
Появившийся в 2015 году корпус исторических дневников Прожито оказался интересным не только для историков: исследователи из разных сфер активно пользуются сервисом для своих проектов. Исторические дневники содержат много важной и полезной информации — например, даты, упоминания каких-либо событий, людей, мест. Однако извлекать все необходимые для исследования данные вручную может быть проблематично: придется анализировать тысячи дневниковых записей. Для автоматизации этого процесса существует распознавание именованных сущностей (named entity recognition, NER). Подробнее о том, что такое NER, можно узнать в нашем материале.
В зависимости от задачи может потребоваться находить разные сущности в тексте — например, для медицинских текстов нужно находить в тексте упоминания лекарств и их побочных эффектов, для новостей — упоминания мест, людей и организаций.
С точки зрения формальной постановки задачи NER, исторические дневники отчасти близки к новостям, ведь в них тоже нужно находить упоминания людей, мест, организаций и так далее. Тем не менее, дневники имеют свою специфику — они сильно отличаются от новостей стилистически и тесно связаны с экстралингвистическим знанием (историческими фактами, доступными в других источниках). Последнее, с одной стороны, дает возможность оценить масштабы тем, обсуждаемых в дневниках. С другой стороны, экстралингвистическое знание помогает узнать, как исторические события воспринимались очевидцами, а также представляет субъективный, личный взгляд на события, исторические описания которых чаще всего мы узнаем из официальных документов.
В 2019 году появился корпус LitBank — датасет для NER, составленный на основе 100 классических произведений англоязычной литературы [1]. Авторы проекта показали, что модели, обученные на этом наборе данных, показывают отличные результаты от тех, что дают модели, обученные на привычных датасетах. В первую очередь это достигается за счет другого распределения сущностей — в датасетах, построенных на новостях, чаще встречаются организации, в LitBank — упоминания людей.
Мы хотели разработать подобный датасет для русского языка, особенно в свете появления других корпусов исторических текстов — Project1917, Пишу тебе. Так появилась идея создания «Размечено».
Структура
Для «Размечено» было решено взять дневники за определенный исторический период. Это решение позволяет с большей вероятностью получить грамматически похожие тексты. Это важно, так как обычно модели машинного обучения хуже работают с наборами разных с точки зрения грамматики текстов. Итоговый выбор пал на период Перестройки.
Всего в датасет вошла 1331 дневниковая запись, взятая из 124 уникальных дневников и состоящие из 14119 токенов (в зависимости от задачи токен может быть предложением, морфемой или буквой, но в нашем случае токены — слова). Тексты размечены на предмет упоминания следующих сущностей:
- PER — Person, имя человека или группы людей, в том числе ненастоящих и знаменитых.
- LOC — Location, местоположение. Тег включает в себя названия стран, городов, штатов и т.д., когда они обозначают место, а также природные объекты: горы, водоемы и т.д
- ORG — Organization, организация. Официальная ассоциация, например, названия фирм, компаний и т.д.
- FAC — Facility, учреждение. Учреждения, построенные людьми: школы, музеи, места работы, аэропорты, вокзалы и т.д.
- CHAR — Characteristic. характеристика человека (звание, профессия, национальность, принадлежность к социальной группе)
- MISC — Miscellaneous, то есть прочие именованные сущности.
Рассмотрим на примерах, как устроена разметка
1.

2.

3.

4.

При разметке именованных сущностей могут возникнуть следующие сложности:
- Составной характер именованных сущностей (Пример 2)
Далеко не все именованные сущности состоят из одного слова.
Это значит, что асессору (реальному человеку на краудсорсинговых платформах) нужно очень внимательно и вдумчиво читать тексты дневников и выделять иногда два, три, а то и больше слов, относящихся к одной именованной сущности
- Раздробленность именованных сущностей (Пример 3)
Иногда между словами одной именованной сущности могут стоять другие (чаще всего служебные части речи), не являющиеся частью этой сущности. Такие слова мы не размечали как сущность.
В отличие от первых четырех сущностей, часто встречающихся в разных наборах данных для NER, предпоследняя, CHAR, является новой. Действительно, помимо самого человека, также интересно уметь находить и его характеристику — например, социальное положение или профессию.
