
Япония — одна из передовых стран в сфере Digital Humanities, но о японских DH-проектах знают немногие. Японские исследователи создают базы данных (про Биографическую базу данных Японии «Системный Блокъ» уже писал тут), анализируют исторические тексты, исследуют искусство и литературу с использованием цифровых методов. В этой статье мы рассмотрим проекты по Digital Humanities в Японии и разберём, какие институты и ассоциации активны в сфере японского DH.
DH-проекты в Японии
Minna de Honkoku
Проект «Минна дэ хонкоку» (みんなで翻刻, что переводится дословно как «Расшифруем вместе») занимается расшифровкой исторических оцифрованных материалов, изданных в Японии до середины XIX века, и популяризации этого процесса. Инициатива была начата в 2017 году Исследовательской группой Киотского университета как проект по расшифровке исторических документов о землетрясениях. Сейчас «Минна дэ хонкоку» расшифровывает материалы, связанные не только с природными катастрофами.
Что значит «расшифровать японский текст»?
До начала XX в. японцы использовали преимущественно ксилографический способ печати книг, при котором наиболее распространён скорописный шрифт кудзуси дзи (崩し字). Для сравнения, на рисунке справа — фотография текста, написанного кудздуси дзи, а слева — его расшифровка на современный японский язык (см. Рис. 1).
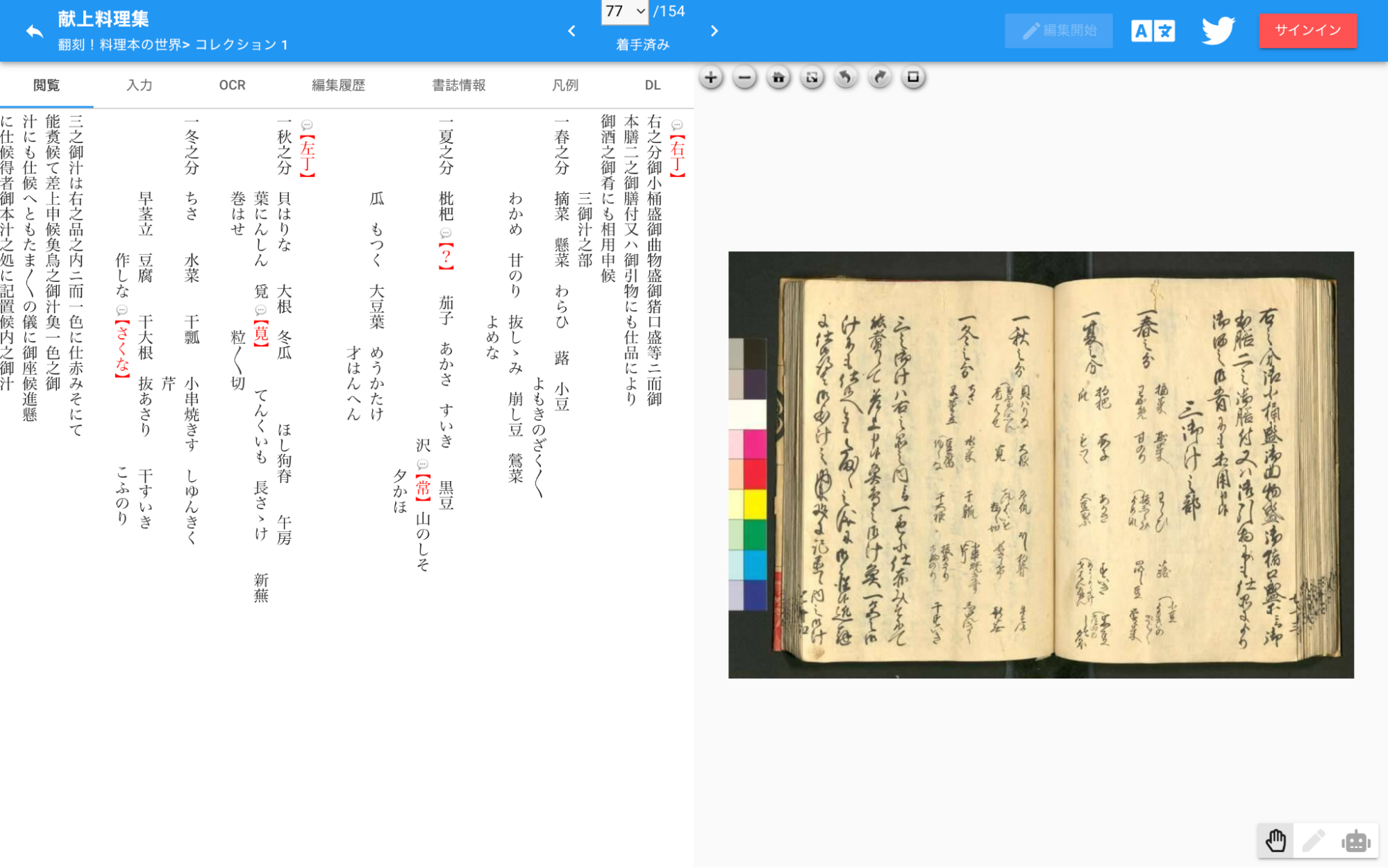
Рисунок 1. Слева находится транскрипция документа, где красным выделен неточный или неизвестный символ. Справа — отсканированный документ, записанный скорописью
