С наступлением эры нейросетей СМИ любят писать, что машинный перевод вот-вот сравнится по качеству с продуктом профессионального переводчика. «Искусственный интеллект в машинном переводе догоняет человека», уверяют заголовки уважаемых технологических медиа. Но так ли это?
Искусственные нейронные сети, обученные на больших данных, действительно повысили качество машинного перевода настолько, что это видно невооруженным взглядом. Если поискать в интернете скриншоты с курьезами Google-переводчика и протестировать их сегодня, разница налицо.
Было:
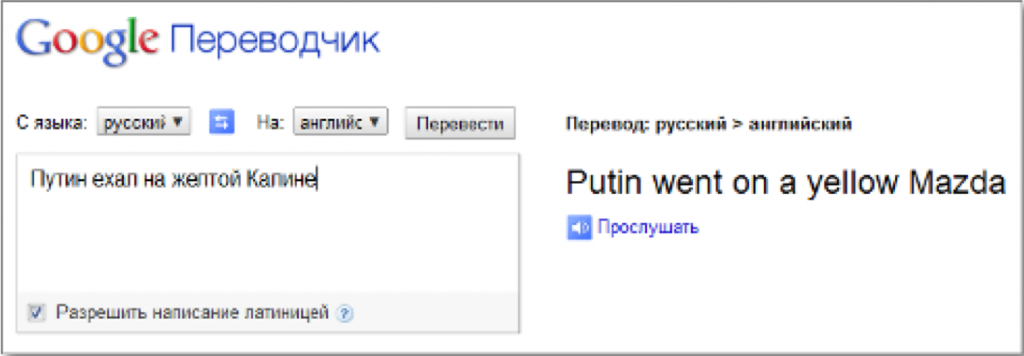
Стало:
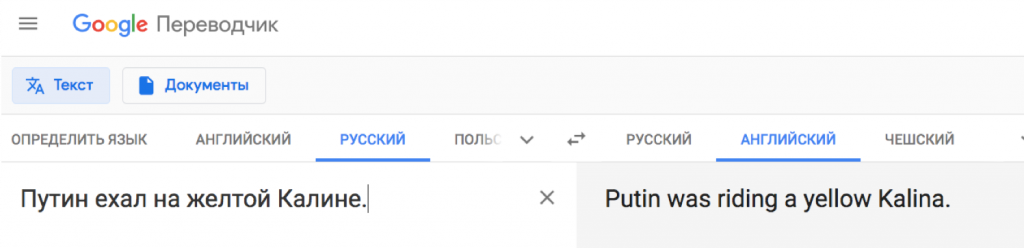
Как работает машинный перевод?
Подробно об истории и устройстве машинного перевода «Системный Блокъ» рассказывал здесь. Сейчас важно вспомнить несколько ключевых фактов и идей:
- С начала 2000-х и до 2015-2016 гг. в массовых переводчиках вроде Google Translate использовался статистический машинный перевод по фразам (phrase-based).
- Статистический переводчик рубил текст на слова и цепочки слов, после чего использовал статистику переводов фраз с языка на язык. Несмотря на огромное количество дополнительных ухищрений, это был негибкий подход, который порождал огромное количество ошибок и курьезов.
- С приходом нейросетей машинные переводчики перешли на них. Нейросеть тоже обучается на готовых переводах, но делает это гораздо гибче. Ей не нужно заранее выделять в тексте фиксированные фразы: нейросетевые алгоритмы сами постепенно выучивают на больших объемах данных оптимальные разбиения текста на части и запоминают закономерности перевода. Благодаря этому и подскочило качество работы машинных переводчиков.
Однако действительно ли нейронный машинный перевод (НМП) приближается к человеческому? Ответ однозначный: вовсе нет! Пока что системы машинного перевода несопоставимы с мозгом переводчика-человека. Они допускают ошибки, которых человек никогда бы не допустил — и которые свидетельствуют о том, что разговоры об «искусственном интеллекте» преждевременны.
Что не так с нейронным машинным переводом?
НМП имеет множество недостатков, которые совсем не похожи на проблемы человеческих переводов. Недостатки нейронных переводчиков можно поделить на 3 категории: достоверность, память и здравый смысл.
- Достоверность: Вероятно, наибольшее беспокойство вызывает то, что НМП может оказаться недостоверным, вызывающе ошибочным и совершенно непонятным. Системы НМП не гарантируют точность перевода и часто пропускают отрицания, отдельные слова или целые фразы.
- Память: Для системы НМП также характерна потеря кратковременной памяти. Системы заточены на перевод одного предложения. В результате они забывают информацию, полученную из предыдущих предложений. Получается хуже, чем развлечение, принятое на вечеринках, в котором каждый участник пишет следующую строчку истории, видя при этом только предыдущую.
