
Язык — одна из самых сложных известных нам систем. При этом мы почти не задумываемся о его сложности, пока не сталкиваемся с иностранным языком и видим степень различия: ведь, к примеру, совсем не очевидно, что постановка определённого артикля — это операция, необходимая для выражения мысли на английском, немецком и прочих языках с артиклями. Лингвисты-типологи изучают, насколько языки мира похожи друг на друга и какие лингвистические явления в них вообще встречаются.
Что такое лингвистическая типология и с чем её едят
Известно, что в мире сейчас существует (по разным подсчётам) около 7000 языков. Сопоставляя лишь крупнейшие из них, мы уже можем увидеть серьезные различия. Скажем, в китайском языке присутствует такое явление, как тоны — это использование высоты звука в языке для различения лексического или грамматического значения. Такие явления не знакомы носителям европейских языков. А если сравнивать все языки мира, включая малые (например, адыгейский или язык индейцев пираха), высока вероятность обнаружить ещё более необычные и редкие явления. Но какой подход нужно выбрать лингвисту, желающему описать всё это многообразие?
Языковые явления можно разбить на условные уровни. Есть фонетический уровень — к нему относятся звуки речи и их возможные комбинации. Есть морфологический — о значимых частях слова (морфемах) и том как они меняют значение слова или помогают образовать новое (впрочем, иногда значение слова меняется не из-за добавления морфем, а из-за более сложных операций, но это отдельная непростая тема, которой мы касаться не будем). Есть синтаксический — на нём слова комбинируются в предложения, устанавливаются «связи» между отдельными словами, чтобы сформировать полноценное высказывание. Есть лексический — о значениях отдельных слов вне зависимости от грамматики, больше всего эти значения похожи на привычные нам словарные описания.
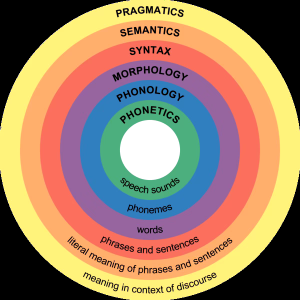
Уровни лингвистической структуры (один из вариантов выделения). Источник
На каждом из этих уровней языки могут кардинально различаться. Рассмотрим фонетическую и морфологическую типологию.
Фонетическая типология
Возьмём наиболее осязаемый уровень — фонетику. Наиболее осязаемый он потому, что фонетику довольно удобно описывать в биологических и акустических терминах (какие речевые органы задействованы в процессе произнесения звука, к примеру: гортань, язык, зубы, трахея, глотка, лёгкие; какая частота и амплитуда у звуковой волны). Например, русский звук [б] можно описать как билабиальный (губно-губной) взрывной. Это значит, что для его образования собирается воздух, а потом резко выпускается движением губ.
Уже на уровне фонетики мы можем обнаружить разительные отличия между языками мира. Скажем, в языках Южной Африки присутствуют особые звуки — кликсы, «щёлкающие» звуки. Пример кликса — билабиальный (то есть образуемая губами) кликс из языка къхонг. Здесь для образования звука необходимо произвести особое движение губами.
Пример звучания щёлкающих согласных (также см. в Википедии)
В большинстве языков мира такие звуки не являются частью фонологической системы. Говоря простыми словами, с их помощью не образуются новые морфемы и слова.
Другие кликсы можно послушать на сайте https://www.ipachart.com/ в разделе Clicks: среди них есть как раз билабиальный, зубной и другие.
Морфологическая типология
Обратимся к морфологии. Тут существует множество интереснейших явлений, но мы рассмотрим именную инкорпорацию. Чтобы разобраться с ней, кратко обсудим теорию семантических ролей (она нам ещё пригодится в следующей части заметки). В лингвистике есть группа теорий, построенных на том, что у нас имеется предикат (чаще всего глагол), а остальные участники ситуации в зависимости от него выражают различные семантические роли. Рассмотрим на простом примере. В предложении «Петя бьёт собаку палкой» мы видим трёх участников: Петя, собака и палка. Петя выступает агенсом (активным участником, осуществляющим действие), собака — пациенсом (тем, на кого направлено действие), а палка — инструментом (с помощью чего осуществляется действие). Как мы видим, в русском языке для описания этой сложной ситуации требуется составить целое предложение из четырёх слов (по одному на предикат и каждую роль). Но что если морфологические свойства языка дают возможность использовать меньше слов?