Чтобы бегло читать такие тексты, необходимо иметь подготовку (в том числе моральную) или быть специалистом по транскрипции. А поскольку таких нерасшифрованных исторических текстов всё ещё много, стало закономерным появление и использование инструментов для автоматического распознавания кудзуси дзи. Стоит отметить, хоть машина и справляется с расшифровкой всё лучше и лучше, помощь человека всё же нужна.
Как работает интерфейс проекта?
«Минна дэ хонкоку» использует два типа программ, которые могут автоматически распознавать рукописные буквы: продукт от компании Toppan Printing и ИИ-модель Центра открытых данных в гуманитарных науках (CODH). Программы считывают скоропись, выделяя при этом те знаки, которые не смогли распознать, и вот здесь уже необходима помощь человека.
Любой пользователь может зарегистрироваться и помочь в расшифровке документов, а также оставить комментарии по поводу транскрипции или скорректировать работу других пользователей (см. Рис. 2).
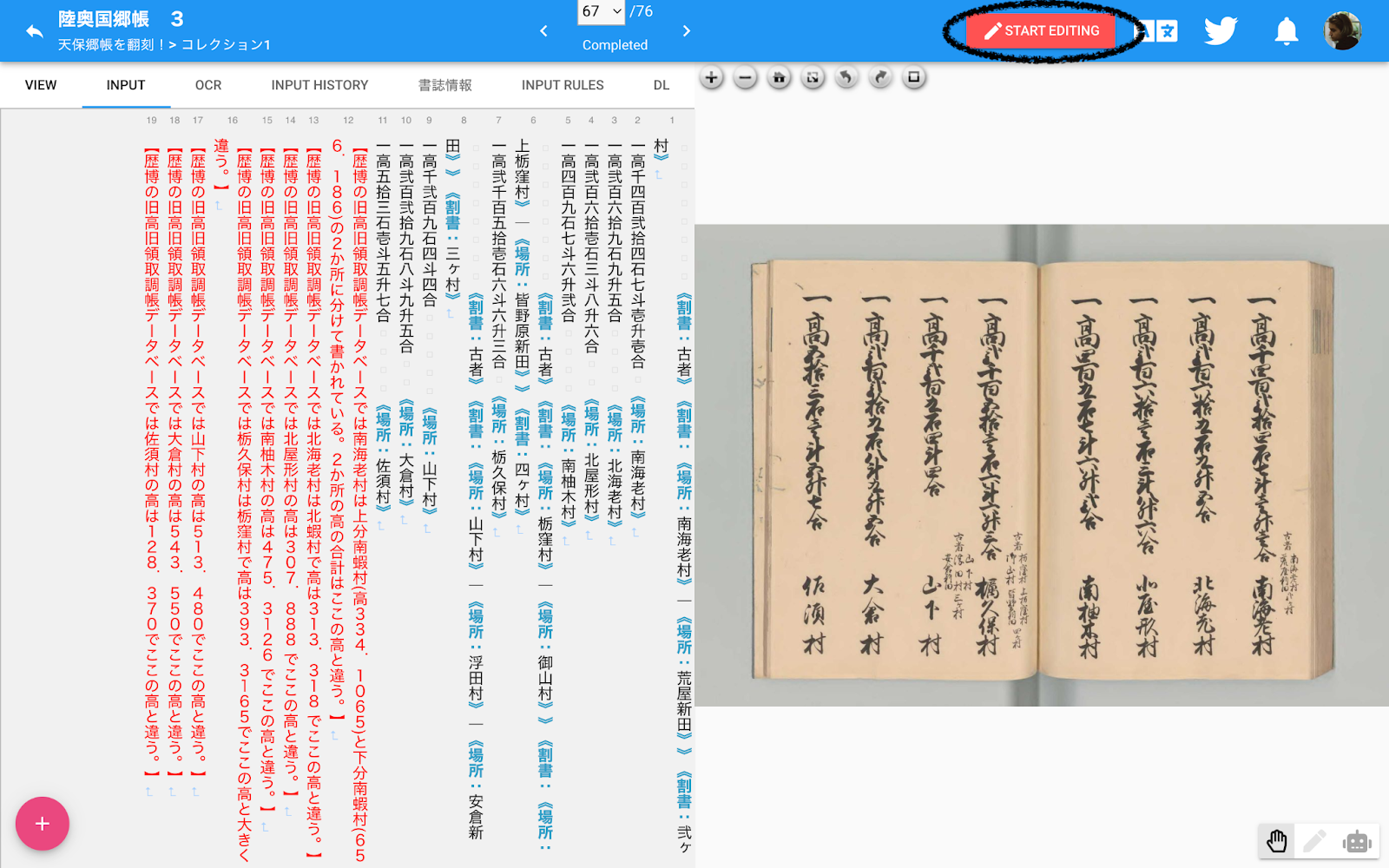
Рисунок 2. Красным цветом выделена неточная расшифровка текста, которую нужно доработать
Сбалансированный корпус письменного японского языка (BCCWJ)
Как отмечает лингвист, профессор Национального института японского языка Маэкава Кикуо [1], одна из главных проблем лингвистических исследований в японском языке на данный момент состоит в том, что не существует единого эталонного корпуса японского языка, который включал бы в себя широкий спектр текстовых данных. Поэтому Национальный институт японского языка (NIJL) с 2005 года ведёт проект по составлению сбалансированного корпуса письменного японского языка, в котором сейчас уже более 100 миллионов слов.
