Недавно «Системный Блокъ» рассказывал о графических фильтрах, которые используются в Инстаграме или в Photoshop. Мы разобрались, как усреднять значения пикселей, а также находить края и углы объектов при помощи ядер свертки. В этом тексте мы пойдем дальше — и разберем по шагам, как с этим работают нейросети.
Чтобы понять, как это поможет нам в машинном обучении, сначала давайте вспомним, чем в общих чертах занимается нейросеть.
Коротко: получает на вход набор чисел и в разных сочетаниях перемножает их между собой и складывает
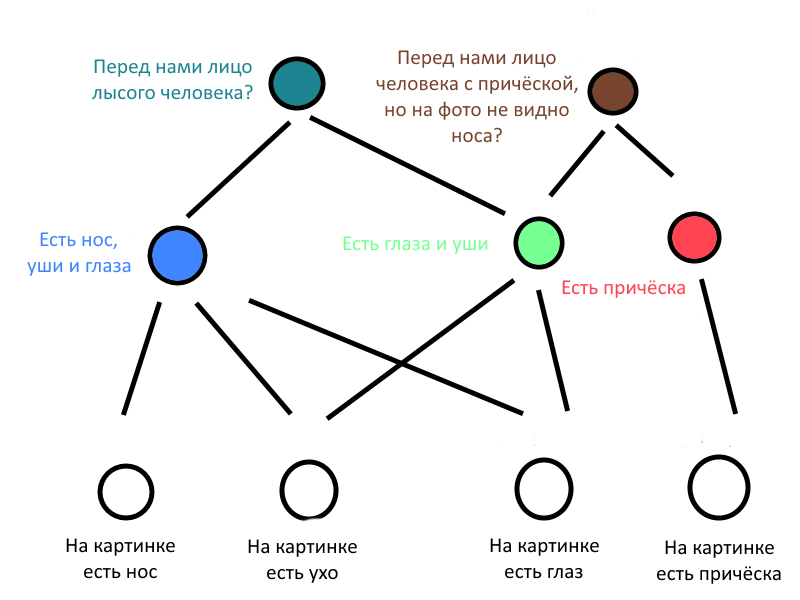
Нейронную сеть можно представить как алгоритм, который получает данные, обрабатывает их в несколько этапов и затем выдает уже измененные данные (в принципе, так делает любой алгоритм). Один этап обработки данных программисты договорились называть слоем нейросети. Слой состоит из нескольких нейронов, то есть функций, которые по-разному обрабатывают разные кусочки входных данных. «Внутри» нейрона программа может, например, просто умножить несколько чисел на несколько других чисел, и, если сумма произведений превосходит заданный порог, передать сумму на вход другому нейрону. Если нейрон отправил свою сумму «по цепочке», говорят, что он активировался. В нашем случае это означает, что он обнаружил те пиксели, которые запрограммирован искать.
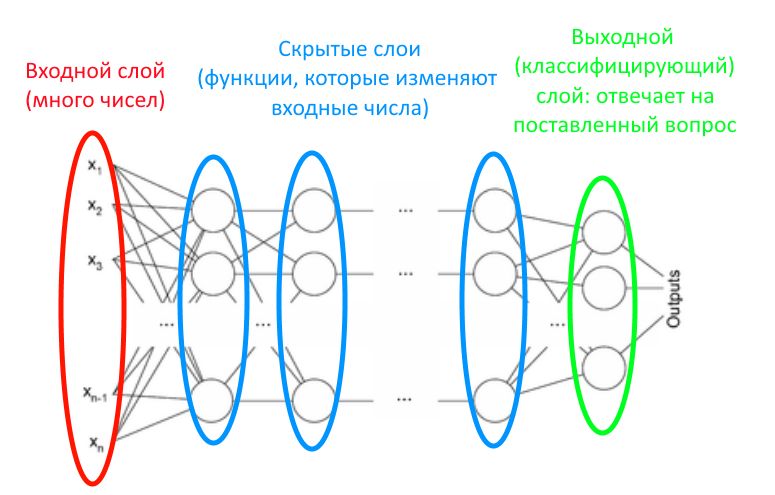
У нейросети есть самый первый, входной слой (в него мы загружаем числа — например, для небольших картинок это может быть каждый пиксель в виде числового кода его цветов), скрытые слои (они «скрытые» буквально, потому что человек напрямую не загружает и не выгружает из них данные), и есть выходной слой, последний. Если задача нейросети — классифицировать картинку с числом, сказав: «я вижу двойку!», то нейронов на последнем слое будет ровно столько, сколько должно быть вариантов ответа. Например, десять, если мы распознаем цифры от 0 до 9. Какой нейрон активировался (набрал нужную сумму), тот и «отвечает» в итоге. Об этих процессах мы уже однажды писали.
