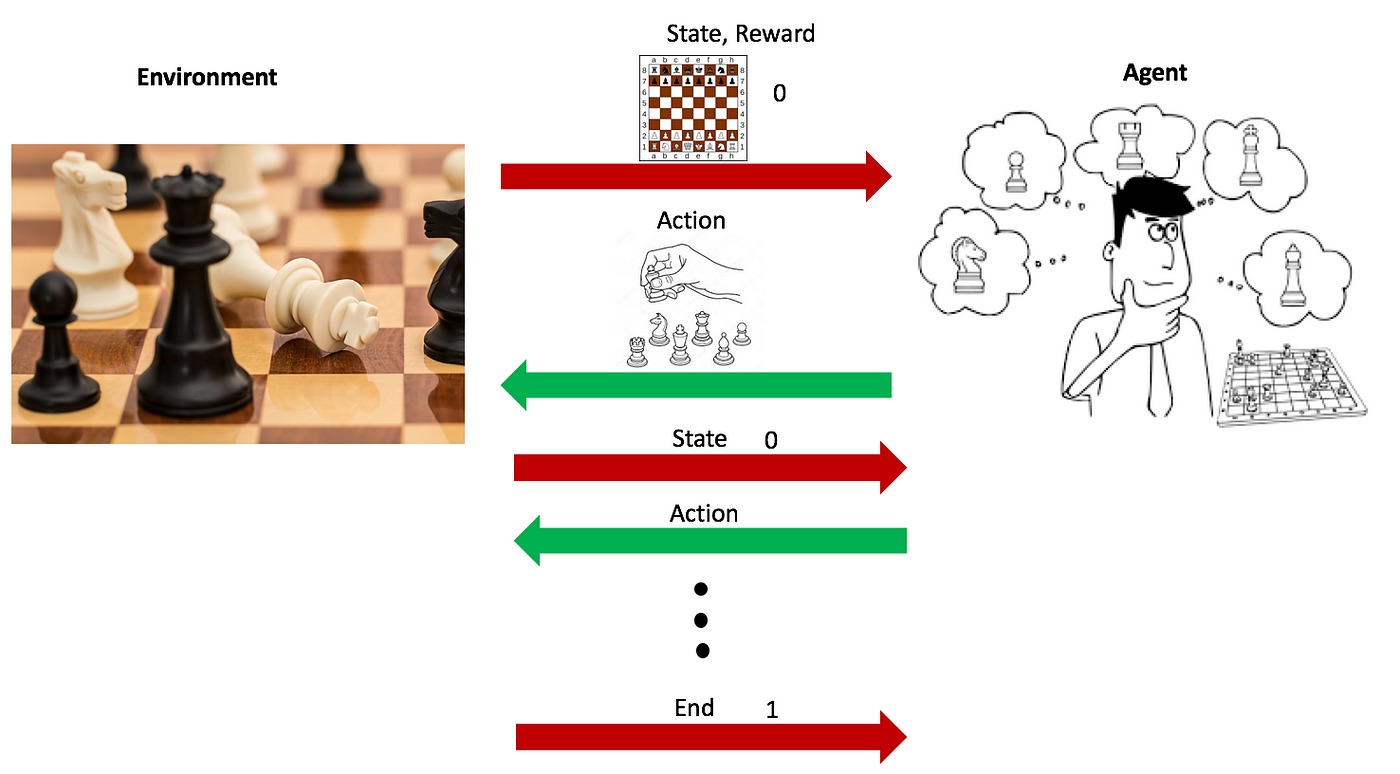
Иллюстрация процесса обучения с подкреплением на примере шахматной партии: анализ состояния доски, выбор оптимального хода и получение награды для постепенного улучшения стратегии и достижения победы. Источник: towardsdatascience.com
Повторяя эти шаги множество раз, компьютер-агент «тренируется» в игре против человека, становясь всё более продвинутым в шахматной тактике и стратегии. Со временем он научится разрабатывать стратегии, которые увеличивают его шансы на победу, улучшая свою способность действовать в сложной среде шахматной партии.
Чем уникально обучение с подкреплением?
Теперь, когда мы определили основные понятия, становится ясно, чем обучение с подкреплением отличается от других видов машинного обучения. При обучении с учителем модель учится на основе предварительно размеченных данных, в которых для каждого обучающего примера есть заранее известный правильный ответ, который должна выдать модель. Например, если мы обучаем модель классифицировать картинки животных, то каждой картинке в обучающем наборе данных будет соответствовать метка, указывающая на вид животного на картинке. Задача модели — научиться предсказывать правильную метку для новых, ранее не виденных изображений на основе изученных во время обучения закономерностей.
Модели, обучаемые без учителя, ищут закономерности в данных без информации о «правильных ответах». Пример задачи обучения без учителя — задача кластеризации, которая заключается в группировке данных по «сходству», которое заранее никак не определяется. Алгоритм может анализировать большой набор данных о покупках пользователей и группировать эти данные в кластеры на основе схожести покупательских привычек, не имея заранее заданных категорий или меток.
