
Что такое оптическое распознавание символов
Оптическое распознавание символов (англ. optical character recognition, OCR) — это преобразование отсканированных документов в машиночитаемый текст, по которому можно искать и который можно редактировать.
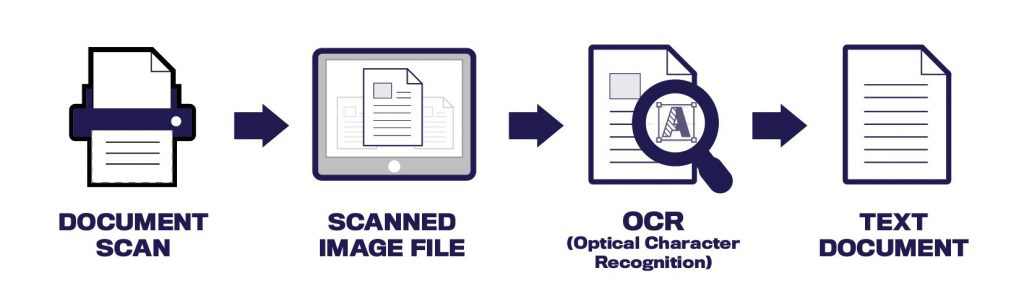
Превращение цифровых копий книг в распознанный машиночитаемый текст предлагает три этапа:
- сбор коллекции отсканированных документов;
- распознавание текста в документах с помощью инструментов OCR и сохранение его результатов в выбранном машиночитаемом формате;
- вычитка и сверка текстов с исходными документами, опционально также количественная оценка качества OCR.
Мы подготовили инструкцию по каждому из этих этапов и ссылки на полезные ресурсы для выполнения проекта.
СОДЕРЖАНИЕ
- Сбор корпуса оцифрованных текстов
- Распознавание текста с помощью OCR
- Программное обеспечение
- Преобразование PDF-файлов в текстовый формат
- Оценка качества результатов OCR
Сбор корпуса оцифрованных текстов
На первом этапе производится сбор коллекции электронных копий изданий, которые можно найти в открытом доступе.
a. Ознакомьтесь с форматом библиографических описаний в каталоге. В нём представлены сочинения из разных типов изданий:
- книжные издания, например, Вопросы по изученiю повѣрiй. Потанина. Спб. 1881 г.;
- сочинения, входящие в состав периодических изданий, например, Островъ Сахалинъ и его каменноугольныя копи. Кеппена. (Гор. Ж. 75 г. VII-XI).
Обычно сканы отдельных статей из газет и журналов недоступны, поэтому следует искать выпуски соответствующего периодического издания, указанные в библиографическом описании статьи. Ссылка на них даётся в конце описания в скобках. Список используемых сокращений представлен в начале каталога.
b. Найдите и загрузите доступные электронные копии изданий в формате PDF.
Ниже приведены ссылки на некоторые ресурсы, где можно найти оцифрованные копии книжных и периодических изданий.
- Национальная электронная библиотека (НЭБ)
- Wikimedia Commons
- Электронная библиотека (репозиторий) Томского государственного университета
- Государственная публичная историческая библиотека (ГПИБ)
- Свердловская областная универсальная научная библиотека им. В. Г. Белинского
- Научная библиотека ИГУ
c. При скачивании файлов убедитесь, что их содержание соответствует запросу.
Например, сравните выходные данные, указанные на первой странице издания, с библиографическим описанием и проверьте, что количество страниц в файле соответствует ожидаемому числу страниц издания.
d. При необходимости переименуйте загруженный файл и дайте ему осмысленное название.
Например, Экономическое_состояние_городских_поселений_Сибири.pdf
e. Добавьте в таблицу с метаданными запись о сочинении из загруженного документа.
Структура таблицы с метаданными
| Название | Автор | Год издания | Издательство | Родительское издание | Сведения об ответственности | Библиотека |
Распознавание текста с помощью OCR
На втором этапе собранные файлы с отсканированными копиями преобразуются в текстовые документы в машиночитаемом формате с помощью технологии OCR.
Для оптического распознавания текста существуют разные инструменты, в том числе консольные программы и инструменты «из коробки» (например, десктопные и мобильные приложения, веб-приложения). Разберём процесс выполнения оптического распознавания символов с использованием двух разных программных решений: приложения ABBYY FineReader PDF и библиотеки Tesseract OCR.