На предыдущей картинке показана схема полносвязной нейронной сети. Это название означает, что каждый нейрон любого слоя работает не с несколькими числами из предыдущего, а сразу со всеми. Все части такой нейросети связаны друг с другом.
Зачем так придумали? Покажем на примере. Допустим, мы бы хотели загружать в компьютер данные о каком-нибудь доме, чтобы предсказывать его цену.
Что станет «множеством чисел» на входе нейросети? Ну, например, х1 — количество окон на первом этаже, х2 — число ванных комнат, х3 — площадь в метрах, х4 — наличие гаража (1 — если есть, 0 — если нет). Создатель нейросети сам решает, какие параметры важны и сколько их необходимо. Эти числа, эти входные данные (x5 — число каминов) еще называют признаками объекта. Человек загружает их на входной слой нейросети.
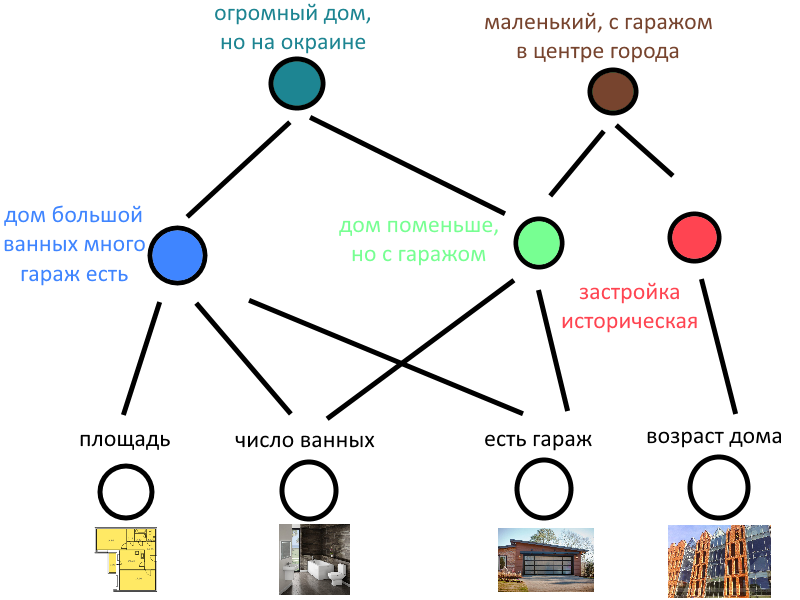
Алгоритм машинного обучения комбинирует все возможные признаки во всех возможных вариациях, скажем, вот этот синий нейрон активируется, если дом огромный и с гаражом (выполнились оба условия), а вот этот красный — если квартира в историческом здании в центре Питера. Нейросеть не останавливается на первом шаге и дальше комбинирует уже комбинации признаков, получая новые промежуточные переменные, а потом, на следующих слоях — комбинации комбинаций комбинаций, еще и еще, и так далее, постепенно углубляя сложность каждой отдельной комбинации. И всегда есть обучающая выборка домов, цена которых заранее известна, и входные признаки — тоже известны. Компьютер запомнит, что когда-то дом площадью больше 100 кв. м с двумя этажами и синей крышей, с пятью окнами продался за 100 000 долларов. В следующий раз, когда при анализе нового дома снова активируются нейроны, «отвечающие» за синюю крышу и за пять окон, программа снова предположит похожую цену. Или немного изменит её, ведь, может быть, активировался еще и нейрон «этот дом стоит возле аэропорта», а такие дома продаются дешевле.
