
Команда компьютерных лингвистов из школы лингвистики НИУ ВШЭ, университета Тренто и университета Осло под руководством Андрея Кутузова представила на конференции AIST библиотеку vec2graph для Python. Vec2graph умеет визуализировать семантическую близость слов в виде сети. Информацию о близости слов vec2graph получает из векторной семантической модели. Вот так выглядит граф для слова «лук»:
Расскажем по порядку, что это такое и откуда берется.
Напоминалка: дистрибутивная семантика
«Системный Блокъ» уже рассказывал о том, что современные технологии автоматической обработки текста (даже те, которые пафосно и не всегда заслуженно называют «искусственным интеллектом») опираются на дистрибутивную семантику. В основе дистрибутивной семантики — простая идея: близкие по значению слова будут встречаться в похожих контекстах (ср. «полицейский бьет митингующего дубинкой», «омоновец бьет митингующего дубинкой», «полиция разогнала мирный митинг», «омон разогнал мирный митинг»).
Чтобы передать такое знание о контекстной близости слов компьютеру, ученые и инженеры обучают векторные семантические модели — например, с помощью word2vec (вот здесь мы подробно рассказывали, как это работает). Такие модели при обучении сохраняют знание о частых и редких контекстах слова в виде упорядоченного списка чисел (т.е. в виде вектора — отсюда и «векторные» модели). Благодаря этому семантические расстояния между словами становятся измеримы, и машина, измерив их, понимает: слова полицейский и омоновец похожи (благодаря частому употреблению в похожих контекстах вектора этих слов будут близкими).
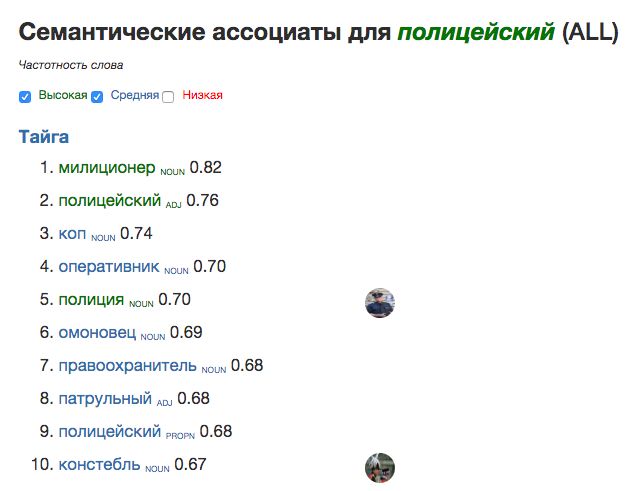
Как визуализировать семантическую близость?
Как отображать эти семантические близости из векторной модели так, чтобы они снова стали понятны человеку? Один самый простой вариант вы уже видели выше: можно для любого слова просто выдавать столбик ближайших к нему «семантических ассоциатов» (т.е. слов с наиболее похожими семантическими векторами).
Можно ли более наглядно? Один из вариантов — попытаться сжать многомерное векторное пространство модели обратно в двумерное. Алгоритмов такого снижения размерности (PCA, MDS, t-SNE) множество, статистика разрабатывает их последние лет 100.
К сожалению, такое представление неизбежно теряет часть информации о соотношении векторов. Невозможно превратить, к примеру, 500-мерное пространство в двумерную картинку на плоскости без потерь.
Семантика и сети
Третья альтернатива — использовать сети (они же графы). Для каждого слова можно строить сеть из его семантических ассоциатов. При этом сам показатель близости можно отобразить, например, через длину линии: чем короче связь — тем ближе слово в векторной модели. Именно такие визуализации делает vec2graph.
Сети хороши не только наглядностью, но и тем, что здесь можно частично преодолеть ограничения так называемых контекстно-независимых моделей (word2vec, fastText и мн.других). Такие модели всегда хранят один вектор для любого слова, даже многозначного. В результате получается, что слова с несколькими значениям типа «кисть» или «лук» будут иметь один гибридный вектор. Такой вектор будет тяготеть сразу и к словам, связанным с растениями, огородом, едой, и к разной военно-оружейно-спортивной лексике («стрелы», «колчан», «лучник»). Это серьезная проблема дистрибутивной семантики.
Сетевая визуализация позволяет отобразить не только самые близкие слова для «лука», но и близость этих самых слов между собой. «Колчан» будет близок «стреле», но не слишком близок «чесноку», поэтому связи между «колчаном» и «чесноком» не отобразится. В результате получается граф с двумя кластерами: один «оружейный», другой — «растительный»:
Видно, что «чеснок» и «репчатый» связаны с луком-растением, но не связаны с оружием.
А вот и код для vec2graph, который позволяет это сделать:
WORD = 'лук_NOUN'
visualize(OUTPUT_DIR, MODEL, WORD, depth=0, topn=8, threshold=0.53, edge=1, sep=True)Как же получается, что не все слова связаны со всеми? Для этого в vec2graph есть полезная опция «порог близости» (threshold). В примере выше если слово входит в топ-8 ближайших семантических ассоциатов, но при этом его близость к «луку» ниже 0,53, оно появится в визуализации как узел сети, но сама такая связь не отобразится. Так происходит со словом «арбалет».
