
Оптическое распознавание символов (англ. optical character recognition, OCR) — это технология, которая преобразовывает отсканированный текст из изображения в машиночитаемый печатный текст. Сейчас OCR широко применяется в различных сферах: упрощает документооборот в компаниях и оптимизирует бизнес-задачи; встраивается в приложения, которые мы используем в повседневной жизни, например, в машинный перевод текста с фотографии; а также применяется исследователями-гуманитариями для работы с текстами.
В этой статье мы поговорим о том, как использовать OCR для распознавания японского текста и какие исследовательские задачи можно решить с помощью одной из таких моделей.
OCR существует достаточно давно, и сегодня нам доступны многие модели, которые успешно распознают печатный текст. Причём распознавать можно не только алфавитное письмо, такое как латиница или кириллица, но и иероглифическое письмо, которое используется в японском и китайском языках. С рукописным текстом сложнее. Если мы хотим исследовать старые японские рукописи с помощью компьютерных методов, то такие модели не смогут адекватно распознать иероглифы.
Кудзусидзи
Классический японский язык, на котором написаны главные исторические источники с VIII по XIX век, сильно отличается от современного японского языка. Многие современные иероглифы упростили, поэтому в старых текстах могут встречаться более сложные иероглифы, которые современные модели OCR могут не узнать, или на один современный иероглиф может приходиться несколько старых вариантов.
Ещё одна сложность в распознавании древних текстов — это скоропись. Иероглифы не разделены на отдельные символы, а плавно перетекают из одного в другой. А ещё текст необязательно последовательный, он может огибать иллюстрации или зависеть от толщины кисти.
Такую старую систему записи называют кудзусидзи. Кудзусидзи сложно распознавать не только компьютеру, но и человеку. Не каждый носитель японского языка в состоянии прочитать кудзусидзи. Чтобы прочитать старые японские тексты, нужно специально этому учиться. Получается, что есть очень много нерасшифрованных древних японских текстов на разные темы, которые может прочитать и перевести на современный язык только узкий круг исследователей. Для облегчения их работы предпринимаются попытки расшифровать кудзусидзи с помощью моделей OCR.
О том, как в Японии привлекают волонтёров для расшифровки старых текстов, мы писали в этом материале.
KuroNet для распознавания японских иероглифов
KuroNet — это модель OCR, специально обученная для распознавания кудзусидзи, которая учитывает следующие особенности древних японских текстов:
- текст непоследовательный: многие модели OCR работают с заведомо выровненным текстом, когда мы точно знаем, например, что после первой строчки надо читать вторую и что слова в каждой строчке следуют последовательно слева направо. Это в чём-то улучшает работу по распознаванию слов, ведь можно использовать окружающий контекст для улучшения предсказаний. Кудзусидзи представляет собой непоследовательную запись, иногда следующий иероглиф расположен не строго ниже предыдущего, а где-то вокруг иллюстрации, или следующая строка может быть не слева, а справа. Поэтому модель KuroNet распознает каждый символ индивидуально, хотя на контекст тоже смотрит: в некоторых случаях значение символа может зависеть от того, какой символ стоит до или после него;
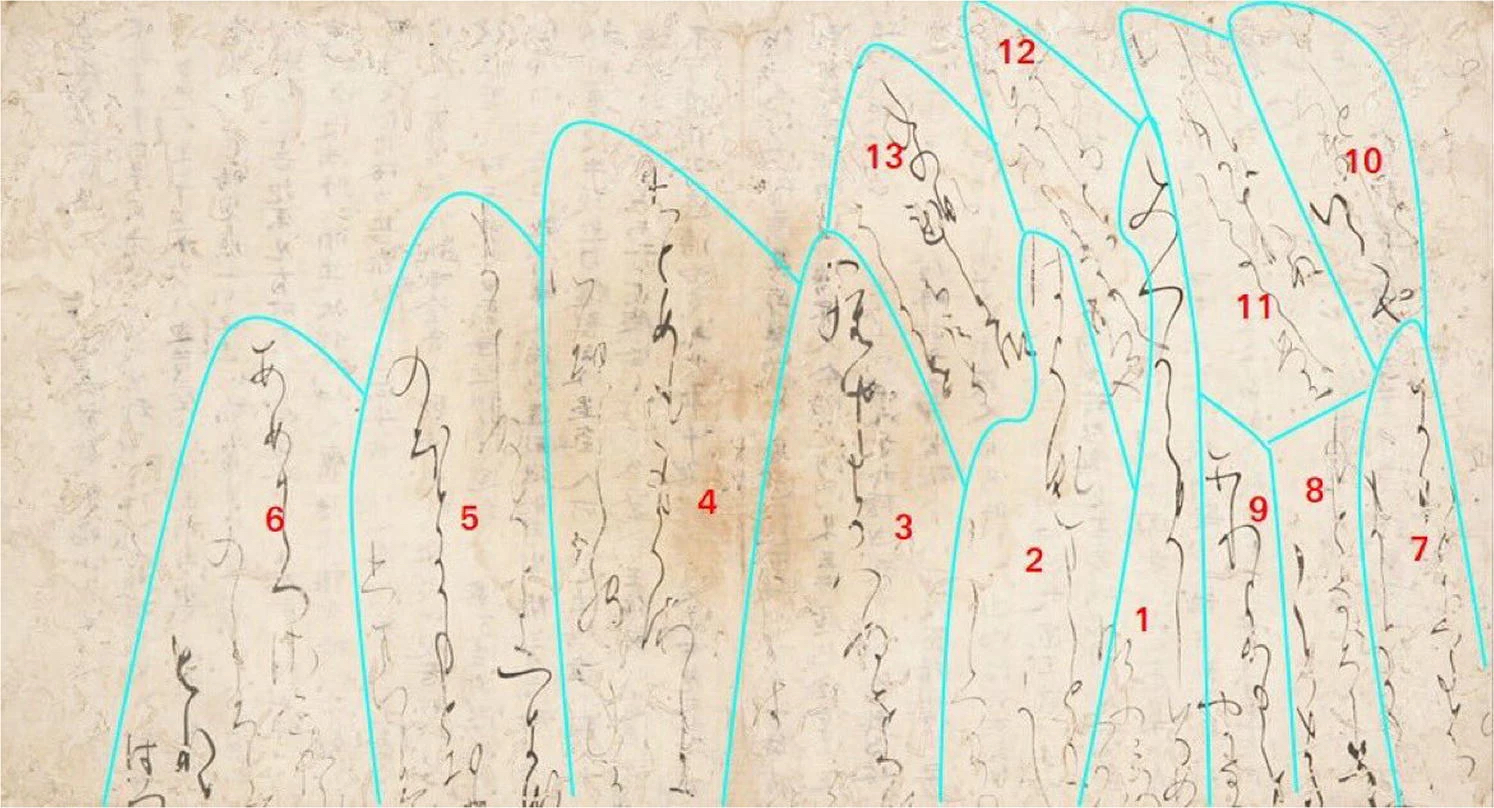
- курсив: для рукописных текстов задача распознавания символов ещё сложнее — нужно не только понять, какой символ написан, но и определить его границы, то есть решить задачу сегментации. Это довольно сложный процесс, который требует много памяти и вычислительного времени. KuroNet упрощает эту задачу тем, что перед тем как классифицировать, какой символ представлен на изображении, модель сначала определяет, есть ли вообще на данном изображении текст, или это фон, или иллюстрация, и если есть текст, то далее определяет возможные границы символа и распознаёт сам символ;

