
О чем пойдет речь
Это первая часть нашего материала о мультимодальных нейросетях — нейросетях, которые могут обрабатывать несколько видов данных одновременно. В этой части мы расскажем о нейросети CLIP, которая представляет изображения и тексты как единый тип данных, и рассмотрим, как это может быть полезно.
Векторные представления: всё есть набор чисел
Для начала необходимо вспомнить, что такое векторное представление данных. Компьютер не способен понимать тексты, изображения, аудио и другие типы данных как человек — компьютер оперирует числами. Поэтому все данные нужно представлять в виде определенной структуры с числами.
Например, черно-белое изображение размера NxM можно представить как таблицу чисел c N строками и M столбцами. Ячейки этой таблицы составляют изображение в виде маленьких квадратиков (пикселей). В каждой ячейке таблицы — число от 0 до 1, которое определяет яркость соответствующей части изображения. 0 — черный квадратик, 1 — белый, промежуточные значения — оттенки серого.
Слова можно представлять через их номера в заранее заданном словаре. Например, словарь состоит из 50 тыс. слов, слово «белый» имеет номер 1156, а «кит» — 190. Тогда текст «белый кит» можно представить как последовательность из двух чисел: 1156 190.
Подобные представления данных подходят для передачи и хранения, но плохо подходят для работы на уровне семантики или, другими словами, на уровне смыслов. Например, слова «голубой» и «зеленый» могут иметь номера 115 и 401 в словаре, при этом сравнение этих чисел не дает никакой информации о «схожести» соответствующих им слов (например, эти слова используют в схожих контекстах).
Можно придумать более нетривиальный способ кодирования данных, однако практически невозможно вручную изобрести универсальное представление, которое бы полностью описывало все признаки, весь «смысл» соответствующего объекта. Всегда найдется задача, для решения которой существующее представление не содержит нужную информацию, поэтому пришлось бы создавать отдельное представление для конкретной задачи.
Решить задачу построения универсальных представлений данных можно с помощью нейросетей. Известные примеры таких нейросетей: Word2Vec для слов; BERT для текстов, нейросети, обученные без учителя (к ним относятся автоэнкодеры в том числе), для изображений.
Нейросети, предназначенные для построения представлений, получают на вход данные, закодированные простым методом в виде чисел, а на выходе возвращают набор чисел фиксированного размера. Такие наборы называют векторными представлениями. Они содержат семантику данных, и с ними удобно работать. Например, косинусная близость между такими представлениями отражает семантическую схожесть соответствующих слов, изображений и других данных.
Вижу только цель: как объяснить нейросети, что от нее требуется
Разберемся, как именно нейросети обучаются создавать полезные векторные представления.
Нейросеть — это последовательность математических преобразований, которые трансформируют входные данные. Например, нейросеть для работы с черно-белыми изображениями получает на вход таблицу чисел (фиксированного размера), описанную выше, и путем многообразных манипуляций с ее строками и столбцами превращает таблицу в набор чисел фиксированного размера (векторное представление).
Типы и порядок преобразований задает разработчик нейросети. Пример преобразования — умножение значений ячеек строки/столбца на число; число может быть произвольным. В этом случае тип преобразования — умножение.
При этом в зависимости от числа, на которое умножаются значения ячеек, преобразование по-разному влияет на входные данные. Числа, от которых зависят преобразования, называются параметрами. Меняя параметры, мы можем влиять на выход нейросети. Подробнее о параметрах нейросетей и других моделей машинного обучения можно прочитать в нашем материале.
Однако мало пользы от последовательности произвольных преобразований. Нам нужны только те последовательности преобразований, которые приводят к векторным представлениям, обладающим определенными свойствами.
Например, мы хотим получить нейросеть, которая для похожих изображений возвращает похожие векторные представления (в смысле косинусной близости), а для разных — сильно отличающиеся.
Для этого соберем набор изображений. Для каждого изображения из набора создадим его измененную версию: повернем на случайный угол, отразим по вертикали, изменим цвета и проведем другие манипуляции с исходным кадром.
