
Токенизация текстов на японском
Многие задачи, связанные с автоматической обработкой текста, начинаются с токенизации — деления текста на слова (токены). На самом деле, токенами могут быть не только слова, но и более мелкие или крупные единицы текста, однако на практике чаще всего используют именно деление на слова. Текст на русском языке, например, можно поделить на слова по пробелам. А что делать с текстом на японском языке, в котором между словами нет пробелов?
Одно из популярных решений — использование словаря, в котором прописаны леммы и их всевозможные словоформы, а также некоторые морфологические сведения. Так устроена библиотека fugashi. Для поиска наиболее вероятных границ слов fugashi использует алгоритм Витерби, который ищет наиболее вероятную последовательность из цепей Маркова. Другой подход для определения границ слов — использование нейронных сетей, однако такой вариант может оказаться довольно затратным по времени.
Как пользоваться fugashi
Сначала необходимо скачать библиотеку fugashi через командную строку с помощью команды:
pip install fugashi[unidic-lite]
- Импортируйте библиотеку fugashi и текстовый файл в своё рабочее окружение.
- Далее вызываем метод fugashi из класса Tagger() и сохраняем результат в переменную tagger.
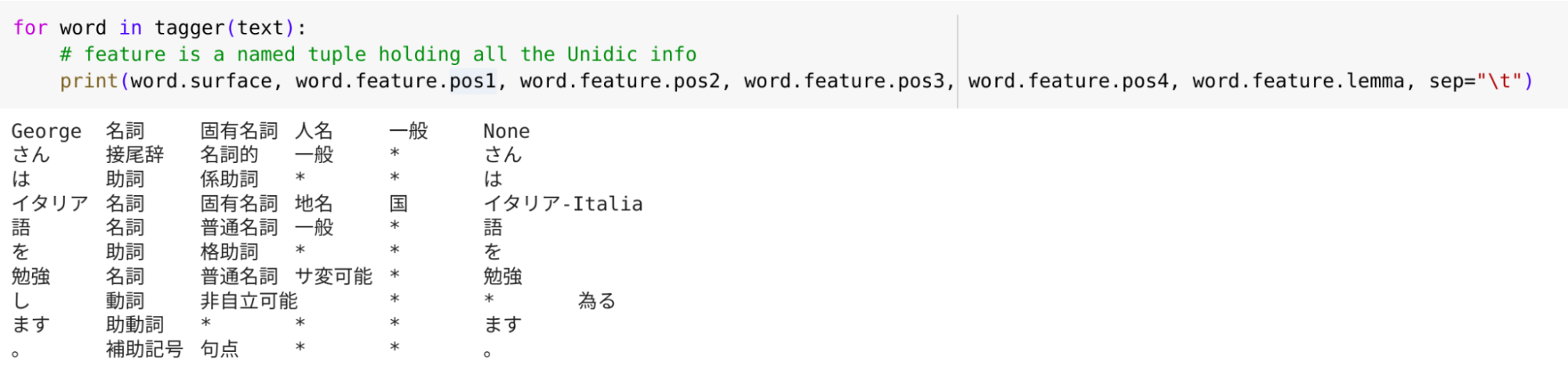
- Для токенизации передайте в созданный токенизатор свой текст. Результатом этой операции будет список специальных объектов типа fugashi.fugashi.UnidicNode. С помощью атрибута .surface можно получить токен в формате строки, что мы и хотели получить. А дополнительно заглянуть в морфологические характеристики каждого токена можно с помощью атрибута .feature: всего таких характеристик 26. Среди них часть речи, тип спряжения, лемма, чтение. Подробное описание всех характеристик можно найти тут.