- фуригана: в японских текстах часто подписывают чтение некоторых сложных иероглифов, такие аннотации называются фуригана и пишутся мелким шрифтом справа от слова при вертикальном письме. Фуригана во многом облегчает понимание текста обычным людям. А вот для компьютера это может стать проблемой, потому что модель может принять фуригану за элемент иероглифа;

- большое количество символов: в отличие от других языков, в японском, как и в китайском, многие слова записываются иероглифами, поэтому распознавать нужно не 30 букв алфавита, а порядка 4000 иероглифов. Некоторые из этих иероглифов могут встретиться всего пару раз во всём тексте, и несмотря на это, для каждого обнаруженного символа на изображении модель будет считать вероятность сходства на каждый из возможных иероглифов в обучающем датасете;
- хэнтайгана: термином хэнтайгана обозначают различные написания символов хираганы, которые появились из-за рукописных записей. Хэнтайгана характерна для старых японских текстов, как раз таких, с которыми работают для изучения кудзусидзи. Это означает, что для того, чтобы модель по распознаванию старых японских текстов работала успешно, она должна использовать мультимодальное распределение (учитывать разные варианты написания) для каждого символа.
Как обучен KuroNet
KuroNet использует архитектуру U-Net для обработки изображений. U-Net — это свёрточная нейросеть, которая изначально была разработана для задач сегментации изображений в биомедицине. Благодаря высокой точности архитектуру можно использовать и в других сферах, например, можно определять, где на изображении находится текст и как можно этот текст поделить на отдельные символы. Своё название сеть получила из-за того, что внешне очень похожа на букву U.