Тут в дело и вступает именная инкорпорация. Проще всего пояснить её механизм на конкретном примере:
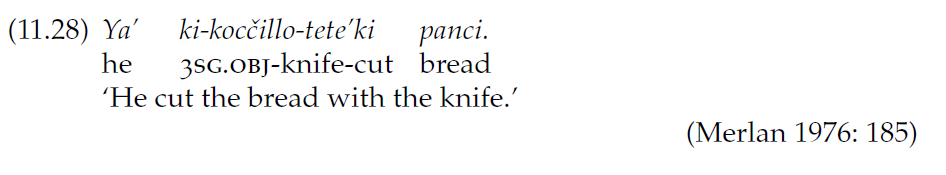
Пример из языка науатль
В этом примере из языка науатль предложение «Он порезал хлеб ножом» состоит всего из трёх слов, потому что одна из ролей (инструмент) добавилась к глаголу «резать» в качестве аффикса -tete-.
А вот ещё один пример, на этот раз из понпейского языка (один из языков Океании):
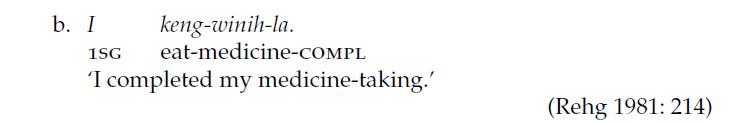
Пример из понпейского языка
Здесь пациенс (лекарство) вошло в глагол «есть» (в русском тут использовался бы глагол «принять», но для примера это не особенно важно).
Ареальная типология: пример с редупликацией
Впрочем, типологи не удовлетворяются просто наличием языкового разнообразия. Описав явления в одном языке, они идут дальше, сопоставляя данные из разных языков и стараясь найти закономерности в том, как функционирует языковое разнообразие вообще. Одна из областей исследования, связанных с этой проблематикой, — ареальная типология. Она занимается поиском языковых ареалов — групп расположенных рядом языков, которые обладают схожими явлениями на различных уровнях языка.
Примером ареального явления послужит редупликация. Выше мы кратко упоминали, что морфология не всегда связана с добавлением к слову морфемы, потому что существуют более сложные операции. Редупликация — одна из таких операций. Кратко её можно описать как полное или частичное повторение части основы для образования нового слова (или новой формы слова).
Редупликация есть и в русском, например, в слове «шашлык-машлык», но она применяется сравнительно редко, а также не используется для образования форм слова. А вот, например, в языке мангап-мбула (один из языков Папуа — Новой Гвинеи) с помощью частичной редупликации (в данном случае повторения пары гласный + согласный в конце основы) образуется форма глагола, обозначающая продолжительность:

Пример из языка мангап-мбула
Посмотрим на карту про редупликацию из World Atlas of Linguistic Structures (Всемирный атлас языковых структур).
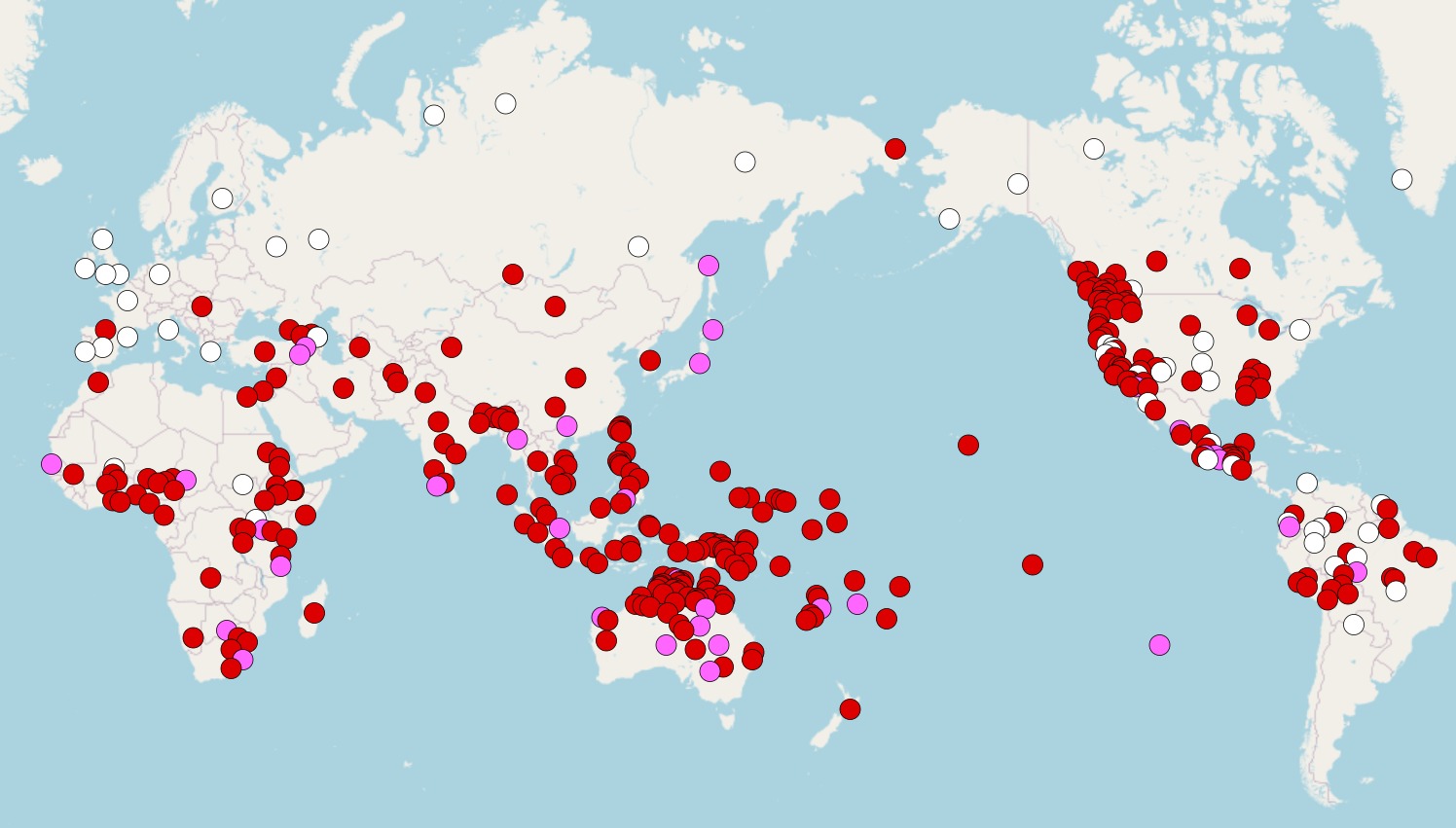
