
Кластеризация, или кластерный анализ – это задача группировки объектов таким образом, что более похожие друг на друга (по некоторым признакам) объекты окажутся в одном кластере, а различные – в разных. Кластеризация применяется в тех случаях, когда мы не знаем о том, как организованы данные.
Предположим, у нас есть отзывы пользователей о работе сайта: их слишком много, и прочитать все не представляется возможным. В этом случае можно, например, сгенерировать семантические вектора текстов при помощи word2vec (подробнее об этом подходе – в нашей статье), и взять средний вектор по всем словам в тексте. Затем применить кластеризацию: таким образом, близкие по смыслу ответы сформируют кластера. Без прочтения большого количества текстов мы узнаем, какие основные преимущества и недостатки сайта волнуют пользователей.
Меры близости
Чтобы определить, схожи ли объекты между собой, используются меры векторных расстояний. Объекты формально описываются через наборы признаков (как правило, чисел), которые можно представить в виде вектора. Например, клиента банка, который решил взять ипотеку, можно представить в виде вектора из его зарплаты, стажа на последнем месте работы в месяцах и суммы, на которую клиент хотел бы получить займ, в миллионах рублей. Получится что-то вроде [32, 18, 1] или [28, 6, 6]. Теперь можно использовать, например, евклидово расстояние. Вот его формула:

В примере выше расстояние между объектами sqrt((32-28)^2+(18-6)^2+(1-6)^2)) приблизительно равно 13.6.
Алгоритмы
Существуют различные методы кластеризации, и их использование приводит к разным результатам. Рассмотрим два метода, которые часто используются в реальных задачах.
K-Means
Для использования этого алгоритма нужно определиться с параметром k — количеством кластеров, которое мы ожидаем получить.
- Выбираем k — количество кластеров, которое мы ожидаем получить.
- Случайным образом выбираем k точек-объектов из всех имеющихся данных. Мы называем их центроидами, потому что на этом шаге мы считаем, что это — потенциальные центры кластеров.
- Для каждой точки-объекта данных определяем, какая центроида к ней ближе всего. На этом этапе считаем, что все точки, ближайшие к одной и той же центроиде, образуют кластер.
- В каждом таком кластере находим среднюю координату – теперь это новая центроида
- Повторяем пункты 3-4: рассчитываем расстояния между каждой точкой-объектом и новыми центроидами, определяем ближайшие, считаем новые центроиды новых кластеров. Этот процесс повторяется до тех пор, пока центроиды не перестанут меняться.

DBSCAN
В этом алгоритме не нужно указывать количество кластеров: оно определяется автоматически. Вместо этого нужно определить радиус поиска точек и минимальное количество точек в кластере.
- Выбираем случайную точку-объект выборки и ищем точки вокруг нее в выбранном нами радиусе.
- Если на предыдущем этапе набралось меньше точек, чем минимальное нужное нам количество, помечаем все эти точки как выбросы: будем считать, что они не принадлежат ни одному кластеру
- Если набралось достаточное количество точек, для каждой из них также ищем новые точки в определенном нами радиусе. Таким образом, все точки, находящиеся друг от друга на расстоянии меньшем или равном заданному радиусу будут образовывать один кластер
Почему мы используем различные подходы к кластеризации? На самом деле, нет одного верного способа разделить объекты на группы. Для разных задач подходят разные методы, а применение нескольких методов на одном наборе данных может выявить разные его особенности. Например, если среди данных есть объекты, не принадлежащие ни к одной группе, и кластеры могут иметь сложную форму, то лучше использовать DBSCAN. K-Means лучше использовать, если заранее известно количество групп, которые должны обнаружиться в данных.
Важная особенность данных, которую нужно учитывать при выборе алгоритма — линейная разделимость. Если выборку можно разделить линиями таким образом, что получатся отдельные кластера, с этой задачей лучше справится K-Means, a если это невозможно — DBSCAN. На картинке ниже первые два набора данных линейно неразделимы: видно, что в этих случаях DBSCAN определяет кластеры более корректно, чем K-Means.

Пример
Допустим, у нас есть несколько объектов — точки с координатами [2, 4], [1, 3], [2, 1], [5, 2], [4, 3], [4, 5], и мы хотим получить информацию о том, как они распределены в пространстве. При взгляде на эти данные можно предположить, какие кластера они могут образовать. Но на практике, как правило, таких объектов гораздо больше, и размерность пространства не позволяет визуализировать данные также наглядно.
Если использовать K-Means с двумя кластерами, получится следующее разделение:
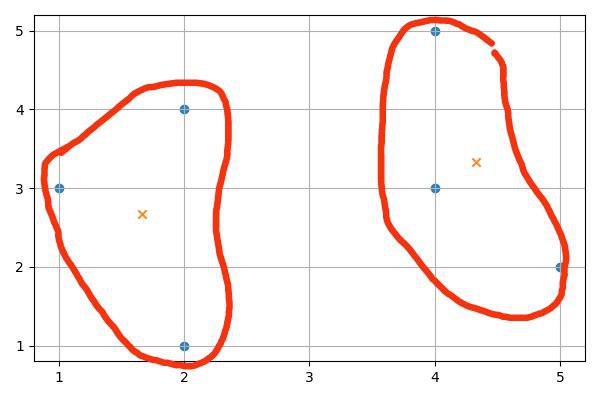
В конце работы алгоритма центроиды окажутся в точках [4 1/3, 3 1/3], [1 2/3, 2 2/3] (отмечены на рисунке крестиками). Точки [2, 4], [1, 3], [2, 1] окажутся в одном кластере, а [5, 2], [4, 3], [4, 5] – в другом.
Если использовать DBSCAN с радиусом равным 2 и минимальным количеством точек в кластере равным 2, получится два кластера и один выброс:
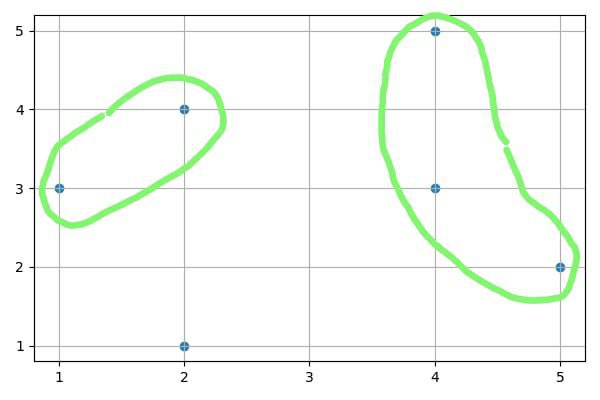
Для точки [1, 3] в радиусе 2 найдется точка [2, 4]. Для точки [4, 5] сначала найдется точка [4, 3], а для нее — точка [5, 2]. У точки [2, 1] не найдется соседей на расстоянии меньше 2.
Где это применяется?
Кластеризация широко применяется во всех областях науки о данных. В маркетинговых задачах кластерный анализ позволяет определить категории клиентов (которые мы заранее не знали) и на основе этой информации предлагать разные товары разным группам. Кластеризация пользователей по геоданным позволяет сгруппировать близкие (в пространстве и времени) точки в полноценные локации: дом, место работы или любимый магазин – и, таким образом, сделать о пользователе дополнительные выводы. Также кластеризация позволяет решить, например, задачу распознавания лиц в толпе: лица, принадлежащие одному и тому же человеку, при достаточном количестве данных, будут собираться в один кластер. Такой подход позволяет избежать ручной разметки изображений.



