В конце первой части нашей статьи об авторстве Беовульфа мы затронули критический разбор (Плехач и др.), ставящий под сомнение как методы, так и результаты Л. Найдорфа и его коллег. Спустя два года после публикации исследования Найдорфа и др. в «Nature human behaviour», на сайте научного журнала стала доступна не только критическая статья, но и ответ авторов оригинальной работы. Научный спор цифровых филологов, не менее интересный и загадочный, чем детективы английских классиков, продолжается!
Как все началось
Анонимность древних текстов всегда привлекала внимание ученых. Системный Блокъ рассказывал, как группа исследователей пыталась ответить на вопрос, является ли древнеанглийская поэма «Беовульф» работой одного автора или комбинацией сразу нескольких текстов. В XIX веке филологи (К. Лахман) склонялись к тому, что несколько языческих песен были объединены христианскими редакторами (теория редакционного свода). В ХХ веке эта теория имела уже меньше сторонников. Ученые разделились на два лагеря: «Беовульф» либо полностью написан одним человеком, либо два разных текста (первый — о битве с Гренделем, второй — с драконом) сведены одним редактором.
Л. Найдорф, М. Кригер, М. Якубек, П. Чоудхури и Дж. Декстер (Найдорф и др.) оценили текст по четырем параметрам (паузация, метрика, сложные слова, n-граммы) и пришли к выводу, что поэма — творение одного автора. Одновременно с этим исследователи находят подтверждения тому, что Кюненвульф, предполагаемый автор поэм «Елена», «Юлиана», «Христос II», «Cудьбы апостолов», также автор поэмы «Андрей» («Andreas»). Однако Петр Плехач, Артем Шеля, Эндрю Купер, Бенджамин Наги (Плехач и др.) подвергли сомнению противоречивую методологию Найдорфа. Но и на этом история не закончилась: авторы оригинальной статьи, М. Кригер, П. Чоудхури и Дж. Декстер (Кригер и др.), написали ответ на критику. В этой статье мы разберем научный спор цифровых филологов.
Паузы (не) имеют значение
В статье Плехача и др. утверждается, что предлагаемые Найдорфом и др. методы непригодны для доказательства текстуальной однородности «Беовульфа». Как следствие, недостоверны и результаты исследования. Плехач и др. убеждены, что древнеанглийская поэма заметно гетерогенна. Первым критерием, подвергающимся критике, становятся смысловые паузы.
В оригинальной работе под смысловыми паузами понимаются паузы, возникающие естественным образом в речи и выделяемые на письме пунктуационными знаками, отличными от запятой. Найдорф и др. подсчитали отношение внутристрочных пауз (смысловые паузы, не совпадающие с концом строки) к остальным смысловым паузам и заметили, что тексты разных авторов имеют отличающиеся друг от друга показатели (две части «Книги Бытия» — Gen. A и Gen. B; «Христос I», «Христос II» и «Христос III»), в то время как тексты одного и того же автора — почти одинаковые («Елена» и «Юлиана»). Ко вторым попали и две (предполагаемые) части «Беовульфа», причем в обеих редакциях.
Но, во-первых, важность этого параметра для атрибуции древнеанглийской поэзии не установлена. Во-вторых, в коде обнаруживается ошибка: обе выборки оказываются из первой части «Книги бытия» (Gen. A), чьё единое авторство и не подвергалось сомнению.
Кригер и др. соглашаются: в репозиторий действительно были загружены не те данные. Тем не менее при использовании правильного кода Gen. A и Gen. B действительно оказываются неоднородны. На рис. 1 видно, что разница в показателях между двумя частями «Беовульфа» в обеих редакциях (K&D и Klaeber) примерно такая же, как между «Юлианой» и «Еленой». Две части Книги Бытия, три поэмы «Христос» и гомеровские «Илиада» и «Одиссея» (хотя, предполагаемо, одного авторства, но в то же время имеющие много различий) демонстрируют больший разрыв.