Проблема с реальными нейросетями в том, что исследователи не могут так просто сказать, какой нейрон за что отвечает: из-за их количества и запутанности сети это не так очевидно, как хотелось бы. К тому же это обычно даже не важно: если правильно настроить веса сигналов, передаваемых нейронами, модель станет верно предсказывать цену всего дома, а ведь это как раз то, ради чего мы её создавали, не так ли?
А можно заставить компьютер предсказывать цену дома по фотографии?
Коротко: можно попробовать. Для этого при помощи ядер свёртки найдем самые простые совокупности черточек и точек на картинке и объявим их «признаками» объекта.
Мы совсем разленились и даже не хотим собирать данные о недвижимости, а хотим, чтобы, получив фотографию дома, компьютер сам всё о нём узнавал и выдавал цену, как-то вот так:

Что сделать входными признаками, какие числа подавать на вход нейросети? Первая мысль — давайте всю картинку, пусть х1 будет первый пиксель, х2 — второй и так далее. Тогда уж точно у нейросети будут все данные, которые могут ей когда-либо понадобиться, правильно? Однако, если наша картинка в HD, 2500 пикселей на 2500, входных данных уже будет около шести миллионов чисел — подобная нейросеть просто расплавит компьютер. Надо как-нибудь сократить количество входных данных. Если на входе будут не пиксели, то что вместо них?
Сейчас отойдем от аналогии с домами. Теперь мы хотим определить, есть на произвольной картинке лицо человека или нет, с лицами получается нагляднее. Так вот, до изобретения сверточных нейросетей разработчики брали картинку и искали на ней углы и края при помощи ядер свёртки. Вот, скажем, знакомое нам ядро, оно находит вертикальные края объектов: найдём такие края на лице человека.
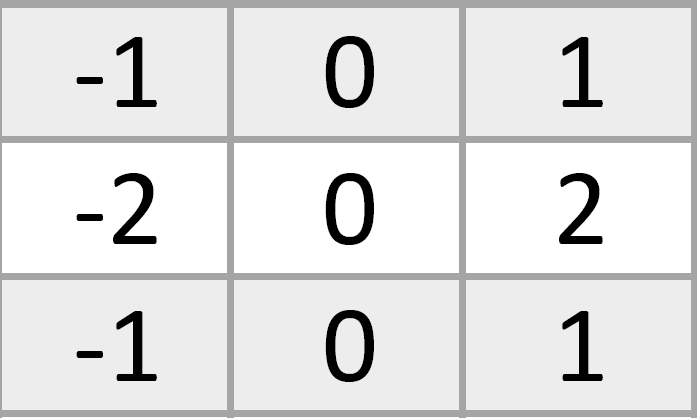
Если повернуть ядро на 90 градусов, так, чтобы нули оказались в одной строке, найдутся и горизонтальные границы. Полюбуемся на результат: получились два милых портрета.
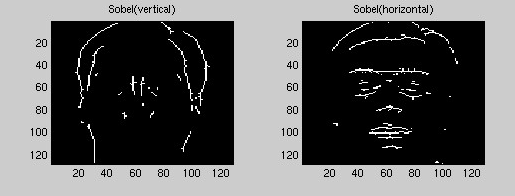
Зачем мы это сделали?
Коротко: маленькие части этих страшных картинок мы будем подавать на вход полносвязной нейросети вместо шести миллионов отдельных пикселей. Так мы сократили количество входных данных.
Программист снова решает сам, какие признаки ему важны, то есть, с какими переменными будет работать его полносвязная нейросеть. Может, признак х1 он сделает «на картинке в левом верхнем углу нашлось больше пяти белых пикселей» (True — если да, False — если нет), а х2 — «посередине есть две продольных полосы». Решение полностью зависит от замысла создателя модели, как и выбор ядер свёртки. Потом начинается обучение модели, как в примере с недвижимостью.
