
Игорь Пильщиков — сооснователь Русской виртуальной библиотеки (rvb.ru), ФЭБ «Русская литература и фольклор» (feb-web.ru) и системы СПСЛ (cpcl.info), профессор славистики в Калифорнийском университете в Лос-Анджелесе, доктор филологических наук. «Системный Блокъ» поговорил с ним о моделировании в литературоведении, масштабировании исследований с помощью компьютера, сложностях с поэтическим метром у больших языковых моделей, проблемах переноса биологических терминов в литературоведение, о важности воспроизведения паттернов (а не выражения авторской индивидуальности) для значительной части мировой культуры на протяжении большей части ее истории, а еще о том, как Шекспир справлялся с дедлайнами и недостатком трезвых актеров.
О способах построения моделей в квантитативных исследованиях
Прежде чем мы начинаем что-то считать в текстах, нужно понять, что именно мы подсчитываем и какие единицы измерения используем. Этот принцип был выработан позитивистским литературоведением, которое еще в XIX веке стало развиваться в квантитативную сторону. В 1930-е годы Б. И. Ярхо описывал этот процесс подготовки материала в первых частях «Методологии точного литературоведения» и в «Комедиях и трагедиях Корнеля». Он показывает, как дифференциальные признаки выделяются путем сопоставления двух и более комплексов (например, комедий и трагедий или стиха и прозы). В этом смысле методологически он оказывается близок к Н. С. Трубецкому, который в те же годы занимался тем же, только в фонологии.

Н. С. Трубецкой (слева) и Б. И. Ярхо (справа)
Чтобы получить хороший результат в квантитативных исследованиях литературы, мы должны быть уверены, что учли в процессе разметки текстов все важные для нашего исследования признаки и придумали, как их подсчитывать. Признаки можно выделять индуктивно или дедуктивно, но в любом случае ориентироваться придется на некоторую упрощенную модель: поскольку мы в принципе не можем описать все свойства объекта (в данном случае текста), то выделяем некоторые свойства как наиболее существенные, абстрагируясь от остальных.
Прежде чем мы начинаем что-то считать, нужно понять, что именно мы подсчитываем и какие единицы измерения используем
Саму модель мы можем придумать и интуитивно. Да, возможно, это не похоже на то, как обычно бывает в точных науках, хотя и в них бывало всякое. Важно, что у нас появится модель, и с ней можно будет что-то делать. Ее можно передать другому, и независимо друг от друга мы можем устроить ей какую-то проверку. Если мы успешно провели разные тесты, то, значит, убедили друг друга в том, что предложенная модель работает ― описывает то, что мы хотели бы, чтобы она описывала.
Выходит, для исследования валидны оба метода: (1) дедуктивный: сначала выделить потенциально релевантные элементы, а потом начать их подсчитывать на доступном корпусе и (2) индуктивный: сразу начинать считать в доступном корпусе все, что можно подсчитать, обращая внимание на «аномалии» и пытаясь их объяснить. Во втором случае непротиворечивая теория (более точная модель) возникает именно за за счет объяснения природы «аномалий»: мы подбираем и складываем абдуктивные объяснения. Это возможный путь, им шли постпозитивисты типа Ярхо.
На пути к использованию новых инструментов
Сейчас всё будут считать с помощью компьютеров. Но отличие от предыдущих квантитативных подходов тут чисто инструментальное. В чем его плюсы и минусы компьютерного подхода? У нас уже есть некоторые, ранее поставленные, задачи и уже выработанные процедуры, подходящие для их решения. Значит, мы можем автоматизировать часть процессов. И это будет происходить, хотим мы этого или нет, потому что лень — двигатель прогресса. Зачем я буду мучиться и делать что-то «руками», если это можно сделать автоматически.
Здесь всплывает еще одно обстоятельство: любой ручной труд без механизации недостаточно масштабируем. Значит, если нужно увеличивать масштаб, то тоже понадобится автоматизация, и она будет происходить.