На следующей иллюстрации можно увидеть распределение сущностей в Размечено:
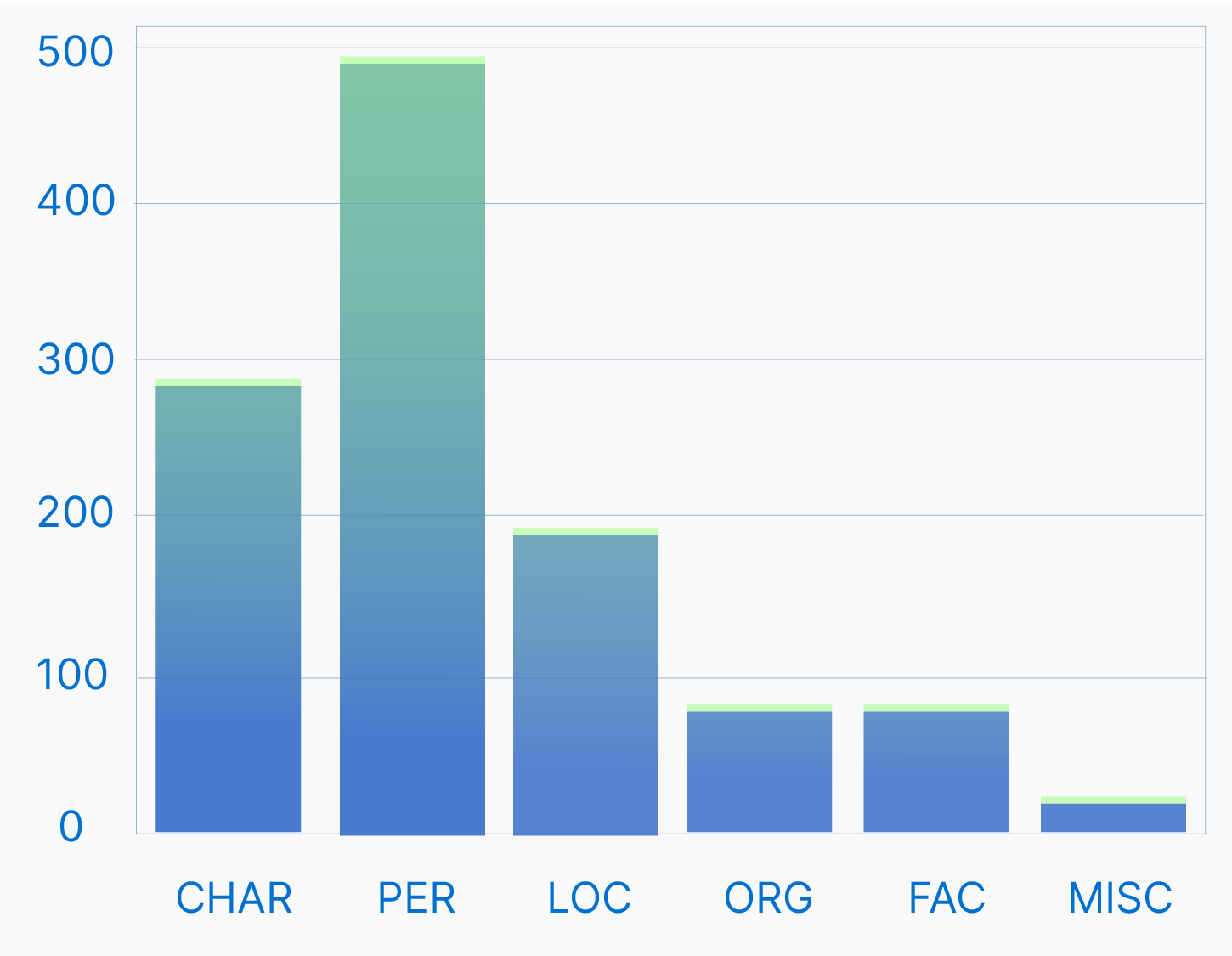
Топ-10 сущностей наглядно иллюстрируют важные для современников Перестройки темы:
| Тип сущности | Топ-10 упоминаний |
| CHAR | ребенок, женщина, президент, друг, поэт, папа, писатель, жена, отец, военный |
| FAC | театр, аэропорт, дом, школа, музей, кафе, станция, библиотека, посольство, тюрьма |
| LOC | город, Москва, Россия, улица, Ленинград, проспект, Кандагар, озера, страна, запад |
| ORG | ЦК, совет, парламент, Политбюро, Правда, КПСС, издательство, верховный, Мосфильм, союз |
| PER | Горбачев, Борис, Ельцин, Володя, Таня, Витя, Рыжков, Яковлев, Сергей, Иван |
Можно заметить, что основная тема для обсуждения — внутренняя политика. Часто упоминаются Горбачев, Ельцин и председатель Совета министров СССР в 1985-1991 годах Рыжков.