При создании сбалансированного корпуса важно обеспечить его репрезентативность. BCCWJ состоит из трёх подкорпусов (см. Табл. 1):
- Производственный подкорпус (книги, журналы, газеты, выпущенные в период с 2001 по 2005 гг.);
- Тиражный (библиотечный) подкорпус (опубликованные в 1980–2005 гг. книги, которые хранятся в библиотеках Токийского мегаполиса);
- Непопуляционный подкорпус (тексты официальных документов, тексты в интернете, в частности, интернет-портал Chiebukuro [2], протоколы Парламента Японии, опубликованные с 1975 по 2005 гг.).

Таблица 1. Левый верхний угол — Производственный подкорпус. Правый верхний угол — Тиражный (библиотечный) подкорпус. Нижняя часть таблицы — Непопуляционный подкорпус. Источник: Maekawa K. Design of a Balanced Corpus of Contemporary Written Japanese. 2007
В корпус попадают разные по длине отрывки из книг, журналов и газет: образцы фиксированной длины (1000 символов) и образцы переменной длины, обычно охватывающие раздел или главу, — 3900, 3000 и 1000 знаков для книг, журналов и газетных статей соответственно. Максимальная длина образца не превышает 10000 символов. Газетные образцы могут быть короче фиксированной длины. Их выбирают случайно, начиная с 1000 символа с начала статьи и со случайно выбранного знака (см. Рис. 3). Эти ограничения важны, так как существуют тексты без четкой структуры, например, длинные философские тексты без разделения на главы.