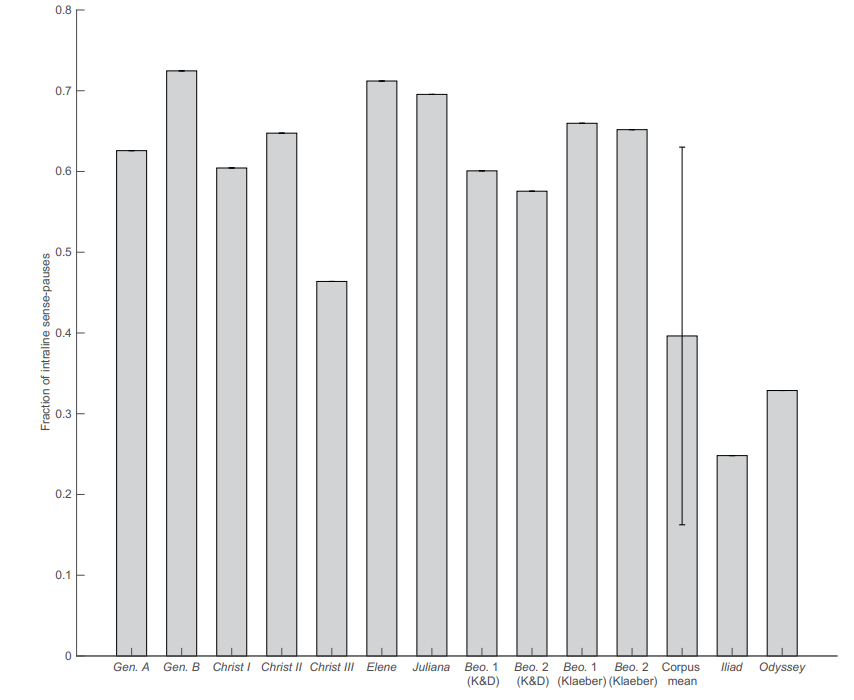
Однако именно это, как считает Плехач и др., и доказывает нерелевантность метода смысловых пауз: тексты разного авторства (Христос I и Христос II, Христос I и Христос III) оказываются почти гомогенными (Рисунок 2), в то время как разница между Gen. A и Gen. B может объясняться саксонским происхождением второй части Книги Бытия. При этом Плехач и др. показывают, что доля внутристрочных пауз неоднородна даже внутри одного текста: если поделить каждый текст на выборки по 100 строк и по каждой выборке посчитать эту долю, то будет большой разброс результатов.
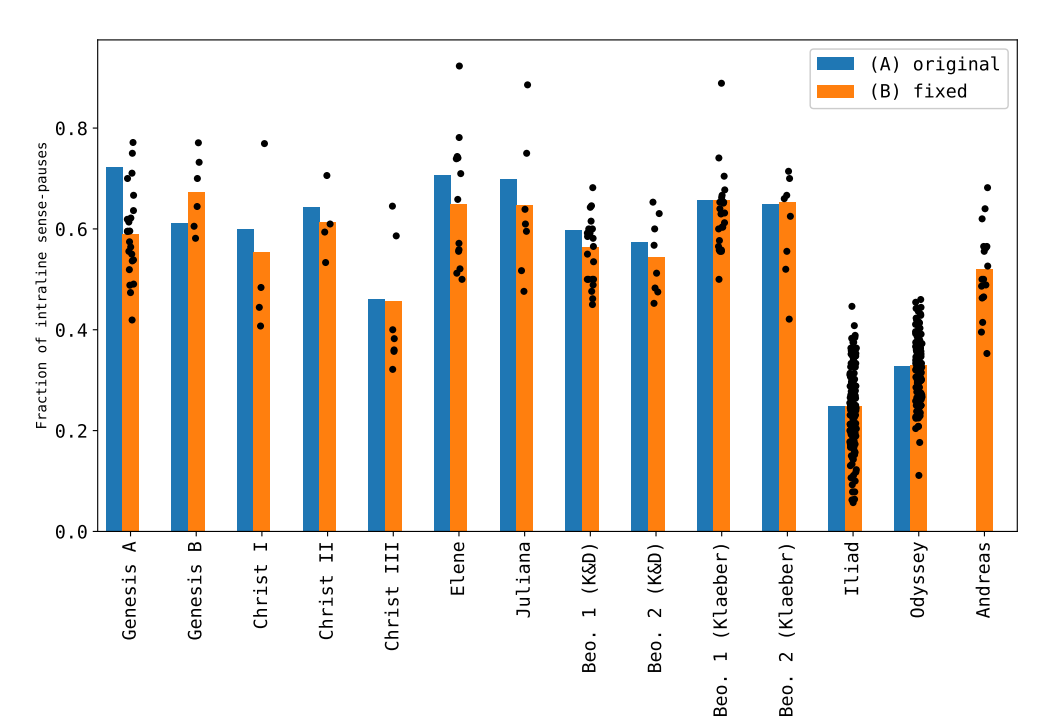
Но Кригер и др. полагают, что маленькие выборки по 100 строк способствуют этой неоднозначности больше, чем сам метод, так как три поэмы «Христос» намного короче остальных анализируемых текстов.