Дневники отлично отражают переходность этого периода. С одной стороны, часто встречаются старые советские термины, такие как ЦК и Политбюро. С другой стороны, часто встречаются слова, отражающие новые реалии, например, президент. Интересно, что внешняя политика интересовала людей меньше. Из всех частотных слов только Кандагар имеет отношение к внешней политике СССР в тот период, так как в этом городе базировались советские войска во время афганской войны.
Разметка
После определения периода дневников, необходимо было также придумать эффективный способ разметки данных. Схематично его можно представить следующим образом:
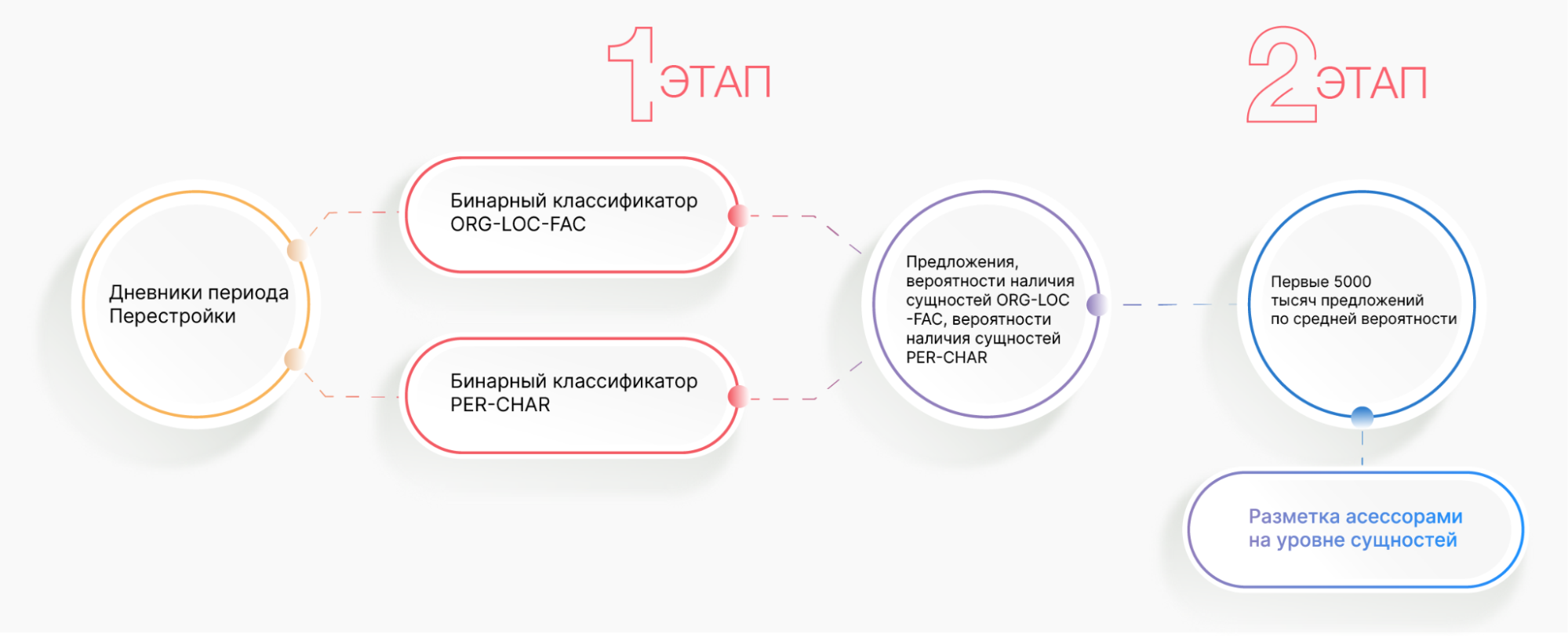
Распишем каждый из этапов подробнее.
Даже после того, как было решено взять дневники только за один исторический период (Перестройку), данных все равно оставалось очень много — около 200 тысяч предложений. Разумеется, разметить такое количество данных было бы дорого, а также не очень разумно — во многих предложениях вообще нет именованных сущностей. Помимо этого, порой трудность разметки состоит в том, что именованные сущности могут состоять не из одного слова, а из нескольких — например, фамилия, имя и отчество. Также непростой для разметки бывает ситуация, когда между словами, обозначающими какую-то одну именованную сущность, вставлено еще какое-нибудь слово. Поэтому в идеале на разметку на уровне токенов хотелось отдать гораздо меньшее количество предложений, в которых, во-первых, с большой вероятностью будут представлены сущности, и, во-вторых, они были бы различными. Как этого добиться?
Если вернуться к описанию сущностей, то можно заметить, что они делятся на две группы. PER и CHAR обозначают людей и их характеристики — национальность, социальное положение, уровень образования и так далее. ORG, LOC и FAC описывают определенные места, и то, чем они являются, их функции — например, дом, церковь, министерство.
