
Как компьютер находит объекты на видео?
Коротко: на самом деле он находит их на отдельных кадрах, но много раз в секунду, а еще может сравнивать изменения конкретных пикселей во времени.
В большинстве случаев найти движущийся объект на видео и описать движение — значит многократно найти этот объект на отдельных неподвижных кадрах. Делать это требуется быстро, совершая как можно меньше вычислений, но в то же время не слишком уж жертвуя точностью распознавания. А ведь видео с точки зрения компьютера та еще мешанина из огромной кучи бессвязных пикселей, меняющих цвет десятки раз в секунду.
Здравый смысл подсказывает: есть многослойные нейросети, по типу сверточных (мы уже рассказывали о них), они найдут среди всей этой неразберихи какие-то маленькие цветовые пятна, скомбинируют их, потом скомбинируют комбинации точек, повторят это еще много раз и в конце концов найдут в кадре нос, ухо, прическу, а может быть, и лицо. Но все это долго. На современных мощных компьютерах можно работать с видео таким образом, но что делать, если у вас смартфон либо фотоаппарат или на дворе 2007 год? Чтобы не рассматривать огромное полотно пикселей, стоит как-то сократить количество данных, на которые машина должна обращать внимание. Если можно быстро решать, есть ли в каждом отдельном кадре что-нибудь, похожее на лицо, появляется возможность работать с видео на лету. Сокращая входные массивы, человечество придумало некоторые интересные уловки.
Уловка первая. Представьте, что ваше лицо — это созвездие.
Коротко: если можно следить за сотней точек, то лучше уж так, чем за миллионом.
Попробуем охарактеризовать лицо человека как совокупность геометрических фигур, линий и точек. Эти точки расставим в уголках глаз, в уголках губ, на ушах, на крыльях носа, несколько поставим на овал лица. Соединим точки линиями и получим рисунок, на основе которого уже можно делать полезные выводы. Если зеленые крестики на верхнем и нижнем веке сближаются, значит, человек моргнул.
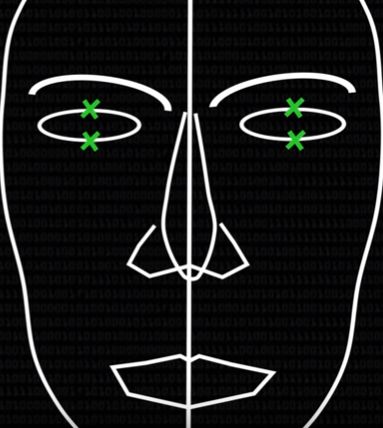
Главное — устроить все так, чтобы видео в режиме реального времени превращалось из потока пикселей в совокупность подвижных точек. Важно проверить, что получается ставить точку «левый угол правого глаза» именно там, где на видео появился этот самый угол. А еще убедиться, что при движении лица точки двигались бы вместе с ним и никуда не сбивались.

Для этого раньше создавали пиксельные модели частей лица, чтобы искать эти части на статичных кадрах. То есть буквально рисовали пиксельное усредненное изображение глаза: зрачка, ресниц, век сверху и снизу. Если на картинке найдется участок, примерно совпадающий с заданным узором, — мы нашли глаз, нос или ухо. Да, это делалось простой и последовательной «примеркой» усредненного глаза на каждый возможный участок фотографии. К сожалению, такой поиск едва ли эффективнее, чем в сказке про Золушку, когда принцу пришлось объехать все королевство (в нашем случае — всю картинку). Для облегчения задачи работают с черно-белыми изображениями — тогда можно сравнивать только яркость пикселей и не обращать внимания на оттенки.