Пример кода:
import fugashi
text = 'Georgeさんはイタリア語を勉強します。'
tagger = fugashi.Tagger()
words = [word.surface for word in tagger(text)]
print(words)
В результате мы получили список слов:['George', 'さん', 'は', 'イタリア', '語', 'を', '勉強', 'し', 'ます', '。']
Морфологический анализ в fugashi
Рассмотрим морфологические характеристики каждого токена подробнее:
- .feature.lemma позволяет получить лемму;
- .pos позволяет получить часть речи, это свойство возвращает четыре значения, пустые значения обозначаются *. Например, для токена 語 fugashi («язык») возвращает следующие значения: 名詞,普通名詞,一般,* (существительное, нарицательное, простое, *). Глагол 勉強します («изучает») разбит на три токена, хотя по сути является одним словом. Так происходит, потому что в японском языке многие глаголы образованы от существительных с помощью добавления глагола する («делать», します — вежливая форма в настояще-будущем времени). Для упрощения работы словаря глаголы разбиваются на составляющие части, это экономит память компьютера и вычислительное время. Так, токены для глагола «изучает» получились следующие:
勉強 名詞,普通名詞,サ変可能,* существительное, нарицательное, спрягается по форме サ, *
し 動詞,非自立可能,*,* глагол, используется после существительного, *, *
ます 助動詞,*,*,* глагольное окончание, *, *, *
- С помощью атрибута .pos можно также найти имена собственные. В нашем примере токен 日本 является именем собственным: 名詞,固有名詞,地名,国.
Если мы хотим найти все упоминания топонимов в тексте, то можно проверять токены на соответствие условию token.feature.pos3 == ‘地名’ (地名 означает «топоним»).
Пример кода, с помощью которого можно найти 20 самых частотных топонимов в тексте:
#let's input the text
filepath_of_text = r"Texts/695.txt" #Soseki's Sorekara
sorekara = open(filepath_of_text, encoding="utf-8").read()
#eliminate the spaces
import re
sorekara = re.sub(r'\s', '', sorekara)
#initialize a list for the place names
places = []
#now loop through the tokens and keep only the place names
for token in tagger(sorekara):
if token.feature.pos3 == '地名':
places.append(token.surface)
#use the Counter function to create a frequency table
from collections import Counter
place_name_tally = Counter(places)
#look at the top 20 most frequent place names
place_name_tally.most_common(20)
[('金井', 58),
('古賀', 44),
('児島', 29),
('東京', 17),
('向島', 14),
('吉原', 14),
('小菅', 13),
('安達', 12),
('日本', 10),
('独逸', 8),
('浅草', 6),
('上野', 5),
('希臘', 4),
('神田', 4),
('下谷', 4),
('仲町', 4),
('支那', 3),
('江戸', 3),
('小倉', 3),
('一条', 3)]Словарь UniDic для особых случаев
Если вы понимаете, что встроенного словаря unidic-lite не хватает для работы с текстом, то fugashi предлагает скачать на свой компьютер и использовать более подробные и объёмные словари UniDic. Можно выбрать словарь, исходя из текстов. Есть современный письменный, современный устный и одиннадцать видов словарей для классического японского:
- 近代口語小説UniDic
- 旧仮名口語UniDic
- 近代文語UniDic
- 近世江戸口語UniDic
- 近世上方口語UniDic
- 近世文語UniDic
- 中世口語UniDic
- 中世文語UniDic
- 和歌UniDic
- 中古和文UniDic
- 上代語UniDic
Чтобы воспользоваться словарём, нужно скачать его на свой компьютер и прописать адрес к нему при вызове класса Tagger():
tagger = fugashi.Tagger('-d path_to_folder/UniDic-kindai_1603')Источники
- Paul McCann. 2020. fugashi, a Tool for Tokenizing Japanese in Python. In Proceedings of Second Workshop for NLP Open Source Software (NLP-OSS), pages 44–51, Online. Association for Computational Linguistics.
- Библиотека Fugashi [Электронный ресурс]. URL: https://pypi.org/project/fugashi/ (дата обращения 19.03.2024).
- Словарь UniDic [Электронный ресурс]. URL: https://pypi.org/project/unidic/ (дата обращения 19.03.2024).
- Типы словарей семейства UniDict [Электронный ресурс]. URL: https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_chj (дата обращения 19.03.2024).

