
Intro
Для исследования мы использовали корпус научно-популярных текстов, собранный студентами магистратуры Школы лингвистики НИУ ВШЭ под руководством Б.В. Орехова. [1] Создатели корпуса написали краулер, который скачал некоторое количество статей со следующих ресурсов:
- ПостНаука,
- N+1,
- GeekTimes,
- Polit.ru (разделы Лекции и Pro Science),
- Чердак,
- Индикатор.
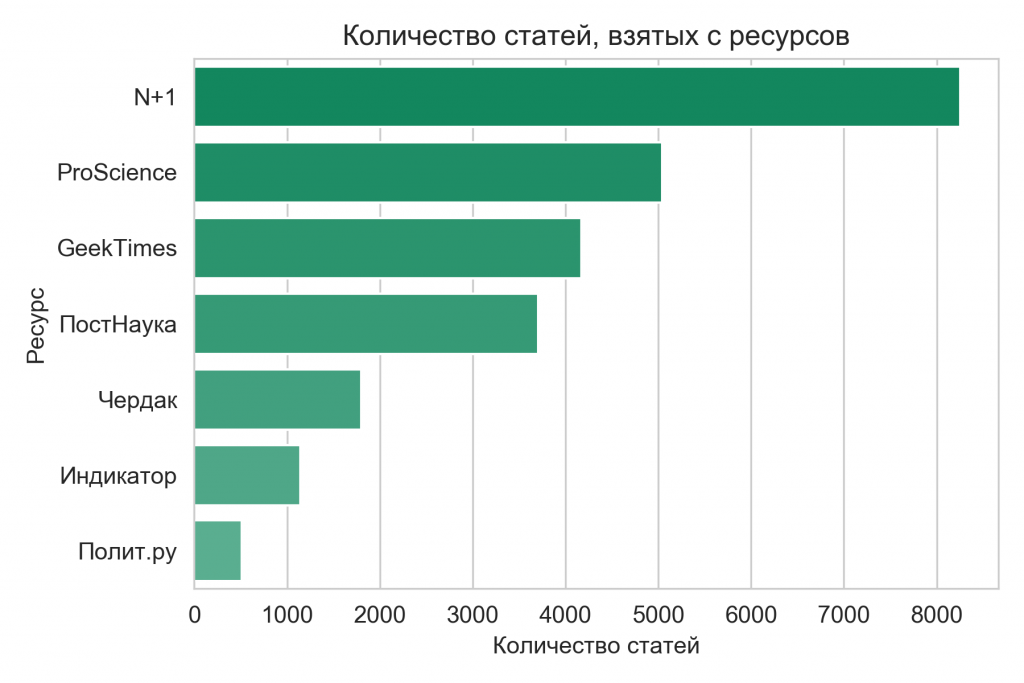
N+1 обогнал всех по количеству материала — 12182 статьи. Ближайшие соперники — Pro Science и Geektimes — содержали всего около 5200 статей. Самым небольшим источником для корпуса стал раздел Лекции на Polit.ru — всего 562 материала. Это может быть связано с тем, что лекции сами по себе являются более сложным форматом, требующим больших затрат — лекцию нужно не только записать, но и расшифровать (что занимает много времени), после чего привести к читабельному виду.
Все тексты были пропущены через морфологический анализатор — так мы смогли получить информацию о том, из чего состоят материалы корпуса, как минимум части речи.
Разгадали тайну имени
Мы выделили имена авторов, которые были помечены специальным тегом для имени собственного. Чаще авторство указывается комбинацией «Имя + Фамилия», а значит, если мы видим два имени собственных подряд, можно предположить, что мы работаем с именем. Непосредственно имя автора, как правило, пишется в полном виде, и нам повезло — не пришлось долго думать и придумывать хитрые трюки, чтобы угадать гендер имён типа «Женя» или «Саша».