Это позитивные вещи, однако таким путем ничего нового не возникнет: все эти инструменты и методы ничего принципиально нового нам не дадут, а смогут только ускорить решение уже поставленных задач. И мы уже даже начали немножко скучать, но тут ― прорыв с ChatGPT и другими генераторами текстов. Пока, правда, не очень понятно, как можно использовать такого рода генератор, например, в лингвистике и филологии.
Несовершенства больших языковых моделей
ChatGPT почему-то совершенно не умеет писать метрическую поэзию. Он никак не способен ни на каком количестве текстов усмотреть, что такое метр и рифмовка. Буквально сегодня я попросил модель 4o сочинить четыре четверостишия элементарным 4-стопным ямбом и получил текст с двумя элементарными же метрическими ошибками. При этом Chat неспособен ни найти у себя ошибку, ни эксплицировать правила, по которым он строит ямбическую строку.

Пример сложностей LLM с поэзией: ChatGPT сначала справляется с хореем, но затем полностью ломается на амфибрахии
Мой коллега по РВБ Евгений Горный попытался научить нейросеть Claude 3.5 Sonnet писать тексты онегинскими строфами на заданную тему. Долго он с Claude маялся, наконец удалось написать онегинскую строфу, но со сбоем в последовательности женских и мужских рифм. Поправили. Увы, через пару итераций Claude забыл схему этой строфы. Ни одну схему, которую он выучил в процессе тренировки, он не был способен запомнить. Или не считал нужным запоминать.
Нейросеть понимает, что человек от нее чего-то хочет, и пытается выполнить задачу. При этом она использует какую-то разметку, которая помогает ей что-то написать. Получающийся текст все-таки состоит, как было прошено, из четверостиший или четырнадцатистиший, во многих строках метр соблюден правильно. Иногда даже целое стихотворение выходит без ошибок, но никто не может гарантировать, что следующий сгенерированный текст тоже будет метрически безупречен. Дело в том, что даже самые простые русские классические двусложные размеры (ямб и хорей) довольно сложно устроены. Они подчиняются правилам, позволяющим пропускать слоги на метрически ударных слогах и добавлять сверхсхемные ударения на метрически безударных. Это возможно или невозможно в зависимости от того, происходят ли оба «нарушения» схемы в двух разных словах или внутри одного: в двух разных можно, а внутри одного нельзя. Таким образом, правила постановки ударений в ямбе и в хорее зависят от словоразделов. В трехсложных размерах (дактиль, амфибрахий, анапест) правила еще сложнее. Даже не все стиховеды четко формулируют эти правила — отчасти потому что мы не знаем точно, что такое словораздел в стихе, отчасти потому, что не всегда можем учитывать градацию силы ударений.
Существуют разные типы описаний художественных текстов: есть чисто дескриптивные методы (выясняющие, что в тексте есть и как он устроен), а есть генеративные (выясняющие, как и из чего его можно построить). Мы, в общем, способны описать, как из идеи «цветок — это прекрасно» рождаются разные стихи, исходя из того, что разные поэтики — это разные формы разработки одной и той же темы. И мы должны с помощью такой поэтики (типа «Поэтики выразительности» Жолковского-Щеглова) уметь написать если не стихотворение Ахматовой, то стилизацию или пародию на него.
Такие модели создаются, но все они неизбежно оказываются недостаточно подробными. Некоторые люди могут, взяв такую модель как инструкцию, сочинить нужный текст, но большая часть людей не может, поскольку никакое описание не будет исчерпывающим. Вот если бы это было возможно, мы легко научили бы машину писать стихи, соблюдая и законы метрики, и нормы поэтики. Сможет ли машина научиться этому сама? Посмотрим. Пока что с поэтикой у разных генераторов выходит то же, что с метрикой ― иногда получается, иногда нет, а почему ― не знаем ни мы, ни генератор.
Загадочные искусственные паттерны работы
Какие-то машины еще в 60–70-е годы худо-бедно какие-то стихи писали, а сейчас нейросети этому учатся. И несмотря на все предыдущие оговорки, получается это у них гораздо лучше, чем у машин предыдущих поколений. Жизнь опять победила смерть неизвестным науке способом. Ровно такие же размышления вызывает у прикладных лингвистов крах ABBYY: то, что собирались построить с помощью прикладной лингвистики, построило себя само.
