
Создатели диалоговых систем работают над гуманизацией компьютерных технологий, чтобы отвечать интересам пользователей. Сотрудники Google разработали чат-бота Meena, который способен общаться на любые темы. Компания утверждает, что это наиболее «человечный» искусственный интеллект из существующих.
Meena — комплексная нейронная диалоговая модель, которая разумно реагирует на контекст разговора и пытается минимизировать перплексию (perplexity) — неопределенность в прогнозировании следующего слова. Цикл обработки запросов выглядит примерно так: бот получает запрос пользователя, далее из базы данных загружается контекст диалога, затем, исходя из этой информации определяется наиболее соответствующий желаниям человека ответ, по итогу диалог сохраняется для того, чтобы ИИ проще справлялся с последующими требованиями.
А что под капотом у Meena?
Meena отличается от других моделей тем, что имеет 2,6 миллиардов параметров и была обучена на 341 гб текста из социальных сетей. В работе Meena используется один блок энкодера и 13 декодеров Evolved Transformer.
Evolved Transformer — это архитектура нейронной сети для понимания естественного языка, представитель семейства нейросетей-трансформеров. Трансформеры требуют меньше вычислений в обучении и лучше подходят для современной техники. Энкодер отвечает за обработку контекста диалога, а декодер использует полученную информацию для формирования ответа. Специалисты Google обнаружили, что улучшение декодера помогает вывести разговор на более высокий уровень.
Как оценивают чатбота
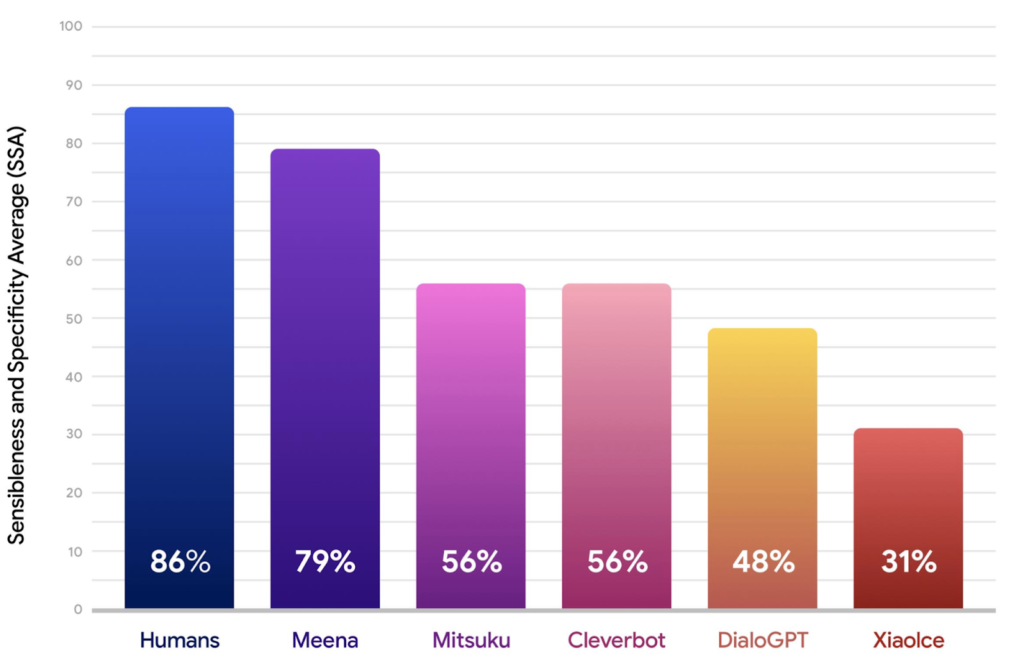
Также совершенствовать бот помогает система Sensibleness and Specificity Average — это метрика, с помощью тестировщик дает оценку, насколько разговор разумен и естественен, а также определяет, насколько конкретный ответ дала Meena. Значение человека в такой метрике равно 86%, показатель Meena — 79%. Другие боты, например, такие как Mitsuku и Cleverbot, набирают всего 56%.