Рисунок 3. Пример образца фиксированной и переменной длины в случае газетной статьи. Иероглифы и буквы, использованные на рисунках и таблицах в газетах, в образец не включены. Рекламу также не используют. Источник: Maekawa K. Design of a Balanced Corpus of Contemporary Written Japanese. 2007
На Рис. 3 показан метод выбора образцов из газет, где статьи длиннее 1000 знаков. Берут случайно выбранную точку, затем определяют образец фиксированной длины в 1000 символов, начиная с этой точки. На рисунке пунктирные и сплошные линии обозначают образцы фиксированной и переменной длины соответственно.
Весь корпус BCCWJ закодирован с использованием японского набора символов, определённого как JIS X0213:2004, с использованием Unicode (UTF16LE) в качестве кода символов. XML используется в качестве основы обмена информацией.
Доступ к корпусу
Особый интерес вызывает доступ к корпусу, а точнее — уровни доступа к корпусу. Существуют три вида уровней (два из них названы по рангам VIII в.: сёнагон — младший советник императора, тюнагон — советник императора среднего ранга).
Онлайн-версию корпуса можно получить бесплатно для уровней:
- «Сёнагон» (без СМС и регистраций);
- «Тюнагон» (с регистрацией на сайте).
Полная версия корпуса BCCWJ платная:
- подписка на весь корпус на DVD-дисках.
Как получить доступ к корпусу?
Доступ «Сёнагон» можно получить без регистрации, но он предполагает только полнотекстовой поиск, т. е. поиск будет осуществляться по всему тексту, который содержит указанную строку. Например, если в строке указать 文学 (бунгаку, «литература»), то поисковик предложит не только это слово, но также 文学者 (бунгагуся, «литературовед / писатель / исследователь литературы»), 天文学 (тэнмонгаку, «астрономия»), 文学賞 (бунгакусё, «литературная премия») и т. д. Если проводить аналогию с русским языком, то при указании слова «метр» поиск выдаст «метр», «тонометр», «симметрия», «метро» и т. д.
Максимальная длина строки, которую можно найти при доступе «Сёнагон», составляет 10 символов.
Если пользатель хочет получить доступ «Тюнагон», то нужно зарегистрироваться на сайте. Однако это не совсем просто. Существует два варианта регистрации:
- через СМС и электронную почту. Пользователь нажимает «Зарегистрироваться», а затем указывает свою электронную почту и номер телефона. На почту придёт ссылка для дальнейшей регистрации, а на номер телефона в течение недели придёт СМС с кодом, который необходимо ввести для регистрации;
- через физическое письмо и электронную почту. На сайте пользователь оставляет заявку на регистрацию с указанием адреса проживания и электронной почты. Ссылка на регистрацию приходит на e-mail, а код будет отправлен письмом на указанный адрес в течение двух недель.
При доступе «Тюнагон» помимо простого поиска строк, для каждого корпуса предусмотрены различные функции поиска с использованием морфологической информации. Согласно сайту корпуса BCCWJ [3], доступ «Тюнагон» имеет срок годности, равный одному году онлайн-версии и двум годам для DVD. По истечении такого доступа он может быть автоматически продлён.
Третий вариант подразумевает покупку четырёх DVD-дисков с полным доступом ко всему корпусу. Подробнее о корпусе можно почитать здесь.
Подытожим: основные проекты кратко
- «Минна дэ хонкоку» — проект по расшифровке японских исторических книг. С помощью искусственного интеллекта и человеческой проверки сложные (а иногда просто невозможные) к прочтению книги становятся понятными для людей знающих и/или изучающих японский язык;
- Японская база данных исторических личностей — проект по сбору информации о японцах. Главное в нём — не просто даты, а взаимосвязи людей и их след в японской истории, приятный бонус — стилометрическая визуализация;
- Сбалансированный корпус письменного японского языка BCCWJ — проект по составлению эталонного корпуса японского языка, который необходим для изучения языка, с использованием компьютерных технологий.
