
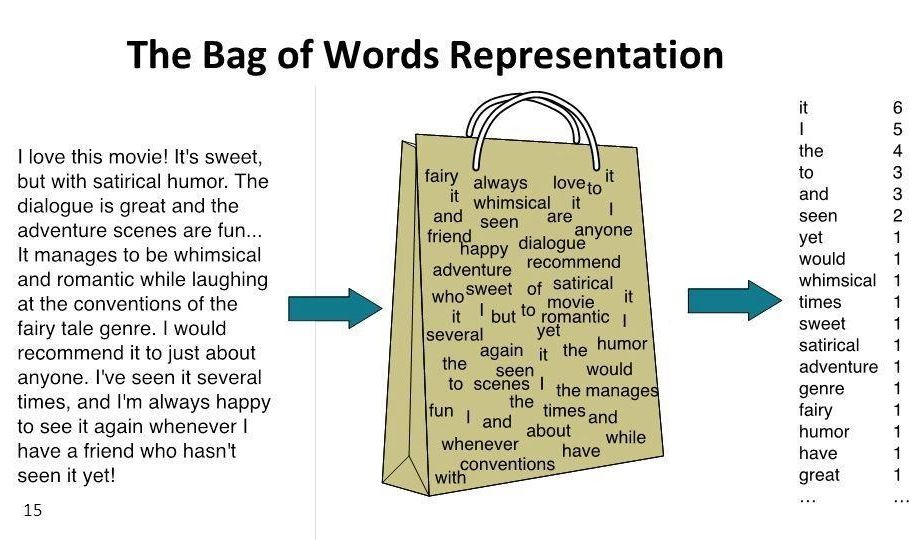
Что такое мешок слов?
Это упрощенное представление текста, которое показывает, какие слова встретились в тексте, но при этом не учитывает их порядок. Такое представление легко запрограммировать, оно удобно для использования в задачах автоматической обработки текста. Несмотря на свою простоту оно оказывается достаточно полезным и позволяет успешно решать такие задачи как классификация текста, т. е. отнесение текста к определенной группе/категории.
Как устроен мешок слов?
Представление мешка слов — это таблица с числами, в которой столбцы таблицы — уникальные слова, а строки — документы коллекции. В ячейках таблицы находится число вхождений слова в документ. Значит, в каждой строке получится набор чисел (он же вектор), характеризующий состав документа.
Пример мешка слов
Пусть у нас есть два текста: «Это были лучшие времена» и «Это было худшее время». В обоих предложениях встречается суммарно 5 различных слов, если привести к начальным формам: «Это», «Быть», «Лучший», «Худший», «Время». Это будет наш словарь.
Выделим встреченные слова из словаря в текстах: в первом встретились [«Это», «Быть», «Лучший», «Время»], а во втором — [«Это», «Быть», «Худший», «Время»].
Векторное представление мешка слов для первого текста будет [1 1 1 0 1], где нолик стоит на месте элемента «Худший», так как оно не встретилось в нем, а для второго — [1 1 0 1 1], где нолик на месте слова «Лучший». Так мы перешли к упрощенному машиночитаемому представлению двух текстов.
Нюансы использования
В реальных задачах все сложнее. Чтобы не мусорить в таблице, из текста убирают служебные слова. Слова приводят не обязательно к начальной форме (см. «лемматизация»), но иногда и обрезают, оставляя только грамматическую основу. (см. «стемминг»). Поэтому правильнее называть их уже не словами, а «токенами». Иногда столбцы обозначают не отдельные слова, а пары подряд идущих слов (биграммы) или тройки (триграммы).
Чаще всего в ячейках пишут не абсолютный показатель «слово встретилось 15 раз», а относительный показатель из статистики: он называется tf-idf и описывает важность слова для классификации текста.
Где это используется?
Мешок слов — полезный инструмент (или модель), который используется для разных задач, например, для классификации текстов на спам/не спам, определения похожести текстов и как упрощенный способ представления текстов для разных задач машинного обучения.