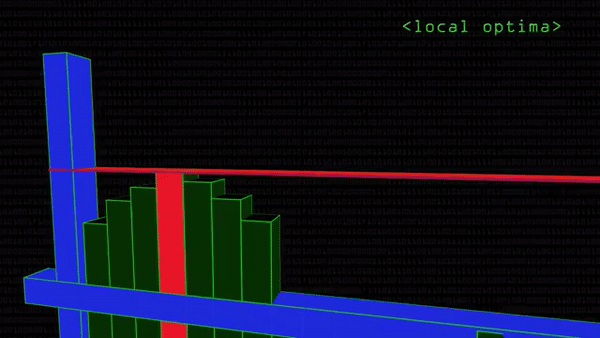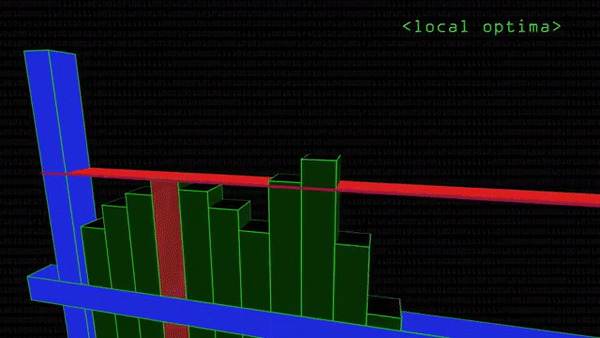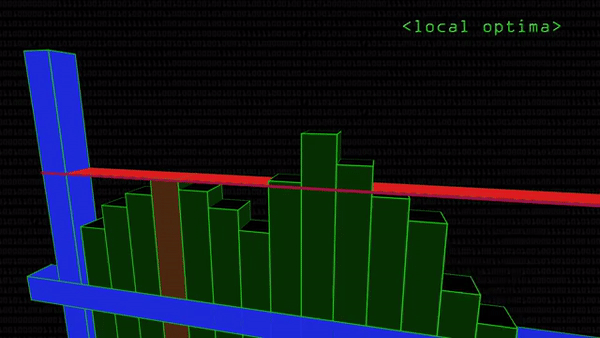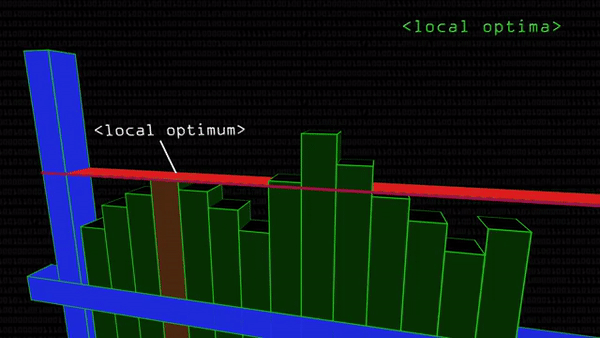
Чтобы не просматривать картинку целиком, программисты останавливают поиск на том участке, где вероятность найти глаз достигает пика, падая по мере удаления от него. Проблемы начинаются, когда принц находит ложную Золушку и отказывается ехать дальше. Такое может случиться, потому что математически поиск подходящего кусочка картинки выглядит как последовательная подстановка цветовых кодов пикселей в функцию. При нахождении кусочка, похожего на заданный образец, она принимает высокое значение: поиск глаза на картинке сводится к поиску максимума функции, как в школе.

Проблема в том, что максимум бывает локальным — на графике выглядит как вершина холма рядом с вершиной горы. Программа фиксирует, что производная функции в данной точке (красная линия на гифке сверху) параллельна оси абсцисс. Значит, дальше значения становятся только хуже (меньше). Останавливаем поиск, нашли Золушку. А настоящая Золушка (подлинный максимум) все это время была совсем рядом.
Проблема с локальным максимумом серьезна, и заранее неизвестно, какого размера будет лицо на фотографии: может быть, там будет 500 разных лиц. Станем примерять эталонный глаз к каждому фрагменту? Звучит неразумно.
Значит, есть другой способ искать лицевые точки на фото?
Коротко: да, больше не будем спрашивать у кусочков фотографии: «Не глаз ли ты?» Будем спрашивать: «Где должен быть глаз?»
Машинное обучение — это обширная область знаний, в рамках которой можно выделить много проблем и методов их решений. Среди методов выделяется, к примеру, классификация — это когда компьютер, зная признаки объекта, складывает его на одну из заготовленных «полочек»; или кластеризация — когда машина группирует похожие объекты, на ходу выдумывая «полочки»; или регрессия — когда по признакам объекта программа старается предсказать какое-нибудь целочисленное значение, связанное с ним. Например, предсказать длину галстука Ивана Петровича в зависимости от времени года, предсказать цену квартиры, опираясь на ее адрес, или предсказать, где на картинке находится нос, если мы знаем, где находится левая бровь.