Может быть, как раз в связи с новейшими практическими успехами мы можем, наконец, трезво оценить разрыв между теоретическим и практическим аспектами нашей деятельности. Модель, которая объясняет, и модель, которая порождает, — это совершенно не обязательно одна и та же модель.
Модель, которая объясняет, и модель, которая порождает, — это совершенно не обязательно одна и та же модель
Что в этом случае должны делать digital humanitsts? Наверное, пользоваться и теми, и другими моделями: и объясняющими, и работающими по неизвестной причине (или неизвестным способом).
Например, нам нужно составить какую-нибудь жанровую классификацию (скажем, разбить корпус романов на детективные романы, любовные романы и «прочие» — неважно зачем, цели тут могут быть разные). Можно передать материал самообучающимся машинам, и они каким-то волшебным образом его классифицируют. Такие «машинные» классификации как-то коррелируют с понятными и привычными нам «человеческими» классификациями. Мы получили результат, и у нас есть повод задуматься: а почему это вообще работает, как это работает, а не можем ли мы построить модель этой модели, чтобы ее понять? Почему в конце концов эта модель сработала так, что вот я своим нормальным человеческим способом получил понятный и убедительный результат, но и она получила неизвестным способом похожий результат? Получается, что можно к этому результату прийти разными путями.
О потенциале ускользающей точности
Науки различаются по степени математизации. Наука тем более точна и, следовательно, тем «более наука», чем более она математизирована. Это еще Кант говорил, потом его цитировал Маркс, а потом Лотман этой цитатой как бы из Маркса защищался от нападок на точные методы.
Есть математика, она идеальна, и поскольку реального объекта у нее нет, то никакой объект ей жизнь испортить не может. Дальше от идеала отстоит классическая физика, где можно сравнивать эмпирический результат с вычисленным: можно бросать реальный камень и смотреть, упадет он, сволочь, или нет, и куда именно. И физики обычно знают, какая точность требуется для их измерений, то есть их точность заключается в осознании степени собственной неточности. Чем дальше в лес, тем неточней науки: в биологии или метеорологии все работает на неполной статистике. В отличие от камня, который при определенных условиях всегда падает в назначенное ему место, дождь даже при определенных условиях падает не всегда: можно только сказать, что он скорее выпадет, чем не выпадет, и прикинуть, насколько «скорее».
Поэтому Б. И. Ярхо считал, что биология и метеорология могут служить для филологии методологическими образцами: та же вынужденная неполнота данных при сохраняющейся возможности описать их статистически. Кроме того, он обнаружил, что какие-то паттерны, наблюдаемые в биологии, мы можем наблюдать и в литературных текстах. Возникает вопрос: паттерны воспроизводятся в обеих областях, потому что эти предметы сходны по своей природе или потому что просто мы так думать и считать умеем, а по-другому не умеем? И тогда применение биологических или физических терминов к литературе — это не обнаружение общих закономерностей, а лишь установление аналогий, которые могут быть сколь угодно отдаленными?