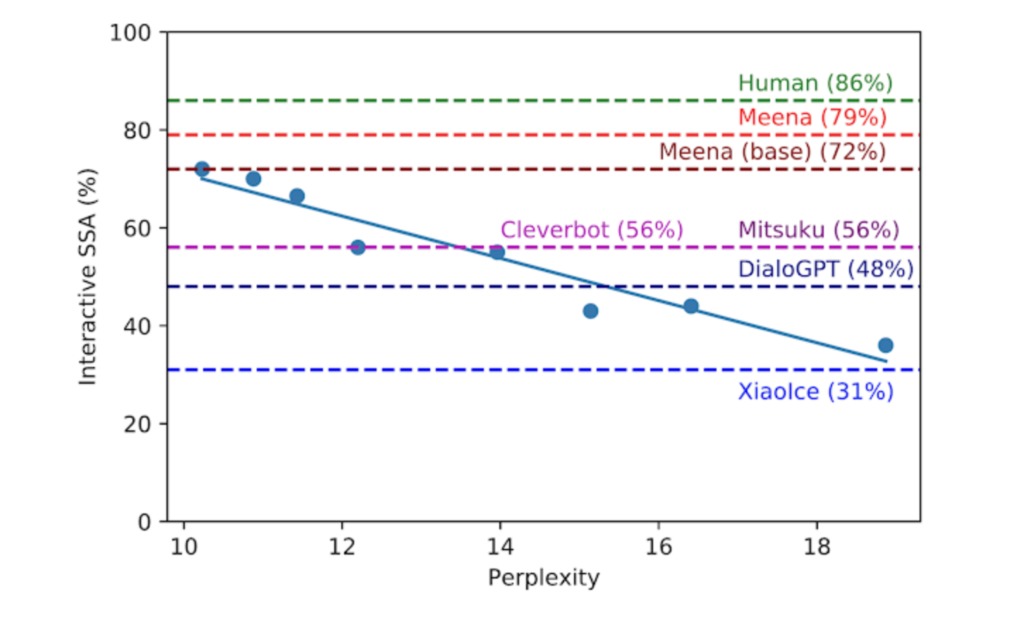
Инженеры пытаются создать метрику, которая будет автоматически оценивать ответы бота и проверять его — это ускорило бы разработку чат-бота, но на данный момент это сложная задача. Исследователи обнаружили, что недоумение — это автоматическая метрика, которая легко доступна любому нейрону seq2seq. Модель демонстрирует сильную корреляцию с человеческой оценкой. Недоумение измеряет неопределенность языковой модели. Чем меньше недоумение, тем более уверенно модель генерирует следующий символ или слово.
В процессе разработки протестировали восемь моделей с различными гиперпараметрами и архитектурами, такими как количество слоев, внимание, общее количество шагов обучения, используется Evolved Transformer или обычный Transformer. Как показано на рисунке ниже, чем меньше недоумение, тем лучше оценка SSA для модели с сильным коэффициентом корреляции.
Разговоры, которые используются для обучения бота представляют дерево смыслов, где каждый ответ рассматривается как ветка — один из возможных ходов диалога. Инженеры Google считают семь ветвей хорошим балансом в условиях ограниченной памяти.
А что дальше?
Google пытается упростить нейронные диалоговые модели с помощью улучшения алгоритмов, архитектуры сетей и вычислений. Программисты хоть и сосредоточились на осмысленности ответов бота, но считают, что «личность» модели и соответствие её ответов фактам заслуживают внимания в последующих разработках.
Есть и проблема безопасности и предвзятости чат-бота, поэтому демонстрационная модель пока недоступна для пользователей. Однако специалисты оценивают риски и выгоду и считают, что предоставление демо-версии чат-бота пользователям поможет в исследованиях.
Источник: Daniel Adiwardana et al (2020) Towards a Conversational Agent that Can Chat About…Anything