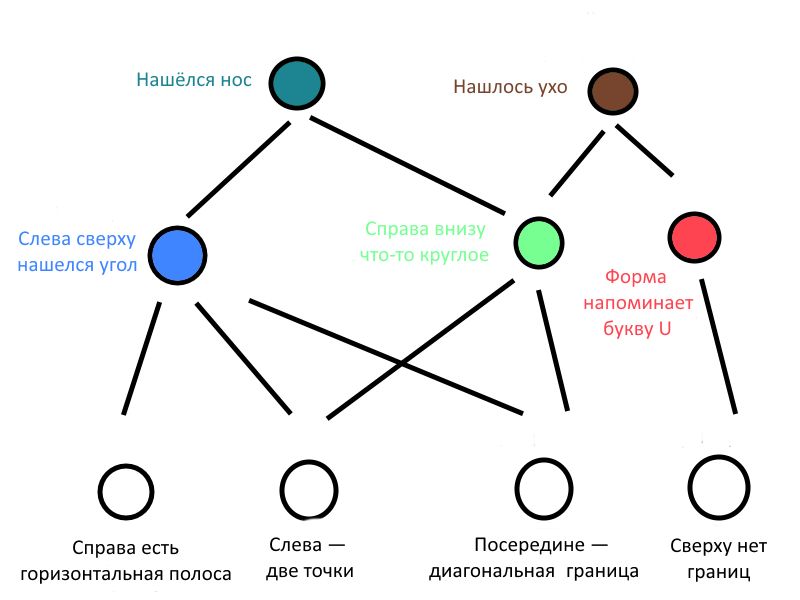
Проблема в том, что низкоуровневые признаки, важные для распознавания, очень трудно придумать человеку — в самом деле, не ищем же мы на фотографиях недвижимости десять параллельных линий, чтобы сказать, что дом попался хороший? Значит, можно попросить компьютер придумать вообще все возможные признаки и их сочетания, а потом самостоятельно выбрать, какие их них — важные. Вот именно эта способность и отличает сверточную нейросеть от всего, что мы рассмотрели ранее.
Это важно: ранее рассмотренные нейросети были не свёрточными, свёрточные начнутся сейчас.
Как компьютер должен выбрать, какие части картинки важны для анализа?
Коротко: составить все возможные сочетания сочетаний разных углов и черточек, и запомнить, какие встречаются на картинках с котами, какие — с двойками, а какие — с людьми.
Благодаря блестящим видео на Youtube-канале Computerphile мы можем наглядно увидеть процессы, протекающие в сверточных слоях сверточной нейросети. Нейросеть из примера учится узнавать на картинках рукописные цифры.
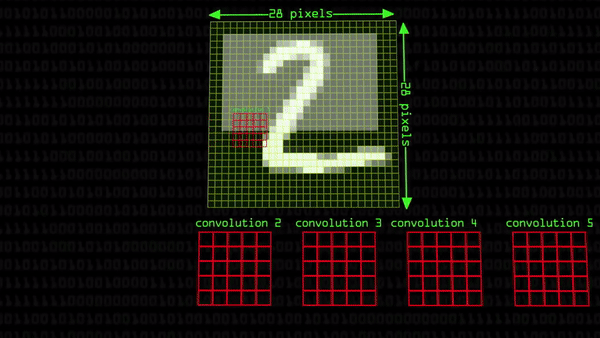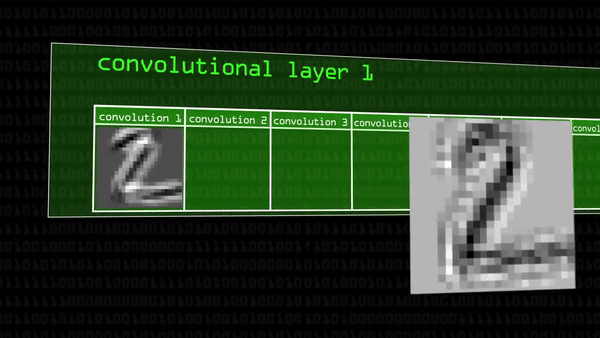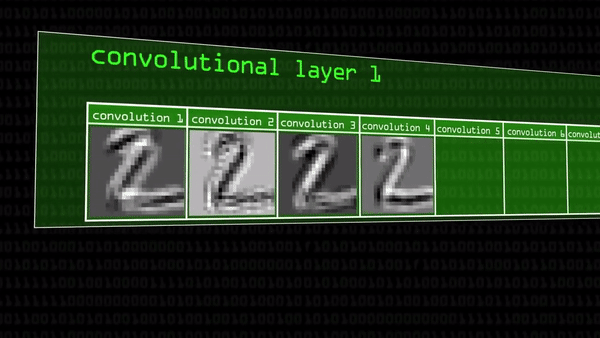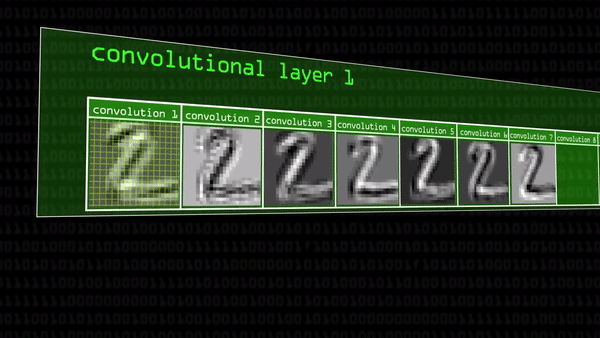
Сперва возьмем маленькую черно-белую картинку с нарисованной двойкой, и обработаем её при помощи ядра свертки 5×5 пикселей. Получится какая-то новая картинка с двойкой, причем некоторые ее части будут выделены ярче остальных, может быть, это были вертикальные границы цифры. Но на первом шаге мы не остановимся, и возьмем сразу еще 50 разных ядер свертки и «пройдемся» ими по изображению двойки:

Получилось 50 новых картинок. Каждое ядро свертки уникально и умножает цветовые коды пикселей на неодинаковые значения. В результате выходит набор пока еще похожих друг на друга изображений (но уже немножечко разных). На них сейчас подсвечено что-то очень простое, например, вертикальные или диагональные края. Такие картинки называются карты признаков, потому что выделенные белые пиксели воспринимаются как уникальные черты объекта. С ними пока вряд ли получится сделать что-нибудь интересное, но до интересного сейчас доберемся:
Перескочим на следующий сверточный слой. На нем к каждой из черно-белых картинок мы применим еще по 50 ядер свёртки, а к каждой из этих новых — еще по 50: так всякий раз карт признаков будет становиться все больше (уже 250 вместо 50). Постепенно получаются те самые «комбинации комбинаций» границ, углов и точек, которые мы видели выше, в примерах с распознаванием черт лица и с угадыванием цены дома.

Важно, что из-за способа применения ядра свертки всякий раз исходное изображение становится меньше, теряет в разрешении, длине и ширине. Поэтому сложные фигуры всё труднее разглядеть на картах признаков, они очень расплывчатые. Так задумано, в частности, чтобы сэкономить память, и реализуется потому, например, что ядро свертки не выходит за края картинки (хотя применяются и способы посложнее, это сейчас неважно). На гифке ниже 36 пикселей превратились в 12 (за 12 «шагов»).
