Сегодня уже мало кому нужно объяснять, что такое чат-боты. Мы неизбежно сталкиваемся с ними, когда хотим открыть вклад в банке, уточнить тариф у мобильного оператора или просто заказать пиццу.
Чат-боты вызывают интерес у бизнеса, ищущего способы сократить расходы на колл-центры и улучшить взаимодействие с клиентами. Кто-то идет дальше — и создает Алису, способную болтать на разные темы, развлекая вас, когда вам скучно, а значит, повышая вашу лояльность.
Как это устроено?
Общая архитектура диалоговой системы состоит из четырех компонентов.
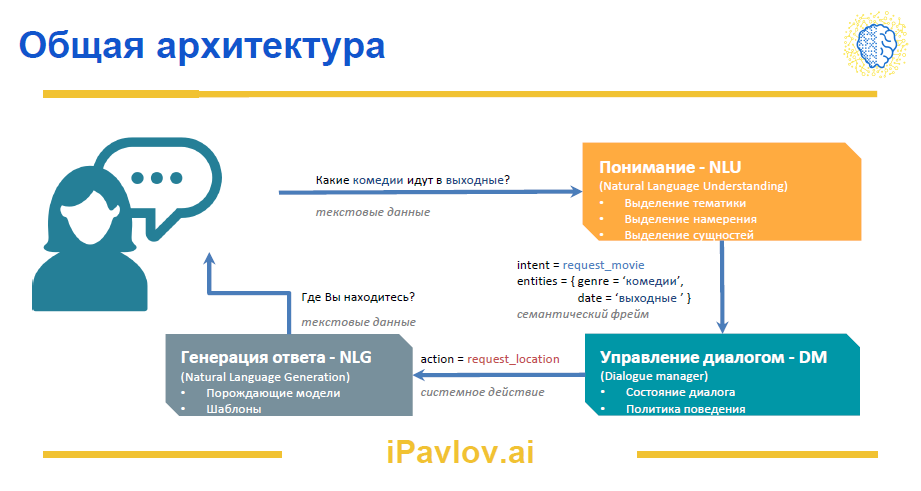
Для начала нам необходимо получить входящие данные от пользователя. Это может быть текст, напечатанный в диалоговом окне, или речь, которую необходимо распознать и перевести в текстовый формат.
Далее на сцену выходит одна из самых сложных частей нашего чат-бота, призванная обеспечить понимание входного сообщения. Для простых целеориентированных чат-ботов проблему понимания естественного языка (Natural Language Understanding, NLU) можно свести к следующим задачам: выделение тематики сообщения пользователя, выделение намерения (intent extraction) и распознавание именованных сущностей (Named Entity Recognition, NER).
После анализа информации, полученной от пользователя, происходит принятие решения о том, как нужно выстраивать общение дальше: уточнить недостающие детали, переспросить, поблагодарить и др.
Наконец, на финальном этапе происходит генерация ответа (Natural Language Generation). В большинстве чат-ботов генерация реализована набором шаблонов, в которые вставляются кастомизированные данные (имя пользователя, заказ и т.д.). Это делается для того, чтобы максимально исключить возможность генерации потенциально неприятных сообщений (все мы помним случай, как чат-бот советовал клиенту банка «отрезать пальцы»).
Как научиться понимать?
Обратимся к самой сложной части нашего чат-бота — пониманию сообщения пользователя. В основе всего лежит т.н. семантический фрейм (semantic frame) — набор знаний о нашем домене (предметной области). Так, например, если мы создаем чат-бот для ресторанов, нам потребуется собрать онтологию, в которой, помимо специальной лексики, будут содержаться, например, знания о ценовой категории ресторана, типе кухни, адресах и т.д.
После определения тематики (домена) сообщения, необходимо понять, что же человек от нас (то есть от бота) хочет. Если продолжить наш пример о ресторанном чат-боте, то нужно определить, хочет ли пользователь найти ресторан, заказать доставку еды или узнать часы работы заведения. Эта задача называется распознаванием интентов (намерений).

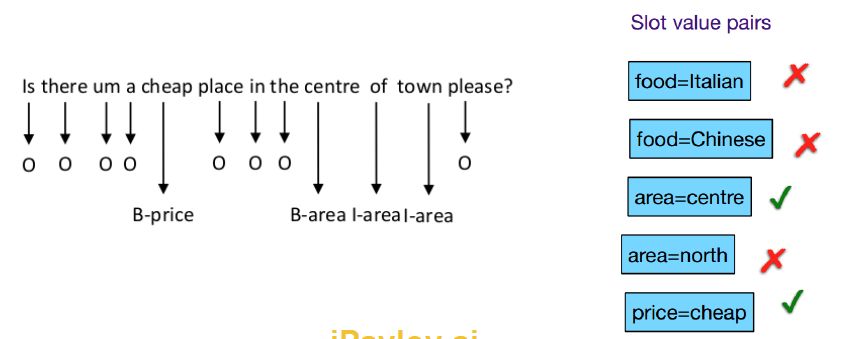
Для каждого интента в семантическом фрейме есть свой шаблон со слотами, которые заполняются информацией, извлеченной из сообщения пользователя. Так, интент «найти_ресторан» может включать слоты «цена», «тип_кухни», «место» и др.