В итоге для первого этапа отбора предложений было решено обучить два бинарных классификатора, один из которых определял бы, есть ли в предложении сущности группы ORG-LOC-FAC, а второй — PER-CHAR. Бинарная классификация — чаще всего простая задача машинного обучения, поэтому достаточно было взять небольшую размеченную выборку для дообучения уже готовой модели. В нашем случае хватило 829 и 1465 предложений для ORG-LOC-FAC и PER-CHAR соответственно. Были проведены эксперименты с разными трансформерами (читайте наш материал про трансформеры), и в рамках данной задачи лучше всего подошла модель ruRoBERTa.
Но как дальше отобрать предложения? Можно было бы просто взять предсказания классификатора и для тех предложений, в которых модели определяют сущности каждого из типов, отдать на разметку. Этот подход возможен, однако лучше взять вероятности предсказаний моделей. Это дает гораздо больше информации, и после этого лучше отдать на разметку те предложения, в которых каждая из моделей наиболее уверена.
| Предложение | Вероятность ORG-LOC-FAC | Вероятность PER-CHAR |
| «Он увлекся, например, стенограммами первых съездов партии после 1917 года, VIII, XI, XII». | 0.94 | 0.75 |
| «Ведь она может знать какие-то семейные предания о Сапожниковых, которым принадлежал Оранжерейный промысел». | 0.88 | 0.92 |
| «Возможно, кооперативные издания создадут некоторую свободу для маневрирования писателей». | 0.74 | 0.83 |
Делается это достаточно просто — пусть у нас есть три предложения (таблица выше) с соответствующими вероятностями наличия в них сущностей. Так как мы хотим, чтобы в предложениях были сущности как одной, так и второй группы, будем считать среднее этих вероятностей.
| Предложение | Вероятность ORG-LOC-FAC | Вероятность PER-CHAR | Среднее вероятностей |
| «Он увлекся, например, стенограммами первых съездов партии после 1917 года, VIII, XI, XII». | 0.94 | 0.75 | 0.845 |
| «Ведь она может знать какие-то семейные предания о Сапожниковых, которым принадлежал Оранжерейный промысел». | 0.88 | 0.92 | 0.9 |
| «Возможно, кооперативные издания создадут некоторую свободу для маневрирования писателей». | 0.74 | 0.83 | 0.785 |
После этого сортируем предложения по средней вероятности:
| Предложение | Вероятность ORG-LOC-FAC | Вероятность PER-CHAR | Среднее вероятностей |
| «Ведь она может знать какие-то семейные предания о Сапожниковых, которым принадлежал Оранжерейный промысел». | 0.88 | 0.92 | 0.9 |
| «Он увлекся, например, стенограммами первых съездов партии после 1917 года, VIII, XI, XII». | 0.94 | 0.75 | 0.845 |
| «Возможно, кооперативные издания создадут некоторую свободу для маневрирования писателей». | 0.74 | 0.83 | 0.785 |
В итоге отбираем какое-то количество первых предложений.
В нашем случае из 200 тысяч предложений было решено взять первые 5 тысяч по среднему вероятностей, и после этого отдать их на разметку асессорам на уровне токенов. Таким образом, в первую очередь, получилось значительно сократить траты на разметку данных, а также отобрать те предложения, в которых с высокой вероятностью будут сущности.
Применение
Как уже было сказано, в отличие от новостных текстов, литературные и дневниковые тексты обладают фабулой. Извлечение именованных сущностей — первый шаг для ее выделения. В дальнейшем на основании этой разметки можно решать задачи разрешения кореференции (нахождение всех выражений, относящихся к одной сущности), а также извлечения событий и построения сложных нарративов, характерных для дневников (то есть выстраивания сюжетной арки не на уровне одной дневниковой записи, а на уровне всего дневника). Это облегчает работу со структурой повествования и может помочь представить ее в более компактном виде.
С точки зрения компьютерных наук, получившийся датасет отлично подойдет для обучения моделей для извлечения именованных сущностей из других корпусов исторических текстов 20 века.
Помимо этого, описанный алгоритм разметки данных можно перенести на любой другой корпус — например, на дневники из Прожито за другую эпоху.
Более подробно со структурой датасета, результатами экспериментов, анализом согласия асессоров можно ознакомиться в оригинальной статье [2]. Также сам датасет доступен в репозитории [3].
Источники
- Оригинальная статья про LitBank.
- Оригинальная статья про датасет Razmecheno.
- Репозиторий, в котором расположен датасет.
Иллюстратор внутренних графиков: Екатерина Эль-Айясс