В некоторых статьях гендер автора уже был указан, для остальных пришлось привлечь морфологический парсинг через Mystem [2] и списки имён. Распределение по рубрикам получилось следующим:
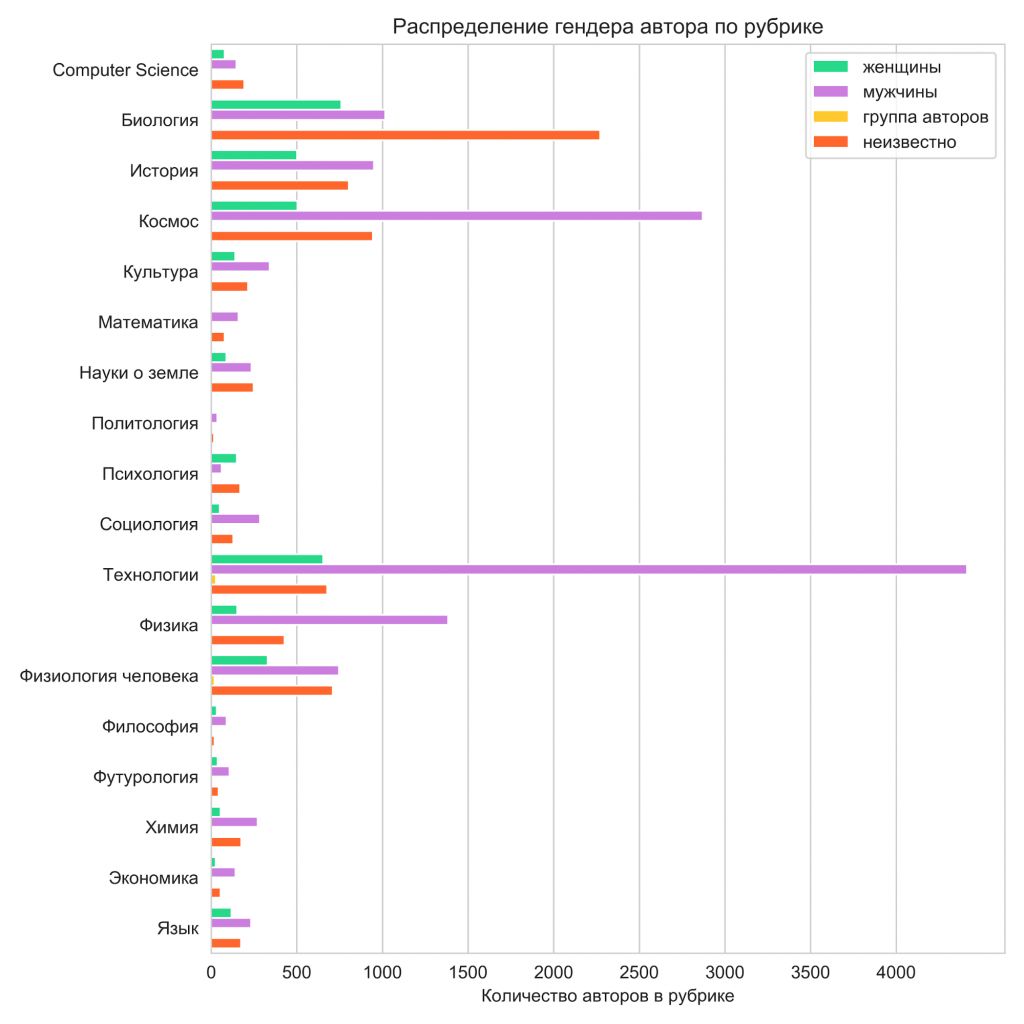
Во-первых, мы обнаружили, что некоторые тексты пишутся целыми коллективами (эта метка присваивалась, если в списке авторов была хоть одна запятая — как иначе можно перечислить авторов?); в основном это происходит в рубрике «Технологии». Чаще всего такие тексты выпускались в ПостНауке или Индикаторе.
С другой стороны, осталось много статей, в которых распознать гендер автора не удалось. Разбор таких случаев показал, что чаще всего в этом поле указан просто источник (например, на GeekTimes много статей, автор которых — компания IBM). В некоторых статьях Чердака и ProScience (разделы «Биология», «Физиология человека») не были указаны авторы, поэтому не получилось достать и проанализировать эти данные. Лидерство мужчин в рубрике «Технологии» можно также объяснить тем, что в эту рубрику сильно вложился GeekTimes, у которого чаще всего указаны авторы.
