
В эпоху Возрождения на смену схоластике и средневековому корпоратизму пришел гуманизм. В центре мира и познания вместо запыленной метафизики средневековых университетов оказался антропоцентризм. Для великого поэта и мыслителя Петрарки studia humanitatis стало настоящей образовательной программой, полностью меняющий прежние мировоззренческие установки. Секуляризация, просвещение и гуманизм с тех пор слились в нашем сознании, и сейчас при этом слове нам приходят в голову международные организации помощи обездоленным, а, может, и банальное человеколюбие.
Но так дела обстояли, разумеется, не всегда. Каким-то образом человечество должно было прийти от положений итальянских мыслителей к современному пониманию гуманизма. В Германии первой половины XIX века велись бурные дискуссии вокруг концепции «гуманизма», повлиявшие и на наше понимание этого термина. Содержание его со временем менялось, и проследить эту эволюцию взялись финские ученые из Университета Турку. При помощи современных методов тематического моделирования исследователи проследили развитие и изменение понятия «гуманизм» в публичном дискурсе Германии на данных немецкоязычной прессы в период с 1829 по 1850 годы.
Что такое тематическое моделирование?
Когда нас спрашивают, о чем книга или фильм, мы можем назвать некоторый набор тем: “о любви”, “о дружбе”, “о женской судьбе”. Бывает, что и в одном произведении сложно определить круг поднятых тем, и уж тем более задача усложняется, когда речь идет о целых коллекциях или группах текстов (ученые называют их корпусами). Если человек еще может сказать, о чем одна книга, то вот назвать, какие темы подняты в миллионе статей по биологии с конца XVIII века, кажется уже неподъемным. Тут-то нам и приходит на выручку topic modelling (тематическое моделирование). С его помощью возможно не только обозначить основные темы в корпусе текстов, но и отыскать такие темы, которые человек бы уловить не смог.
В основе тематического моделирования лежит довольно сложная математика. Само по себе тематическое моделирование является набором алгоритмов для выявления семантических структур в тексте или коллекции текста. Один из самых популярных алгоритмов — это латентное распределение Дирихле (LDA). В машинном обучении этот метод применяется еще с 2003 года. Суть алгоритма в построении модели, где каждое слово в каждом документе относится к определенной узкой группе слов (или топику).
Таким образом, топик или тема – это совокупность слов, которые с высокой вероятностью встречаются в документе рядом. Количество тем и слов в этих темах задаются уже нами. Пользователь далее интерпретирует “топик” (упорядоченный список слов), выделенный для него в удобную модель. В итоге мы получаем, с какой частотностью в определенном тексте появляются те или иные топики. Благодаря тематическому моделированию можно проверить, о чем говорят дневники с фронтов, какие темы интересуют авторов self-help литературы и т.д.
Для тематического моделирования существуют и кросс-платформенные инструменты. Например, относительно старая , но все еще популярная программа MALLET (Machine Learning for Language Toolkit). Изначально эта программа была создана для статистической обработки естественного языка, однако благодаря возможности классифицировать топики для большого массива текстов, MALLET стал популярен и среди историков. Важно помнить, что MALLET предназначен для крупных массивов данных, и результаты на небольшой коллекции документов могут быть нерелевантными по разным причинам. Кстати, у «Системного Блока» есть обучающий пост по MALLET.
Подготовка датасета
Для исследования была взята выборка из цифрового корпуса Австрийских газет (ANNO), предоставленного Австрийской Национальной Библиотекой (https://anno.onb.ac.at). С помощью алгоритмов оптического распознавания (OCR) и механизма поиска исследователи обнаружили, что слово Humanismus (“гуманизм”) в разных формах имело 326 вхождений между 1808 и 1850 годами. Здесь возникли первые сложности, поскольку фрактура, поздняя разновидность готического шрифта, с трудом поддавался OCR, а потому результаты вышли не самые точные. К тому же “гуманизм” мог зачастую встречаться один раз за весь документ или не использоваться эксплицитно. Поэтому ученые выделили 95 ключевых текстов, составивших датасет. В состав датасета вошли новости, статьи и обзоры книг, а репринты, рекламы или некрологи были удалены.
На этом чистка датасета не окончилась. Чтобы определить наиболее релевантные тексты, которые говорят о «гуманизме», была создана сетевая визуализация в Gephi (популярном инструменте для визуализации данных). На получившейся схеме можно проследить связь городов публикации с разнообразными публикациями, где встречается в различных формах понятие “гуманизма”. Для это ученым пришлось сделать разметку данных вручную. Чем больше упоминаний понятия “гуманизм” в газете или в журнале конкретного города, тем шире (или, как говорят, тяжелее) получились кружки. Так, на этой картинке коричневые круги обозначают газеты, а голубые – немецкоязычные города. Чем толще соединяющее кружки ребро, тем частотнее употребление слова “гуманизм” в газете или журнале. Таким образом, мы можем проследить, какие центры публикаций оказались в дискуссии о гуманизме наиболее влиятельными.
