
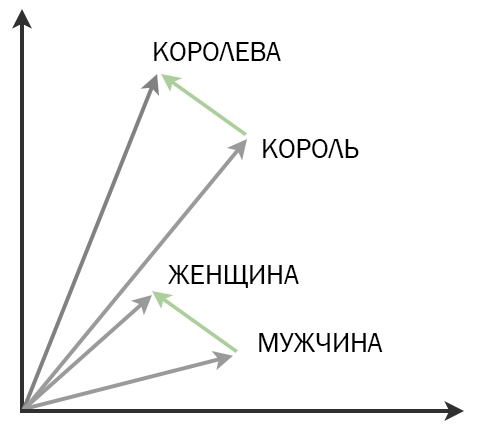
Технология Word2Vec работает с большим текстовым корпусом и по определенным правилам присваивает каждому слову уникальный набор чисел — семантический вектор. Помните, как мы складывали и вычитали векторы в школе? Точно так же, если из вектора слова король вычесть вектор мужчина и прибавить вектор женщина, получатся числа, соответствующие слову королева.
Никто явно не указывал эти закономерности — они напрямую следуют из того, каким способом слова получают свои наборы чисел.
Как можно представить смысл слова в виде чисел? Специальный код для каждой буквы?
Нет. С точки зрения семантического вектора смысл спрятан не внутри слова, а сосредоточен в его контексте. Вектор показывает, как часто слово встречалось рядом с другими словами.
Вся идея семантических векторов основана на дистрибутивной гипотезе. Она состоит в том, что смысл слова заключается не в наборе его собственных звуков и букв, а в том, среди каких слов оно чаще всего встречается. То есть смысл слова не хранится где-то внутри него, а распределен между элементами его возможных контекстов, отсюда и название — дистрибутивная гипотеза.
Если подходить к тексту с этой позиции, то котёнок окажется сильнее связан по смыслу с щенком, потому что оба они встречаются рядом со словами милый, пушистый, маленький. В то же время со словом стол котёнок почти не будет связан — котята редко бывают ровными, пластиковыми и деревянными.
А откуда цифры?
Представьте себе квадратную таблицу, в которой каждая строчка — это какое-то слово из словаря большого текстового корпуса. Они идут по порядку: абажур — первая строчка, Абакан — вторая, ящур — последняя. Столбцы — это те же самые слова, и они тоже идут по порядку. В ячейке на пересечении столбца и строки пишется число раз, которое слово из строки встретилось в корпусе рядом со словом из столбца.
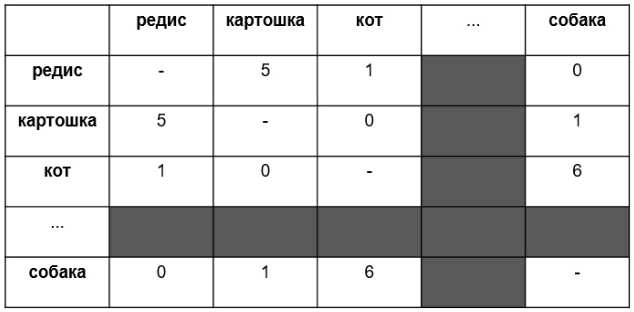
Вот и всё, семантические вектора готовы: ими станут строки нашей таблицы. Посмотрите: в примере строка редис кодирует информацию о том, что слово редис встретилось рядом с картошка 5 раз, в то же время встретилось рядом с кот лишь однажды, а с собака не встретилось вообще. Похожим образом ведёт себя и картошка: слово встречается рядом с названиями овощей часто, а с видами животных — редко. Так вот, если записать первую строку таблицы как (5; 1; 0), получится трехмерный вектор, в этом упрощённом примере он кодирует смысл слова редис. Если элементы векторов похожи, при их математическом сравнении окажется высока специальная мера схожести под названием «косинусная близость».
Если семантические векторы двух слов «косинусно близки» по отношению друг к другу, лингвист делает вывод: эти векторы принадлежат словам, близким по смыслу в человеческом понимании.
«Встретились рядом» — это где?
Итак, в ячейках таблицы пишем число раз, которое слово из столбца и слово из строки встретились в корпусе «рядом», то есть на расстоянии не более N слов. Это расстояние лингвисты называют «шириной окна» поиска, его настраивают вручную. Сейчас принято использовать N = 10. При обработке текст разбивается на отрывки из подряд идущих N слов (на N-граммы, подробнее о них можно узнать в нашей статье «Что такое N-граммы и с чем их едят?»), затем считается количество N-грамм, в пределах которых встретились два слова. Если два слова встретились внутри N-граммы, в ячейку на пересечении нужного столбца и строки добавляется единица. Можно сравнить N-грамму с мыльным пузырём, который движется через текст: если два слова попали в него одновременно — они «стоят рядом».

Для чего вообще все это нужно?