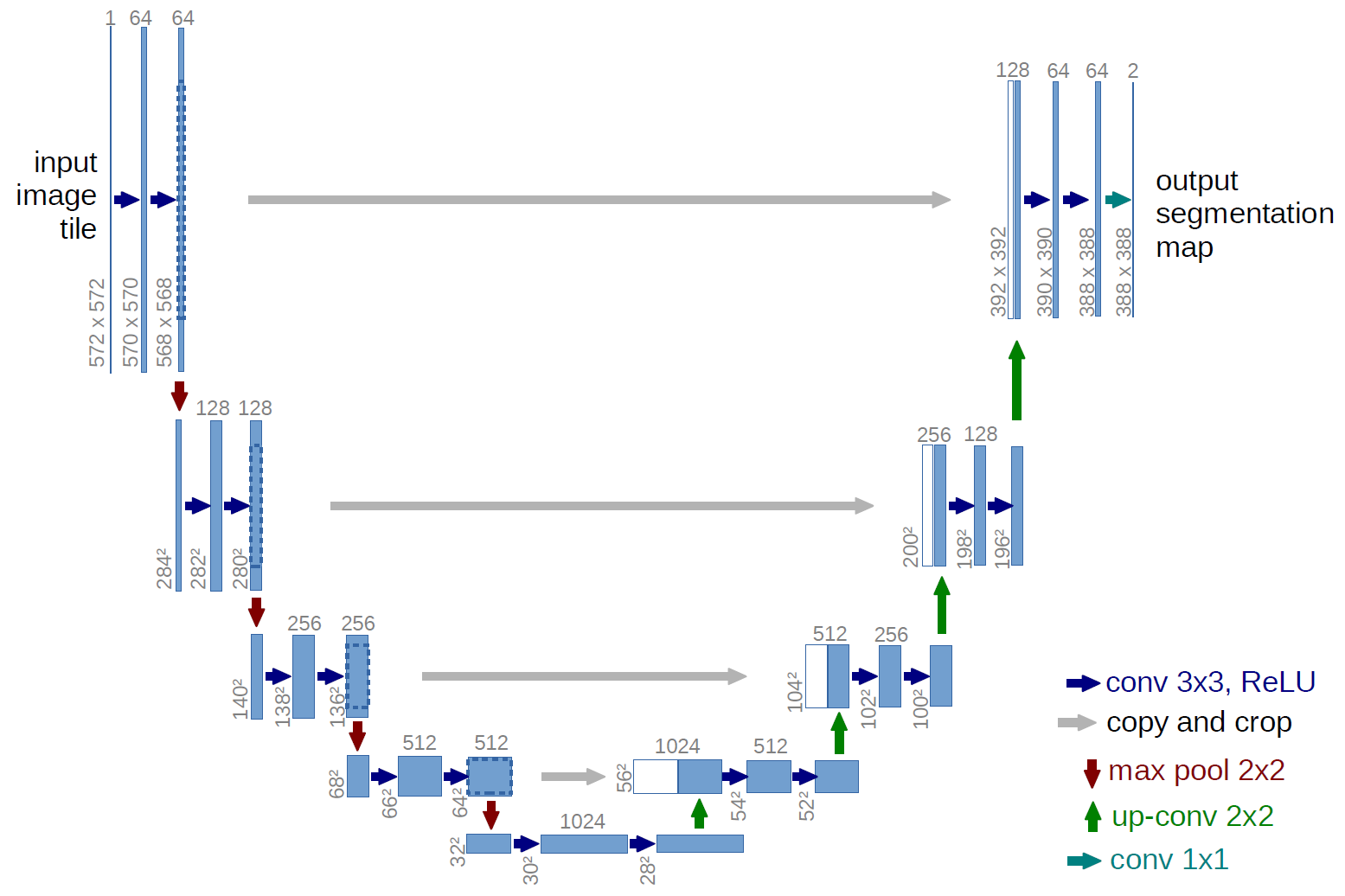
Архитектура нейросети U-Net. Источник: https://arxiv.org/abs/1505.04597
Архитектура состоит из слоёв энкодера и декодера. Проще говоря, сначала мы постепенно сжимаем изображение и сохраняем разметку на каждом этапе, а затем постепенно разворачиваем изображение до исходного размера, складывая разметку на текущем этапе с результатом разметки того же уровня из первого шага.
KuroNet обрабатывает изображение размера 976х976 пикселей с помощью U-Net и получает на выходе 64 признака для сегментации каждой точки. Используя эти признаки, модель считает вероятность того, что на данной позиции находится текст или фон. Если на данной позиции скорее всего находится текст, то после этого модель пытается определить, какой именно символ может быть изображён. Затем точки, соответствующие одному символу, группируются вместе, и с помощью алгоритма DBSCAN подбирается наиболее подходящее совпадение. Кроме того, KuroNet использует нормализацию групп и регуляризацию, чтобы избежать переобучения модели.
Как работать с KuroNet
Особенность KuroNet заключается в том, что он построен на стандарте IIIF (International Image Interoperability Framework, Международная концепция интероперабельности графических образов). Этот стандарт, разработанный в 2012 году, появился для того, чтобы пользователи онлайн-коллекций музеев, библиотек и архивов могли не просто просматривать изображения, но и работать с ними: создавать коллекции, подписывать аннотации, делать OCR. Подробнее о нём можно узнать по ссылке.