Получили тематики текстов без регистрации и СМС и посчитали, про что пишут чаще всего
В составе датасета нам не пришлось применять тематического моделирования (о нём можно прочитать в публикации Системного Блока [3]) или других методик, чтобы понять, о чём тексты. Источники разбились на три класса: для некоторых текстов присутствовали теги, для других — рубрики, третьи использовали и то, и другое. Вся эта информация объединилась в отдельный раздел.
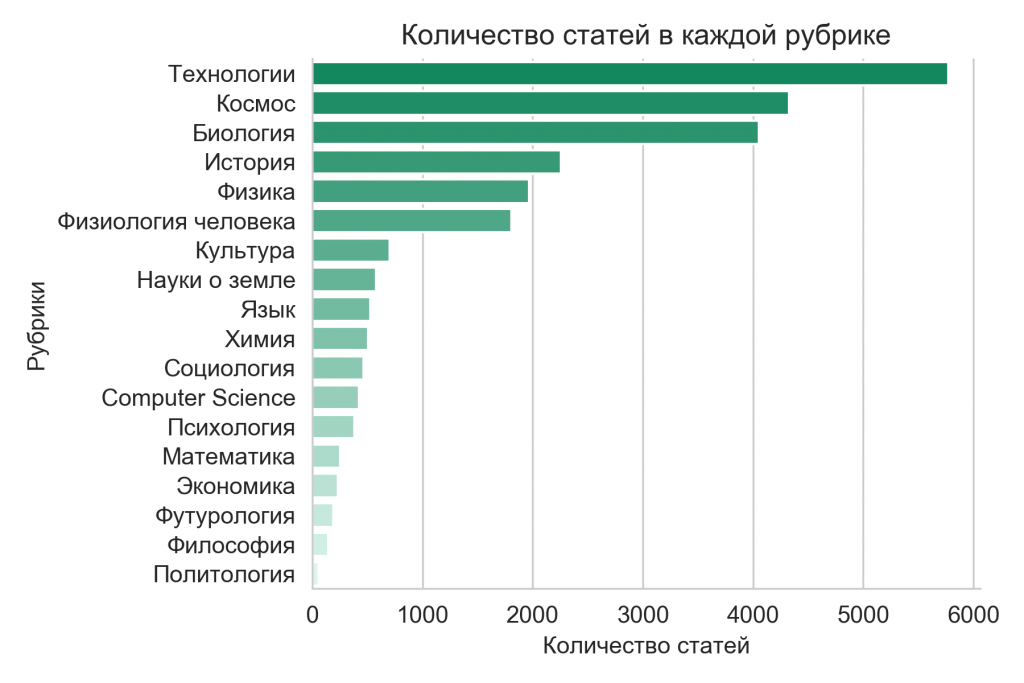
Обычно сам жанр научно-популярных текстов воспринимается как объяснение сложных концептов простыми словами — причём основными науками скорее ожидаются естественные. Эти ожидания оправдываются — в корпусе больше всех представлены рубрики Технологии и Космос. Меньше всего материалов относятся к рубрике Политология — это довольно логично, если вспомнить, что сайт Полит.ру меньше всех остальных представлен в тексте; а где ещё читать про политику?
Увидели чёткую разницу между устной и письменной речью
В материалах Полит.ру и Постнауки замечен явный тренд на использование местоимений-существительных (например, она, это, кто) и междометий (ну, так). Местоимения делают текст более связным и понятным для читателя — рассказывая об одном элементе, концепте или явлении, автору нужно всегда держать читателя в курсе, о чём идёт речь. Таким образом, текст получается более связным.