Программное обеспечение: ABBYY FineReader PDF

ABBYY FineReader PDF — наиболее развитое приложение для оптического распознавания символов, которое позволяет конвертировать графические документы (например, фотографии, сканы, файлы PDF) в редактируемые электронные форматы (например, plain-text файлы, Microsoft Word).
Примеры действий в следующих разделах выполнены в программе ABBYY FineReader PDF версии 15.
Преобразование PDF-файлов в текстовый формат с помощью ABBYY FineReader PDF
а. После открытия приложения в общем меню навигации выберите опцию Открыть в OCR-редакторе.
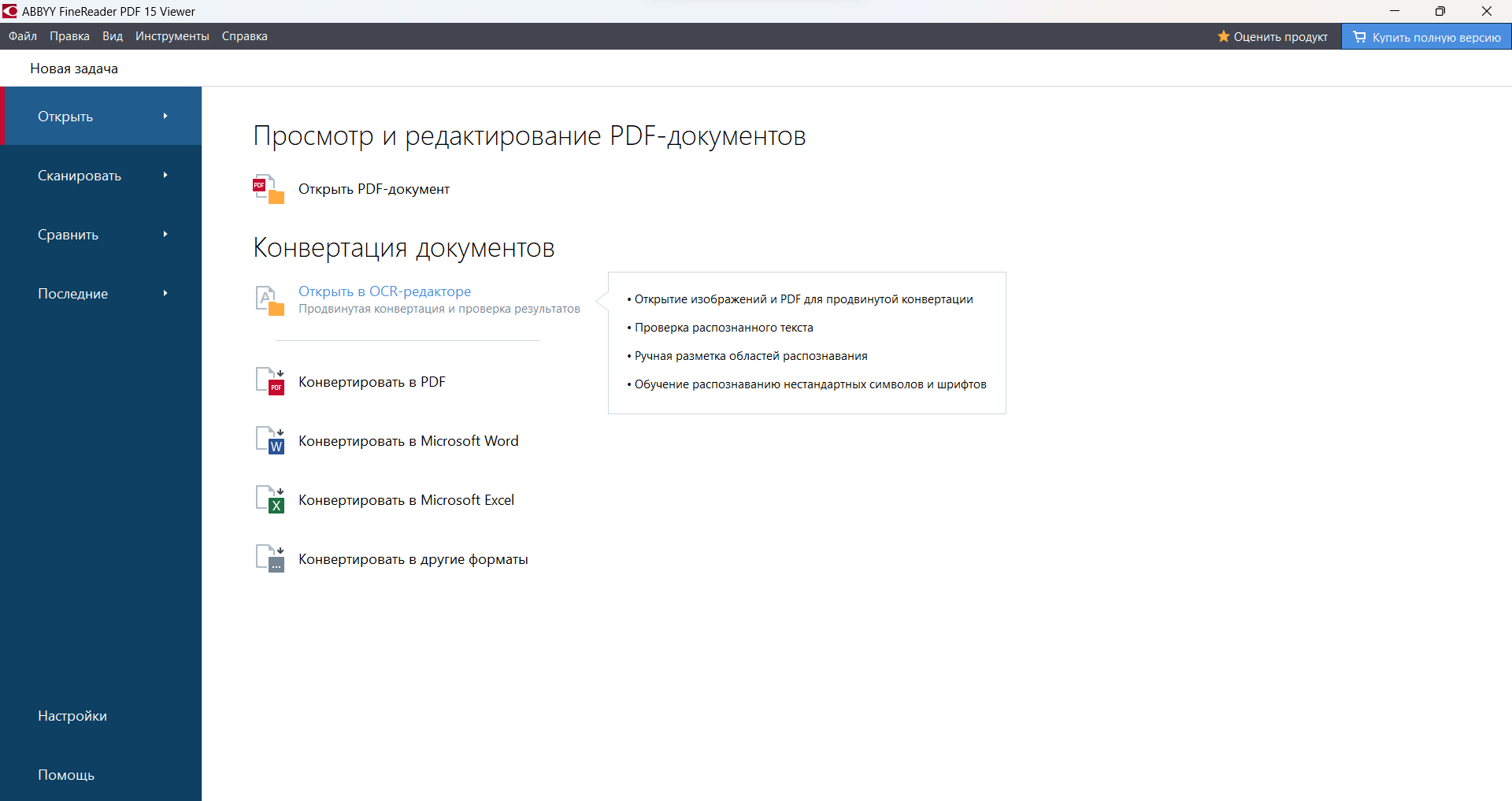
b. Выберите файл для распознавания.