Эти проекты общедоступны и вы можете в них поучаствовать сами (хотя на некоторых проектах необходимы регистрация и знание японского языка). Для людей, изучающих культуру Японии и японский язык, это большой плюс.
Официальные институции в японском Digital Humanities
Теперь кратко расскажем о главных институтах и ассоциациях, которые занимаются цифровыми гуманитарными исследованиями в Японии.
Japanese Association for Digital Humanities (JADH)
Japanese Association for Digital Humanities (JADH) — одно из самых полезных коммьюнити для цифровых гуманитариев в Японии. Здесь собраны актуальные новости о выпусках журналов про японский DH, конференциях, новостях. Проект создал «DH-календарь», с помощью которого удобно отслеживать мероприятия.
Digital Humanities Japan
Японские цифровые исследования (Digital Humanities Japan) — международное сообщество японистов-цифровых исследователей, которое начало свою деятельность с семинара в Университете Чикаго в 2016 году. Они организуют семинары и лекции в сфере японского DH. Кроме того, сообщество создало вики по Японским цифровым исследованиям.
National Institute of Japanese Literature (NIJL)
Национальный институт японской литературы (National Institute of Japanese Literature, NIJL) — это главный источник идей для проектов в области Digital Humanities в Японии. Многие проекты, о которых мы говорили выше, брали своё начало именно здесь. Институт занимается оцифровкой, хранением и исследованием культурных и исторических объектов, представляющих огромную ценность для Японии. Кроме того, институт проводит различные конференции и воркшопы.
International Institute for Digital Humanities
Международный институт Цифровых гуманитарных наук в Японии (International Institute for Digital Humanities) занимается в основном исследованиями буддийских текстов, рукописей и непосредственно Digital Humanities как отдельной дисциплиной для изучения.
Что ещё можно почитать
Напоследок подборка интересных статей и сайтов о японском DH.
Онлайн-журнал, который ведётся командой учёных, исследователей и библиотекарей, рассказывающих про свой опыт использования цифровых инструментов в гуманитарных науках. Часто делают обзоры на DH-проекты стран Азии и Африки.
Блог ведётся с 2019 года на японском языке и рассказывает о деятельности института, участиях в конференциях, о DH-исследованиях. Также здесь есть обзоры на публикации, связанные с буддизмом, литературой и Digital Humanities.
В гайд-статье Алексея Киселёва («Системный Блокъ») рассказывается о том, что такое Voyant Tools и как им пользоваться на примере японского корпуса текстов из YouTube.
Проект («плюралистический цифровой архив»), который интерактивно отображает последствия бомбардировки Хиросимы 6 августа 1945 года, используя 3D-моделирование. Пользователь может посмотреть панорамный вид на Хиросиму, прочитать рассказы выживших, посмотреть на фотографии и другие материалы, собранные из разных источников. Проект также подготовил аналогичные карты про бомбардировку Нагасаки, Великое японское землетрясение (2011 г.) и другие события
Источники:
- Maekawa, K. (2007, March). Design of a balanced corpus of contemporary written Japanese. In Symposium on Large-Scale Knowledge Resources. URL: https://www2.ninjal.ac.jp/kikuo/LKR2007KM.pdf (дата обращения: 29.11.2023).
- Chiebukuro — доска объявлений в браузере Yahoo!Japan, где любой пользователь может задать вопрос и получить на него ответ. Своего рода японские «Ответы mail.ru». URL: https://chiebukuro.yahoo.co.jp/ (дата обращения: 29.11.2023).
- Summary Balanced Corpus of Contemporary Written Japanese Language. URL: https://clrd.ninjal.ac.jp/bccwj/en/ (дата обращения: 29.11.2023).