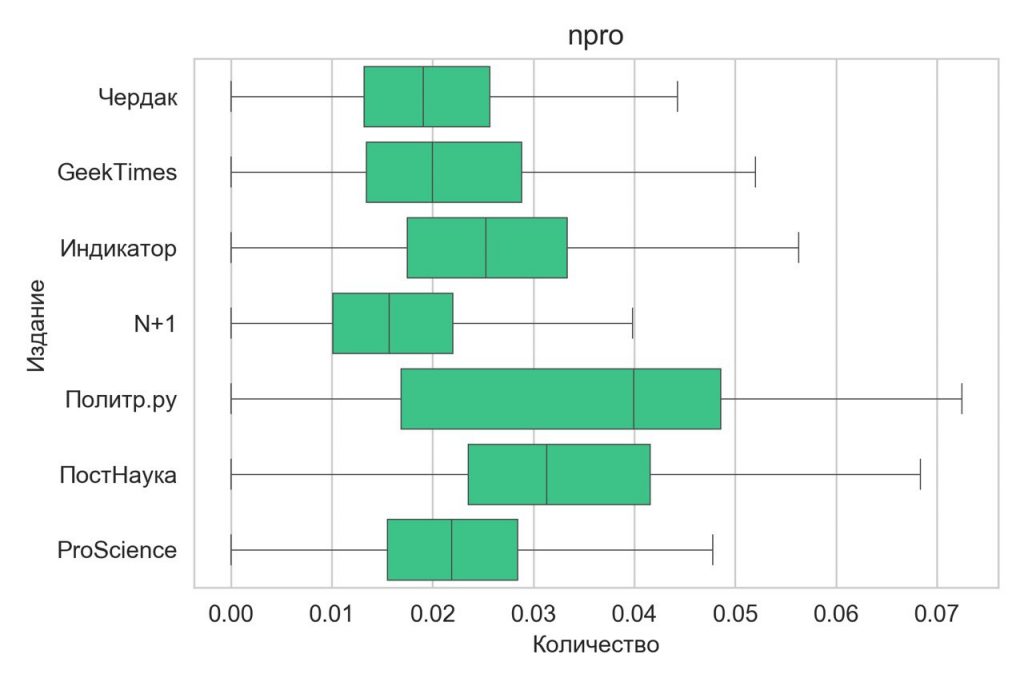
Междометия же — хорошо заметный признак устной речи. Они часто заполняют пустоту, когда человек концентрируется или что-то вспоминает; даже в письменной речи мы скорее видим их в диалогах. Этот факт можно связать с контентом этих ресурсов — и там, и там есть лекции, под которыми есть расшифровки. Таким образом, полностью дешифрованный текст будет содержать и одну из главных отличительных черт разговорной речи.
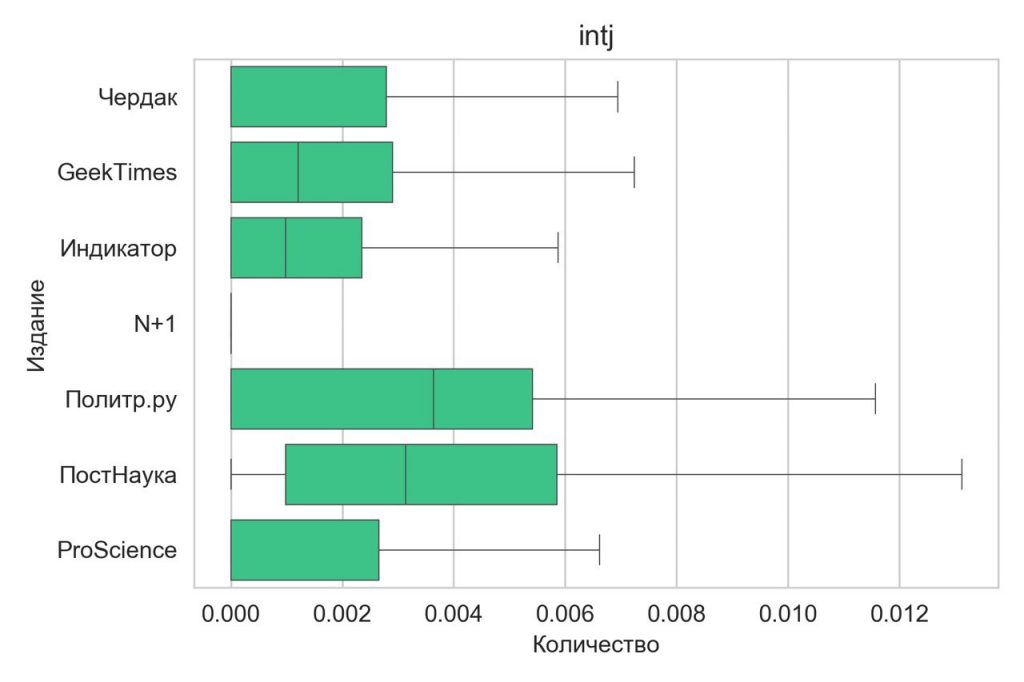
Нашли фишки рубрик
Разные рубрики требуют разного изложения и повествования. Тексты гуманитарных рубрик — это, как правило, связные рассказы, которые плавно переходят от одного понятия к другому. Плавность рассказа и его связность обеспечивает гораздо большее по сравнению с техническими обеспечивает наличие союзов.