Как извлечь информацию для заполнения слотов? Для этого необходимо в достаточно большом корпусе примеров выделить вручную важные для нас слова и фразы, а далее на размеченном корпусе обучить модель машинного обучения выделять необходимые нам факты и сущности автоматически. Такая модель способна извлекать необходимую нам информацию из сообщения пользователя, после чего специальный инструмент относит их к определенному слоту семантического фрейма.
Управление диалогом
После того, как мы постарались извлечь и структурировать всю необходимую нам информацию, наступает этап стратегического планирования: что необходимо сделать чат-боту в ответ на сообщение пользователя?
На концептуальном уровне управление диалогом представляет собой достаточно простую вещь: у нас есть последовательность наблюдений (непосредственно текст сообщения пользователя) и некоторое количество состояний диалоговой системы (история взаимодействия чат-бота и пользователя; по сути — заполненные слоты семантического фрейма). Также в систему управления должен входить определенный набор действий, которые система может предпринять: обратиться с вопросом к пользователю, если какой-то слот оказался незаполненным, сделать запрос к базе данных и т.д.
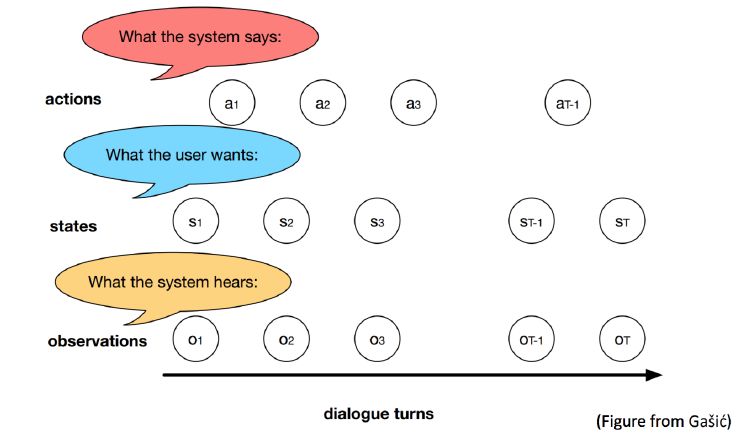
Для голосовых чат-ботов характерно также уточнение значения неоднозначно распознанного фрагмента речи.

Генерация сообщений
Для непосредственного взаимодействия с пользователем чат-боту нужно уметь самостоятельно генерировать выходные сообщения. В большинстве современных решений механизм генерации основан на некотором количестве шаблонов, в которые вставляются необходимые переменные конкретного диалога (имя пользователя, результаты запроса и т.д.). Несмотря на то, что такая система может быть достаточно громоздкой и сложной в поддержании, разработчики идут на это, чтобы обеспечить полную предсказуемость сгенерированных сообщений и перестраховаться на случай порождения неэтичных текстов.

Это все хорошо, а как бота-то сделать?
Невооруженным глазом видно, что реализация описанной выше системы — дело очень трудоемкое, требующее целой команды специалистов с экспертизой в разных областях. Но есть и хорошие новости: для облегчения жизни разработчиков командой DeepPavlov был создан ряд инструментов, помогающих решить самую сложную задачу работы чат-бота — понимание естественного языка. Рассмотрим их поподробнее.

Итак, первым делом боту нужно научиться определять предметную область — домен разговора, а также интент пользователя. Для этого необходимо классифицировать входящее сообщение — задача, которой специально обучены модели нейронных сетей DeepPavlov на основе BERT: можно взять как предобученные модели, так и дообучить их на своих данных для более точных предсказаний.
Далее мы хотим выделить интересующие нас сущности — факты, которыми мы потом будем заполнять слоты семантического фрейма. У DeepPavlov также есть модели для решения задачи NER, стабильно показывающие высокое качество для русского языка (F1 score до 98.1).
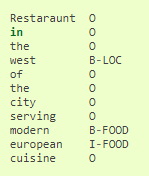
Распознанные сущности необходимо вставить в слоты — для этого в пайплайне распознавания именованных сущностей есть специальный компонент slotfiller.

Также DeepPavlov предоставляет удобный спеллчекинг, помогающий справляться с опечатками в сообщениях пользователей и не плодить лишних сущностей — все вариации написания в рамках определенного порога приводятся к одному слову.
Что касается управления диалогом, у DeepPavlov есть несколько доступных конфигураций для целеориентированных ботов. Так, простой go_bot, обученный на датасете dstc2 (соревнование по созданию диалоговых систем Dialog State Tracking Challenge 2), доступен из коробки.
Можете сами попробовать запустить его прямо в консоли:
from deeppavlov import build_model, configs
bot1 = build_model(configs.go_bot.gobot_dstc2, download=True)
bot1(['hi, i want restaurant in the cheap pricerange'])
bot1(['bye'])Отсутствующие пакеты можно установить, выполнив команду:
python -m deeppavlov install gobot_dstc2Полезные материалы
Помимо своих инструментов, команда DeepPavlov создает тьюториалы, выступает на конференциях и активно рассказывает о своих разработках широкой общественности. Для более подробного знакомства с их библиотекой и ее возможностями рекомендуем посмотреть документацию. Также на сайте доступны стенды с демонстрацией ключевых инструментов библиотеки, а в репозитории — colab-тетради с руководством по запуску целеориентированного чат-бота.
Источники
- Валентин Малых. Как сделать своего бота с помощью DeepPavlov
- DeepPavlov для разработчиков: #2 настройка и деплоймент
- Neural Named Entity Recognition and Slot Filling