Значит, распознать лицо можно регрессией: группа исследователей собирает 1000–3000 фотографий, скрупулезно вручную отмечает на каждой из них 70 лицевых точек и дает машине задание запомнить все варианты их взаимного расположения. В будущем, обучившись на таких данных, программа на основе того, как выглядит бровь, предскажет, как далеко от нее должен находиться нос или ухо.
Дальше каждая из лицевых точек «голосует» за то, где на картинке вероятнее всего должны располагаться другие точки. Для этого генерируется вектор (его направление и длина — это и есть те целочисленные значения, что предсказывает регрессия в данном случае), и он протягивается от данной точки к тому месту, где должен найтись подбородок или верхняя губа.

Интересно, что чем дальше «голосующая» точка находится от той части лица, положение которой она предсказывает, тем ошибочнее получается предсказание. К счастью, ошибки носят случайный характер и указывают во все стороны. При суммировании векторов они обнуляют друг друга, и остаются только правильные указатели.
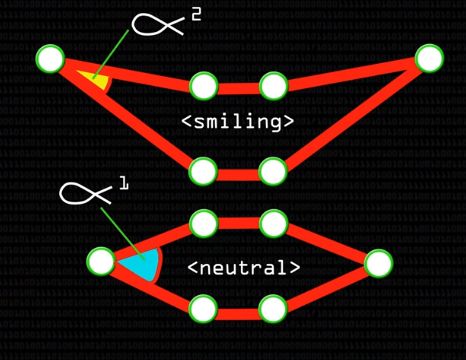
Когда нашлись все необходимые точки, стоит проверить получившуюся фигуру на допустимость: не оказалась ли верхняя губа под нижней или глаз ниже рта? Если так вышло, то стоит заново начать поиск лицевых точек. Если же все в порядке, то перед нами готовая геометрическая модель лица. На ней легко отследить изменения: например, зафиксировать улыбку, если угол, отмеченный на картинке ниже, станет меньше, чем был до этого, а то и сделать величину этого угла одним из входных признаков для многослойной нейросети — с подобным объемом данных она уже справится.
В целом держать в памяти перемещения сотни точек на лице человека гораздо проще, чем в реальном времени обрабатывать каждый пиксель исходного видео. Мы с успехом сократили количество входных данных, и такая модель лица уже может ответить на некоторые практические вопросы.
Но геометрическая модель не может дать идеальный результат в любой ситуации. Иногда люди улыбаются не как Джокер, а только немного напрягают уголки рта, так что в уголках и на щеках образуются ямочки. Выражение лица изменилось, а расположение лицевых точек — нет. Что выручит нас?
Уловка вторая. Бинарный локальный шаблон.
Коротко: сейчас закодируем, какие пиксели ярче своих соседей, а какие — темнее.
Оператор локального бинарного шаблона — это очень простая и вместе с тем хитрая штука. У нас есть черно-белая картинка. У каждого пикселя свой цветовой код: чем больше число, тем ярче точка, тем ближе она к белому. Оператор выбирает какой-нибудь пиксель (будем звать его «центральный») и сравнивает его значение со значениями соседей. Если значение соседнего пикселя больше центрального (сосед оказался светлее), вместо значения соседнего запишем 1, иначе — 0.