Больше примеров сетевых визуализаций
Молодой
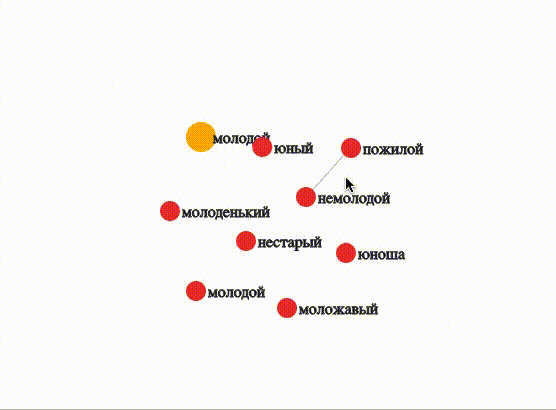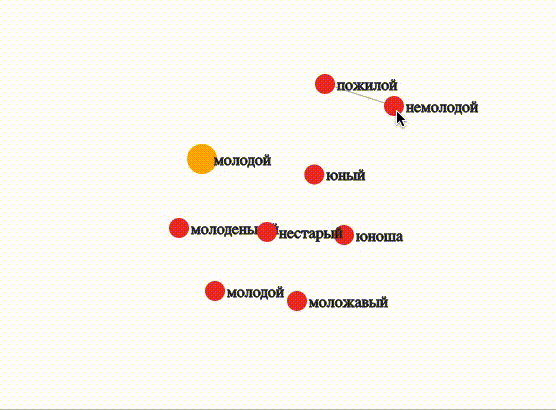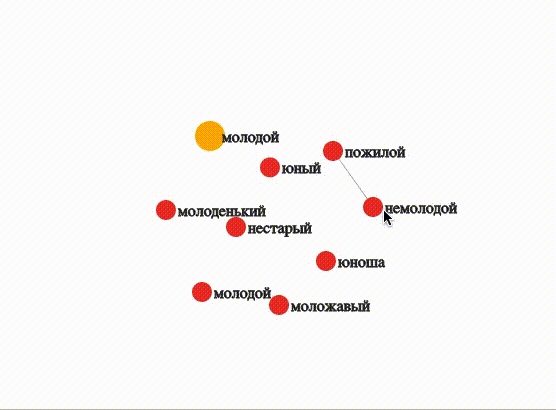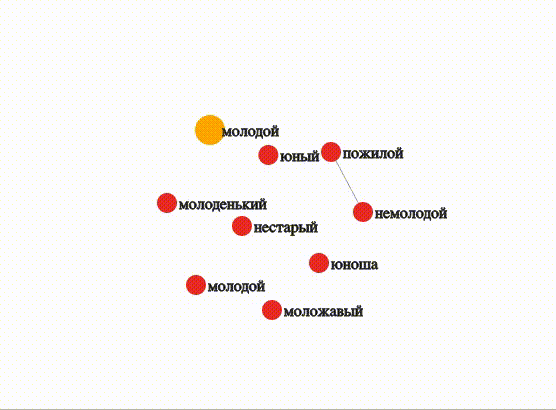
WORD = 'молодой_ADJ'
visualize(OUTPUT_DIR, MODEL, WORD, depth=0, topn=8, threshold=0.7, edge=1, sep=True)При высоком пороге близости (0,7) только «немолодой» и «пожилой» достаточно близки друг другу, чтобы отобразилась связь.
Оранжерея
WORD = 'оранжерея_NOUN'
visualize(OUTPUT_DIR, MODEL, WORD, depth=0, topn=8, threshold=0.6, edge=1, sep=True)«Теплица» связана по смыслу с «оранжереей», но далека от цветов, поэтому между ней и «цветочными» словами связи слабые (в данном случае — меньше 0.6).
Как сделать это самому?
Самая большая радость в том, что сделать это несложно: нужно лишь установить библиотеку vec2graph, скачать предобученную дистрибутивную модель на ваш вкус, а ещё установить несколько зависимостей.
Установка библиотеки и зависимостей:
Удобнее всего делать это с помощью pip. Если работаете в jupyter — можно обратиться к командной строке прямо там с помощью «!»:
! pip3 install --user --upgrade pip # может понадобиться
! pip3 install smart_open --upgrade # может понадобиться
! pip3 install gensim --upgrade # может понадобиться
! pip3 install vec2graph --upgradeИмпорт из vec2graph:
from vec2graph import visualize
from gensim.models.keyedvectors import KeyedVectorsЗаранее создать папку для html-файлов с графами, прописать путь к ней и к дистрибутивной модели:
OUTPUT_DIR = '/Users/aika/Documents/Masters/VIZ/viz_graphs'
MODEL = KeyedVectors.load_word2vec_format('model.bin', binary=True)Использование vec2graph:
Теперь осталось задать слово и параметры, как было выше в подписях к визуализациям:
WORD = 'попугай_NOUN' # нужен pos-тэг или не нужен зависит от того, как слова представлены в модели.
visualize(OUTPUT_DIR, MODEL, WORD, depth=0, topn=8, threshold=0.62, edge=1, sep=True)depth=0 означает, что будет создан один файл с графом, узлами которого будут слово WORD и его ближайшие соседи. Если увеличивать глубину, то ближайшие слова-соседи исходного запроса тоже распустятся графами в отдельных html-файлах.
topn=8 значит количество слов-соседей для одного слова-запроса.
threshold=0.6 — самое интересное: это минимальное значение косинусной близости, необходимое для прорисовки ребра между словами. По умолчанию этот показатель равен нулю, тогда граф полносвязный, но интереснее всего его регулировать и выяснять, какие слова близки и образуют кластеры, а какие оказываются дальше.
edge=1 отвечает за толщину рёбер.
sep=True означает, что метки частей речи показывать не нужно.
Результат будет выглядеть так:
Теперь вы можете сами исследовать значения слов.
Ссылки
Создатели библиотеки: Алексей Яскевич, Анастасия Лисицына, Тамара Жордания, Надежда Катричева, Елизавета Кузьменко, Андрей Кутузов.