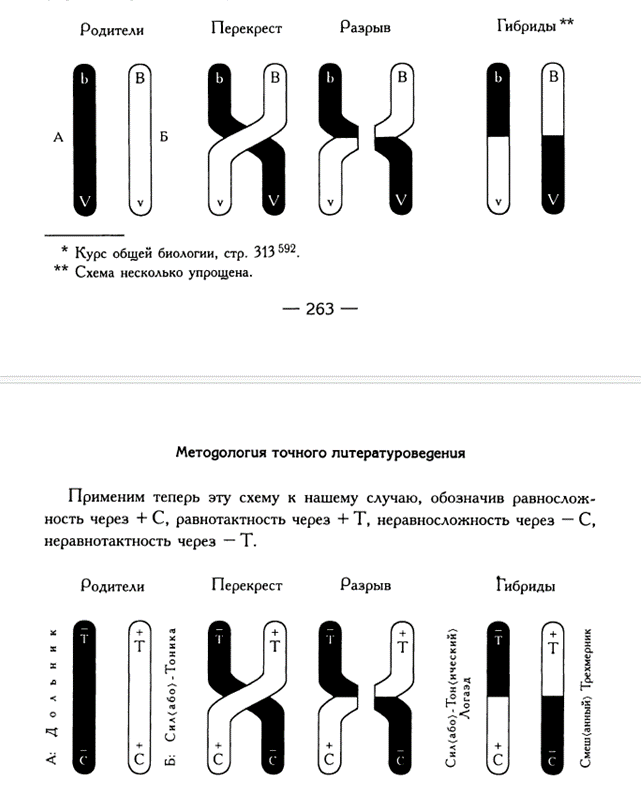
Б. И. Ярхо сравнивает явление гибридности в биологии и стиховедении. [3, стр. 263–264]
Но ведь и в точных науках термины — это не какие-то первослова, указывающие на первовещи. Любое наше описание в конечном счете тропеично [от слова «троп» — переносное, а не прямое значение слова. — Прим. СБъ]. Иногда оснований для переноса значения больше, иногда меньше. В любом случае, каждое новое словоупотребление влечет за собой какую-то модификацию значения. Человеческий язык обладает запасом неточности, и в этом залог его выживания и залог нашего взаимопонимания, ведь мы немножко по-разному все слова понимаем. Были бы у нас жесткие значения слов, мы бы друг друга вообще, может, не понимали.
Человеческий язык обладает запасом неточности, и в этом залог его выживания и залог нашего взаимопонимания, ведь мы немножко по-разному все слова понимаем. Были бы у нас жесткие значения слов, мы бы друг друга вообще, может, не понимали
Однако с параллелями между филологией и биологией не все так гладко. В биологии мы разделяем живые существа на роды, виды и особи. А особь разделяем уже на разные ее члены. А что у нас есть в литературе? Вроде бы у нас есть роды, которые разделяются на жанры, которые представлены произведениями, а в произведении есть какие-то части. В таком виде эта идея сформулирована впервые в середине XIX века, это гегелевская формулировка.
Классицизм XVII века еще так не мыслит. В их теориях никаких родов нету, но они все время пытаются организовать отношения между жанрами как можно более систематично ― и вот только к концу XVIII века всё построили, как приходят романтики и всё ломают. Но ведь так вообще устроено искусство. Как только мы построили идеальную систему — больше неинтересно, давайте по-другому теперь будем делать. Поэтому и система жанров, и конкретные жанры, и поджанры все время меняются, они нестабильны. Но это еще полбеды — в конце концов, животный мир тоже эволюционирует, динозавры по улицам не бегают, хотя раньше вполне себе бегали.
Как только мы построили идеальную систему — больше неинтересно, давайте по-другому
Есть другая проблема: отсутствие единого основания деления, позволяющего строить классификацию. Тот же Ярхо жаловался, что в литературоведении нет четкого представления о системе жанров. Мы вообще не понимаем, что такое жанр, что такое поджанр. У нас нет никакой номенклатуры. Даже по набору признаков один жанр не равен другому. Жанры, возникшие из бывших твердых строфических форм, formes-fixes, — например, сонеты, — определяются формальными признаками, а другие жанры определяются совсем другими признаками, может быть, не формальными, а содержательными. Элегия сначала определялась формально, потому что ее требовалось писать элегическими дистихами, а потом ее стали писать любыми размерами, и осталось только нечеткое содержательное определение (стихотворение о любви, преимущественно грустное). А детектив, например, формальными или содержательными признаками определяется? Это зависит от того, считаем ли мы тип персонажа формальной или содержательной характеристикой.
Искусственный vs естественный интеллект
Мы не знаем, что такое человеческий разум. Является ли искусственный интеллект действительно интеллектом? Вопрос отчасти бессмысленный, потому что если мы не знаем, что такое интеллект, то мы не можем знать, является ли то, о чем мы говорим, его аналогом. Но о статусе искусственного интеллекта по сравнению со статусом естественного поговорить уже можно.
