
Когда заходит речь о переносе стиля текстов, то на ум сразу приходит машинная поэзия. В статье мы расскажем о других возможных применениях методов машинного обучения, позволяющих менять стилистику текста без изменения его содержания, а также разберёмся, как эти методы работают.
(Анти)утопичное будущее и нейроцензура
Сгенерированные нейронной сетью песни, стилизованные под творчество Егора Летова, аккаунты Neural Meduza, Neural {вставьте имя любого медийного человека или СМИ} в Twitter’е могут показаться любопытными безобидными демонстрациями методов генерации и стилизации текстов. Однако эти методы могут приносить и практическую пользу.
В прошлом году ВКонтакте запустил тестирование двух функций: фильтрация оскорбительных комментариев в сообществах и предупреждение самих комментаторов о том, что их слова могут кого-то обидеть.
Сама по себе задача классификации эмоциональной тональности текстов не нова. Но что если ВКонтакте или любая другая социальная сеть решит пойти дальше? Не топорно удалять оскорбления или предлагать изменить реплику, а автоматически менять её тональность? Диаметральная смена окраски комментариев будет слишком грубым нарушением свободы слова, но можно обойтись полумерой: автоматически «сглаживать» высказывания: «Какой же автор тупой» превратится в более приемлемое «Автор показался мне глупым человеком», а обсценная лексика может заменяться нейроцензором различными эвфемизмами.
Подобную технологию может использовать не только крупная компания, но и, к примеру, недобросовестный предприниматель, который с помощью нейронных сетей делает из негативных отзывов положительные, притом степень положительности может настраиваться, чтобы клиент не заподозрил обмана.
Переводчик с канцелярита на русский
Приведённые выше примеры могут испугать, однако есть и положительные сценарии использования. Так, этой зимой сообщество во Вконтакте «Мемы про машинное обучение» и ОВД-Инфо анонсировали хакатон по анализу данных. Одной из предложенных организаторами тем был переводчик с канцелярита на понятный язык. Если бы существовал параллельный корпус текстов, то задача свелась бы к рядовой задаче машинного перевода. Однако собрать такую обучающую выборку сложно. Возможное решение — методы переноса стиля: берём непонятный официально-деловой текст и стилизуем его под тексты, написанные обычными людьми.
Всё — это небольшой набор чисел: векторные представления текстов