- Здравый смысл: Системы НМП не обладают здравым смыслом в человеческом понимании — то есть внешним контекстом и знаниями о мире. Умение различать, какие контексты подходят для определенных переводов, важно для нашего понимания ситуаций, но эти контексты часто трудно охватить полностью.
Расскажем об этих недостатках подробнее.
Достоверность: нейросеть, да ты гонишь!
Системы НМП не вооружены методами определения достоверности фактов в тексте перевода. Хуже того, такая недостоверность непредсказуема и непоследовательна, что затрудняет ее автоматическое выявление и исправление. Например, системы НМП могут путать отрицания и опускать целые отрывки информации. Каковы последствия таких ошибок?
В сообщении Дэна говорится:
«Конечно, я правда люблю тебя. Поужинаем в эту пятницу? Увидимся!»
Но машинный перевод его подвел, потому что выдал:
«Конечно, я не люблю тебя. Пока!»
Весьма душераздирающая ошибка! Безусловно неприятная, но не непоправимая…
А вот нейросеть разворачивает важнейшую строчку в знаменитом стихотворении Пушкина на 180 градусов: дай бог превращается в god forbid, т.е. не дай бог.
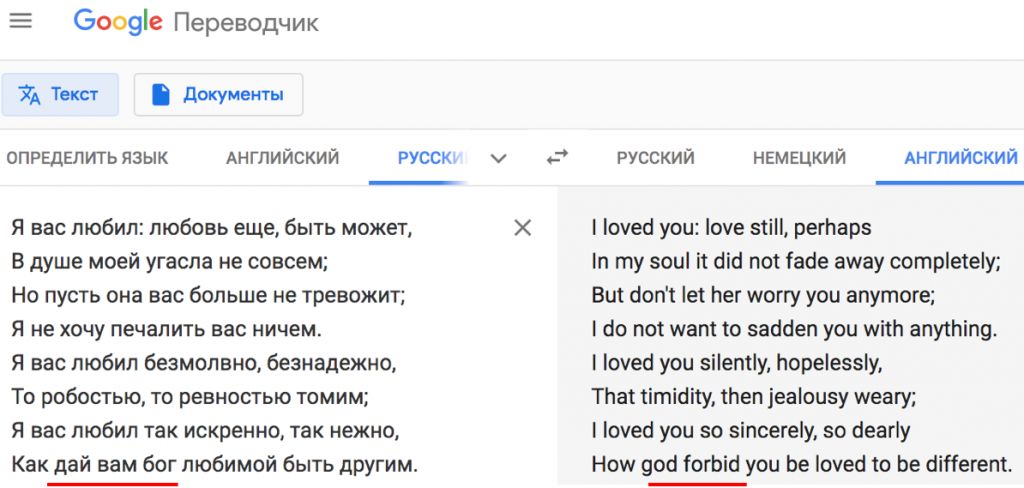
Тоже грустно. Но, кажется, не опасно. Однако бывает и опаснее:
«США не нападали на ЕС! Бояться нечего,» — написала по-французски авторитетная газета Le Monde. Но воспользовавшись нейросетевым переводчиком, англоговорящие страны поняли бы это так:
«США напали на ЕС! Ничего не боятся».
Представьте, что этот неправильный перевод распространяется по всему Интернету. Разлетятся ли фальшивые новости, прежде чем их успеют исправить? Это больше, чем просто неприятность — это может стать катастрофой.
К сожалению, «гладкость» (которая является основным преимуществом НМП) может усугубить проблему, придавая неточным переводам более правдоподобный характер и вместе с тем осложняя ее выявление.
Одним из главных препятствий на пути широкого внедрения НМП является отсутствие доверия к такой системе. Почему эти системы неточны? Давайте подробно рассмотрим две основные причины и их признаки.
Проблема достоверности № 1: Искаженные данные, искаженные переводы
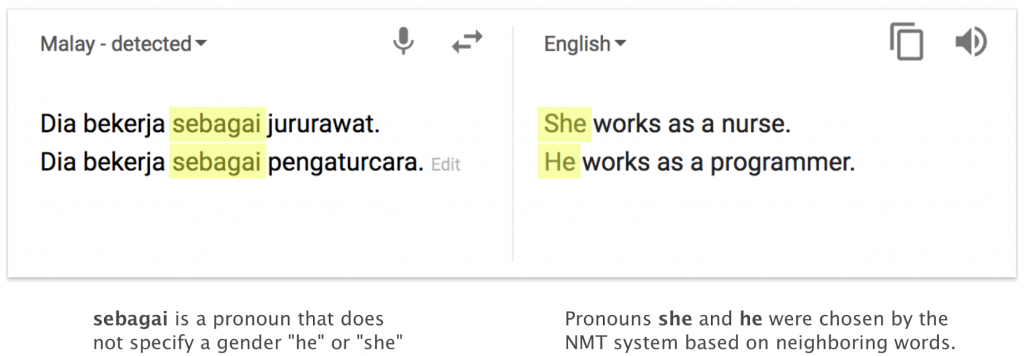
Хотя первоначальный малайский текст не содержал никакой гендерной информации, в переводе на английский язык предполагается, что медсестра-женщина, а программист-мужчина. Система НМТ предположила такой вариант, поскольку в данных для машинного обучения было больше примеров медсестер-женщин и больше примеров программистов-мужчин.