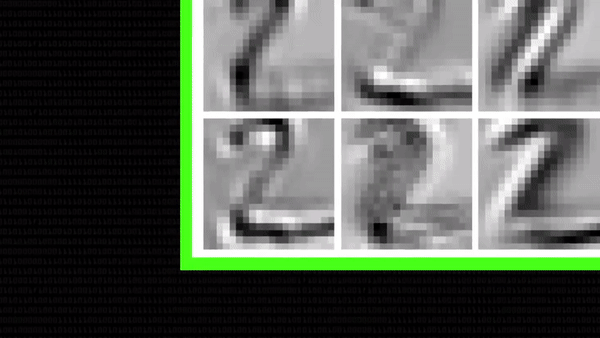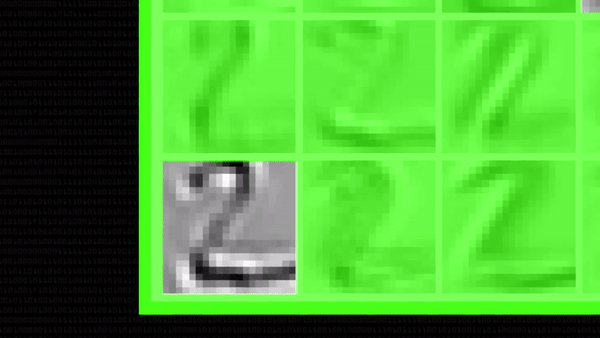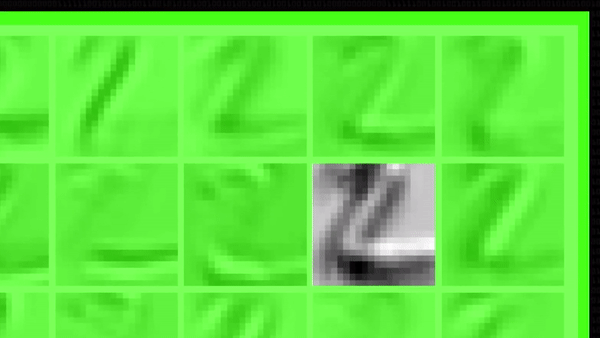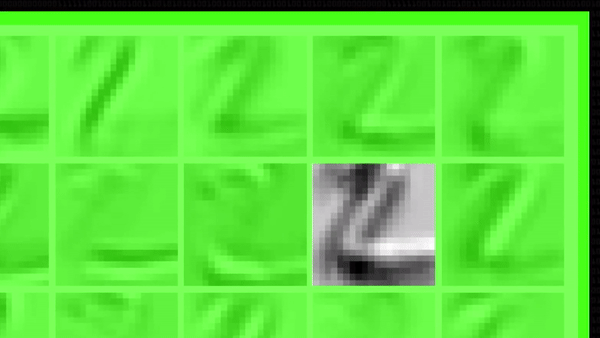
На этом этапе уже можно заметить, что некоторые свертки подсвечивают только определенные геометрические фигуры двойки, немного абстрактнее, чем раньше. Пока везде сохраняется диагональная часть, но с остальными чертами алгоритм поступает по-разному: на иллюстрации ниже первая свертка выделяет белыми точками «крючок» в верхней части цифры, а вторая — верхнюю часть нижнего горизонтального штриха. Свертки понемногу специализируются.
Все это это время количество карт признаков быстро росло (помните?), ведь к уже 50 первым сверткам мы применили еще по 50 ядер: значит, только на втором этапе получилось 250 новых черно-белых картинок.
С каждым шагом находимые признаки углубляют уровень абстракции, а размерность картинки падает. В конце-концов от исходной картинки останется всего один пиксель: он подсветится, если на изображении нашлась такая комбинация (комбинаций комбинаций комбинаций) линий и черт, которое человек называет двойкой.
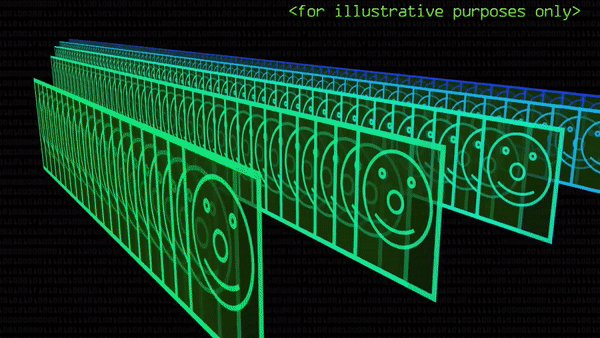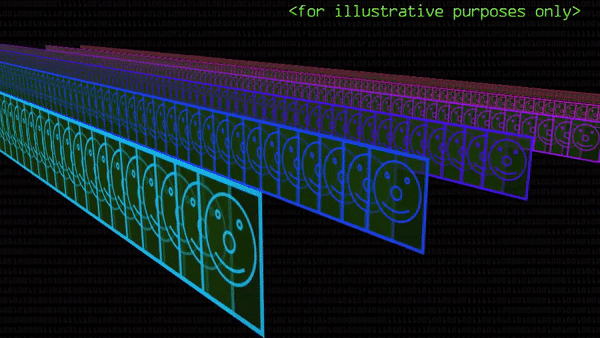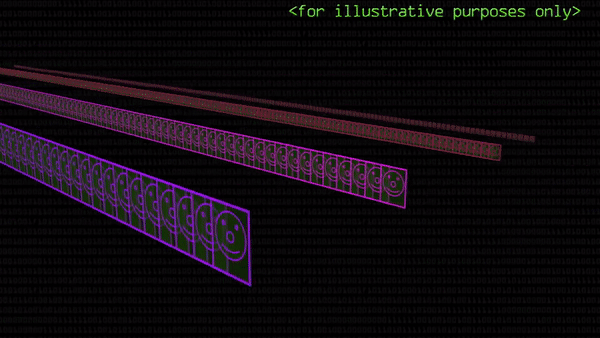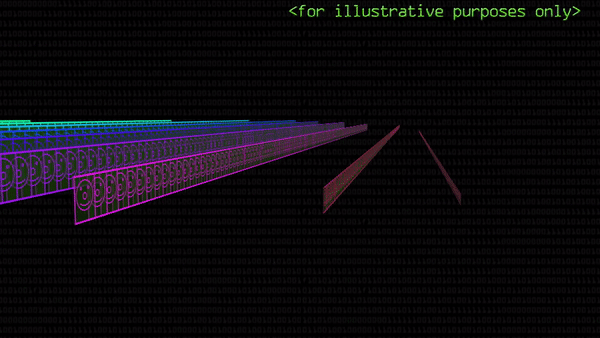
Мы больше не знаем, где на картинке расположен тот или иной признак, но знаем, что для компьютера он станет частью абстрактной «идеи» двойки, не связанной с конкретным начертанием. Платону понравилось бы!