Запустится интерфейс редактора изображений, в котором можно настроить параметры и области распознавания, выбрать формат вывода и выполнить вычитку и сверку результатов распознавания.
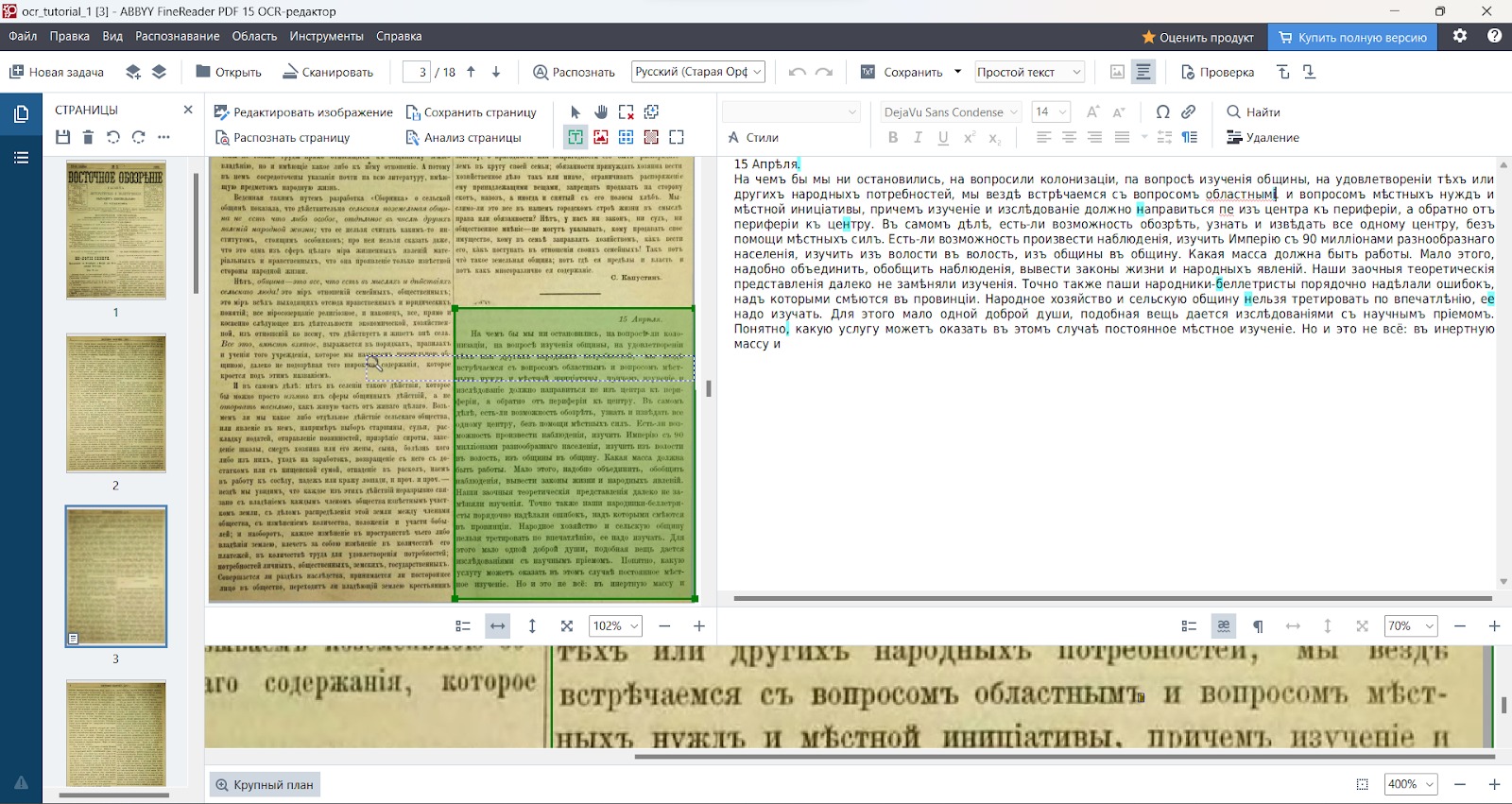
Интерфейс редактора изображений разделён на три основных области:
- панель изображений, расположенная слева на экране;
- текстовая панель, расположенная справа;
- панель «Крупный план», расположенная в нижней части экрана.