С многомерными векторами (то есть с векторами, состоящими из большого числа элементов) можно делать всё то же самое, что и с привычными двумерными — складывать их, вычитать, даже строить пропорции. Что самое интересное — при сложении векторов двух слов получается вектор третьего слова, и оно «суммирует» смыслы двух слагаемых в человеческом понимании, иногда неожиданно или даже поэтично. Если вычесть вектор слова король из вектора слова королева, получится абстрактное представление о роде, выраженное в числах. Теперь если эту разность прибавить к вектору слова лев, то получится, скорее всего, львица. Это может быть полезно при автоматическом анализе текста в поисковиках, чат-ботах и голосовых помощниках. А ведь компьютер просто складывает и вычитает числа, никакого представления о том, что такое род слова, в него не заложено!
А если рассчитать семантические векторы слов на примере двух одинаковых коллекций текстов на разных языках, векторы слова и его перевода будут похожи (если не одинаковы) — пригодится для создания онлайн-переводчика.
Посмотрите, что умеет «семантический калькулятор» с сайта RusVectores. Он основан на тех же принципах и умеет складывать и вычитать векторы, строить пропорции между ними. Что, например, так же относится к слову Италия, как Москва к России?

Но на практике пользуются не этой таблицей, а нейросетью. Почему?
Таблица получается слишком большой и заполненной нулями. Компьютерные лингвисты работают с объемными текстовыми коллекциями, и в них количество уникальных слов легко переваливает за сотни тысяч, а то и больше. Если использовать нашу таблицу, вектор каждого слова крупного корпуса состоял бы из ста тысяч элементов. Но что еще хуже — почти все элементы оказались бы нулями, потому что есть слова, которые вообще никогда не встречаются друг с другом в текстах. Знаменательные слова встречаются с небольшой, «своей» группой соседей, определяющей их смысл, в то время как служебные встречаются со всеми подряд.
Итак, получилась слишком большая таблица, состоящая в основном из нулей. Математики придумали много способов «сжать» ее, оставив только нужные сведения: к таким методам относятся, например, сингулярное векторное разложение и случайное индексирование.
Но зачем строить большую и непонятную таблицу, чтобы потом ее сокращать, если можно сразу придумать маленькую и удобную? Так и поступил ученый из Чехии Томаш Миколов, предложивший в 2013 две нейросетевые архитектуры: CBOW и Skip-Gram.

Как устроен Skip-Gram?
В машинном обучении есть такой трюк: можно изобрести задачу и натренировать нейросеть со скрытым слоем нейронов решать её, а потом просто не использовать нейросеть для решения этой задачи. Так поступает и Skip-Gram. Тренировка нейросети на самом деле нужна, чтобы запомнить веса нейронов, полученные в ходе обучения: в нашем случае веса как раз и станут семантическими векторами, которые мы пытаемся получить.
Если вы новичок в нейронных сетях и не понимаете, о чем речь — прочитайте наш пост на эту тему.
Фальшивая задача следующая: дано конкретное слово в середине предложения (входное слово). Алгоритм наугад выбирает одно слово из близких к входному и для каждого слова в словаре предсказывает вероятность того, что наугад выбрали именно его.
Предсказания показывают, насколько вероятно найти то или иное слово возле входного. Кстати, у слова «возле» здесь тоже есть конкретный смысл: это выбранная «ширина окна», или N-граммы.
Например, если обученной нейросети подать на вход слово котик, высокие вероятности на выходе будут присвоены словам пушистый, маленький, милый, более низкие — не связанным с котиками словам, например фламинго или ананас.
В каком виде нейросеть получает данные?
Нейронные сети не работают со словами в виде текстовых строк, они работают с числами. Чтобы обозначить каждое словарное слово уникальным номером, пользуются методом «one-hot encoding». Его суть проста: представьте, что в словаре 10 000 слов. Номер каждого слова будет состоять из 10 000 цифр, и все они будут нулями — кроме одной единицы. Единица будет стоять на месте, которое слово занимает в словаре по алфавиту. Третье по счету слово в словаре будет закодировано так: 00100(и еще 9995 нулей). Такое представление данных называется one-hot вектором.
А из чего вообще эта нейросеть состоит?