Далее подадим по отдельности нашей нейросети три изображения: оригинальное изображение; его измененную версию; произвольное изображение из нашего набора, отличное от текущего. Нейросеть вернет нам их векторные представления.

Примеры оригинального изображения и его измененных версий
Посчитаем косинусную близость между: векторными представлениями текущего изображения и его измененной версией; векторными представлениями текущего изображения и произвольным изображением из набора.
После сравним эти два числа. Если первое число больше второго, значит, свойство, которое мы требовали от нейросети вначале, выполнено. На первых двух изображениях представлен один и тот же объект. От наших трансформаций смысл изображений не поменялся, и их векторные представления похожи. На первом и третьем изображениях, в свою очередь, разные объекты. Их векторные представления менее схожи, чем для представлений первого и второго изображения.
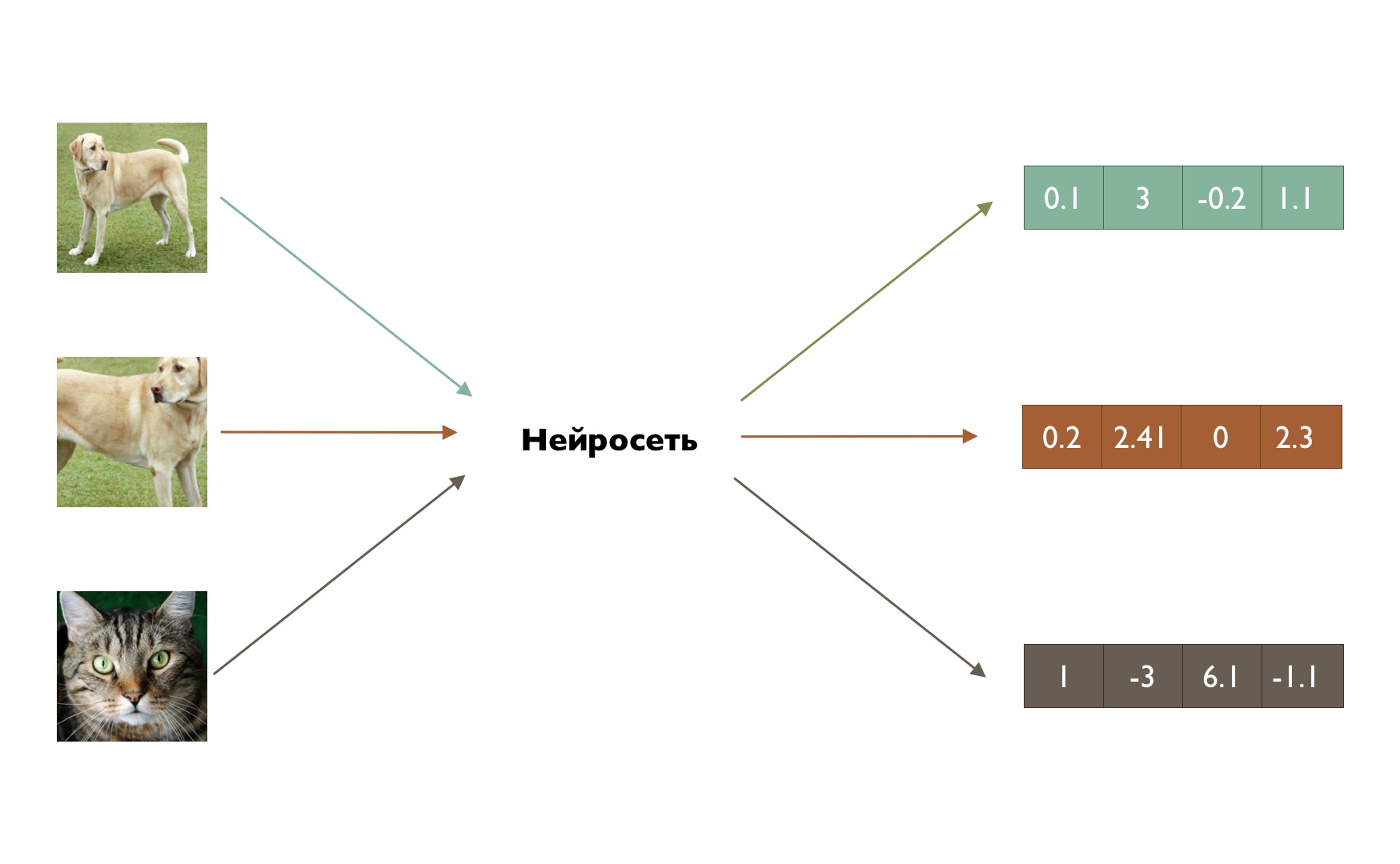
Демонстрация работы описанной нейросети. Для изображений одной и той же собаки нейросеть выдала схожие наборы чисел (векторные представления), а для кошки — совсем другой
Заметим, что наше требование к векторным представлениям свелось к конкретному алгоритму с подсчетом косинусной близости между выходами нейросети. Этот алгоритм можно запрограммировать на компьютере. Более того, этот алгоритм можно записать в виде математического выражения, значение которого будет зависеть от того, в какой степени выполняется требование. Чем больше выполняется требование, тем меньше значение выражения; соответственно, чем сильнее нарушается требование, тем больше значение.
Такое выражение называют функцией ошибки, или целевой функцией. Ее цель — численно показывать, насколько хорошо нейросеть решает поставленную задачу (что эквивалентно тому, как сильно нейросеть ошибается). Благодаря ней компьютер может в автоматическом режиме определять, насколько сильно нужно менять нейросеть. Если ошибка большая, то требуется сильно изменить нейросеть, если нет — нужны незначительные изменения.
Изменить нейросеть можно, меняя параметры преобразований, из которых она состоит. Как именно нужно искать оптимальные параметры? Возможных комбинаций значений параметров бесконечно много, и просто перебирать их крайне времязатратно. Поэтому существуют специальные методы, которые позволяют на основе информации от функции ошибки приближать параметры к правильным значениям за разумное время.