Карта о типах редупликации в языках мира
Красным на карте обозначены языки, в которых есть и полная, и частичная редупликация; сиреневым — языки, в которых есть только полная редупликация; белым — языки, в которых редупликация непродуктивная (то есть почти не используется).
Эта карта наглядно показывает нам, как языки с редупликацией объединяются в ареалы. Выделяются, например, языки Океании (к которым относится и рассмотренный ранее мангап-мбула), языки Западной Африки, языки западного побережья Северной Америке и многие другие. Европейские языки тоже образуют своеобразную группу, только для них общим признаком является отсутствие редупликации (запомним, что технически об ареальных чертах можно думать и так, потом нам это пригодится).
Стоит оговориться, что языковые ареалы выделяются по совокупности признаков, а не одному конкретному. Из-за этого вопросы о границе ареала и количестве общих черт, которое необходимо, чтобы точно говорить об образовании ареала, нередко становятся предметами дискуссий. В следующем разделе мы поговорим о том, что вычислительные методы могут привнести в эти дискуссии.
Отдельно важен для ареальной типологии вопрос о том, связана ли общность черт внутри ареала с тем, что языки произошли из одного языка-предка, или с тем, что они повлияли друг на друга за время нахождения рядом (этот процесс также называется языковой конвергенцией).
А как что-то посчитать в ареальной типологии?
Как на вопросы ареальной типологии можно отвечать с помощью вычислительных методов? Исследователи строят общую картину на основе данных, чтобы затем было понятнее, в какие аспекты стоит углубиться (это сравнимо с дальним чтением в Digital Humanities). Применительно к ареальной типологии можно представить типологическую информацию в форме вектора.
За этим стоит следующая идея. Попробуем выделить набор лингвистических признаков языка — как раз тех черт, о которых мы говорили в прошлом разделе. Причём постараемся превратить их в вопросы, на которые можно ответить «да» или «нет», а в некоторых случаях добавляют вариант «нет данных». Например, «есть ли в языке двойственное число».
Расположив эти признаки в едином для всех исследуемых языков порядке, мы можем получить вектор, представляющий язык в виде набора нулей и единиц. Ведь слова «да» и «нет» легко превратить в числа, всего лишь заменив их на 1 и 0 соответственно. К полученным векторам несложно применить алгоритмы кластеризации.
Подобное исследование проводили для языков южной Азии исследователи из университета Гётеборга в Швеции. Они опирались на данные Linguistic Survey of India — сборника описаний языков Индии от начала XX века . Данные отражают состояние грамматики языков на начало XX века, но из более современных исследований языков Южной Азии известно, что многие признаки всё же сохранились, а значит, данные достаточно релевантные.
Для каждого языка указывались его основные морфологические и фонетические черты, а также короткие разобранные тексты на этом языке. Как отмечают сами исследователи, прошлые попытки использовать эти данные в ареальных исследованиях приводили к весьма скромным результатам из-за краткости описаний, но применяя вычислительные подходы удалось прийти к интересным и значимым выводам.
Чтобы упростить обработку результатов, учёные составили список из вопросов для 72 черт, описанных в Linguistic Survey of India. В качестве возможных вариантов принимались «да», «нет» и «нет данных». Материалы собрали в таблицу, а затем к ним применили алгоритмы кластеризации и визуализировали результаты.
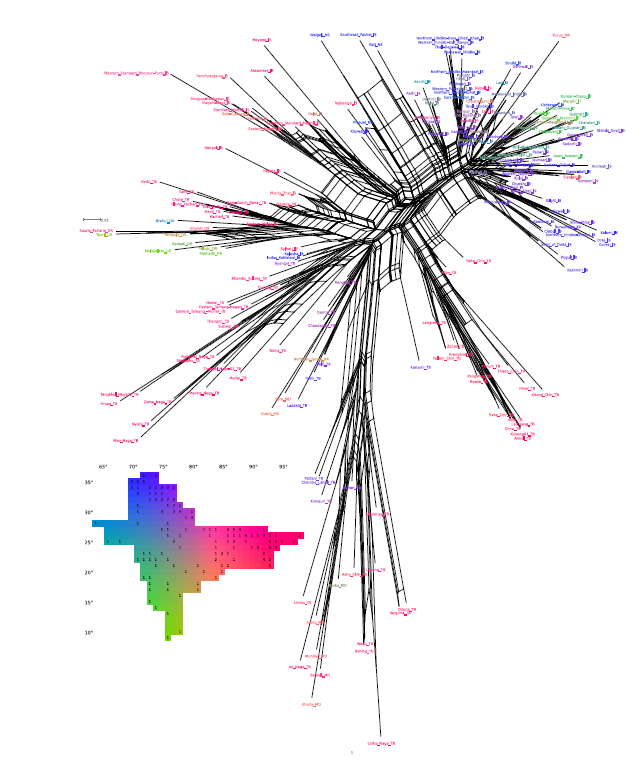
Визуализация результатов исследования языков Юго-Восточной Азии (A bird’s-eye view on South Asian languages through LSI)
Полученные диаграммы позволили наблюдать некоторые неочевидные закономерности. Так, обнаружилось, что нуристанские языки, которые не принадлежат к индо-арийской ветви (в отличие от большинства других исследовавших языков), при визуализации результатов оказываются к ним близки.
На графике выше показано как распределяются языки по итогам кластеризации, какие значимые группы они образуют.
Чем тут помогает NLP
Теперь вы знаете, как на материале грамматических описаний лингвисты составляют базы данных для вычислительных типологических исследований. При этом разобраться в грамматике даже одного языка — задача трудоёмкая (особенно если вспомнить, что многие грамматики составлялись давно, а значит, могут быть неточными или содержать устаревшую терминологию). Поэтому некоторые исследователи обращаются к методам Natural Language Processing (NLP, обработка естественного языка), чтобы ускорить процесс создания базы и покрыть большую выборку языков.
Существует много техник извлечения информации из текста, так называемого семантического парсинга. В этой статье мы попробуем разобрать только одну, в достаточной степени основанную на лингвистике, а не чисто машинном обучении. Эта техника построена вокруг уже встречавшейся нам теории семантических ролей.
Всё те же шведские исследователи попробовали решить задачу для нескольких конкретных лингвистических явлений: в каком порядке идут существительное и числительное, стоит ли прилагательное перед существительным, согласовывается ли прилагательное с существительным по числу и падежу, есть ли в языке определённые артикли.