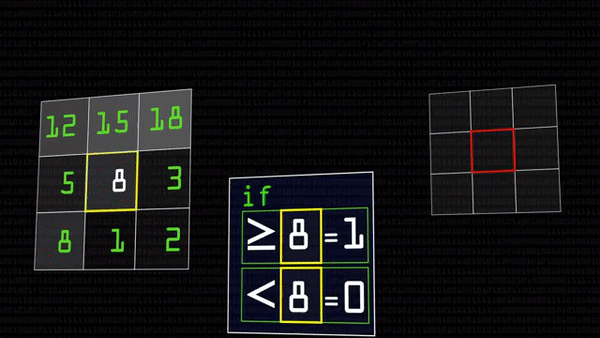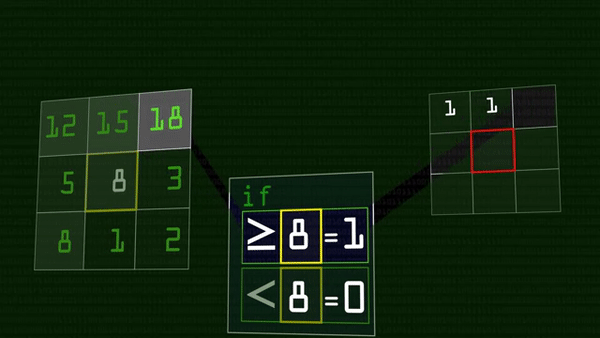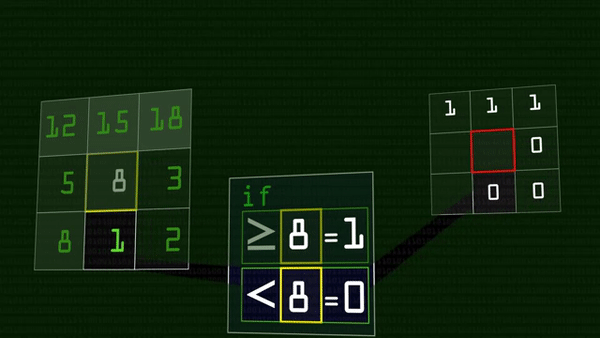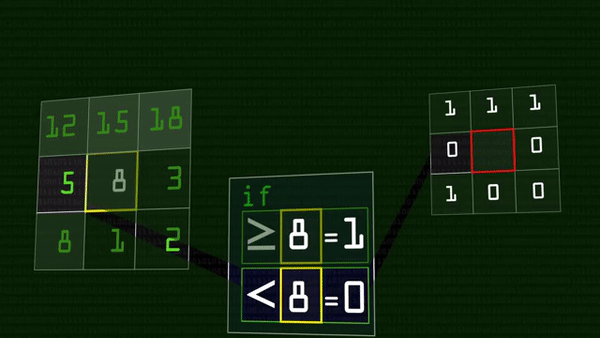
В итоге получится восемь единиц и нулей, которые, если записать их подряд, можно представить как число в двоичной системе счисления. Это число мы и запишем в центральный пиксель вместо его прежнего состояния, можно даже перевести в десятичную систему.
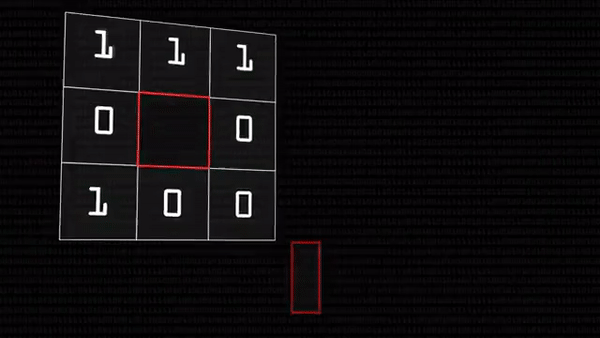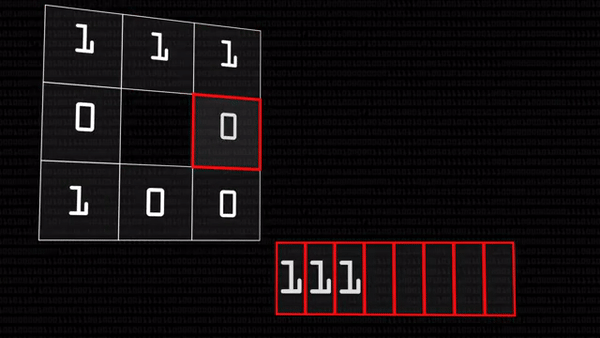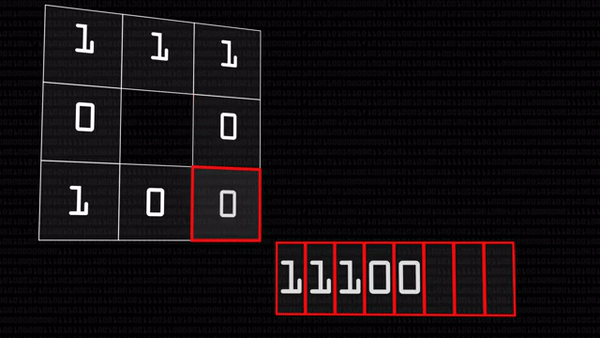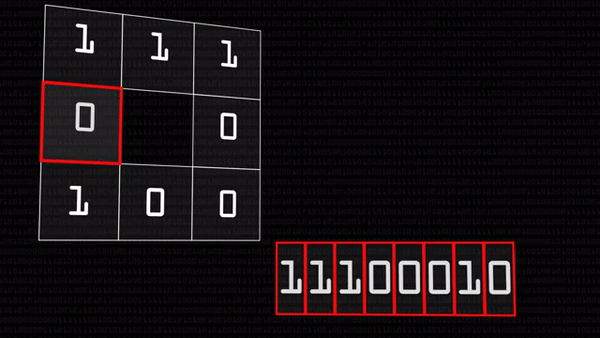
В результате у нас получилось число, характеризующее яркость данного пикселя относительно своих соседей, кодирующее локальный световой узор. Прелесть этого оператора в том, что он работает одинаково хорошо при разном освещении на фотографии: если в лицо на картинке посветить фонариком, оно станет светлее, но относительные величины яркости останутся прежними — 28 все равно останется меньше 35.