В рамках этой статьи устройство этих методов не так важно. Для простоты можно представить, что у нас есть суперкомпьютер, который способен перебирать триллионы комбинаций параметров за разумное время, и с помощью него мы можем найти ту комбинацию, которая обеспечивает маленькую ошибку. Поиск оптимальной комбинации параметров на основе информации от функции ошибки называется обучением нейросети.
Подытожим: наши требования к свойствам нейросети можно формализовать с помощью функции ошибки. Функция ошибки позволяет оценивать, насколько хорошо нейросеть соответствует нашим требованиям. На основе этой информации мы можем эффективно уменьшать ошибку нейросети, то есть обучать ее решать нашу задачу.
CLIP: как подружить текст и картинки
Наконец, перейдем к мультимодальным нейросетям. Модальность данных — это тип данных, например, текст, изображение, аудио. Соответственно, мультимодальные данные — данные нескольких типов. Мультимодальные нейросети — нейросети, работающие сразу с несколькими типами данных.
Допустим, мы хотим обучить нейросеть, которая умеет генерировать векторные представления и для текстов (например, как BERT), и для изображений (например, как нейросеть, описанная выше). При этом мы хотим, чтобы представления изображений были похожи на представления их текстовых описаний. Например, чтобы представление изображения собаки с теннисным мячиком было схоже (с точки зрения косинусной близости) с представлением текста «собака с теннисным мячиком».
Наша нейросеть будет состоять из двух отдельных внутренних нейросетей — для текста и для изображений. Помимо основного требования добавим еще одно: представления изображения и ее текстового описания должны быть более схожи, чем представления изображения и не соответствующего ей текстового описания. То есть представление изображения собаки с теннисным мячиком должно быть более схоже с представлением правильного описания, нежели чем, например, с описанием «кошка с футбольным мячом».

Демонстрация работы нейросети CLIP
Обучение этой мультимодальной нейросети устроено аналогично примеру с нейросетью для изображений выше:
- Из набора изображений и их текстовых описаний выбираем пару «изображение-описание» и с помощью соответствующих нейросетей получаем пару векторных представлений (изображения и описания).