Отобрав те грамматические описания, которые им подходили (были написаны на английском языке и содержали информацию о нужных чертах), они разбили описания на предложения и с помощью парсера Propbank извлекли из каждого предложения список предикатов их аргументов.
Сам Propbank работает на основе бинарных и мультиклассовых классификаторов (подробнее о том, как устроены такие модели, можно почитать здесь). Эти классификаторы были обучены на наборе пар предикатов и их аргументов с некоторыми дополнительными параметрами: порядок слов, соседние слова, части речи и другие).
Попробуем пояснить следующий шаг алгоритма на примере. Допустим, исследователи хотят извлечь информацию о том, идёт ли прилагательное перед существительным. Для этого они берут предложение The adjectives follow the noun they qualify («Прилагательные следуют за существительным, которое определяют»). Разберём его структуру с помощью теории семантических ролей. В нём есть предикат follow («следовать»), который имеет два основных аргумента: adjective («прилагательное») как субъект/агенс, то есть тот, кто выполняет действие «следовать», и noun («существительное») в качестве объекта/пациенса, то есть тот, за кем следуют. Получаем удобную структуру: предикат follow, субъект adjective и объект noun. Затем, когда алгоритм будет анализировать текст грамматики, он будет искать предикат follow с такими же субъектом и объектом.
Подобный анализ исследователи провели для всех исследуемых черт, составив список возможных предикатов и их аргументов. Искать по структуре предиката гораздо удобнее, чем просто по совпадению с ожидаемым предложением, потому что таким образом покрывается более широкий набор вариантов описания. Ведь в грамматике может быть написано и предложение, скажем The adjectives and adverbs follow the noun they qualify («Прилагательные и наречия следуют за существительным, которое определяют»), а значит, прямой поиск нужной информации не найдёт, а вот поиск по аргументам предиката справится.
Разумеется, этот алгоритм далеко не идеален. Так, например, суждение машины может расходиться с суждением экспертов просто на уровне договорённостей. Скажем, во время анализа свойства «идёт ли прилагательное перед существительным», алгоритм находил в описаниях аргумент usually («обычно») и сообщал, что возможны оба варианта. Технически решение является абсолютно правильным, но работавшие с грамматикой эксперты сочли, что случаи, когда прилагательное идёт после существительного, слишком редки, чтобы учитывать это как значимую черту (а ведь строгость в отношении таких моментов вполне может меняться в зависимости от исследовательских задач).
Иногда происходят ошибки и во время парсинга: из-за некорректного деления текста на предложения Propbank приписывает предикату аргументы из другой части текста. Безусловно некоторые системы семантического парсинга грамматик, основанные на инструментах глубинного обучения, показывают большую точность, но этот алгоритм интересен в первую очередь тем, что за ним стоит лингвистическая идея — что для решений задач NLP в наше время редкость.
Источники
- Björkelund A., Hafdell L., and Nugues P. 2009. Multilingual Semantic Role Labeling. In Proceedings of the Thirteenth Conference on Computational Natural Language Learning (CoNLL 2009): Shared Task, pages 43–48, Boulder, Colorado. Association for Computational Linguistics.
- Borin, L., Saxena, A., Comrie, B. and Virk, S. M. A bird’s-eye view on South Asian languages through LSI : Areal or genetic relationships? In: Journal of South Asian Languages and Linguistics 7, no. 2 (2020): 203-237. https://doi.org/10.1515/jsall-2021-2034.
- Carl Rubino. 2013. Reduplication. In: Dryer, Matthew S. & Haspelmath, Martin (eds.) WALS Online (v2020.4) [Data set]. Zenodo. https://doi.org/10.5281/zenodo.13950591 (Available online at http://wals.info/chapter/27, Accessed on 2024-11-10).
- Click Consonant. 2022. Wikipedia. September 1, 2022. https://en.wikipedia.org/wiki/Click_consonant.
- Haspelmath, Martin, and Andrea D Sims. 2013. Understanding Morphology. Abingdon: Routledge.
- Virk, S. M., Borin, L., Saxena, A., Hammarström, H. (2017). Automatic Extraction of Typological Linguistic Features from Descriptive Grammars. In: Ekštein, K., Matoušek, V. (eds) Text, Speech, and Dialogue. TSD 2017. Lecture Notes in Computer Science(), vol 10415. Springer, Cham. https://doi.org/10.1007/978-3-319-64206-2_13.