Дальше с получившимися числами на месте прежних центральных пикселей мы поступим как со статистикой. Разбив на фрагменты большое изображение, зафиксируем, сколько раз в любой из его частей нашлось 13 или 25. Такая статистика хорошо описывает фрагменты картинки, показывая, как часто на них встречаются темные участки по соседству со светлыми и насколько резки границы между ними. Эти частоты встречаемости чисел можно использовать опять-таки как входные данные для машинного обучения: алгоритм запомнит, что в тех фрагментах, где присутствует глаз, число 143 встретилось 72 раза, а 14 не встретилось вовсе.

Заметьте, мы только что описали большой фрагмент картинки довольно экономно и абстрактно. Что еще лучше, такая статистика для участков различных фотографий с глазом или подбородком будет похожа, даже если на фото разное освещение, люди разного пола, возраста или этнических групп, ведь все, что берется в расчет, — это яркость пикселей относительно друг друга.
А при чем тут видео и компьютерное зрение? Ведь для поиска объектов на статичной картинке есть сверточная нейросеть!
Коротко: теперь можно на лету анализировать, как изменяются значения пикселей на видео, ведь возможных значений всего два — 0 и 1.
Сначала отметим важную вещь: локальный бинарный шаблон очень хорошо находит края объектов. Если после его применения в рамке 3×3 оказался ряд нулей и ряд единиц, значит, где-то тут светлая часть картинки переходит в темную, а именно это и есть определение края объекта. Запомним это.
А теперь представим, что один кадр видео, которое мы хотим анализировать, выглядит как квадрат 3×3 точки. В таком случае видео из трех таких кадров уже выглядит как куб 3×3х3 точки: добавили временное измерение. Можно понаблюдать, как меняются значения пикселей-соседей вокруг центрального пикселя куба, но есть проблема: если соседей 26 (по 9 сверху и снизу и еще 8 посередине), то у куба найдется целых 226 состояний. Как уследить за ними?

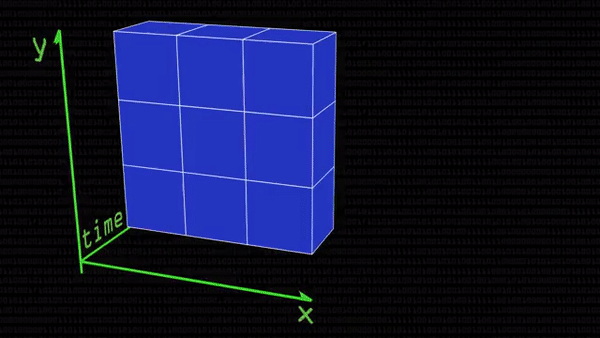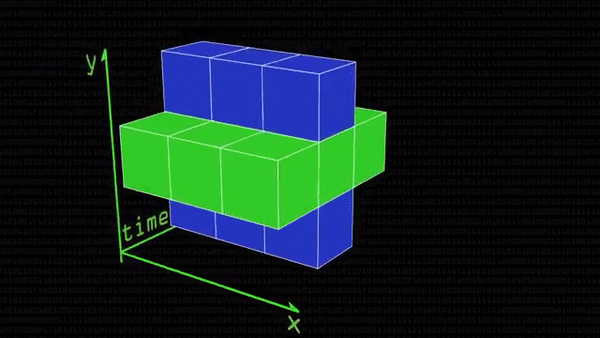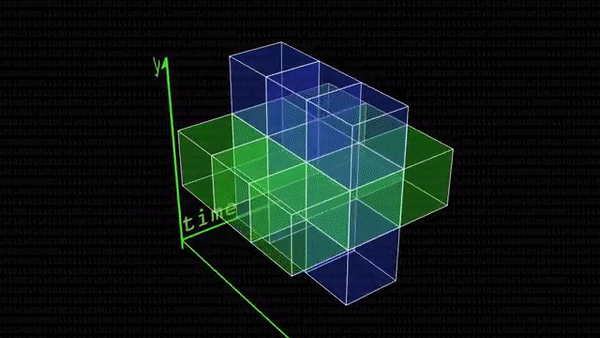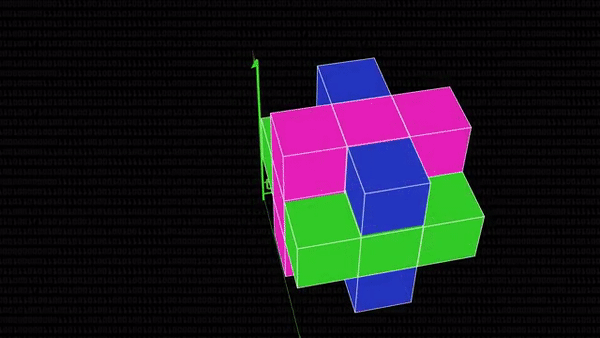