Прежде чем переходить к разбору методов переноса стиля с сохранением содержания, важно рассказать о векторных представлениях текстов. Ранее мы рассказывали о методе Word2Vec. Основная идея заключается в том, что благодаря нейронным сетям, мы можем представлять слова в виде компактных наборов чисел (векторов), которые хорошо сохраняют семантику слов: например, вектор слова «кот» более похож на вектор слова «лев», нежели чем на вектор слова «собака». Эта идея вполне естественно обобщается на тексты. Одним из способов векторизации текстов являются модели автокодировщики. Автокодировщик — это модель, которая состоит из двух частей: кодировщик и декодировщик.
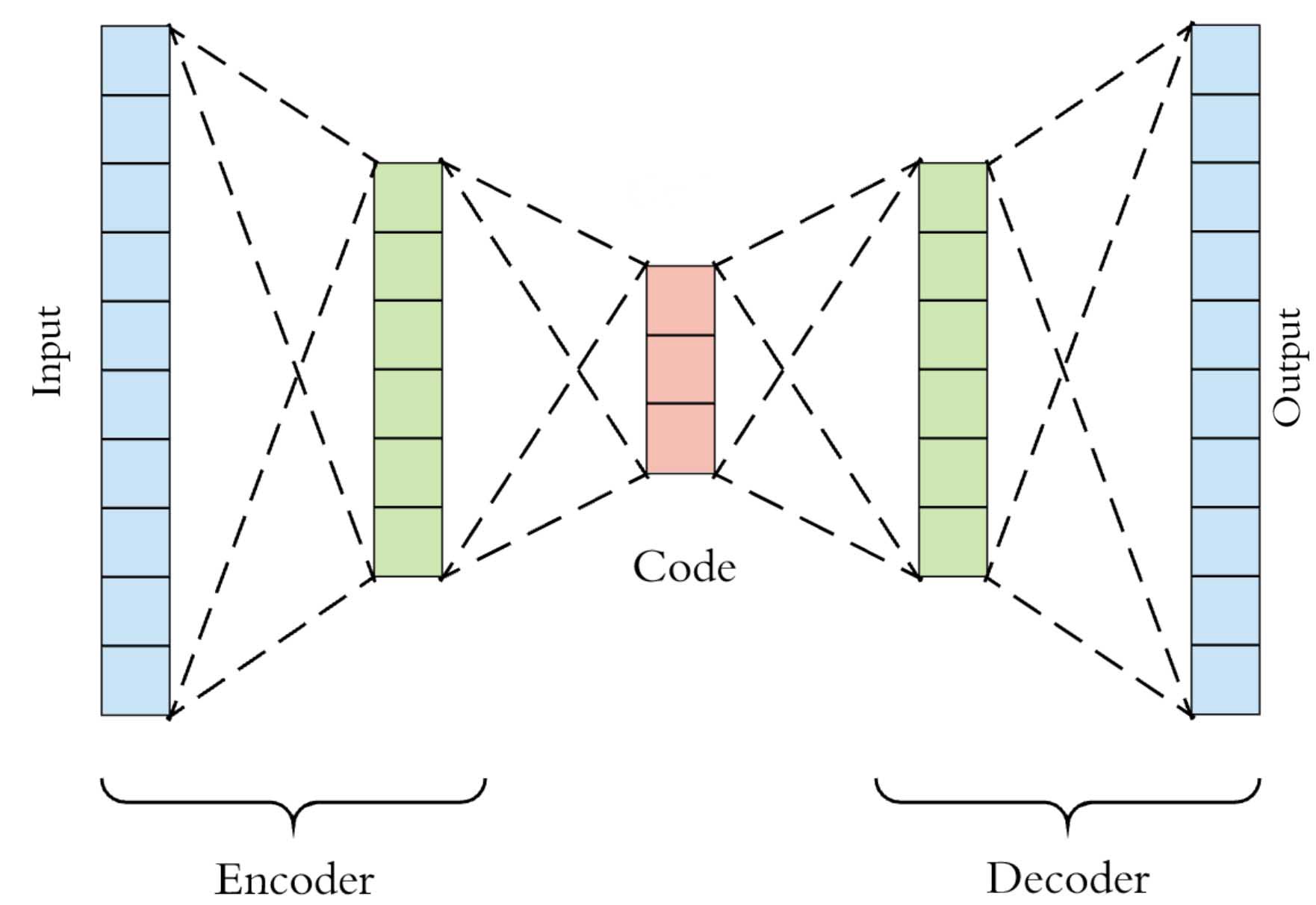
Задача автокодировщика — обучиться сжимать такие сложные данные, как текст, картинки или звук, в небольшой вектор. Он обучается следующим образом: кодировщик (может быть рекуррентной нейронной сетью или трансформером) представляет входные данные в виде вектора (в англоязычной литературе его часто называют «bottleneck»), затем декодировщик из полученного вектора пытается восстановить исходные данные. Во время обучения вся модель обучается таким образом, чтобы минимизировать различия между исходными данными и данными, восстановленными с помощью декодировщика. Из-за небольшого размера вектора модель попытается «засунуть» в него самое необходимое: представьте, что Вы пытаетесь уместить главу «Войны и Мира» в 512 чисел — придётся быть избирательным.
Переходим к переносу стиля: ещё больше нейронных сетей
Теперь, когда мы знаем, как компактно представлять тексты, можно перейти к самому интересному. Что у нас есть:
- Два корпуса текстов, каждый соответствует одному из двух стилей: положительный/отрицательный или токсичный/обычный и.т.д
- Автокодировщик, который можно обучить эффективно представлять тексты в виде векторов
Авторы статьи [1] предлагают следующий способ:
- Сначала обучить автокодировщик на обоих корпусах
- С помощью него получить векторные представления текстов стиля 1
- Немного изменить ранее полученные векторы, чтобы они были более похожи на векторы текстов стиля 2
- Подаем на вход декодировщику измененные векторы, на выходе получаем тексты стиля 2
Самое интересное — второй пункт, как изменить векторы так, чтобы на выходе получился текст нужного стиля? Давайте обучим ещё одну нейронную сеть! Возьмем векторные представления текстов для обоих корпусов и обучим нейронную сеть по ним определять стиль текста.
После того как сеть обучилась, будем пытаться её обмануть: ранее мы рассказывали, как именно это сделать. Рассмотрим простой пример:
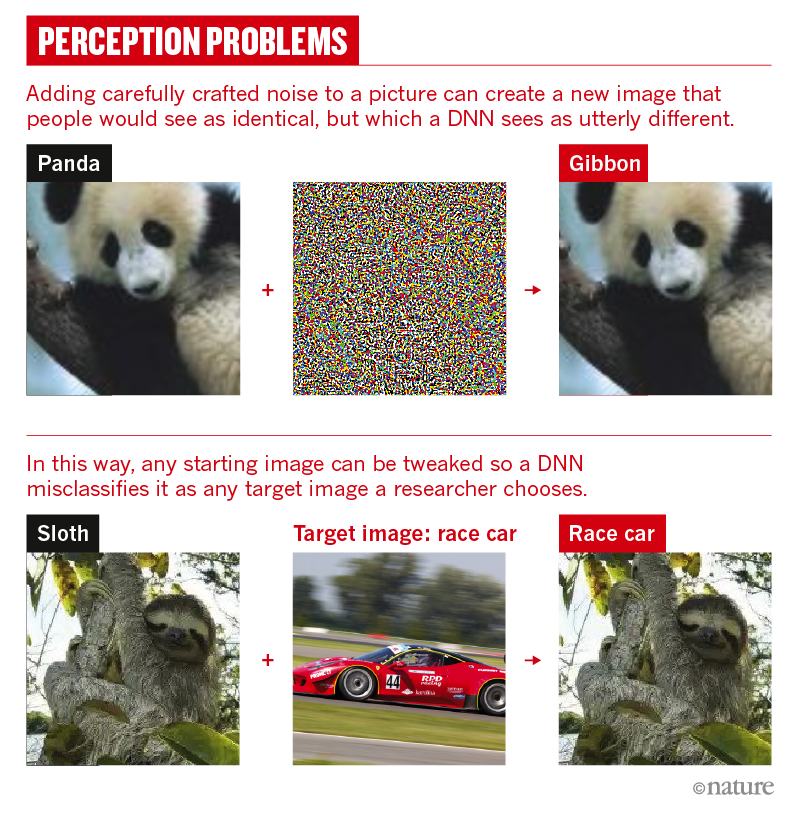
Есть фотография панды. К ней можно добавить специальный шум, из-за которого нейросеть распознает на фотографии гиббона.
Точно так же мы можем взять вектор текста стиля 1, добавить к нему шум и тем самым обмануть обученную нейросеть. Оказывается, что изменённый вектор тоже соответствует какому-то тексту. А поскольку шум мы подбирали таким образом, чтобы нейросеть перепутала стиль, то и на выходе мы получим текст нужного нам стиля.
Об этом можно думать так: векторные представления текстов образуют пространство текстов, по которому мы можем путешествовать. Размер нашего шага определяется степенью изменения (интенсивности шума) исходного вектора.
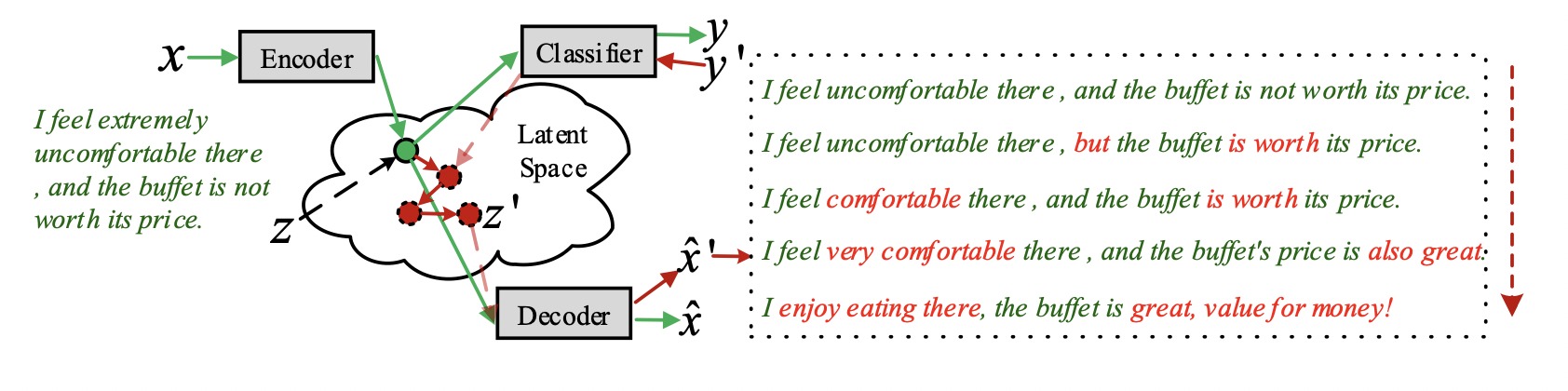
Справа на изображении выше можно видеть, как степень изменения исходного вектора влияет на конечный текст. Зеленый цвет обозначает исходные слова, красный — слова, которые появились за счёт «прогулки» в пространстве текстов.
Ещё примеры результатов:

В первой колонке — перевод позитивных отзывов в негативные. Во второй колонке — наоборот, сверху вниз растёт интенсивность изменения векторов исходных текстов.
Заключение
Мы рассказали об одном методе, который основан на изменении векторных представлений текстов. Однако существуют и другие методы, использующие эту идею. Например в статье [2] авторы предлагают обучать автокодировщик так, чтобы вся информация о стиле содержалась в одной части вектора, а информация о содержании — в другой. Такой подход даёт возможность менять не только стиль, но и содержание, причём независимо друг от друга. Однако при этом требуется не одна дополнительная нейросеть, а целых четыре.
Помимо стиля текста тем же способом можно менять и другие атрибуты текста. Например, пол автора или время действия. Главное — не заплутать во время путешествия.