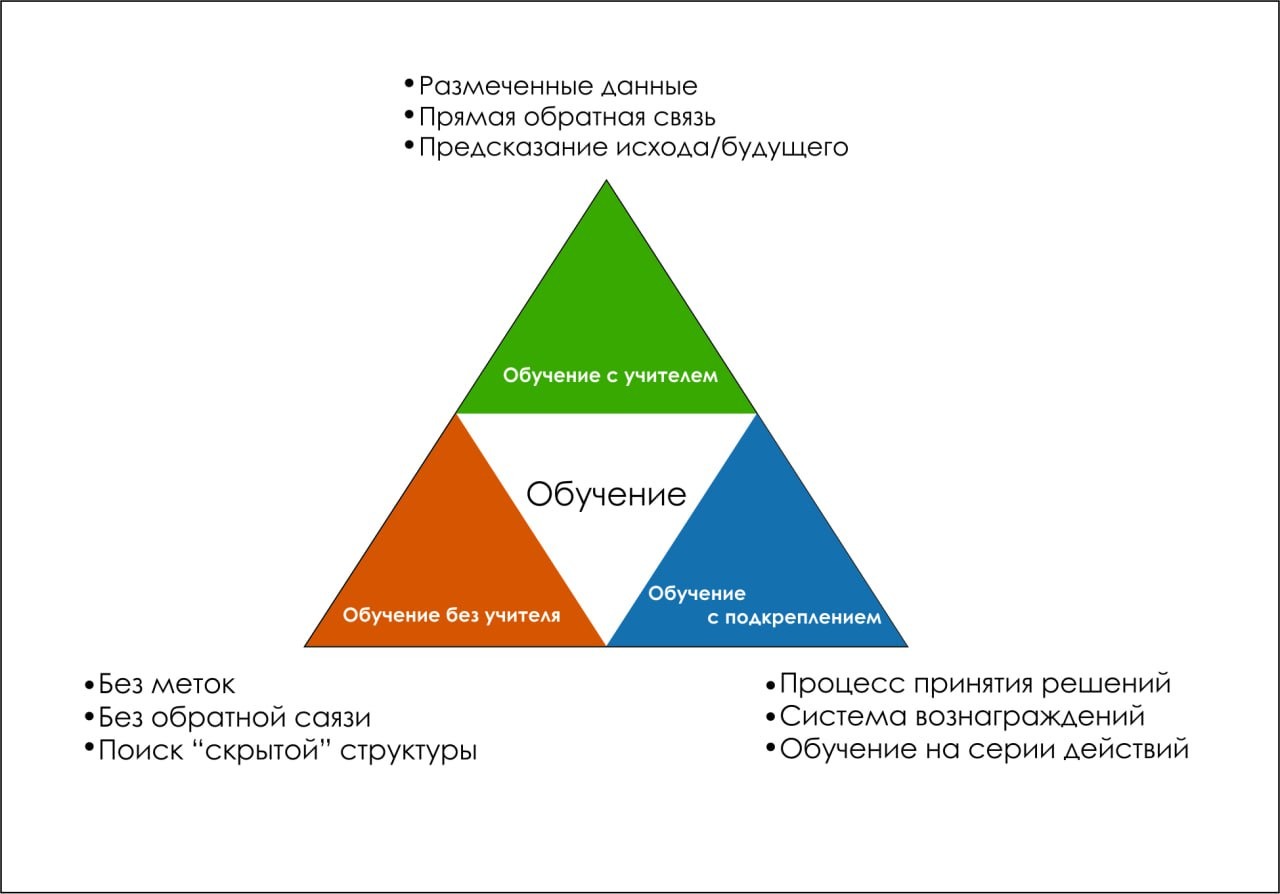
Парадигмы машинного обучения. Источник: medium.com
В отличие от этих подходов, обучение с подкреплением не опирается на заранее определённый набор данных. Агент активно взаимодействует с окружением и учится на основе проб и ошибок, динамически собирая данные. Этот процесс позволяет ему исследовать среду и адаптировать своё поведение для достижения целей, что делает его особенно подходящим для ситуаций с постоянно меняющейся средой. Таким образом, агент не просто учится на основе данных: он сам формирует их в процессе взаимодействия со средой.
Подводя итог первой части нашего обзора обучения с подкреплением, мы заложили фундамент для понимания того, как модели машинного обучения развиваются через опыт.
В следующей статье мы детально рассмотрим алгоритмическую составляющую обучения с подкреплением на примере базового метода Q-Learning. Мы выясним, как именно агенты, будучи в новой для себя среде, учатся на своих ошибках, принимают решения и постепенно двигаются к цели, усваивая уроки из каждого своего действия.