Написание текста песни под уже готовую музыку — сложная задача. Необходимо учитывать тоновые и ритмические свойства мелодии: размер такта, высоту нот, наличие пауз. Длинное слово в песне, приходящееся на паузу в музыке, будет звучать ненатурально.
Недавно группа японских ученых предложила подход, позволяющий автоматически порождать тексты песен с учетом свойств мелодии. Система работает на основе рекуррентной нейросети, которая обучалась на коллекции выравненных пар «мелодия — текст».

Обученная нейросеть получает на вход мелодию — и сама определяет, в каких местах должны заканчиваться стихотворные строки и строфы, где лучше прервать предложение или поставить слово покороче.
В итоге получаются тексты, которые выглядят натурально для человека, который одновременно слушает музыку и читает слова. Системы, которые существовали раньше, так не умели — они либо вообще не учитывали свойства мелодии, либо требовали, чтобы все было введено вручную и после этого генерировали тексты по ритмическим шаблонам. В обоих случаях результат получался хуже.
Гармония текста и мелодии
Первым делом авторы исследования подготовили данные для обучения. Они собрали на музыкальных сайтах и форумах 1000 нотных партитур — и выравняли ноты с текстами. Для решения задачи авторам требовалось не только связать отдельные слоги с конкретными нотами — нужно было еще и разметить базовую дискурсивную структуру текста: деление на слова, предложения, стихотворные строфы. Это было сделано при помощи инструментов компьютерной лингвистики (морфологический анализатор для японского, автоматический определитель произношения иероглифов) и алгоритма Нидлмана — Вунша, который обычно используют в биоинформатике для выравнивания аминокислотных последовательностей.

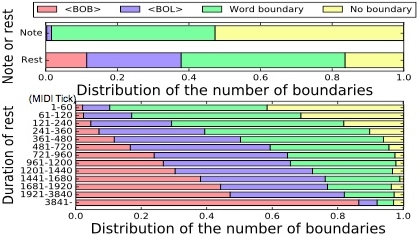
Исследовав полученные данные статистически, авторы уже получили интересные закономерности. Например, чем длиннее в пауза, тем меньше вероятность, что на нее приходится слог какого-то слова. Даже короткие паузы чаще всего совпадают с границами слов, а не с их серединой. Пауза большой продолжительности — почти всегда граница строфы. Раньше связь пауз в мелодии и границ слов/строк/строф оставалась на уровне интуиции, теперь для этого есть еще одно статистическое подтверждение.
Как училась нейросеть?
Далее на собранных данных обучали рекуррентную нейросеть. Задача нейросети — порождать слова песен для новых мелодий, учитывая взаимосвязь музыки и текста. Модель обрабатывает мелодию, представленную в виде последовательности (т.е. вектора) нот и пауз, и выдает цепочку слов, разбитую на строки и строфы. На каждом отдельном шаге нейросеть порождает одно отдельное слово (или границу строк/строф).
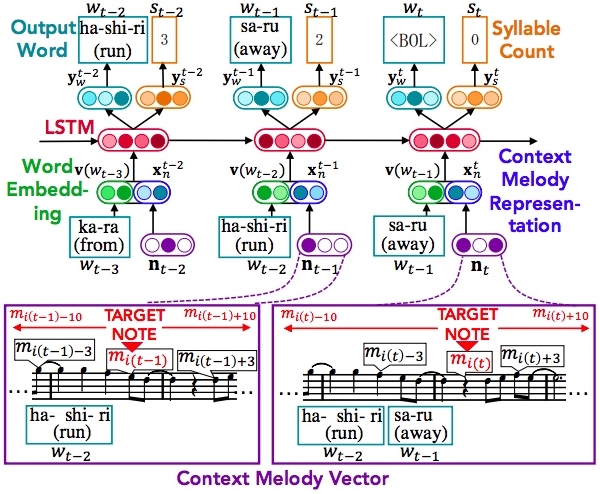
Входными данными каждого шага служат предыдущее порожденное слово и параметры мелодии в этом месте — свойства нот или пауз, которые идут до и после (10 слева и 10 справа). Модель сначала предсказывает число слогов в новом слове, а затем подбирает само слово. Порождение текста прекращается, когда количество слогов во всех порожденных словах сравнивается с количеством нот в мелодии.
Маленькая хитрость
Для обучения нейросетей нужно много данных. Поэтому авторы придумали и попробовали две стратегии обучения, которые позволяют не ограничиваться размеченной тысячей пар «текст-мелодия».
- Первый вариант (самый простой) — обучить модель на большом количестве текстов без мелодий, а затем до-обучить на размеченной тысяче. Авторы статьи взяли 53,181 текстов песен и подали их на вход своей нейросети вместе с пустыми (нулевыми) векторами мелодий. Далее была подана 1000 песен с ненулевыми мелодиями.
- Второй вариант (более сложный и — СПОЙЛЕР — давший самые лучшие результаты) — сгенерировать для текстов псевдо-мелодии. На основе 1000 размеченных текстов уже добыта информация о том, как распределяются по нотам слова, границы строк и строф. С ее использованием была построена вероятностная модель порождения псевдо-мелодии для текста. Она создала мелодии для тех же 53,181 текстов, которые использовались в первом варианте. Теперь нейросеть обучали уже не на обнуленных мелодиях, а на псевдо-нотах, порожденных моделью.
Как оценивали нейросеть?
Авторы исследования очень ответственно подошли к оценке результата и провели целую батарею тестов.
- Во-первых, они измерили перплексию (perplexity) порожденных песен — это стандартная мера из теории информации, которая оценивает «предсказуемость» каждого следующего слова в тексте. С помощью перплексии часто оценивают, насколько читаемым получился текст, порожденный машиной.
- Во-вторых, авторы породили тексты для размеченной тысячи мелодий, для которых уже есть слова. Используя стандартные метрики точности, полноты и F-меры, исследователи оценили, насколько совпадают музыкальные и текстовые границы в порожденных текстах — с границами в настоящих словах этих песен. Дополнительно авторы попросили живого человека — не профессионального музыканта, но опытного исполнителя с музыкальным образованием — расставить границы слов, строк и строф в 10 случайных мелодиях. Его результат сравнивался с тем, что получилось у нейросетевой модели.
- В-третьих, для оценки результатов применили краудсорсинг. 50 краудсорсеров слушали музыку, читали сгенерированные для этой музыки тексты и выставляли оценки от 1 до 5 по нескольким параметрам:
- «Слушабельность» (Listenability). Естественно ли звучит текст, нормально ли воспринимаются на слух границы слов и строк в тех местах, где они оказались?
- Грамматичность (Grammaticality). Насколько грамматически правильным получился текст?
- Осмысленность строк (Line-level meaning). Насколько осмысленно выглядят отдельные строки песни
- Осмысленность текста (Document-level meaning). Насколько осмысленно выглядит весь текст.
- Общее качество текст песни (Overall quality).
А еще тексты под те же мелодии попросили написать нескольких профессиональных авторов. Их творения тоже оценивались — и краудсорсеры не знали, является ли автором песни человек или машина.
По итогам всех оценок самый лучший (и самый близкий к человеческому) результат продемонстрировала модель, обученная на псевдо-мелодиях. Стратегия, когда на основе небольшого количества размеченных нот порождаются псевдо-данные гораздо большего объема и на них производится обучение, оказалась наиболее успешной.
Источник: A Melody-conditioned Lyrics Language Model