Знаки препинания
Помимо работы с частями речи, мы извлекли все знаки препинания, посчитали их частотность (количество употреблений в тексте) и записали среднюю долю знаков препинания в тексте.
Самым показательным знаком оказалась дробь — она чётко отличила традиционно гуманитарные рубрики (например, история, социология, язык) от технических (физика, космос, технологии). В гуманитарных текстах дробь почти никогда не нужна, в то время как во многих «технических» рубриках могут присутствовать числа, выраженные дробью, а может, даже математические выкладки.
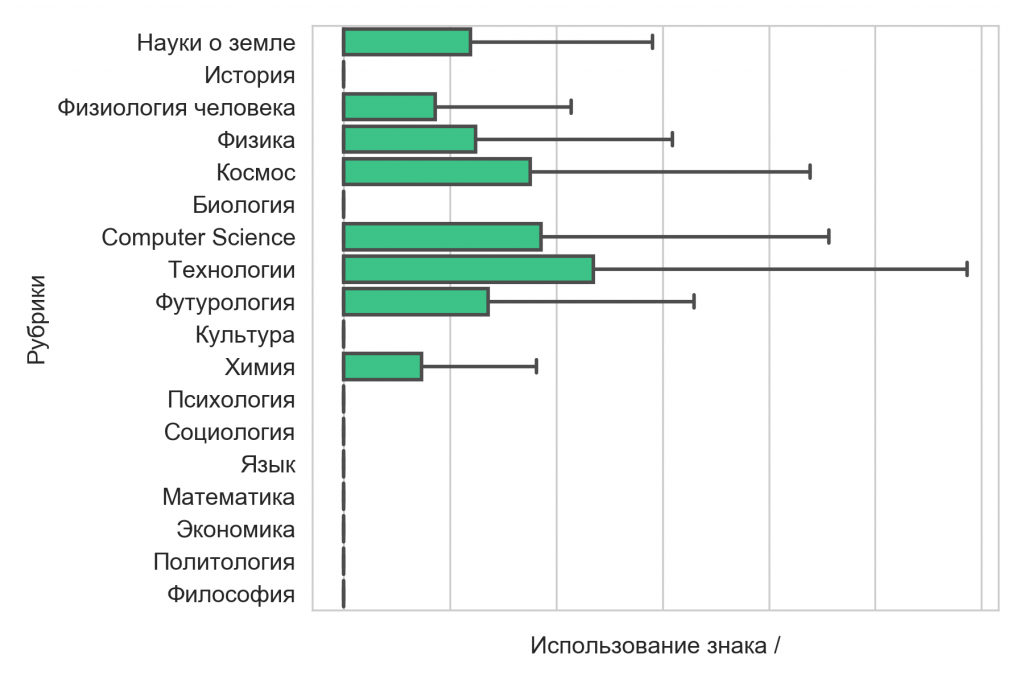
Также технические рубрики выделяет большое количество числительных, что не очень удивительно: логично предположить, что там, где находятся дроби, будут и числа.