К счастью, оказывается, можно не учитывать абсолютно все изменения пикселей на видео или в статичном кадре. Из кубика достаточно выделить 3 перпендикулярные друг другу плоскости (их еще называют ортогональными) и посмотреть на них внимательнее. Соответственно, синяя плоскость — это статичный кадр, зеленая показывает, как со временем изменяются пиксели в ряд по горизонтали, а розовая — по вертикали. Если где-нибудь в этих плоскостях ряды единиц соседствуют с рядами нулей, значит, нашелся край какого-то объекта. А если он нашелся в розовой или зеленой плоскости, значит, раньше этого края там еще и не было: что-то на видео изменилось (но не обязательно даже сдвинулось: может, человек улыбнулся, и появились темные ямочки на щеках), и можно фиксировать изменение.
Уловка третья. Алгоритм Виолы — Джонса.
Коротко: сейчас будем вычитать друг из друга прямоугольные области на картинке и быстро решать, на каком кадре точно нет лиц.
В 2002 году Пол Виола и Майкл Джонс опубликовали работу на тему быстрого распознавания объектов на видео, и с тех пор работу процитировали примерно 17 000 раз. Их метод на тогдашних слабых процессорах позволял работать с 15 кадрами видео в секунду и успешно находить там лица — неважно, сколько их и какого они размера. С тех пор этот алгоритм не сдавал позиций и до сих пор используется в фотоаппаратах, планшетах и смартфонах.
В чем его суть? Создатели вводят четыре типа узоров, которые, как картинку с глазом в начале статьи, мы будем примерять к разным частям кадра.
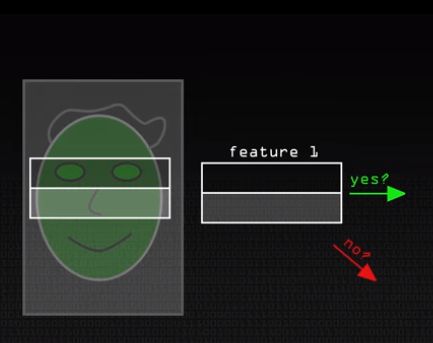
Если тест пройден и примерка показала, что верхняя часть и вправду темнее нижней, то с кадром работаем дальше и проверяем его во второй раз, уже с другими пикселями.
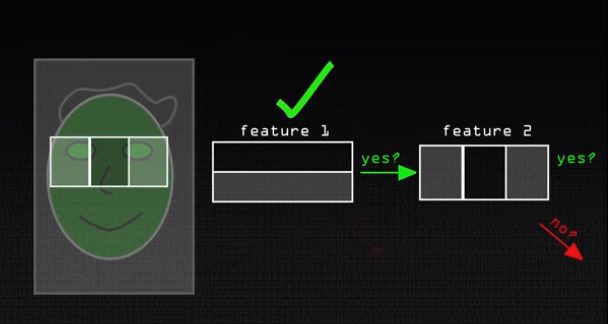
Если хоть на каком-то этапе окажется, что кадр не соответствует признаку, его моментально отбрасываем и считаем, что лицо внутри проверяемого участка не нашлось. Либо берем следующий кадр, либо ищем лицо на том же самом, но уже в другом месте. Такой подход позволяет не проводить почти никаких вычислений с большей частью кадров на видео и ускоряет процесс.