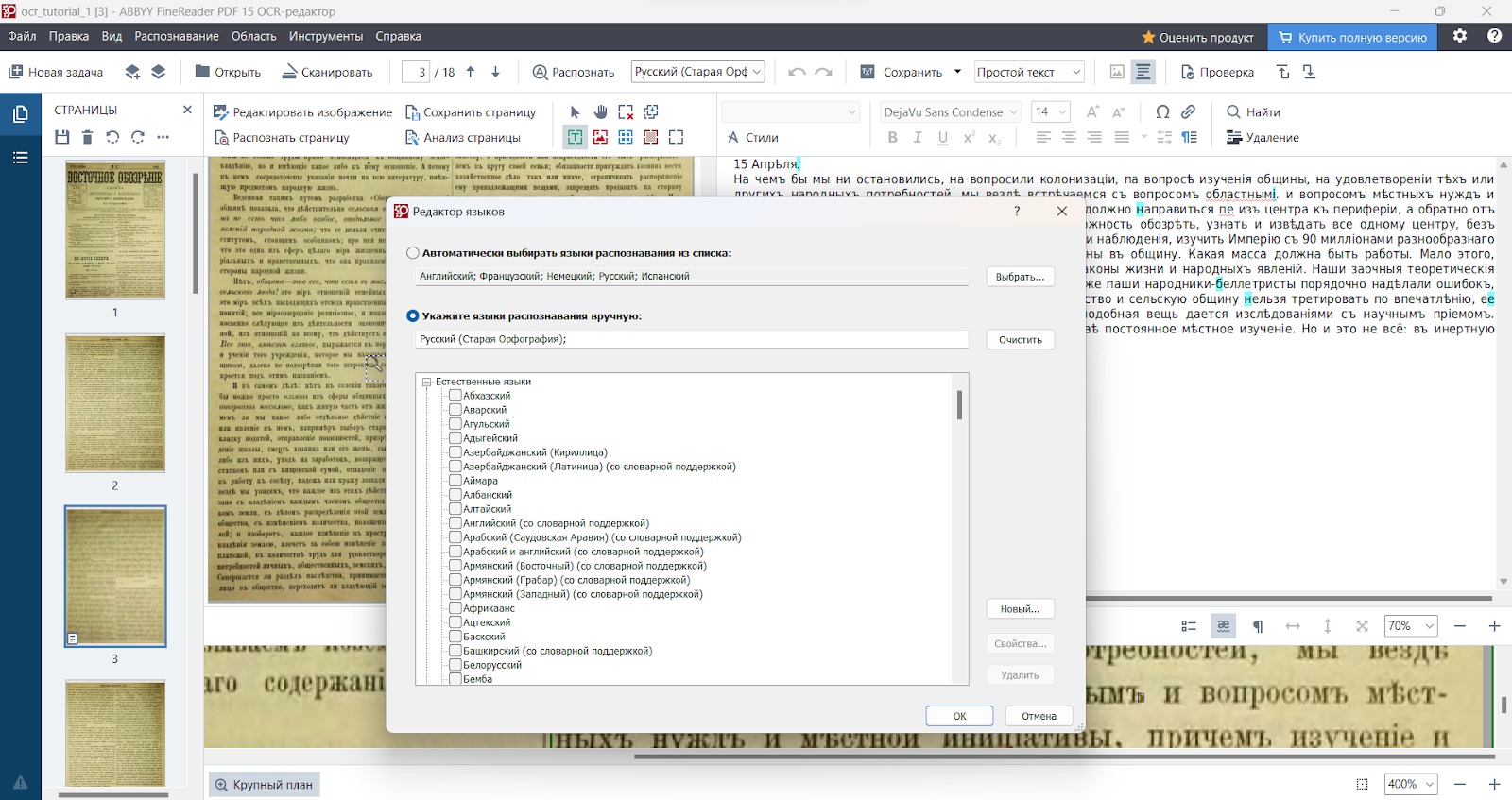
с. На панели главной инструментов есть поле Редактор языков. В раскрывающемся меню выберите опцию Полный список языков и укажите Русский (Старая орфография), сохраните изменения.
d. В раскрывающемся меню поля Тип сохранения выберите опцию Простой текст.