Для того чтобы воспользоваться KuroNet, необходимы следующие шаги:
1) заходим по ссылке: http://codh.rois.ac.jp/kuronet/iiif-curation-viewer/;
2) регистрируемся (при помощи соцсетей или электронной почты), нажав на Login в правом верхнем углу экрана. При необходимости можно переключить язык;
3) перед нами открылось окно IIIF Curation Viewer. Находим IIIF (в формате .json) и вставляем ссылку на желаемый текст.
Внимание: просто загрузить картинку или файл не получится — нужна онлайн-библиотека, которая поддерживает IIIF. В качестве примера мы возьмём изображение из Японской парламентской библиотеки — гравюру Цукиока Ёситоси из серии «Сто видов луны». IIIF URI будет находиться справа внизу и выглядеть вот так:
4) Теперь перед нами открыт документ.
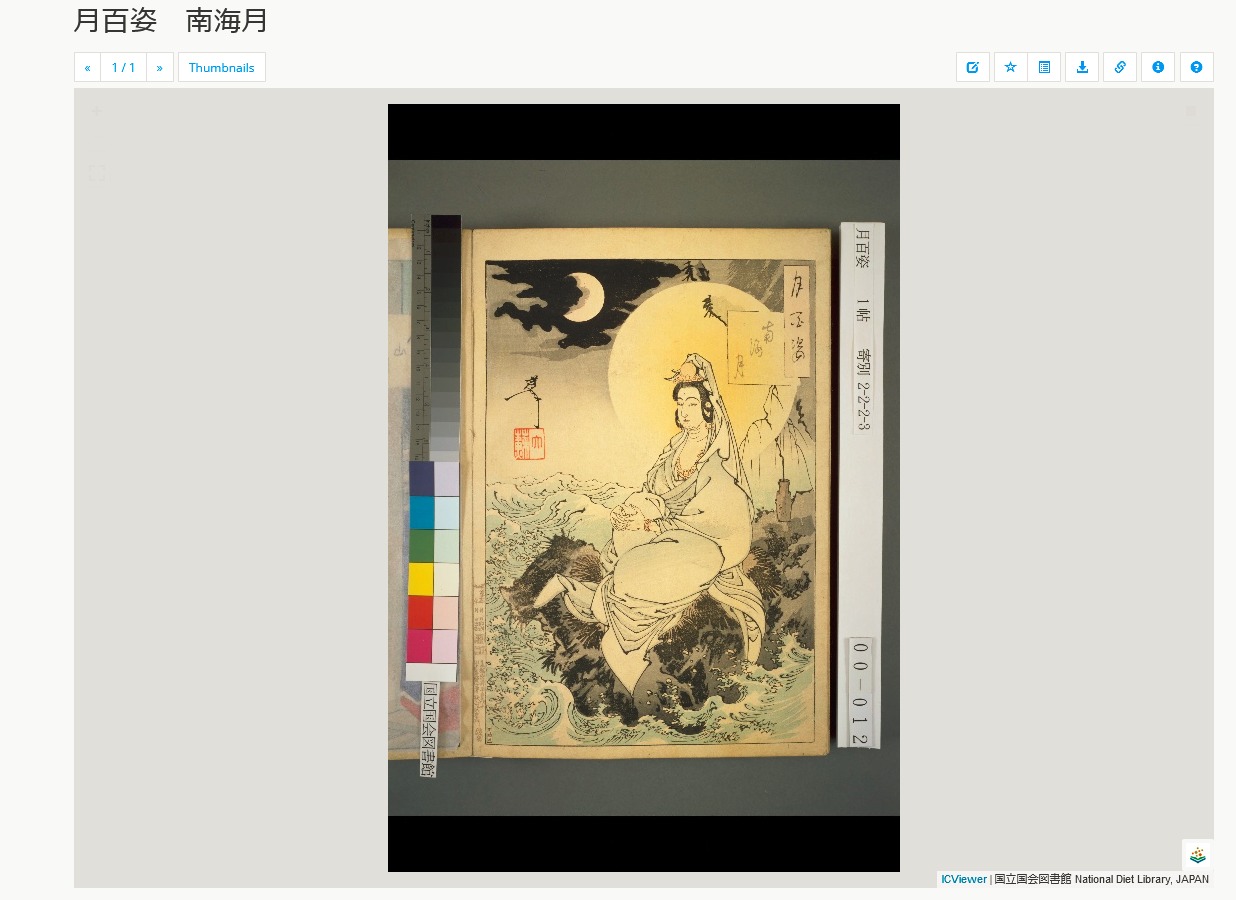
При необходимости мы можем выбрать отдельную страницу. Справа находится панель инструментов.
Чтобы воспользоваться KuroNet, наводим курсор на зону изображения. Под панелью инструментов появится чёрный квадрат с надписью Draw a rectangle.
Рисуем квадрат над надписью, которая нас интересует.
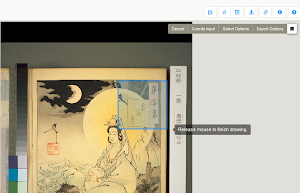
После клика на нарисованный квадрат выбираем KuroNet Kuzushiji Recognition Service — в отдельной вкладке откроется дашборд.
5) Дальнейшее распознавание текста ведётся на японском языке. Когда открывается дашборд, перед нами появится окно со следующим текстом:

Слева направо можно увидеть следующие графы:
領域指定画像 (рё:ики ситэй гадзо:) — это область картинки, которую мы выбрали для распознавания.
くずし字OCR (кудзуси-дзи OCR) — распознавание скорописи.
自動テキスト化 (дзидо: тэкисуто-ка) — автоматическое распознавание текста.
手動テキスト化 (сюдо: тэкисуто-ка) — ручное распознавание текста.
6) В графе くずし字OCR нажимаем на 予約:実行 (ёяку: дзико; предварительно: выполнить), чтобы провести предварительное распознавание текста. После этого наш дашборд будет выглядеть вот так:

Фраза 成功:閲覧 (Сэйко:: эцуран; Успех: просмотр) в конце второй графы означает, что распознавание прошло успешно. Нажав на неё, мы получим доступ к окошку IIIF Curation Viewer с уже распознанным текстом:

Однако такое распознавание только указывает на положение иероглифов в тексте. Функция 自動テキスト化 (автоматического распознавания текста) позволяет получить текст в порядке расположения (вертикальном или горизонтальном), а функция 手動テキスト化 (ручного распознавания текста) поможет внести правки.
Нажимаем на 処理:実行 (сёри: дзико:; обработка: выполнить) в графе автоматического распознавания текста (自動テキスト化), а в открывшемся окне на テキスト化を実行する (тэкисутока-о дзико: суру; выполнить обработку текста), тогда мы увидим следующий результат:

Знатоки японского могут увидеть, что текст оказался распознан не совсем точно. Вместо 月百姿 南海月 у нас получилось 月一次次の 海月. То есть иероглифы 百姿 оказались распознанными неправильно, а 南 вообще не распознался. Кроме того, появились лишние иероглифы: 製.
На самом деле сами разработчики указывают на ограничения: ксилографические книги распознаются легче, чем рукописи. Для примера посмотрим два конкретных текста из Японской парламентской библиотеки:
1. Страницу из книги «Катава-мусумэ» (かたわむすめ) Фукудзавы Юкити.

Получившийся результат:
にてぬりたるやうなれども近悪世間の人は尚
これにこゝろづかずたま〱目にとまることあ
るも珍しからぬむしばにもあらんなどとて噂
するものもあらず唯両親はとくよりこれを患
ひ世に不具なるものも多き中に眉毛のなきも
のかては古来人の話に聞しこともなくあまつ
さへはじめてはへし歯の黒きとは以かなる因
縁なるやと人しらずひとり心を悩ませしかど
もなほ親の欲目にて眉毛は兎もあれ歯ははへ
2. Стихотворение Оно-но Комати из антологии «Хякунин-иссю» («Сто стихотворений ста поэтов»).

Получившийся результат:
花の色は
うつりに
けりな
いたら
づに
我身
よにふる
ながめ
し
せまに
В целом, KuroNet достойно справился с распознаванием этих текстов, тем не менее, есть некоторые неточности. Так вместо 近悪 в первом тексте должно быть 近処. Что касается стихотворения Оно-но Комати, то здесь KuroNet не совсем точно распознал строку: вместо しせ в двух последних строках должно быть せし.
Приложение miwo
Что делать, если у текста, который вы хотите распознать, нет IIIF и он вообще находится не в цифровом виде? На помощь может прийти приложение miwo, основанное на KuroNet, которое можно скачать с GooglePlay или AppStore.
Интерфейс приложения miwo на японском языке.

Открыв приложение, мы увидим кнопки для четырёх образцов (サンプル). Внизу находятся кнопки コメント (комментарии), テキスト (текст), アルバム (галерея) и カメラ (камера). При помощи последних двух мы можем получить изображение для распознавания. Попробуем взять один из образцов.

Для распознавания стоит нажать зелёную кнопку внизу в центре. После текст, как и в KuroNet, отобразится на изображении.

Нажав на кнопку テキスト(текст), вторую справа, можно получить сплошной текст и скопировать его (コピー).

Так при помощи приложения miwo можно распознать японские рукописи прямо с телефона.
Заключение
KuroNet — это модель оптического распознавания символов японского языка, которая специально обучена для работы с рукописными текстами. Модель помогает исследователям-японистам в распознавании старых японских текстов, которые имеют свои особенности. В таких текстах нет современных японских иероглифов, а есть их более сложные, старые варианты, из-за чего современные модели компьютерного зрения не справляются с такой задачей. Кроме того, все эти тексты рукописные, иероглифы соединены друг с другом, а написание может меняться в зависимости от толщины кисти или индивидуального стиля рукописца.
Ещё одна сложность — текст не всегда последовательный, то есть следующая строчка может быть как слева, так и справа, или вообще может огибать картинку. KuroNet учитывает все эти особенности и позволяет распознавать старую японскую рукопись довольно точно. KuroNet можно попробовать самим: на сайте или в приложении miwo.
Источники
- Lamb, A., Clanuwat, T. & Kitamoto, A. KuroNet: Regularized Residual U-Nets for End-to-End Kuzushiji Character Recognition. SN COMPUT. SCI. 1, 177 (2020). URL:
https://doi.org/10.1007/s42979-020-00186-z (дата обращения: 26.01.2024). - Ronneberger, O., Fischer, P., Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. In: Navab, N., Hornegger, J., Wells, W., Frangi, A. (eds) Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. MICCAI 2015. Lecture Notes in Computer Science, vol 9351. Springer, Cham. URL: https://doi.org/10.1007/978-3-319-24574-4_28 (дата обращения: 26.01.2024).