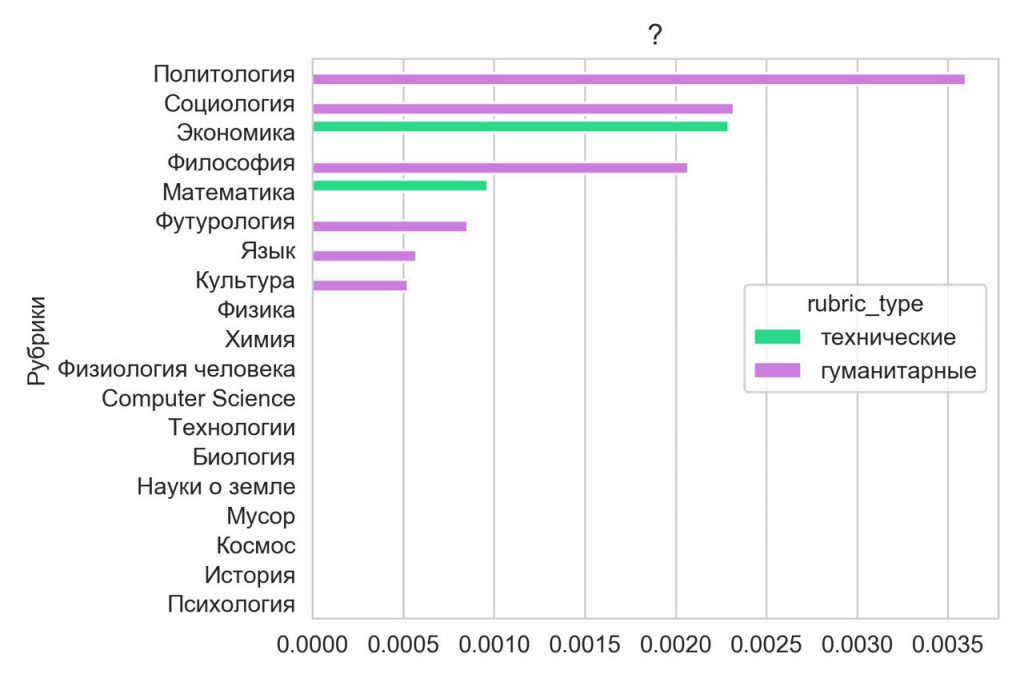
А что, если мы посмотрим по эмоциональным знакам препинания — например, вопросительному знаку? Оказывается, больше всего его любят политологи, социологи и философы. Получается, что в явном виде вопросы задают больше авторы текстов гуманитарной направленности. Политология могла оказаться в топе благодаря тому, что тексты на Полит.ру, основном поставщике материалов в этой рубрике, в основном являются расшифровками лекций, на которых вопросы часто используются для того, чтобы привлечь или удержать внимание аудитории.