Вот ее архитектура:
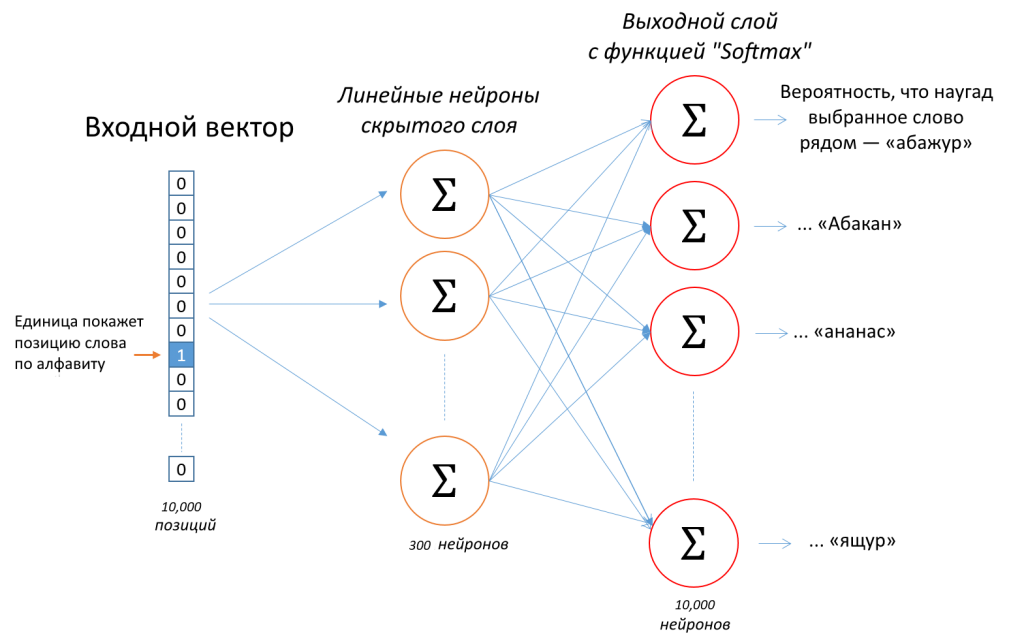
Входной one-hot вектор, кодирующий слово по положению в словаре, подается на скрытый слой нейросети, где превращается в другой вектор (как — расскажем далее). Новый вектор попадает на выходной слой и умножается на 10 000 наборов разных чисел (уникальный для каждого из 10 000 слов в словаре). Затем специальная функция Softmax превращает каждый получившийся набор в число между 0 и 1 — выходное число. Сумма 10 000 выходных чисел даёт единицу. Каждое из выходных чисел показывает, какова вероятность встретить слово данного выходного нейрона рядом с изначально заданным словом.
Теперь разберемся, что происходит на скрытом слое.
Скрытый слой нейросети
Задача: сформировать семантический (не one-hot!) вектор из фиксированного количества элементов, то есть чисел. Элементов обычно 300. Каждый элемент также называют признаком слова, которому вектор принадлежит. «Выучить признаки» — значит получить вектор.
Сразу же при подаче на вход нейросети one-hot вектор попадает на скрытый слой нейросети. Там он умножается на таблицу (матрицу) весов. Размеры таблицы — 300 (по числу нейронов) на 10 000 (по числу слов в словаре, их может быть больше).
Получение чисел в этой таблице на самом деле и является подлинной целью обучения нейросети. Ведь если посмотреть на ее строки, то как раз и получатся семантические векторы с фиксированным числом элементов. А выходной слой после тренировки нейросети мы отбросим.
One-hot encoding хорош тем, что умножение вектора в таком формате на матрицу — все равно что выбор конкретной строки.

Откуда нейросеть возьмёт числа на скрытом и выходном слое?
Это самая непростая часть, ради которой всё и затевалось. За неё отвечает процесс тренировки нейросети. Большая таблица 300×10 000, из которой мы потом станем брать готовые вектора, в самом начале заполнена случайными значениями.
Обучение выглядит так: N-грамма уже «прошлась» по тренировочному тексту и записала, что слово под номером 2 в словаре (это был абажур) встретилось рядом со словами номер 4581, 313 и 939. Все эти данные хранятся в виде one-hot векторов. Вектор «абажура» будем называть входным, а векторы его соседей — выходными. Входной и выходной вектора взаимосвязаны, вместе они образуют тренировочный пример для слова абажур. Тренировочных примеров — миллионы.
Суть процесса обучения — много раз заставить нейросеть предсказать, какие слова вероятнее всего встретить рядом с абажуром. Она много раз ошибется и каждый раз будет смотреть на то, какие вектора должны были получиться, то есть какие выходные вектора связаны с входным. В конце концов методом проб и ошибок алгоритм будет понемногу корректировать изначальные случайные значения и в итоге подберет те самые веса, на которые нужно умножать вектор абажура, чтобы получить вектора правильных слов. А потом придет человек, заберёт веса и скажет, что это — семантический вектор абажура.
Создатель нейросети вычисляет подходящую функцию потерь (штрафовать нейросеть за ошибочные предсказания — ее работа), обрабатывает не по одному слову за раз, а «комплектами» по 64 слова и применяет разные хитрые уловки вроде исключения самых частотных слов из обработки (негативное сэмплирование).
Мы сознательно опустили множество деталей, в том числе — не рассказали, как математически выглядит подбор нужных весов нейронов для правильного предсказания векторов (речь идет о «градиентном спуске»). Зато теперь вы знаете, как можно превратить слово в набор чисел, выразив ими его смысл.
Источники
- Как работает Word2Vec
- Что такое негативное сэмплирование
- Word2Vec: как работать с векторными представлениями слов
- Еще раз о том, как работает Word2Vec