Вот так это выглядит. На гифке ниже уже совершенно нельзя разглядеть никакие черты двойки, но при помощи яркости отдельных пикселей эти картинки 4×4 кодируют наличие «признаков» двойки на исходном изображении. Если сложим 16 значений пикселей вместе, получится единый сигнал, передаваемый сверткой. Его мы включим в полносвязную нейросеть.

Как раз этот длинный-длинный ряд одномерных сигналов и станет входными данными для полносвязной нейросети, какую мы уже видели ранее. Только теперь эти признаки не примитивны, а очень сложны и абстрактны — а главное — сформированы самим алгоритмом.
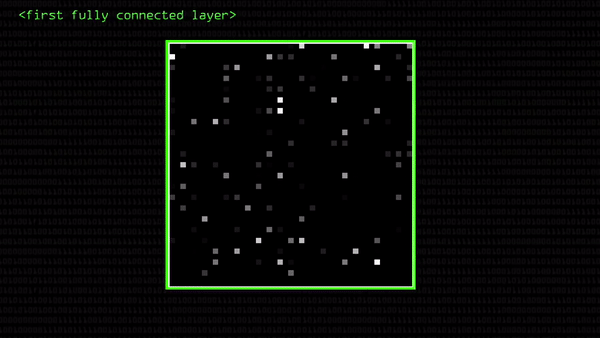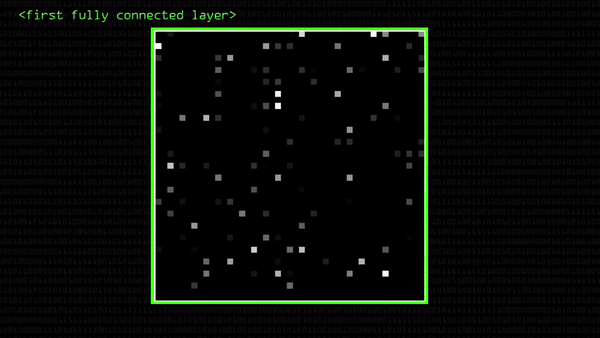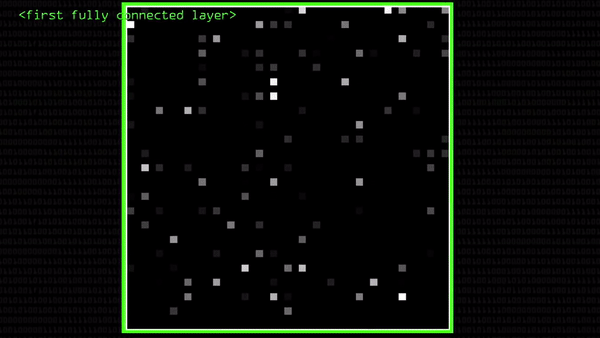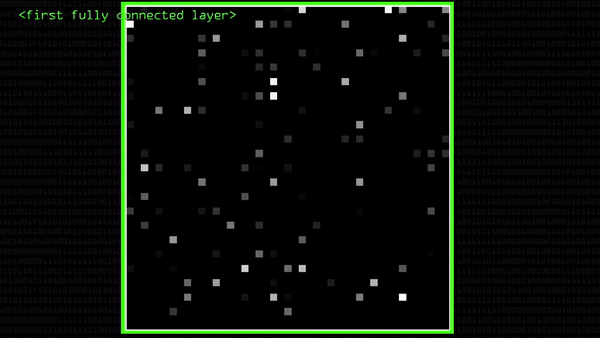
Посмотрите, какая карта активации нейронов получилась в нашем примере. Это — визуализация первого полносвязного слоя, где каждая точка — одна бывшая свертка 4×4 (но все пиксели сложили и получился один). Чем ярче светится точка, тем важнее сигнал для распознавания двойки (то есть, тем больше сумма кодов 16 пикселей свертки). Грубо говоря, так компьютер «представляет себе» понятие о нарисованной цифре.
Если бы мы распознавали не двойку, а четверку, свертки бы получились совершенно другими и подсвечивали бы не те части картинки, что раньше, хотя мы и умножали бы пиксели на те же самые числа. Вот, например, две совсем непохожие свертки четверки и двойки, хотя с картинками проделали ровно одно и то же:

Эта «непохожесть» разных объектов как бы высвечивается алгоритмом, показывается во всей ясности. Для четверки и двойки хорошо видна разница в том, какие нейроны активировались на полносвязном слое нейросети: именно эта разница и позволяет компьютеру отличать одно от другого.

Вот на это, в общих чертах, и похож механизм работы свёрточной нейронной сети. Сначала алгоритм выделяет на исходной картинке очень конкретные и низкоуровневые признаки, группы пикселей, оказавшихся рядом с каким-нибудь цветовым пятном. Подсвечивая на получившихся картинках с признаками новые элементарные признаки, программа комбинирует их и постепенно усложняет. Исходное изображение превращается в бесчисленные комбинации карт признаков, где активированы те или иные пиксели, и медленно сжимается, доходя в размерах до единственной точки — а эту точку уже можно рассматривать как сигнал, передаваемый нейроном. Такой сигнал комбинируется с другими сигналами и активирует цепочку нейронов в полносвязной сети, на конце которой один-единственный нейрон, сложив достаточное количество «очков» от других нейронов, заявляет: «Я вижу на картинке лицо!»
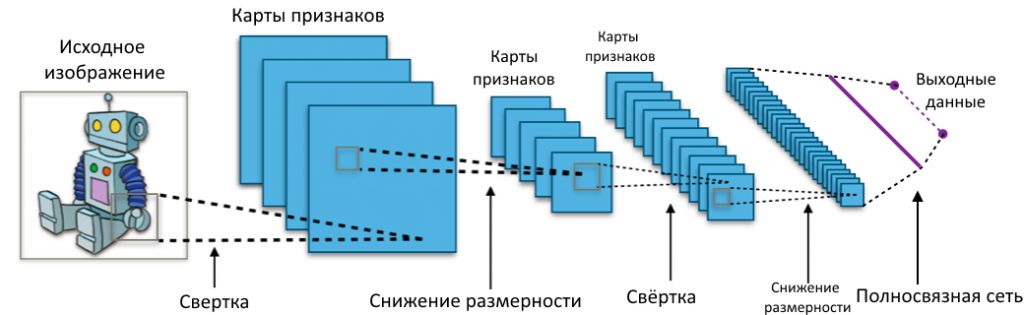
Источник: Inside a Neural Network — Computerphile