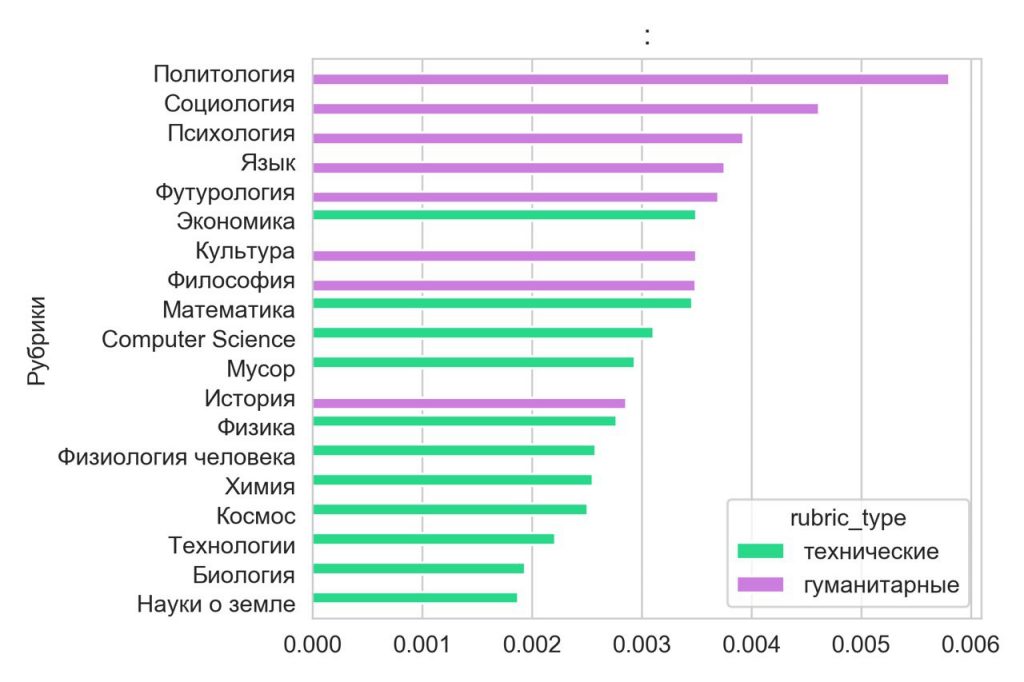
Также оказалось, что «гуманитарии» более склонны к использованию двоеточия — видимо, для пояснения примеров:
Длина текста
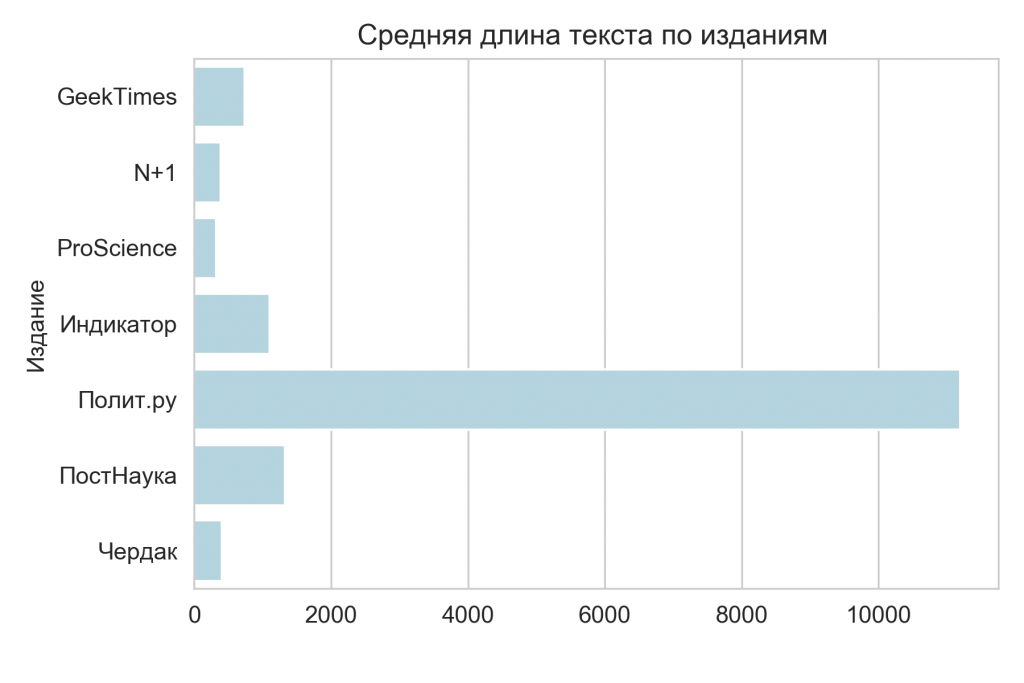
Обратимся к длине текста. Здесь однозначно распознаются лекции Полит.ру — в среднем около 32 тысяч знаков. Это примерно в 10 раз больше, чем второй самый «болтливый» ресурс — Индикатор.ру. По всей видимости, это связано с тем, что лекции Полит.ру длиннее того же типа повествования на Постнауке (на Полит.ру один текст — это, например, полная лекция, а видео Постнауки, к которым выкладываются расшифровки, нечасто превышают 10 минут), а в устной речи мы успеваем произнести гораздо больше слов, чем при написании текстов. Другая теория заключается в том, что помимо обсуждения, политологи дают ещё и самые развёрнутые комментарии.
