
1. Как работает тематическое моделирование?
Тематическое моделирование (topic modeling) — это способ научить машину выделять в текстах содержательные темы. Например, проанализировав массив новостных и публицистических текстов о протестных митингах, машина может выделить там темы (топики) «полицейское насилие», «география Москвы», «требования и лозунги» и др.
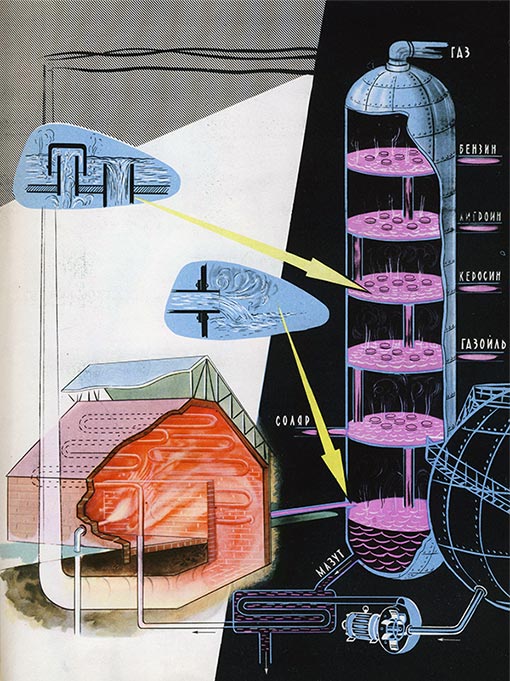
Естественно, компьютеры не могут понять смысл статей напрямую. Но если есть большая коллекция текстов с разными темами, то вероятности совместного употребления слов позволяют нам выделить отдельные тематические пласты — примерно, как химики разделяют нефть на фракции: бензин, керосин, солярка, мазут, асфальт…
Как выглядит в чистом виде такой тематический пласт, «отфильтрованный» из множества текстов? Это просто набор слов, характерных для темы. Слова в наборе отсортированы по важности для данной темы. Посмотрите, к примеру, на такой набор слов:

Это явно про отношения между полами! А вот такой набор слов:

— это про музыкальную индустрию и звукозапись.
И тот, и другой пример реальные — они получены нами на корпусе 6700 текстов одного из современных русских СМИ. Размеры слов на визуализации пропорциональны тому, насколько они значимы для темы, насколько хорошо они характеризуют ее. Этот показатель как раз и рассчитывает алгоритм тематического моделирования.
Разумеется, слова нельзя просто так «склеить» друг с другом по признаку частого совместного упоминания — тогда получится много довольно бессмысленных тем типа таких:

Чтобы темы были осмысленными, нужно определять слова, которые не просто частотны, а именно характерны для одних контекстов, но при этом практически не употребляются в других. Для этого используется хитрая математика, о которой мы уже рассказывали вот здесь. Не будем в нее углубляться — вместо этого поработаем с готовым инструментом для тематического моделирования. В этом инструменте все математические хитрости уже реализованы — от нас требуется только освоить нужные команды.
2. Да, хватит уже бла-бла. Как это сделать самому?
Приведенные выше примеры содержательных тем (условно назовем их «межполовые отношения» и «музыка») мы получили с помощью Mallet — старой, но по-прежнему очень популярной программы для тематического моделирования. Mallet выделяет темы при помощи латентного размещения Дирихле (LDA) — это классический способ, придуманный в 2003 году и остающийся популярным по сей день.
2.1 Подготовка
Первым делом Mallet нужно скачать — программа распространяется свободно и доступна для всех операционных систем. Но пользователям Windows придется пострадать чуть больше других.
Решаем траблы с Windows (маководы и линуксоиды могут сразу переходить к следующему разделу — установке JDK)
Во-первых, на Windows скачанный вами архив с Mallet желательно распаковывать непосредственно в корень одного из системных дисков — т.е. чтобы путь к папке был вроде «D:\mallet-2.0.8» или «C:\mallet-2.0.8». C более длинными путями бывают проблемы (на юникс-подобных системах — Mac OS и Linux — с такими сложностями мы не сталкивались).
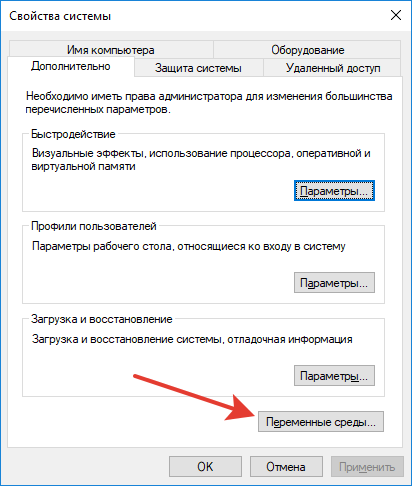
Во-вторых, на Windows нужно будет установить т.н. переменную среды (environment variable), которая даст системе путь к тому месту, куда вы установили Mallet. Имя переменной (variable name) — MALLET_HOME, значение переменной (variable value) — собственно путь (например «D:\mallet-2.0.8» или «C:\mallet-2.0.8»).
Можно сделать это через панель управления, найдя в разделе «Система» в «Продвинутых настройках системы» кнопочку «Переменные среды»:
А можно сделать то же самое по-хакерски — и честно говоря, так проще всего — через командную строку. Ведь дальше нам все равно потребуется работать именно с командной строкой. Поэтому идем в меню «Пуск» — и вводим там в окошке поиска три буквы: cmd, а затем жмем enter:
Оказавшись в командной строке, пишем: setx MALLET_HOME «D:\mallet-2.0.8». Эта команда установит для переменной среды MALLET_HOME значение D:\mallet-2.0.8.
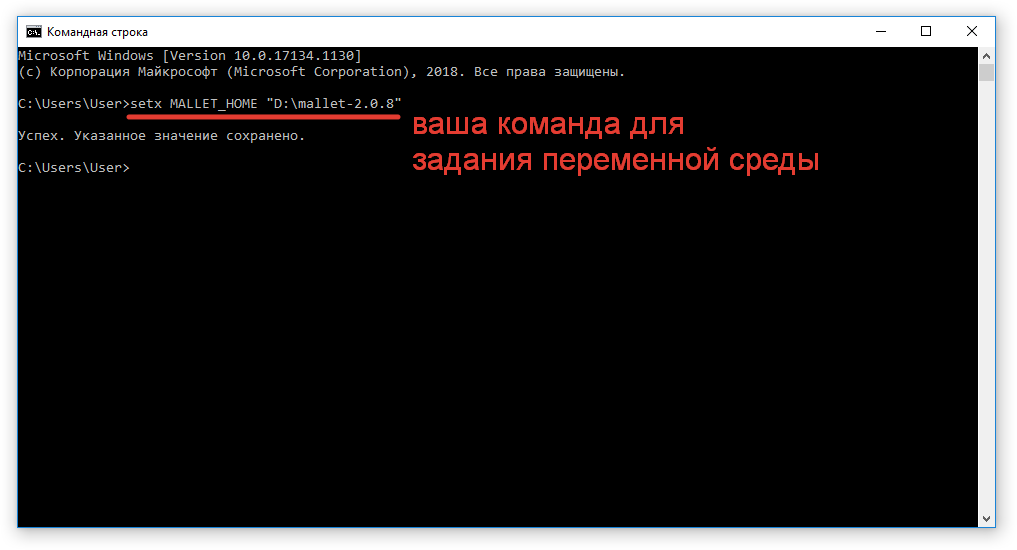
Если у вас путь отличается, измените его в команде.
На этом борьба с проблемами Windows должна закончиться — попробуем запустить программу.
Ставим JDK