Это явление — неблагоприятное побочное последствие того, как обучаются нейронные сети. Используя данные реального мира (такие, как гендерные соотношения в профессии среднего медицинского персонала и программировании), система НМТ вводит необоснованную информацию в свои переводы. Этот пример особенно показателен, поскольку система перевода усугубляет существующее в мире неравенство. Тем не менее такого рода ошибки могут возникать всякий раз, когда система запоминает тенденцию в данных для обучения и может неправильно использовать этот шаблон при переводе. Например, если ваши данные для обучения были собраны в 2013 году, и в них встречается много примеров «президент США Обама» и нет ни одного примера «президент США Трамп», крайне маловероятно, что ваша система НМП использует вариант «президент США Трамп» — она легко сменит «Трампа» на «Обаму».
Проблема достоверности № 2: Попробуйте что-то новое и получите чепуху.
Системы НМП иногда выдают абсурдные вещи. И нам не совсем понятна логика этого безумного абсурда. Вот пример:
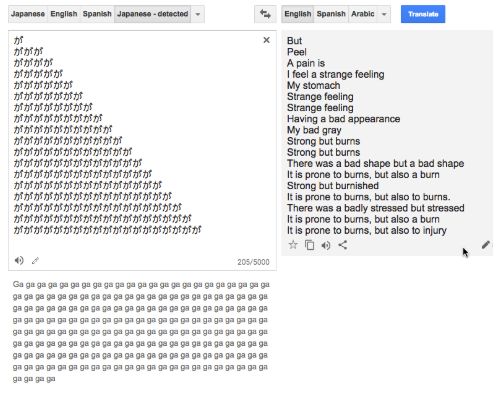
Разное число повторений этого знака японского алфавита выдает совершенно случайные фразы.
Причина в том, что такие цепочки символов не встречаются в данных, на которых обучалась система. В результате в этом примере английская система генерации текста автоматически генерирует фразы, которые звучат «гладко» на английском языке, но имеют мало сходства с японским исходным текстом.
В целом системы НМП плохо работают при переводе исходных текстов, которые сильно отличаются от данных, использованных для машинного обучения. Такое явление ограничивает их способность распространяться на новые области и новые стили формулировки. Нейросети порождают языкоподобную чушь, когда сталкиваются с чем-то новым.
Память
Системы НМП имеют еще один заметный дефект: они сильно заточены на перевод отдельных предложений. Нейросети в современных переводчиках плохо помнят, что было до того предложения, которое они переводят.
Рассмотрим пример искаженного местоимения для слов «медсестра» и «программист». В них предложения исходного текста были представлены без фоновой информации о поле медсестры и программиста. Это привело к тому, что система НМП неправильно поняла гендерные местоимения, чрезмерно полагаясь на статистические модели, которые она видела в данных для машинного обучения. Но что, если бы система НМП имела доступ и к другим близстоящим предложениям? Например, если в предыдущем предложении упоминалось, что программист — женщина, правильно ли система НМП выберет местоимение?
К сожалению, нет. Система не может использовать правильные местоимения, даже если в предыдущем предложении говорится, что программист — женщина!
Почему системы НМП обучаются переводить по одному предложению, а не весь документ сразу? Причины технические. Во-первых, нейронной системе трудно читать длинный документ, компактно хранить всю эту информацию и эффективно ее запоминать. Во-вторых, этим системах нужно больше времени при большом объеме исходных данных.
Неспособность использовать более широкий контекст является основным препятствием для успеха НМП. Почти любой перевод требует понимания нескольких предложений, но в некоторых случаях, таких как перевод истории, это имеет решающее значение. Рассказывание историй — такая же человеческая деятельность, как и любая другая, требующая сочетание творчества, интеллекта и коммуникативных навыков, которые отличают нас от животных. Если системы перевода ИИ не могут переводить текст связно, не говоря уже о том, чтобы делать это красиво, то можем ли мы действительно сказать, что они обладают человеческим уровнем перевода?