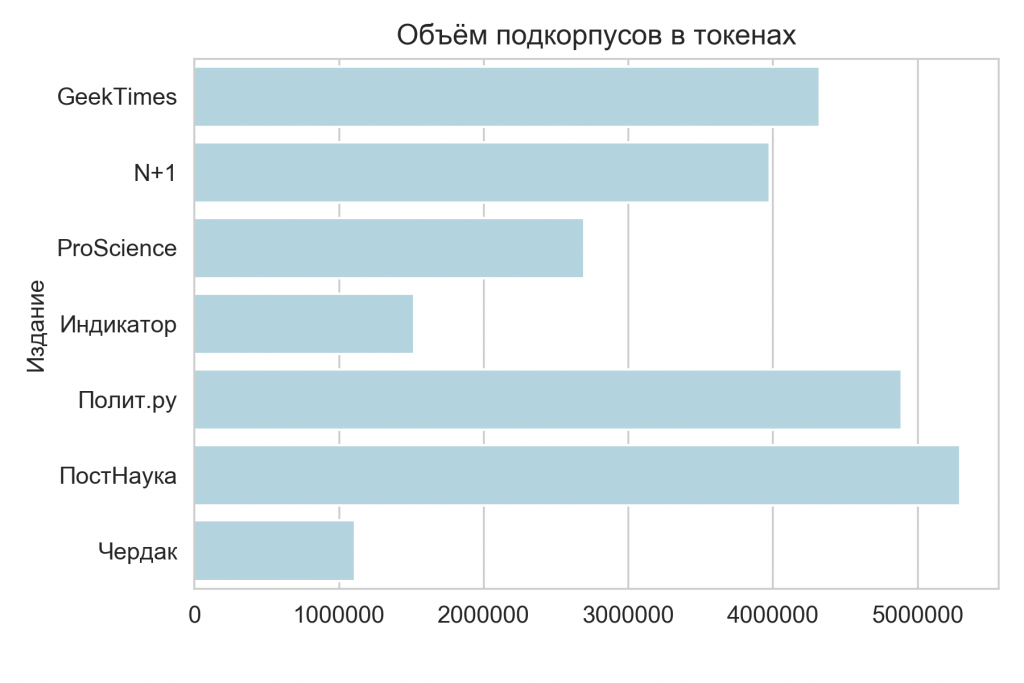
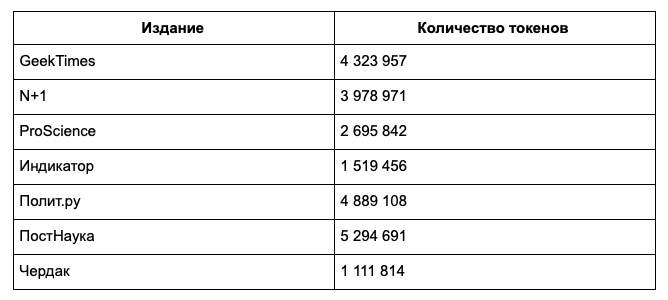
При этом если взглянуть на объём подкорпусов в токенах, то наблюдается совсем другая картина: Полит.Ру уступает лидерство ПостНауке — если писать короче, но больше, можно обойти тех, кто выкладывает мало текстов, но больших.
Подытоживаем
Несмотря на то, что научпоп использует простую лексику для сложных концептов, разные его «ветви» всё же отличаются друг от друга. Помимо разных стилей повествования, такой подход наверняка помогает читателям взять от текста всё.
Ссылки
[1] Оригинальный корпус
[2] Mystem — морфологический анализ текста на русском языке
[3] Как понять, о чём текст, не читая его