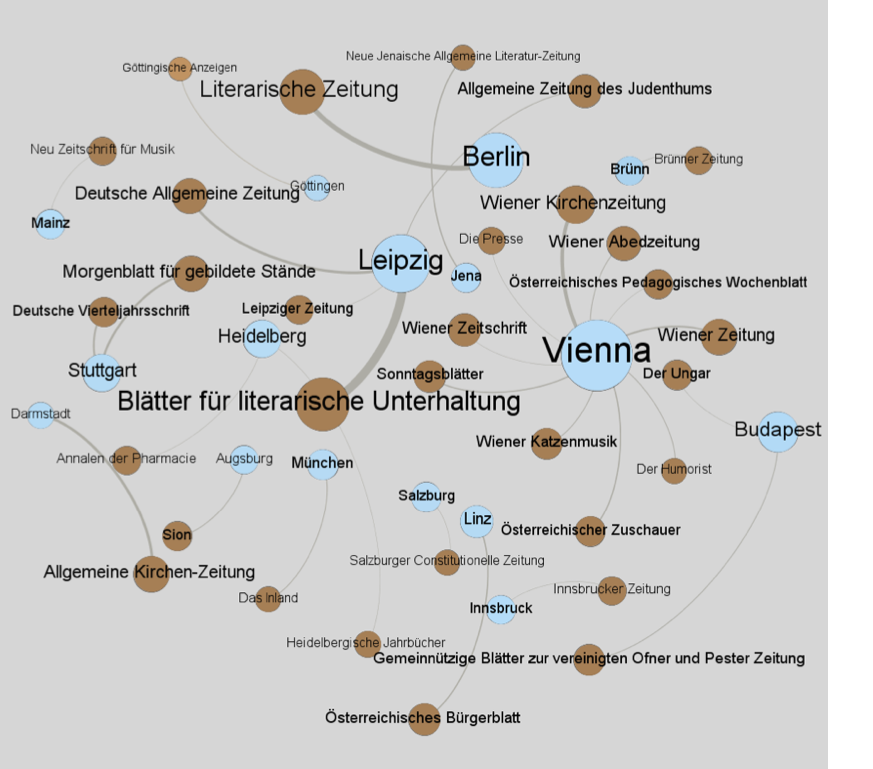
Как можно заметить по картинке, дебаты о гуманизме ушли далеко за границы Австрии и охватили собой все немецкоговорящие территории того времени в Европе.
Использованные методы
В исследовании дискурса Германии начала девятнадцатого столетия о “гуманизме” финские ученые использовали два метода тематического моделирования – MALLET и динамическое тематическое моделирование (DТМ).
Для выявления главных тем из ключевых 95 текстов использовалась программа MALLET с оптимизацией интервала. Это позволило присвоить каждому топику вероятностный параметр Дирихле, создающий между темами пропорции в зависимости от их превалирования в корпусе. Однако, поскольку MALLET предназначен для работы с большими массивами данных, полученные результаты не стоит воспринимать как итоговые. К тому же, количество топиков задается самим пользователем, следовательно, человек заранее прогнозирует, сколько тем будет встречаться в текстах, предварительно с ними не ознакомившись. Это похоже на поиск иголок в стоге сена с той разницей, что мы, еще не приступая к поискам, уже решили, что иголки в сене есть и и ровно 5/10/20/100.
MALLET способен лишь показать совокупность и пропорции топиков, но не их развитие и трансформацию. Для этой программы не существует хронологических или пространственных рамок, поэтому на данных, полученных с помощью MALLET, исследователи использовали уже другой метод – динамического тематического моделирования (DTM). В отличие от LDA и MALLET, DTM показывает статистические изменения в топиках на протяжении некоторого отрезка времени. Лучше всего DTM работает на больших массивах, поэтому для оптимизации работы DTM с небольшим набором данных ученые сделали предобработку текстов. Они избавились от редких слов и выражений, встречавшихся не более раза или двух во всем тексте, убрали пунктуацию, провели лемматизацию и удалили стоп-слова (слова, которые никак не важны для топиков, например, артикли или междометия).
Полученные результаты
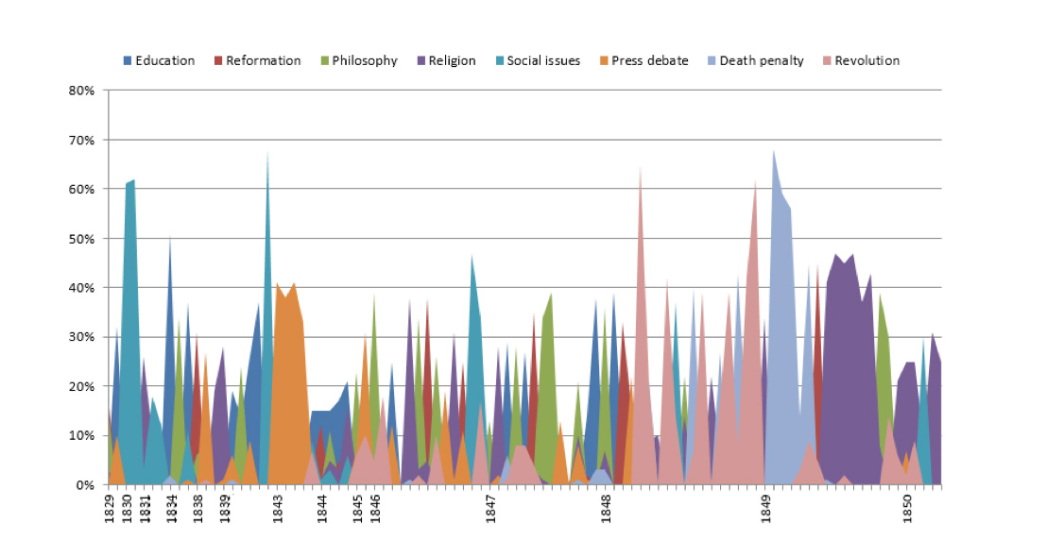
В итоге исследователи выбрали 8 тем, распределенных MALLET по степени превалирования в корпусе (слева направо): Религия, Образование, Революция, Философия, Реформы, Смертная казнь, Дебаты в прессе, Социальные проблемы. В таком виде, тем не менее, топики не могут нам сказать ни о чем явно: допустим, в теме “Философия” особую величину занимает упоминание Арнольда Руге – гегельянца и политического философа XIX века, но не до конца ясно, какое отношение он мог бы иметь к революциям в 1848-1849 годах или к другим топикам, например, к Реформации. Безусловно, концепция “космополитического гуманизма” небезынтересна, но важно проследить, как дискурс развивался.
Поэтому далее исследователи классифицировали топики MALLET по годам с 1829 по 1850. Здесь уже видны первые тематические тренды эпохи: так, в начале века пальму первенства забрали “Образование” и “Социальные проблемы”, когда ближе к 1848 году все более и более превалировали “Революция”, “Религия” и “Смертная казнь”.
База данных из MALLET была загружена в DTM в хронологическом порядке с 1829 по 1850 годы, но уже не по топикам, а по ключевым словам. Так изменения наиболее заметны. Допустим, частота встречаемости Zeit (“время”) или Zukunft (“будущее”) к середине века серьезно возросла, что подтверждает гипотезу, выдвигаемую историками идей (например, Р. Козеллеком), о существенном изменении восприятия времени в новую эпоху. Но не только частота конкретного слова может многое сказать об изменении дискурса – наличие слов рядом тоже имеет значение. Вместе с Zeit к середине столетия стали все чаще встречаться Wissenschaft (“знание/наука”) и Erziehung (“образование”). Э. Гидденс в “Последствиях современности” не зря описывал, что осознание модерна случилось в XIX веке при отделении понятия “времени” и полной его абстрагированности.
В итоге, после всех фильтров, чисток и перераспределения данных в разных программах, исследователи получили 10 топиков, ранжированных по степени важности, которые бы ассоциировались с прогрессией дискурса о “гуманизме”. После интерпретации топикам были присвоены такие обозначения:

Плюсы и минусы использованных инструментов
По признанию самих авторов исследования, финальные выводы нельзя использовать как достоверную статистику, а лучше обратиться к каждому конкретному топику и уже самостоятельно изучить его в процессе пристального медленного чтения.
Небольшой охват текстов в корпусе всегда дает менее релевантные результаты, однако не всегда существует возможность этот корпус расширить. При изучении понятия “гуманизм” ученые попытались через последовательную и ручную корректировку некоторых документов сгладить погрешности, вызванные нехваткой текстов в корпусе. После фильтраций несколько раз менялись как темы, так важность некоторых тем. “Образование” из MALLET на стадии DTM сменилось на “Изучение языка”. Результаты в лучшем случае можно назвать “плавающими”. Некоторые гипотезы удалось подтвердить. Например, была подчеркнута значимость А. Руге в политических дебатах около середины XIX века и подтвердились предположения Э. Гидденса и Р. Козеллека о дискурсе времени.
Это исследование финских ученых продемонстрировало недостатки цифровых инструментов в гуманитарных исследованиях, но в то же время позволило подсветить темы, о которых прежде историки в контексте гуманизма вряд ли задумывались.
Источники:
- Hakkarainen, H., & Iftikhar, Z. (2020). The many themes of humanism: Topic modelling humanism discourse in early 19th-century German-language press. In M. Fridlund, M. Oiva, & P. Paju (Eds.), Digital histories: Emergent approaches within the new digital history (pp. 259–277).
- Гуманизм // Энциклопедия Кругосвет. URL: https://www.krugosvet.ru/enc/kultura_i_obrazovanie/literatura/GUMANIZM.html