Здравый смысл
Системы НМП не обладают здравым смыслом: знаниями или контекстом о мире, которые помогли бы помочь правильно перевести текст.
Предположим, вы читаете статью о музыкальном концерте и отправляете французский перевод (выполненный системой НМП) своим франкоязычным друзьям. В английской версии в статье есть интервью различных концертмейстеров, в том числе одного молодого человека, который восклицает,
«Я большой поклонник металла!»
Однако в переводе, это предложение становится таким:
«Je suis un énorme ventilateur en métal» («Я огромный вентилятор из металла».)
Система не знает, что в этом контексте «metal fan» — это человек, который является поклонником музыкального жанра «металл», который более уместен, чем вентиляционный блок, сделанный из металла.
Эта проблема относится к самым истокам МП. Мы можем найти другой пример в очень влиятельной статье Йегошуа Бар-Хиллела 1958 года «Демонстрация невыполнимости полностью автоматического высококачественного перевода»:
Коробка в ручке.
Здесь систему НМП вводят в заблуждение тем, как же перевести «pen»: как письменную принадлежность или как некоторое пространство?
Для эффективного перевода системе НМП необходимы общие знания о мире. Однако эти знания трудно кодировать в полном объеме и нелегко извлечь из объемов данных. Нам нужны механизмы для включения здравого смысла и знаний о мире в нейронные сети.
Какой перевод можно назвать хорошим? Сложность оценки систем НМП
Как мы оцениваем качество системы машинного перевода? В настоящее время наиболее распространенным способом является использование оценки BLEU. Чтобы вычислить оценку по алгоритму оценки качества текста BLEU, мы берем переводы, произведенные системой MП, и сравниваем их с предложениями, переведенными людьми. Если перевод, написанный машиной содержат много слов и фраз, общих с переводами, выполненными людьми, то система получает более высокий балл BLEU.
Оценка BLEU является полезной жесткой мерой качества перевода, особенно для систем с низкой производительностью. Однако исследователи обнаружили, что оценка BLEU часто не сходится с оценками людей по качеству перевода. Это означает, что хотя показатель BLEU и может помочь нам определить, какая из систем лучше всего работает, обычно этого недостаточно для честной оценки самых эффективных систем.
Просить людей оценивать перевод напрямую — лучше, чем использовать BLEU. Но несмотря у оценивания качества МП человеком тоже есть недостатки.
Человеческая оценка не является автоматической, и поэтому она дорогостоящая и медленная — требует времени и знаний. Почти все исследования машинного перевода используют автоматические метрики, такие как BLEU, вместо более точной оценки человеком.
Человеческая оценка не всегда последовательна. Трудно добиться согласия между специалистами по оценке, особенно если они не являются двуязычными переводчиками, а просто сравнивают предложения на своем родном языке.
Двигаясь вперед, важно быть в курсе ограничений оценок НМП, сравнивая эту систему с переводчиками-людьми.
Мы работаем над этим… Как выглядит будущее?
НМП стремительно развивается и прогрессирует каждый месяц. Разработчики начинают осознавать проблемы, изложенные выше: достоверность, искажение данных, отсутствие смысла в полученном тексте перевода, память, здравый смысл и метрики оценок. Например, Google призвал исследователей к борьбе с искажениями фактов в НМП, выпустив новый набор метрик оценки специально для решения этой проблемы.
В течение прошлого года НМП также достиг заметных улучшений в эффективности и производительности. Это связано с внедрением новых систем, которым больше не требуется последовательно обрабатывать данные, например, слева направо или справа налево. Эти системы обрабатывают исходные предложения за раз, что позволяет легко находить соответствия в данных для машинного обучения. Таким образом, мы можем обучиться на большему объему данных за то же время и, в конечном итоге, выполнять более эффективные переводы. Среди таких успешных систем можно выделить Google Transformer и нейронные сети Salesforce’s Quasi-Recurrent.
Между тем, можно ожидать ускорение распространения новых исследований. Гарвардский OpenNMT — реализация нейронного машинного перевода с открытым исходным кодом в LuaTorch, PyTorch и Tensorflow — быстро объединяет новые методы исследований, и теперь другие легко могут брать за основу лучшие системы. Многие утверждают, что новая коммерческая система deepL, основанная бывшим исследователем Google, обходит по качеству Google Переводчика. Microsoft Переводчик продолжает предлагать новые функции в своей многоязычной поддержке предприятия. Машинный перевод развивается стремительно, и от наблюдения за его эволюцией сложно оторваться.
Подробнее узнать о том, как оценить качество машинного перевода с помощью метрики BLEU, можно тут.
Источник: SHARON ZHOU, Has AI surpassed humans at translation? Not even close!
Материал подготовлен совместно с группой переводческих компаний AKM Translations (www.akmw.ru)