- Из набора с данными выбираем произвольное не соответствующее изображению из п. 1 описание. С помощью нейросети для текста получаем векторное представление описания.
- Считаем две косинусные близости: между представлениями изображения и его описания; между представлениями изображения и неправильного описания.
- На основе посчитанных косинусных близостей считаем ошибку нейросети с помощью функции ошибки.
- Используя посчитанную ошибку, обновляем параметры нейросети.
Как можно увидеть, отличия есть только в наборе данных и в количестве нейросетей. Достать необходимый набор с изображениями и их описаниями на самом деле не так сложно. На многих сайтах изображения подписаны, поэтому достаточно извлечь эти пары из большого архива веб-данных. Заметим, что помимо пар «изображение-текст» можно рассматривать пары «видео-текст», «аудио-текст» и другие — от этого алгоритм не меняется.
Описанная выше нейросеть называется CLIP (Contrastive Language–Image Pre-training). Она была разработана в 2021 году компанией OpenAI, создавшей языковую модель GPT. Contrastive в названии обозначает метод обучения нейросетей Contrastive learning. В этом методе при расчете функции ошибки сравнивают косинусные близости между представлениями «соответствующих» объектов (изображения и их описания; изображения и их измененные версии и т. д.) и несоответствующих объектов (изображения и произвольные описания; разные изображения и т. д.). Другими словами, при обучении этим методом нейросеть учится сравнивать/противопоставлять объекты на основе их семантического соответствия.
Как и где используется CLIP
Нейросеть CLIP отображает изображения и тексты в одно пространство векторных представлений. Другими словами, CLIP представляет изображения и текст как единую модальность, поэтому представления изображений и их описаний взаимозаменяемые. Поэтому можно сравнивать семантическую схожесть изображений и текстов, используя их представления.
Из этих свойств вытекают несколько практических применений CLIP.
Первое применение — поиск изображений по их текстовым описаниям.
Например, вы хотите разработать сайт с фотографиями домашних питомцев, на котором можно по текстовому запросу найти нужные фотографии. Для реализации этой функции нужно сделать следующее:
- Собрать фото питомцев и для каждого фото получить его векторное представление с помощью нейросети для изображений (напомним: CLIP содержит отдельную нейросеть для изображений и отдельную нейросеть для текстов). Затем сохранить представления в базу данных.
- Получить векторное представление поискового запроса пользователя с помощью нейросети для текстов.
- Посчитать косинусную близость между представлением запроса из п. 2 и представлениями фотографий из базы данных (п. 1).
- Вывести изображения, чьи представления имеют наибольшую косинусную близость с запросом пользователя.
CLIP для подобного мультимодального поиска используется в поисковиках, онлайн-магазинах и рынках стоковых изображений.
Второе применение — классификация изображений.
Задача классификации — то есть задача определения того, что изображено, — обычно решается обучением нейросети. Если набор классов меняется, то нужно обучать новую нейросеть. То есть, если нейросеть обучена различать кошек и собак на изображениях, она не способна определять пингвинов и фрукты. Для каждого набора классов приходится собирать специальные наборы данных — набор пар вида (изображение; класс объекта на изображении). Зачастую собрать такую выборку сложно, особенно если классы необычные.
CLIP позволяет решать задачу классификации без обучения на специальной выборке. Для это используется следующий алгоритм:
1. Каждому классу сопоставляют текст(ы) вида «изображение/фото/рисунок {название класса}». Например, класс «собака» сопоставляется с текстами «изображение собаки», «фото собаки».
Для всех текстовых описаний классов с помощью нейросети для текстов (компонента нейросети CLIP) получаем векторные представления и сохраняем их в базу данных.
2. Для классификации данного изображения получаем его векторное представление с помощью нейросети для изображений (компонента нейросети CLIP) и считаем косинусную близость с векторными представлениями описаний классов из п. 1. Классом изображения будет тот класс, чье представление имеет наибольшую косинусную близость.