Еще одна небольшая техническая деталь: для работы маллет нужен Java Development Kit — пакет разработчика программ для Java. Если вы не программируете на Java, скорее всего, у вас он не установлен. Просто установите его отсюда.
2.2 Подбираем корпус текстов
Тематическое моделирование может сработать хорошо и на небольшом наборе текстов, если в них действительно присутствует тематическая разнородность. Но все-таки его применение более осмысленно на больших коллекциях, которые просто так не прочитаешь. Вот, например, мы взяли корпус текстов одного сетевого издания, и попробовали выделять темы в нем. Наш корпус содержит 6700 текстов, ваш может содержать меньше или больше. Для начала предлагаем вам поработать вот с этим корпусом новостей — популярный набор данных для тематического моделирования. Или используйте примеры, поставляющиеся вместе с mallet — они лежат в папке sample-data, которая уже есть у вас после распаковки mallet.
Поместим корпус (т.е. просто множество txt-файлов) в отдельную папку внутрь папки, с которой мы работаем:
(на Windows процедура ничем не отличается)
Тематическое моделирование в Mallet осуществляется в два шага. На первом шаге надо перевести все ваши текстовые файлы во внутренний бинарный формат .mallet. Второй шаг — непосредственное моделирование, когда алгоритм ищет в корпусе заданное нами число тем и выводит их, а также выдает распределение тем по документам.
2.3 Работаем с Mallet
Mallet — это очень просто устроенная программа, у нее даже нет графического интерфейса. Поэтому все команды мы будем отдавать через ту же самую командную строку. На Mac OS и Linux это называется терминалом (Terminal).
Для начала пропишем путь к папке, в которой лежит программа (это просто наш распакованный архив). В командной строке (или в терминале) это делается с помощью команды cd. Эта команда понимает как абсолютные, так и относительные пути. Например, если у вас Windows и распакованный архив с mallet лежит у вас в D:\mallet-2.0.8, вы можете сделать так:
cd D:\MalletTutorial\mallet-2.0.8
- Для перехода командной строки между дисками может предварительно понадобиться выполнить команду /d D:\ (если по умолчанию ваша командная строка работает с диском С, например)
Если у вас Линукс или Mac OS, и вы, например, положили mallet в папку vasya в папке Users, то попасть в нее можно точно так же, с помощью cd:
cd users/vasya/mallet-2.0.8
В папку нам нужно попасть, чтобы потом было недалеко ходить за самим исполняемым файлом, т.е. программой, которая непосредственно «делает» тематическое моделирование.
Перевод файлов в формат .mallet
Для того, чтобы программа могла работать с текстами из нашего корпуса, необходимо привести их в формат .mallet. Для этого нам нужно воспользоваться командой
import-dir. Этой команде нужно сообщить, откуда брать файлы (параметр). Вот так выглядит «голая» команда в командной строке:

А вот наши пояснения к ее частям:

Внимание: в Windows разделителем пути в командной строке служит не слэш (/), а двойной бэкслэш (\). Т.е. если вы работаете из командной строки Windows, путь из папки с mallet к исполняемому файлу будет иметь вид bin\mallet.
Для того, чтобы mallet смог выдавать вам слова, характеризующие все топики, нужно указать еще один параметр: —keep-sequence. Это позволяет программе помнить, в какой последовательности шли слова в текстах. А чтобы наши темы получились более осмысленными и не замусоривались служебными словами вроде и, на, в, про и т.п., можно еще передать Mallet список стоп-слов. Это делается в той же команде import-dir с помощью опции —stoplist-file, после которой через пробел вводится путь к файлу со стоп-словами:

В папке stoplists (находится прямо в основной рабочей папке —там же, где мы создавали папку с корпусом и куда прописывали путь) у Mallet уже лежат готовые списки стопслов для нескольких языков, русского среди них нет, но скачать русский список можно много где (раз, два). Мы скачали такой список, назвали его stop_ru.txt и положили его в папку stoplists, поэтому можем теперь его использовать.
Все, теперь в нашей папке появился нужный нам файл с расширением .mallet:
Можно приступать непосредственно к тематическому моделированию.
Получение топиков
Для обучения тематической модели и получения нам понадобится вторая — и последняя в этом тьюториале — команда для Mallet, которая так и называется: —train-topics, т.е. обучить топики. Ей надо передать тот самый файл .mallet, полученный нами на предыдущем этапе, но теперь уже в качестве входных данных:
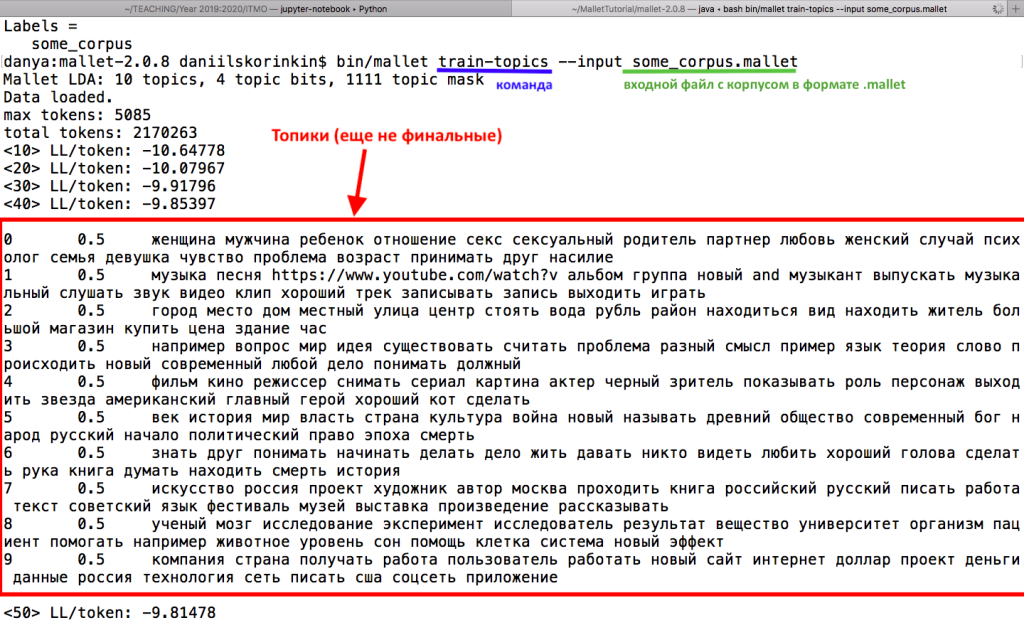
У команды train-topics есть много параметров, которые вы можете изучить самостоятельно с помощью опции —help:

Расскажем про несколько самых важных.
—num-topics позволяет указать, сколько тем должен выделить Mallet. Необходимость задавать число тем вручную — слабое место большинства алгоритмов тематического моделирования. Зато регулировка этого параметра позволяет получать более общие, абстрактные, или наоборот более дробные, конкретные темы. Вот, например, в «Войне и мире» при попытке выделить 2 темы выделяется что-то похожее на «военную» и «мирную» темы.
—output-topic-keys — сюда указываем путь к файлу, в который надо сложить темы. В файле будет просто 20 строчек с темами в виде мешка слов, то же самое, что выдаст вам командная строка:

—topic-word-weights-file — а вот тут можно указать путь к файлу, в который Mallet сложит полные данные: какие слова обладают какой значимостью для какого топика. На основе данных из этого файла уже можно делать облака слов для любого из ваших топиков — например, с помощью wordclouds.com, как это делаем мы:

Все! Остальные параметры команды для обучения тематических моделей мы призываем вас исследовать самостоятельно. Удачного тематического моделирования!



