
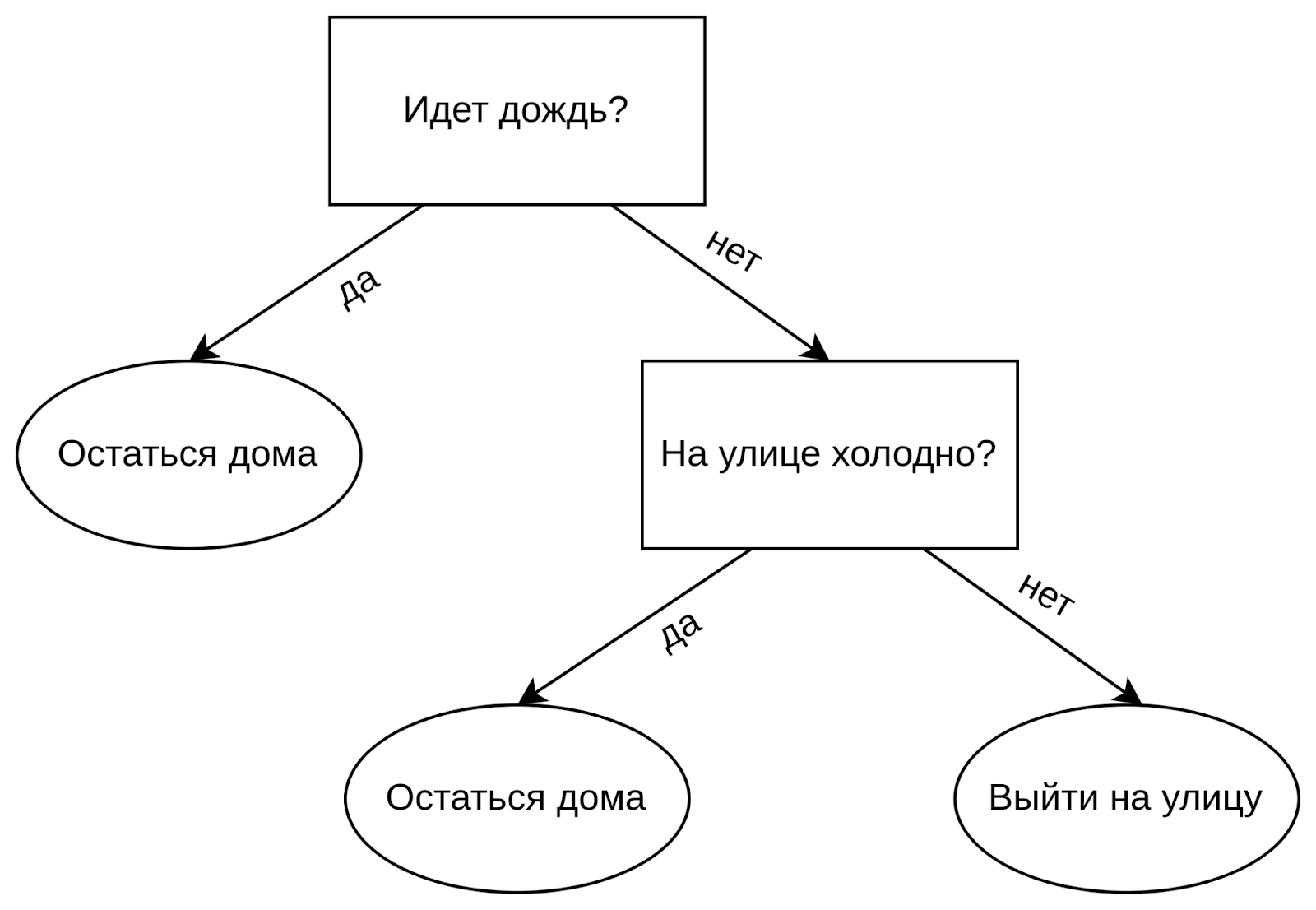
Предположим, что у вас выходной, и вы размышляете, прогуляться или остаться дома. Сначала вы смотрите в окно, чтобы узнать, не идет ли дождь: вы решили, что если идет дождь, то лучше остаться дома. Если дождь нет, вы проверяете погоду. Если на улице не слишком холодно, лучше прогуляться. Такое рассуждение можно представить в виде дерева решений:
В машинном обучении деревья решений – популярный алгоритм благодаря своей простоте и интерпретируемости.
Зачем нужны деревья
Как и в случае с остальными алгоритмами машинного обучения, задача дерева — предсказать целевую переменную по наблюдаемым переменным. На вход дерева подается выборка из объектов, каждый из которых описывается несколькими признаками, и затем делится на части таким образом, чтобы значение целевой переменной в таких частях было наиболее упорядоченно. В задачах классификации (когда целевая переменная — это класс) это значит, что задача дерева в том, чтобы, по возможности, объекты одного класса были сгруппированы вместе. В задачах регрессии (когда целевая переменная — непрерывная числовая характеристика) чтобы сгруппировались близкие друг к другу значения целевой переменной.
Дерево состоит из элементов двух типов — узлы, или ноды — элементы дерева, в которых формулируется какое-то правило, и листы — элементы, в которых записаны конечные значения. Например, в примере выше конечные значения — это варианты «выйти на улицу» и «остаться дома», а узлы — вопросы.
Когда нельзя использовать деревья
Благодаря своей универсальности, деревья используются практически везде, где есть табличные данные. Однако, при их использовании важно помнить о том, что они не способны к экстраполяции. Это значит, что они способны предсказать целевую переменную только в том диапазоне, который они уже «видели» в обучающей выборке. Если задача подразумевает, что целевая переменная может сильно выйти за пределы того, на чем обучалось дерево, оно не сможет корректно ее предсказать: например, если стоит задача предсказания цен на акции компании X, и за обучающий период акция торговалась в диапазоне от 3 до 10 рублей, то дерево не сможет предсказать событие, когда акция будет стоить, скажем, 50 рублей — зато с такой задачей может справиться регрессия.
Выращиваем деревья путём укрощения хаоса
В отличие от примера выше, в машинном обучении в узлах дерева решений не вопросы, а значения признаков, по которым необходимо разделить выборку. Каждый раз нужно делать это таким образом, чтобы получить самое полезное знание об объекте данных, или, говоря более формально, максимальный прирост информации. На практике это означает, что нужно разбить данные таким образом, чтобы в обеих частях после этого они оказались наиболее упорядочены. В этом может помочь понятие энтропии – меры хаоса, или неупорядоченности в системе. Ее можно рассчитать по следующей формуле:

Где n — количество возможных вариантов, а p(i) – вероятность одного из них. Рассмотрим формулу на примере. Допустим, есть пять цветных шариков:

Шарик либо оранжевый (с вероятностью 2/5), либо сиреневый (c вероятностью 3/5). То есть всего два возможных варианта, вероятность первого ⅖ , а второго – ⅗. Значит, энтропия будет равна 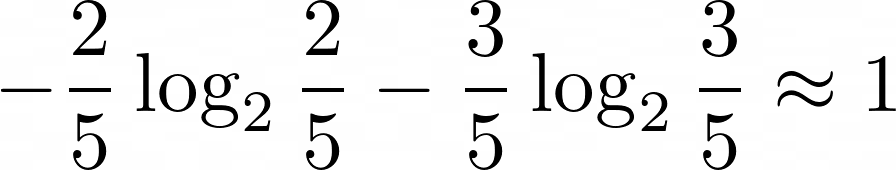 . Попробуем разделить выборку из шариков на две части так:
. Попробуем разделить выборку из шариков на две части так:

Теперь слева окажется три шарика – два оранжевых и один сиреневый. То есть, вероятность выбрать оранжевый шарик — ⅔, сиреневый — ⅓. Если подставить эти значения в формулу, можно вычислить, что энтропия равна 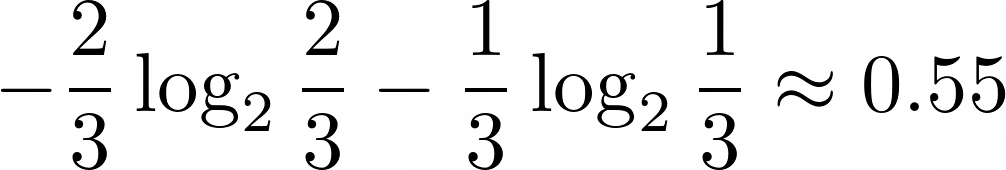 . В правой части она окажется равна нулю (-log2(1) = 0). Мы нашли такое разделение, которое уменьшило энтропию в обеих частях – можно сказать, что обе части стали более упорядочены. В дереве решений на каждом шаге ищется наилучшее разделение выборки из возможных. Когда при одном из разделений энтропия становится равна нулю — то есть, все объекты в этой его части одинаковы, построение дерева заканчивается, и модель выдает результат.
. В правой части она окажется равна нулю (-log2(1) = 0). Мы нашли такое разделение, которое уменьшило энтропию в обеих частях – можно сказать, что обе части стали более упорядочены. В дереве решений на каждом шаге ищется наилучшее разделение выборки из возможных. Когда при одном из разделений энтропия становится равна нулю — то есть, все объекты в этой его части одинаковы, построение дерева заканчивается, и модель выдает результат.
Пример
Допустим, мы хотим определять, выдать ли займ клиентам банка, и для этого будем использовать дерево решений. У нас есть следующие данные:

Первые два столбца содержат признаки для обучения модели, последний столбец – целевую переменную, которую нужно предсказать. Статус 1 означает, что клиент не вернул кредит в срок, 0 – что кредит выплачен вовремя.
Сначала нужно разобраться, какой признак обеспечивает оптимальное разделение. Вот так будут распределены классы целевой переменной, если отсортировать по возрастанию возраст (для наглядности отметим невозвращенные займы красным, а возвращенные – зеленым):

А так — если отсортировать доход:

Если перебрать все варианты, окажется, что в качестве первого разделения оптимальнее всего выбрать разделение по доходу: все клиенты с доходом от 68000 вернули займы. Следующее разделение – тоже по доходу: все клиенты с доходом 23000 и ниже не вернули займ. Остались только два клиента — одному 23 и его доход 47000, другому 34 и его доход 40000. Здесь можно разделить клиентов по возрасту. Так выглядит визуализация этого дерева решений с помощью модуля tree библиотеки sklearn:

Здесь визуализируется не только условие, по которому была разбита выборка (верхняя строчка в каждой ячейке), но и некоторая дополнительная информация:
- Samples – количество объектов в этом узле
- Value – количество объектов каждого класса (сначала 0, потом 1 в этом узле)
- Class – преобладающий класс в этом узле
- Цвет ячейки подсказывает, какой класс преобладает в подвыборке в этом узле дерева: здесь класс 1 отмечен синим, класс 0 — оранжевым. Более бледный цвет подразумевает большую неупорядоченность в этом узле.
Важно, что дерево делит выборку по среднему значению между объектами выборки: например, первое разделение проходит между числами 47000 и 68000, и 57500 – это среднее от этих двух чисел.
Деревья умеют зубрить
В примере выше при последнем разделении выборки мы видим два объекта данных: в одном клиенту 23 года, и он просрочил займ, во втором – клиенту 34, и он вернул займ. Из этого дерево делает вывод, что тот, чей возраст меньше или равен 28.5 лет, не вернет займ. Возможно, в большинстве случаев это правило верно – но дерево сделало его только по двум объектам. Если бы клиент 23 лет вернул займ, а клиент 34 лет не вернул, дерево сделало бы совершенно противоположные выводы. Такая проблема называется переобучением. Переобучение – это ситуация, когда модель способна хорошо объяснять закономерности только для выборки, на которой она обучалась, другими словами, модель “зазубрила” правильные ответы. Поэтому для данных, которых не было в обучающей выборке, модель будет давать крайне плохое качество. Эта проблема часто встречается в деревьях решений. Существуют разные способы сделать так, чтобы результат работы модели был более стабилен и не так сильно зависел от обучающей выборки. Например, такие:
- Сократить глубину дерева. При построении дерева решений можно сделать первые несколько разделений и на этом остановиться. Например, в примере выше можно было бы делить пользователей только по доходу меньше или больше 57500 рублей — тогда в каждом конечном листе дерева было бы не менее 3х наблюдений
- Не делать разделение, если количество объектов в листе дерева меньше определенного числа. Идея здесь, как и в первом варианте, сводится к тому, чтобы подтверждать каждое условие дерева достаточно большим количеством наблюдений.
Где это применяется?
Благодаря тому, что деревья легко интерпретировать и визуализировать, их иногда применяют для анализа признаков, влияющих на целевую переменную. Допустим, если в данных достаточно много признаков, можно построить дерево небольшой глубины, чтобы узнать, какие из этих признаков имеют больший вес. Однако, как правило, сами по себе деревья решений используются редко: на практике оказывается, что это достаточно грубый метод для описания реальности, и они часто ошибаются. Гораздо более популярны ансамбли из деревьев. Например, случайный лес: данные делятся на подвыборки, на каждой из которых обучается отдельное дерево, и ответ модели определяется посредством голосования. В случае классификации, например, случайный лес предскажет тот класс, за который “проголосовало” большинство деревьев.