Сам вопрос, считать ли моим написанное искусственным интеллектом, включенное мной в мой текст, — это хороший вопрос. Но это вопрос, имеющий смысл только в романтической и постромантической культуре. То есть в европейской культуре последних 200 с копейками лет.
Большая же часть культуры устроена совершенно по-другому. Текст существует как некоторый паттерн, который я стараюсь воспроизвести. Либо я просто повторяю, а вариации возникают из-за того, что мы не можем повторить точно. Либо я генерирую текст по образцу, стараясь сделать это наилучшим образом.
Какой-нибудь singer of tales, сказитель, у которого есть набор формул, порождает длинные, сложные тексты [этому посвящена одноименная книга А. Б. Лорда. — Прим. СБъ]. Он может сгенерировать такие тексты, на которых зиждется вообще вся европейская культура, например, «Илиаду» и «Одиссею». Но во всех этих видах культуры, архаических, фольклорных, в культурах средневекового типа не стоит вопрос об оригинальности, авторстве и индивидуальности стиля. Стоит вопрос о том, насколько хорошо текст соответствует паттерну. И 90%, если не больше, мировой культуры устроено именно так.
Мы говорим, что Расин такой гениальный, а Лафонтен растакой гениальный, потому что мы слышим в их произведениях голос Лафонтена и Расина. А с их собственной точки зрения, они были хороши не поэтому, а потому что смогли написать лучшие вещи в жанре, который они не изобретали, а копировали (а с нашей точки зрения — перепридумывали и переизобретали). Для них, классицистов, важно было не кто сделал, а как это сделано и сделано ли это так, как нужно. Для романтика иначе: всегда важно, кто это сделал, и хочется сделать не так, как другие. Эта тенденция достигает пика в авангарде: важно кто сделал, и не важно что ― текст может редуцироваться до авангардного жеста, до отсутствия текста, как в «Поэме конца» Василиска Гнедова, представляющей собою пустой лист бумаги.
Однако есть исключение, в некотором роде парадокс. В нашей постромантической культуре требование оригинальности не распространяется на перевод. Идеальный постромантический перевод ― это перевод, который верен оригиналу, то есть это новый текст, максимально приближенный к образцу и одновременно вызывающий желание быть прочитанным как бы вместо оригинала. И вот вообразим, что я сделал перевод с помощью искусственного интеллекта, а потом его отшлифовал; разве вы не будете читать этот перевод, если он действительно хорош? Уверен, будете читать. А если он будет плохим, то не будете читать. Но не будете потому, что он плох, а не потому, что его сделали с помощью искусственного интеллекта. А почему вы мне вдруг простили пользование машиной? Именно потому, что от перевода не ждут оригинальности. Но стоит автору написать с помощью ИИ фрагменты собственного романа, поднимается скандал. Не говоря уж о целом романе.
Что же получается? Если коротенький стишок, составленный с помощью искусственного интеллекта приписать себе нельзя, а огромный перевод можно, то проблема не в природе текста, а в нашей интерпретации этой природы, придании ей некоторого статуса. То есть в структуре нашей культуры.
Если коротенький стишок, составленный с помощью искусственного интеллекта, приписать себе нельзя, а огромный перевод можно, то проблема не в природе текста, а в нашей интерпретации этой природы, придании ей некоторого статуса
Напомню, как работал ренессансный драматург, тот же Шекспир. Нужно завтра ставить пьесу, ничего нету, текста нет, все актеры пьяные (это я фантазирую), сымпровизировать не смогут. Дело плохо. Сперли пьеску из соседнего театра. Ну, хреново написано, но первая часть вроде ничего. Быстро раздаем своим подельным и подручным, это вставили целиком, это переписали, взяли кусок еще кем-то написанного, дальше руководитель театра «Глобус» прошелся по всему гениальной рукой, окончание дописал сам, и вот мы имеем абсолютно классические, базовые тексты европейской культуры. И это, заметьте, не значит, что «Гамлет» не был им написан.