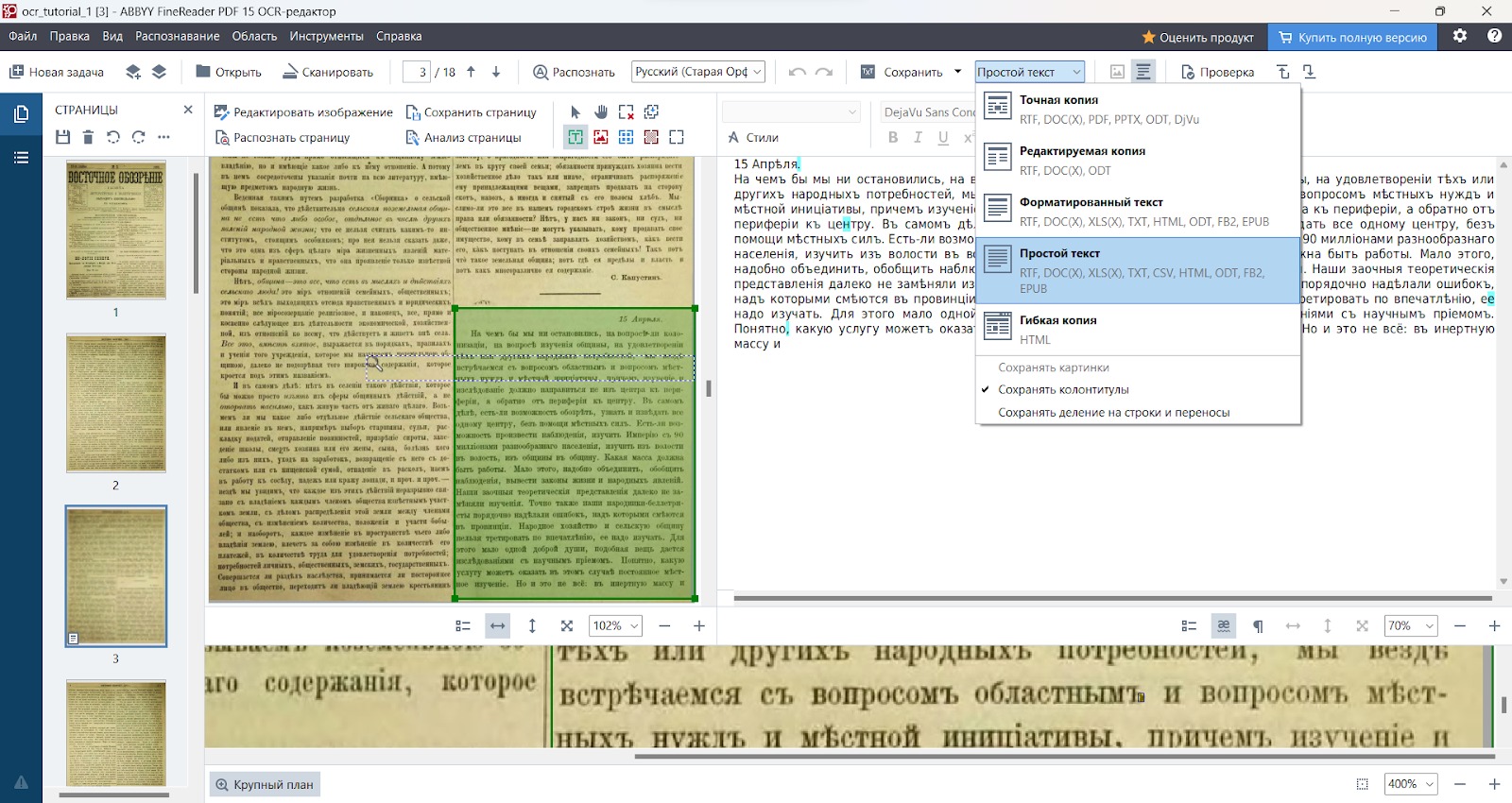
e. Используйте инструменты в верхней части Области изображений и при необходимости настройте границы и тип области распознавания.
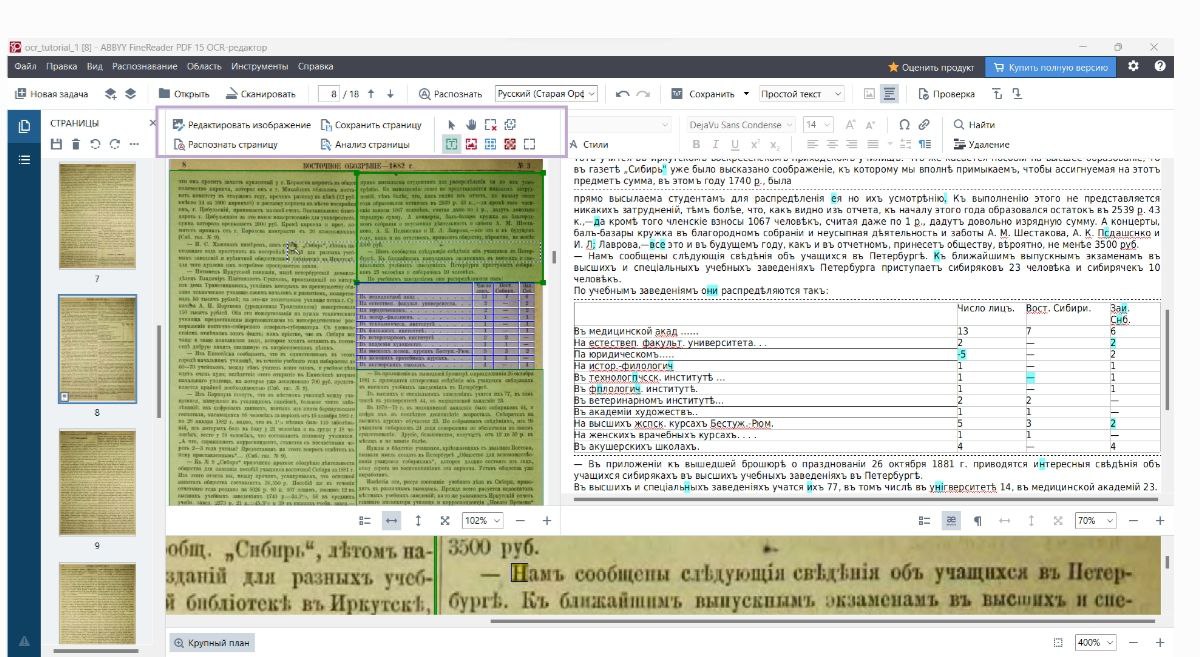
Чтобы выбрать область, нажмите на кнопку соответствующего типа области и выделите всю область текста, таблицы или изображения, которую нужно распознать.
Для более точного определения границ области можно использовать панель Крупный план.
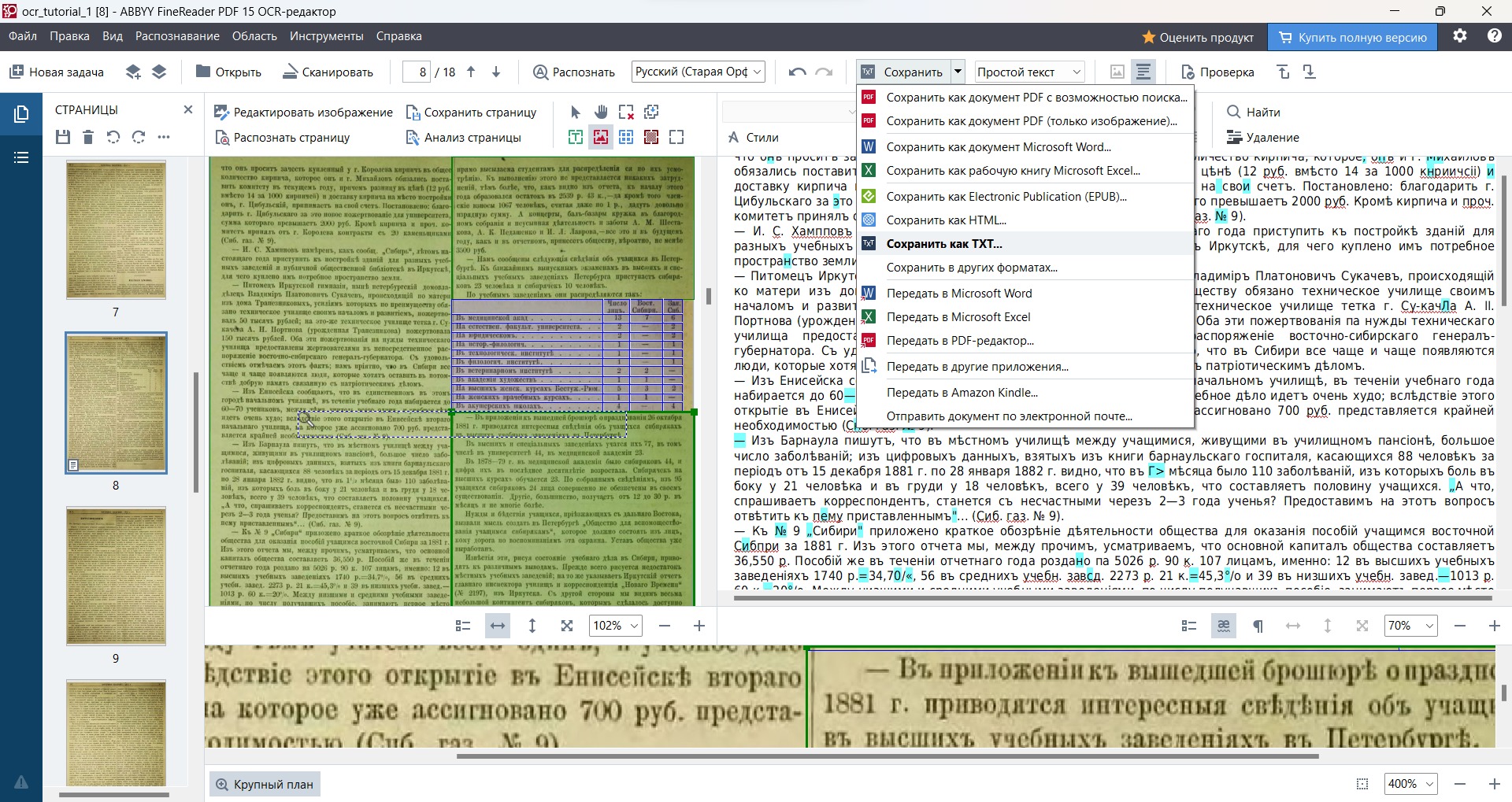
d. На главной панели инструментов нажмите Сохранить и выберите опцию Сохранить как TXT. Дайте файлу осмысленное название и сохраните его в каталог с необработанными распознанными текстами.
e. Чтобы позже количественно оценить качество распознавания текстов с помощью OCR, нужно подготовить золотой стандарт.
Сверьте текст с распознаваемого изображения в Панели изображений с результатом распознавания в Текстовой панели и исправьте несоответствия.
Чтобы проверить потенциально ошибочно распознанное слово, щёлкните на него в Текстовой панели. Область изображения с этим словом будет выделена в Панели изображений, а на панели Крупный план будет увеличенное отображение этого слова.
f. После окончания вычитки и сверки текстов нажмите кнопку Сохранить на главной панели инструментов и выберите опцию Сохранить как TXT. Дайте файлу осмысленное название и сохраните его в отдельный каталог с вычитанными текстами.
Программное обеспечение, альтернатива: Tesseract (если FineReader не подходит по финансовым или идеологическим соображениям)
Tesseract OCR — это одна из наиболее мощных программных библиотек с открытым исходным кодом для оптического распознавания текста (OCR). Она разработана для извлечения текста из растровых изображений и его преобразования в машиночитаемый формат.
С Tesseract можно работать через командную строку или с использованием Python-оболочки (pytesseract). У Tesseract нет встроенного графического пользовательского интерфейса, но доступны варианты от сторонних разработчиков, например, gImageReader.
В следующем разделе будет описан процесс оптического распознавания текста из PDF-файла с помощью Tesseract через командную строку. Примеры приведены для операционной системы Linux.
Преобразование PDF-файлов в текстовый формат с помощью Tesseract
a. Установите Tesseract OCR и ImageMagick.
ImageMagick — это инструмент для обработки и редактирования изображений. Он необходим для приведения многостраничных PDF-документов и/или PDF-файлов без встроенного текстового слоя к формату, с которым может работать Tesseract. Кроме того, ImageMagick предоставляет инструменты для предобработки и улучшения качества изображений.
sudo apt install tesseract-ocr sudo apt install imagemagick
b. Установите необходимые языковые пакеты для Tesseract.
sudo apt install tesseract-ocr-[lang]
В команде выше замените [lang] на код соответствующего языка. Полный список доступных в Tesseract языков и алфавитов можно найти в документации. Так, например, будет выглядеть команда для загрузки пакета с русским языком:
sudo apt install tesseract-ocr-rus
Проверить список уже установленных языковых пакетов можно, выполнив команду:
tesseract --list-langs
c. Приведите PDF-документ к формату TIFF c помощью утилиты convert из пакета ImageMagick.
TIFF (Tagged Image File Format) — это формат, который используется для хранения растровых изображений.
convert input_file output_file
Замените input_file и output_file на имя входного PDF-файла и имя, которое должно быть присвоено полученному TIFF-изображению, или укажите пути к ним.
Во время конвертации можно настраивать параметры итогового TIFF-изображения, чтобы улучшить его качество.
convert -density 300 input_file -depth 8 -background white -alpha off output_file
Выше приведён пример команды со следующими параметрами:
- -density 300: параметр разрешения изображения.
Согласно общим рекомендациям, оптимальное разрешение для сканов документов — 300 dpi (точек на дюйм) или выше (400–600 dpi), если размер шрифта менее 10 пунктов.
- -depth 8: параметр цветовой глубины изображения (в битах на канал).
Для текстовых документов обычно применяют градацию серого (grayscale) или чёрно-белый (1-bit) режим.
- -background white: параметр цвета фона изображения.
- -alpha off: параметр уровня прозрачности.
Для обработки изображений с помощью OCR-программ рекомендуется устанавливать белый цвет для фона и удалять альфа-канал (канал прозрачности).
d. Извлеките текст из документа в формате TIFF с помощью Tesseract и сохраните в файл.
tesseract input_file output_file -l [lang]
Замените input_file и output_file на имя TIFF-изображения и имя, которое должно быть присвоено файлу с извлечённым текстом, или пути к ним. Чтобы указать язык распознавания, используйте флаг -l и замените [lang] на соответствующий код.
Если в документе есть текст на разных языках, то их коды необходимо указать через знак «+». Например, если в документе содержится текст на русском и французском языках, то команда будет выглядеть так:
tesseract input_file.tiff output_file.txt -l rus+fra
e. Выполните сверку распознанного текста с текстом из исходного PDF-документа и исправьте несоответствия.
Если предполагается дальнейшая количественная оценка эффективности оптического распознавания текста с помощью Tesseract OCR, то перед вычиткой создайте копию текстового файла с необработанными результатами.
Оценка качества результатов OCR
Третий этап — оценка качества распознавания текстов, выполненного с помощью OCR.
Для количественной оценки согласованности результатов OCR с эталонными данными используются следующие метрики:
Precision (Точность)
- показатель доли правильно распознанных символов относительно всех символов, которые OCR-система определила как символы;
- Precision =

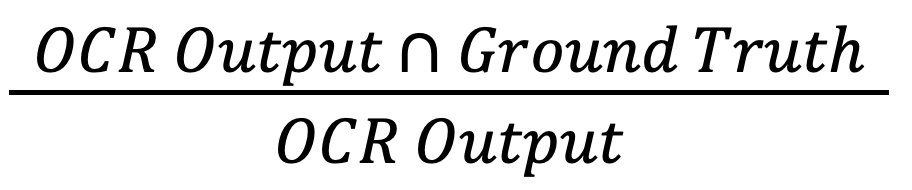
Recall (Полнота)
- показатель доли правильно распознанных символов относительно всех действительных символов в исходном документе;
- Recall =
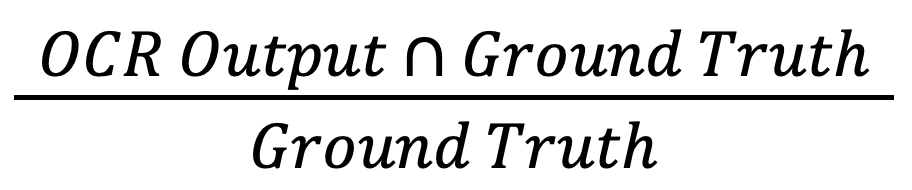
F1-мера
- гармоническое среднее между точностью и полнотой;
- F1 =

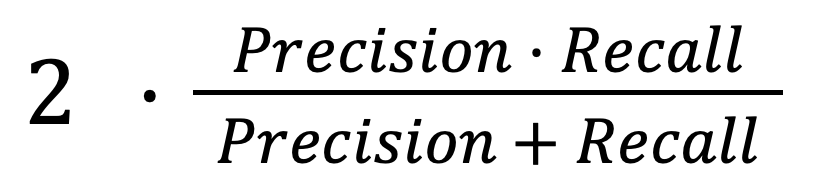
Для сравнения распознанного текста с эталонным текстом и поиска совпадающих последовательностей (то есть для вычисления показателя OCR Output Ground Truth) используется расстояние Левенштейна.
Расстояние Левенштейна (редакционное расстояние) — метрика сходства между двумя строковыми последовательностями. Алгоритм работы с расстоянием Левенштейна реализован на Python в библиотеке Levenshtein. В репозитории доступен ноутбук с примером программной реализации и использования функции вычисления метрик Precision, Recall и F1-меры, а также скрипт для выполнения в командной строке.