Логичный вопрос — как понять, на какой участок кадра следует примерить признаки, и смотреть, правда ли квадрат посередине оказался в целом темнее квадратов по сторонам? И это сложная часть в алгоритме. Перед тем как его можно будет использовать для определения лиц, сначала разработчикам приходится заняться обучением модели. Для этого они находят пару тысяч фотографий с лицами и пару тысяч фотографий без них, а потом на каждую из этих картинок примеряют признаки во всех возможных положениях, пропорциях и размерах. Это очень долгий процесс. Для стандартного размера признака 24×24 пикселя существует около 170 000 возможных вариантов его разрешенных состояний. Нужно проверить их все, а затем решить, какая именно рамка, какого размера и в какой части картинки лучше всего отделила лица от фотографий стены — с учетом того, что абсолютно никакая рамка не справится с этой задачей хорошо в одиночку.
Но допустим, что нашлась какая-то рамка. Может быть, она вычитает значения пикселей глаз из пикселей носа и пропускает на следующий этап почти все лица, а вместе с ними еще много лишних фотографий, на которых просто так получилось, что одна часть светлее другой. Эту рамку мы будем использовать как первый тест в алгоритме, а после нее выберем вторую по эффективности рамку, затем третью, четвертую и так далее — всего обычно используют несколько тысяч проверок. Мы ранжировали их так, что сначала алгоритм проверяет участок картинки на общие признаки: верно ли, что левая половина участка ярче правой, и если это действительно так, то картинка проходит на следующий этап. Признаки плавно становятся более конкретными и точными, хотя, может быть, и нелогичными, с точки зрения человека. Но на каждом этапе машина подбирает их таким образом, чтобы отсеять максимальное количество ненужных примеров и пропустить дальше все подходящие. В машинном обучении этот умный подбор цепочек простых тестов называют бустингом.
Кстати, на первом участке фотографии, где нашлось лицо, нельзя останавливать алгоритм — нужно проверить и другие кусочки изображения в разных вариациях и размерах: вдруг где-то найдется еще одно? Так что вычитать друг из друга прямоугольники с пикселями придется действительно быстро.

Для быстрого вычитания произвольных частей картинки друг из друга создатели пошли на красивую хитрость.
Хитрость эта состоит в том, чтобы значение каждого пикселя в кадре заранее заменить на сумму значений всех предыдущих пикселей и его собственного.

Теперь для того, чтобы посчитать сумму пикселей в правом нижнем углу, мы можем не складывать сами пиксели, а отнять от суммы вообще всех точек на картинке (то есть от значения самой последней точки) суммы тех областей, которые нам не нужны (то есть значения их нижних правых пикселей). Все манипуляции с большими областями сводятся теперь к работе со значениями их крайних пикселей.

Забавно, что в этом конкретном случае мы ничего не добились: нашли сумму четырех пикселей в четыре действия, но, если бы этих пикселей было больше — а их всегда гораздо больше, — такой подход сэкономил бы вычислительную мощность.
Эта уловка — преобразование изображения в интегральный формат — помогает значительно ускорить вычитание одного фрагмента картинки из другого, а вкупе с тщательным подбором оптимальных признаков, то есть размеров и положений вычитаемых участков, обеспечивает высокую скорость и приемлемую точность алгоритма.
Это лишь некоторые из приемов, используемых разработчиками для построения алгоритмов компьютерного зрения. Главное в таком деле — придумать, как быстро учесть важные части изображения, не обращая внимания на остальные. Можно превратить лицо в созвездие точек, можно закодировать яркость пикселей относительно друг друга или даже многократно проверить, а не темнее ли вон тот квадрат, чем соседние два? И хотя наши примеры касались именно распознавания лиц, базовая идея при распознавании любых объектов остается примерно одной и той же.
При написании этого текста анимацию и многие сведения мы брали из отличных видео на Youtube-канале Comuterphile:



