
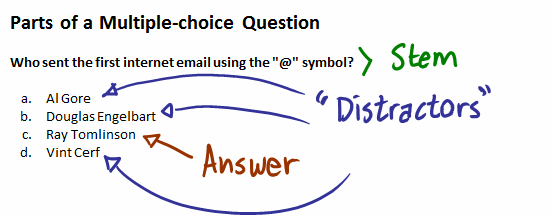
Вы наверняка сталкивались с тестовыми вопросами. Самый частый формат — четыре варианта ответа, из которых правильный — только один. При этом если неправильные варианты слишком неадекватны, вопрос не имеет смысла — ответ уже лежит на поверхности. В то же время если больше одного варианта может по некоторой логике быть правильным, тест становится несправедливым.
В англоязычной специальной литературе для неправильных вариантов ответа в тестах существует специальное название — дистракторы (distractors, букв. «отвлекатели»). Хороший подбор дистракторов является одной из наиболее важных задач при дизайне тестов.
На Западе, где стандартизированные тесты играют особенно большую роль в вертикальной социальной мобильности, профессия создателя тестовых материалов является одной из самых востребованных и высокооплачиваемых в сфере образования. Неудивительно, что последнее время появляются попытки её автоматизировать. Один из способов сделать это — автоматизировать генерацию дистракторов.
Как ищут ложные варианты-приманки
Один из определяющих факторов в задаче генерации дистракторов —их наличие или отсутствие в обучающей выборке. Проще говоря, есть ли у нас готовые хорошие примеры дистракторов, сделанные людьми. От этого зависит, будем ли мы решать задачу обучения с учителем (supervised learning) или обучения без учителя (unsupervised learning).
В случае обучения с учителем мы будем учиться ранжированию — то есть используемый алгоритм должен присваивать наиболее высокие ранги словам или предложениям, действительно являющимся дистракторами для данного вопроса (помеченным как дистракторы в тестовой выборке).
Получив на вход текст вопроса и текст «кандидата в дистракторы», классификатор должен «решить», насколько хорошо данный ответ может сойти за правильный в контексте данного вопроса, выдав определенную вероятность в виде числа. Подтверждением успешного обучения является получение настоящими дистракторами большего, чем у остальных кандидатов, рейтинга.
Задача порождения дистракторов сводится к а) подбору списка слов-кандидатов и б) обучению ранжированию. Вопросы нужного формата обычно собираются из оцифрованных копий учебников или интернет-ресурсов.
Найти дистракторы без учителя
В случаях, когда готовый пул вопросов нужного формата отсутствует, наступает время применения unsupervised-подхода. Такая ситуация возникает, когда сами вопросы генерируются из определенного корпуса текстов. Разумеется, в таком случае к ним нет готового обучающего набора отвлекающих неправильных ответов.
Пример такого варианта — gap-filling questions, то есть вопросы, получаемые заменой какого-либо слова или словосочетания в корпусном предложении на пропуск. Задача проходящего тест — догадаться, какая единица должна быть на месте пропуска.

Для языкового тестирования вопросы с пропуском на выбор правильного ответа можно получить, используя специальный корпус ошибок — так называют корпуса, содержащие тексты, написанные не-носителями определенного языка, которые содержат области, размеченные как ошибки, а также их исправления.
Как делают варианты с дистракторами на корпусе ошибок
В работе, о которой пойдет речь далее, используется корпус REALEC. Он содержит тексты на английском языке, написанные русскоязычными студентами в качестве письменных заданий-эссе.
В системе LangExBank (см. репозиторий) каждый тестовый вопрос — предложение корпуса REALEC, в котором область ошибки заменена на пропуск. Таким образом, правильный ответ и один неправильный ответ в исходных данных уже есть — это исправление и оригинальная область ошибки. Теперь задача состоит в том, чтобы получить ещё 2-3 неправильных варианта.
В LangExBank реализована генерация дистракторов из вопросов, полученных на основе лексических ошибок и ошибок на употребление предлогов. Для подбора дистракторов используется классификатор в виде рекуррентной нейронной сети. Нейросеть должна заполнить пропуск, но в обучение модели внесена такая принципиальная поправка: если модель предсказывала правильный вариант (т.е. слово-исправление), штраф для неё увеличивался в 2 раза.
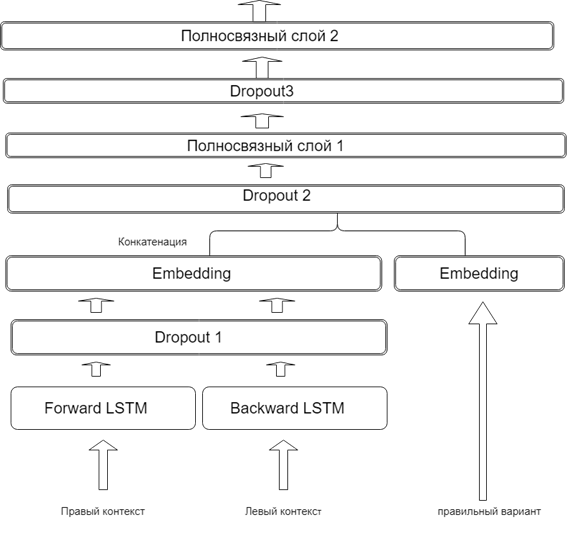
Нейросеть, построенная по схеме выше, обучается угадывать слово в оригинальной области ошибки на основе правого и левого контекстов ошибки, а также ее исправления. При этом правый контекст проходит через рекуррентный слой в прямом направлении, а левый — в обратном.
Полученные на выходе рекуррентного слоя векторы «склеиваются» друг с другом и вектором слова в исправлении. В качестве дистракторов используются топ-3 предсказаний модели, не равных слову в области ошибки и слову-исправлению.
Так как в датасете изначально не содержатся дистракторы, качество сгенерированных вариантов можно проверить только вручную. Наиболее адекватный результат показывает модель для предлогов, но все же результаты пока далеки от совершенства — почти в каждый набор попадает как минимум один «слишком неправильный» или «слишком правильный» на наш человеческий взгляд вариант.
Примеры работы нейросети


Но есть и хорошие примеры:

Что дальше?
Используемый в системе LangExBank сейчас подход не идеален, однако позволяет добиться некоторых результатов в нетривиальной задаче. Возможное улучшение — использование для генерации дистракторов не рекуррентного классификатора, а генеративной рекомендательной сети, как в работе (Liang et al. 2017). Однако, здесь возникает другая проблема — варианты, которые смогут «обмануть» дискриминатор, могут оказаться «слишком правильными».
В целом, основной проблемой для генерации дистракторов в сфере языкового тестирования является именно принципиальное отсутствие для каждого контекста единственно возможного варианта заполнения — языки устроены так, что в них почти не существует валентностей, которые могут заполняться одной и только одной единицей.
Несмотря на описанные проблемы, используемый в LangExBank механизм генерации лексических дистракторов должен помочь преподавателем в формировании тестовых материалов — его выдачу сейчас стоит скорее стоит воспринимать как рекомендацию. Поэтому платформа поддерживает редактирование полученных из корпуса тестов. В будущем планируется добавление моделей порождения дистракторов и для других типов ошибок.
Источники
- Логин Н. В. Платформа для оценки знаний английского языка с использованием корпусного материала: дипломная работа на соискание степени бакалавра. НИУ ВШЭ, Москва, 2020
- Репозиторий с исходным кодом тестовой платформы LangExBank
- Heaton 1988 – J. B. Heaton. Writing English language tests. London: Longman, 1988.
- Liang et al. 2017 – C. Liang, X. Yang, D. Wham, B. Pursel, R. Passonneaur, & C. Giles. Distractor Generation with Generative Adversarial Nets for Automatically Creating Fill-in-the-blank Questions. // K-CAP 2017: Proceedings of the Knowledge Capture Conference, 33, 2017. P. 1-4.
- Welbl et al. 2017 – J. Welbl, N. Liu, M. Gardner. Crowdsourcing Multiple Choice Science Questions. arXiv:1707.06209. 2017. Дата обращения: 30.05.2010.

