
Недавно мы писали о том, как компьютеры «понимают» значения слов благодаря дистрибутивным моделям (их еще называют векторными). Таким моделям не нужно толковых словарей, энциклопедий и справочников. Просто дайте им Очень. Много. Текстов — и вуаля, они могут сказать, что помидор и томат очень похожи по смыслу, а помидор и лингвистика — совсем нет.
Но дистрибутивные модели умеют не только сравнивать слова по смысловой близости. Еще они могут складывать и вычитать значения — в самом прямом арифметическом смысле. Например, такая модель (и без всякого искусственного интеллекта!) выдаст вам слово «королева», если вы скомандуете взять «короля», вычесть из него «мужчину» и прибавить «женщину». Кстати, вы можете воспроизвести это сами на rusvectores.org (который мы тоже уже показывали) в разделе семантический калькулятор. Советуем использовать модель, обученную сразу на Национальном корпусе русского языка и русской Wikipedia.
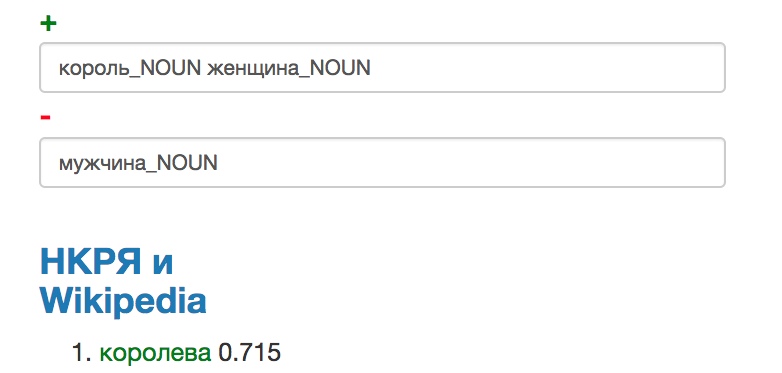
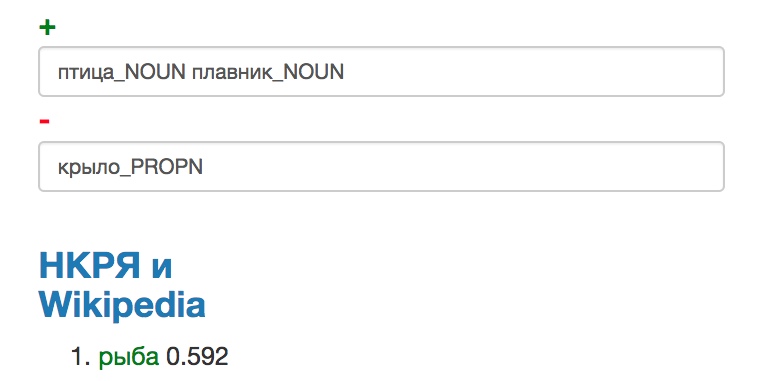
Еще пара примеров. Вычтем из птицы крыло и прибавим плавник:
А теперь немного похулиганим — вычтем из Гитлера Германию и прибавим СССР. Конец немного предсказуем:

Напоследок — философский вопрос. А что будет, если из слова жизнь вычесть слово любовь?
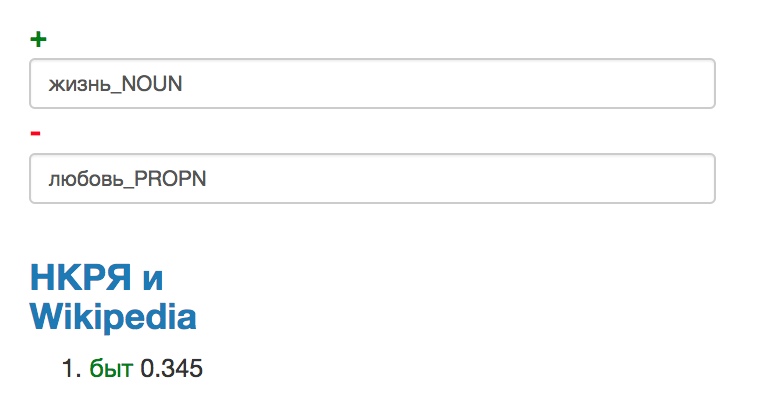
Как видите, дистрибутивные модели — те еще философы. Напоминаем, ни в одном случае модель на самом деле не обладает никаким настоящим знанием о значениях слов. Такой результат получается благодаря тому, что модель запоминает контексты употребления каждого слова в виде вектора (т.е. попросту набора чисел — с какой частотой встречались рядом с этим словом другие слова). А про вектора мы помним со школы, что их можно складывать и вычитать. Так и работает семантический калькулятор.