Театр «Глобус» в Лондоне в представлении художника. Источник
А доромантическая, даже доклассическая живопись? Не всегда какой-нибудь один ренессансный художник рисовал всю картину с начала до конца. У него мастерская, они работают на заказ, подмастерья подготавливают композицию, и вот он в конце рукою мастера прошелся. Не факт, конечно, что без последнего гениального штриха все это вместе будет производить тот же эффект. Но сейчас нам интереснее другое: чем эти театральные или живописные подмастерья отличаются от нашего искусственного интеллекта, который по модели того, как все делают, быстро подгоняет то, что здесь, по идее, должно быть?
А ведь художники еще и тренируют свою мастерскую. Цена на мастерскую Рембрандта или Рафаэля была и будет гораздо выше, чем на мастерскую художника третьего ряда, потому что их подмастерья лучше натренированы ― сначала их учат, а потом они еще и сами учатся. И чем это отличается от supervised learning и self-supervised learning?
Давайте отвлечемся от художественных текстов, я хочу другой пример привести, нехудожественный. В научном тексте, особенно в точных науках, где важна только формула, эксперимент и вывод, существует заранее заданная типовая структура статьи. В этих областях исследователи давно уже отдают полученные результаты нейросети, чтобы она уложила их в готовый формат. И точно так же филолог может отдать свою книгу другому человеку, чтобы тот проверил библиографию или составил указатель. А Набоков, между прочим, говорил — и не зря, что если даже вы не сами написали свою книжку, то указатель к ней вы все равно должны составлять сами. Значит, где у нас индивидуальность и креативность, а где автоматизм и ремесленничество, — это не онтологическое свойство культурных объектов, а исключительно точка зрения на них, которая то ли детерминирована культурой, то ли коррелирует со структурой культуры.
О значении «общих мест»
Книжка «Семь бесед о филологии и Digital Humanities: Интервью и дискуссии» вышла в издательстве МГУ очень не вовремя, в начале 2022 года. Мне хотелось не столько собрать под одной обложкой свои устные тексты, сколько снабдить их многочисленными ссылками, чтобы раскрыть то, что в разговоре остается за кадром как общеизвестное, а читателю может показаться совсем непонятным.
Сама эта идея, положенная в основу книги, возникла из опыта общения. Встречаясь с коллегами и студентами в разных странах, начинаешь понимать: ничего общеобязательного и общеизвестного не существует. «Известное известно немногим» (любимая цитата М. Л. Гаспарова из «Поэтики» Аристотеля). Фактически нет никакой информации или точки зрения, которая непременно будет общей для всех собеседников.
Начинаешь понимать: ничего общеобязательного или общеизвестного не существует. Фактически нет никакой информации или точки зрения, которая непременно будет общей для всех собеседников
Лучше все разъяснять по максимуму. Однако баланс понятного и непонятного очень трудно удержать: если все понятно, то скучно, если ничего не понятно ― неинтересно. Поэтому прежде чем сказать что-то новое, надо убедиться в том, что есть нечто понимаемое нами одинаково или хотя бы сходно, а потом в этом сходном начинать искать различия.
Источники
- Лорд А. Б. Сказитель / Пер. с англ. и коммент. Ю. А. Клейнера и Г. А. Левинтона. Послесл. Б. Н. Путилова. Статьи А. И. Зайцева, Ю. А. Клейнера. М.: Издательская фирма «Восточная литература» РАН, 1994. 368 с.
- Пильщиков И. А. Семь бесед о филологии и Digital Humanities: интервью и дискуссии (2015–2021) / Общая ред. и сост. В. С. Полиловой. М.: Издательство Московского университета, 2022. 190 с.
- Ярхо Б. И. Методология точного литературоведения: Избранные труды по теории литературы / Изд. подгот. М. В. Акимова, И. А. Пильщиков и М. И. Шапир; Под общей ред. М. И. Шапира. М.: Языки славянских культур, 2006. xxxii, 927 с.