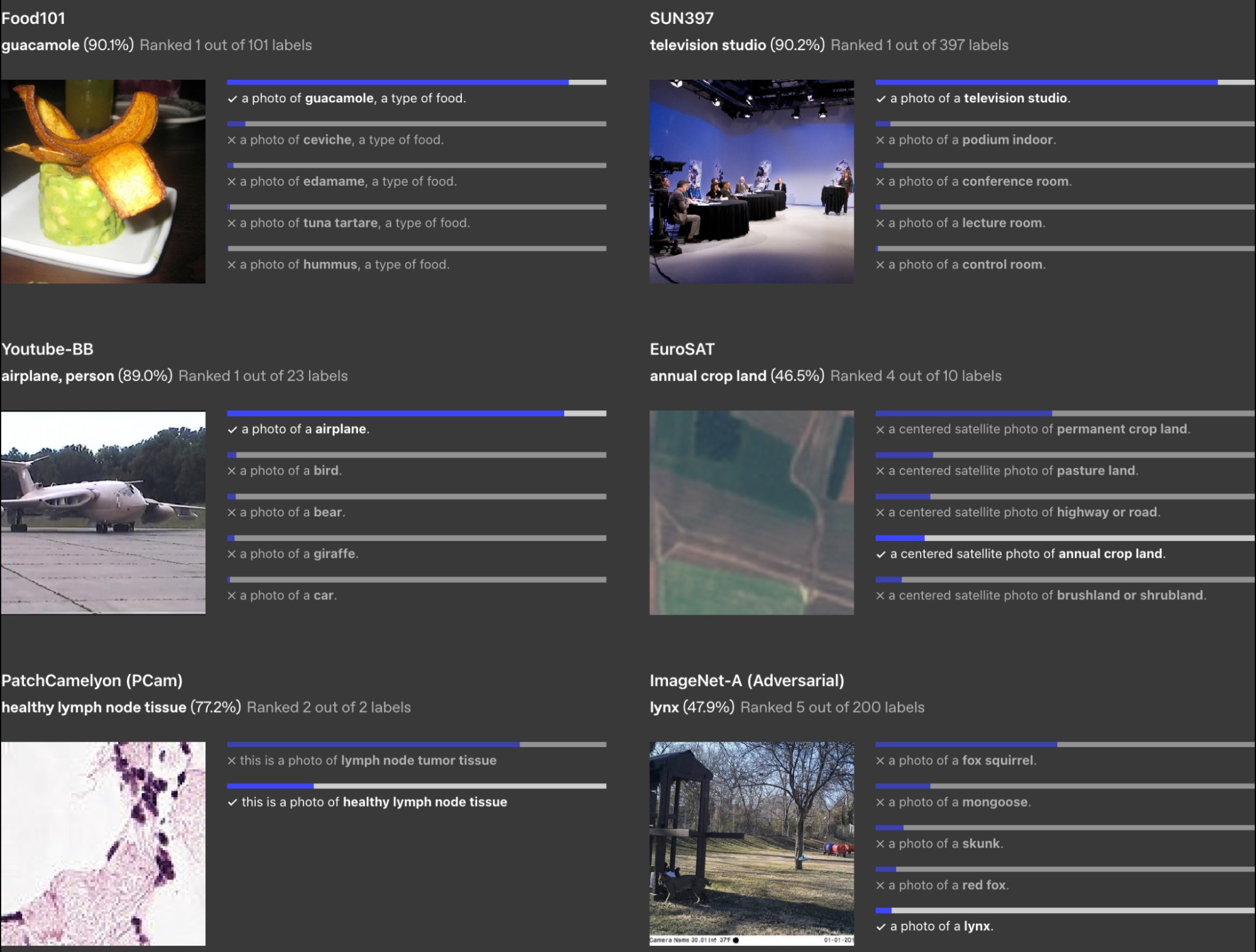
Демонстрация работы модели CLIP в качестве классификатора. Справа от каждого изображения находятся описания разных классов и косинусная близость между их представлениями с представлением изображения. Чем длиннее синяя полоска, тем больше косинусная близость, и наоборот. CLIP может классифицировать самые разные данные: еду, транспорт, виды тканей, фотографии со спутника
Такой алгоритм классификации на основе CLIP работает лучше, чем специальные нейросети, обученные для классификации. Особенно превосходство CLIP наблюдается в случаях, когда качество изображений, которые нужно классифицировать, сильно варьируется. CLIP более устойчив к вариациям освещенности, изменениям ракурсов и другим сложным визуальным условиям.
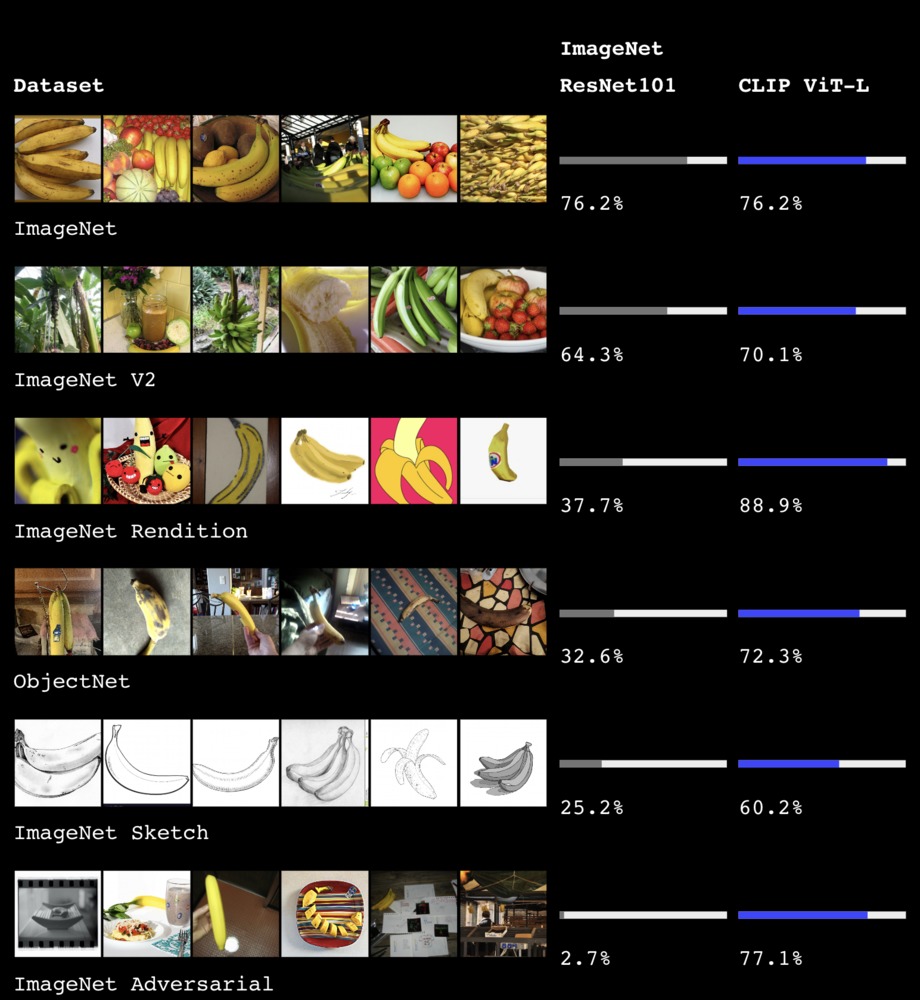
Сравнение обычного классификатора (Resnet101) с CLIP. В каждой строке изображены бананы в разных стилях/условиях. Справа отображена точность распознавания класса «банан» для каждой модели
Третье применение CLIP — использование с другими нейросетями.
Векторные представления CLIP можно использовать в паре с языковыми и генеративными моделями, тем самым наделяя их мультимодальными способностями. Такие модели могут генерировать изображения по текстовым описаниям, создавать описания изображений, анализировать визуальное содержание и выполнять другие задачи. О том, как конкретно это реализуется, мы расскажем во второй части материала.