Плехач и др. также утверждают, что изначально метод смысловых пауз применялся для хронологического анализа текстов (драматических) одного автора. Слабыми сторонами этого подхода также становятся несколько недочетов в коде и неоднозначность постановки знаков препинания. Однако Кригер и др. отмечают, что ни доработка кода, ни вариативность пунктуации в разных изданиях не влияют существенно на статистику, а роль смысловых пауз в поэзии подчеркивалась не одним исследователем.
А важен ли размер?
Также Найдорф и др. проанализировали метрику древнеанглийских текстов. Ими была выявлена частота употребления пяти возможных ритмических типов (паттернов) полустиший «Беовульфа» как в целом в поэме, так и последовательно по полустишиям (от первого до последнего). Частота использования разных типов оказалась равномерной на протяжении всего текста. В метрическом плане текст гомогенен.
Метод анализа древнеанглийской метрики, использованный Найфордом и др., по мнению Плехача и др., неубедителен по двум причинам.
Во-первых, рассмотрение полустиший вместо целого стиха кажется произвольным решением с точки зрения литературной теории ХХ века, так как минимальная независимая единица древнеанглийской поэзии — это именно стихотворная строка. На это авторы оригинальной статьи, ссылаясь на Снорри Стурлусона, отвечают, что древнегерманские поэты считали базовой метрической единицей полустишие. Стурлусон — ключевая фигура древнескандинавской поэзии, автор не только знаменитой «Младшей Эдды», но и первых «учебников» по поэтическому творчеству. Так, в «Языке поэзии» Снорри рассказывает о главных приемах в скальдической поэзии. Скальдическая поэзия противопоставлялась эддической как более изощренная, но менее богатая содержанием. В «Перечне размеров» Стурлусон на примере собственных произведений разбирает скальдические размеры. Поэтому обращение к такой важной фигуре, несомненно, обосновано.
Во-вторых, увеличение количества анализируемых параметров в 5 раз (каждое из двух полустиший может быть представлено пятью вариантами, по правилам комбинаторики — 5^2 = 25 вариантов одной строки) еще ярче подсвечивает метрическую неоднородность.
Найдорф и др. пришли к выводу, что доля каждого типа остается линейной по всему тексту, и в районе 2300 строки (4600 полустишья, конца первой части) заметного сдвига нет, а значит поэма гомогенна:
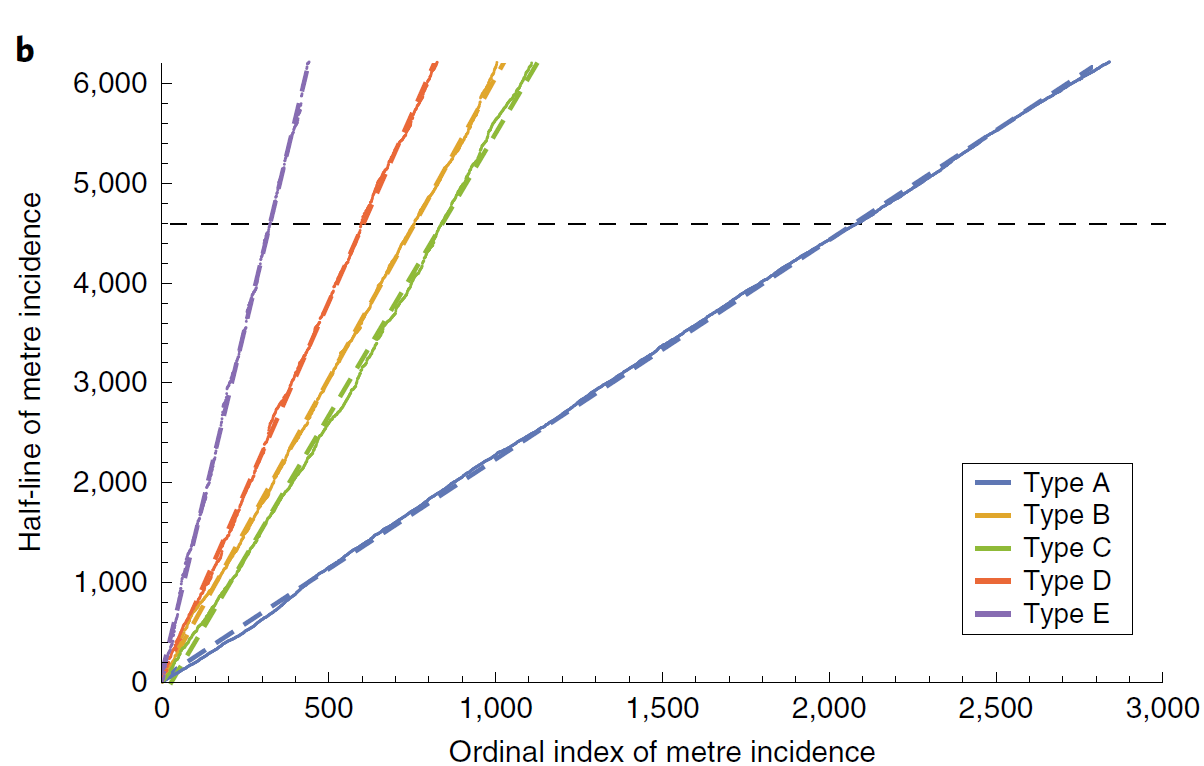
Плехач и др. используют более тонкий метод «скользящего окна»:
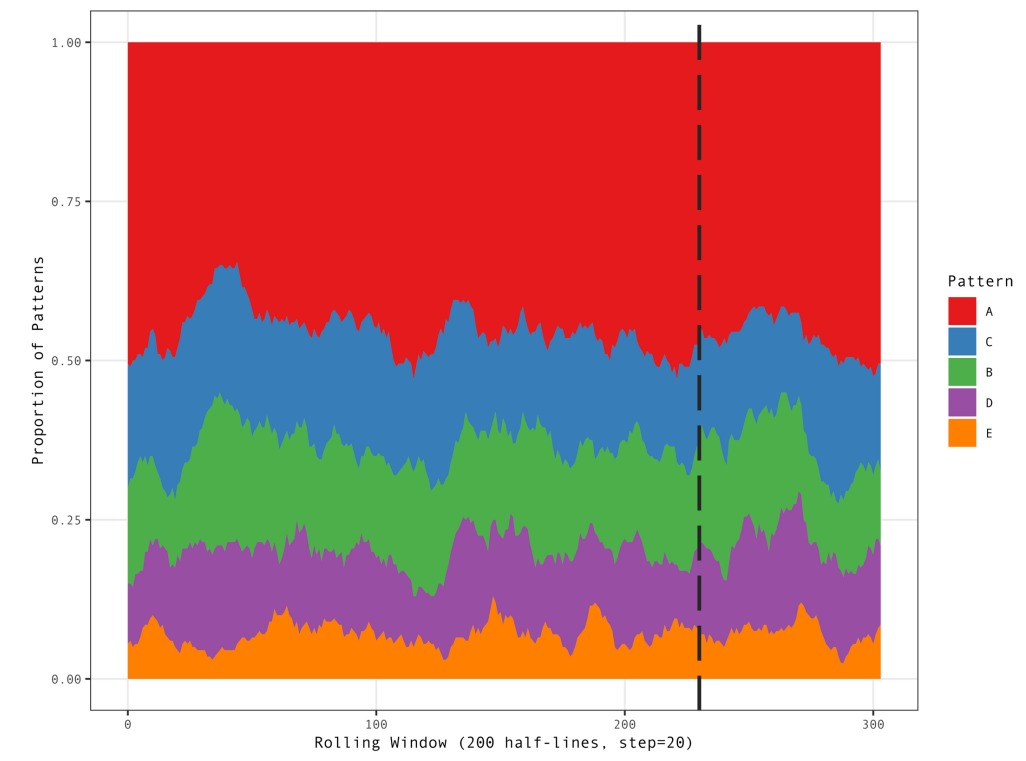
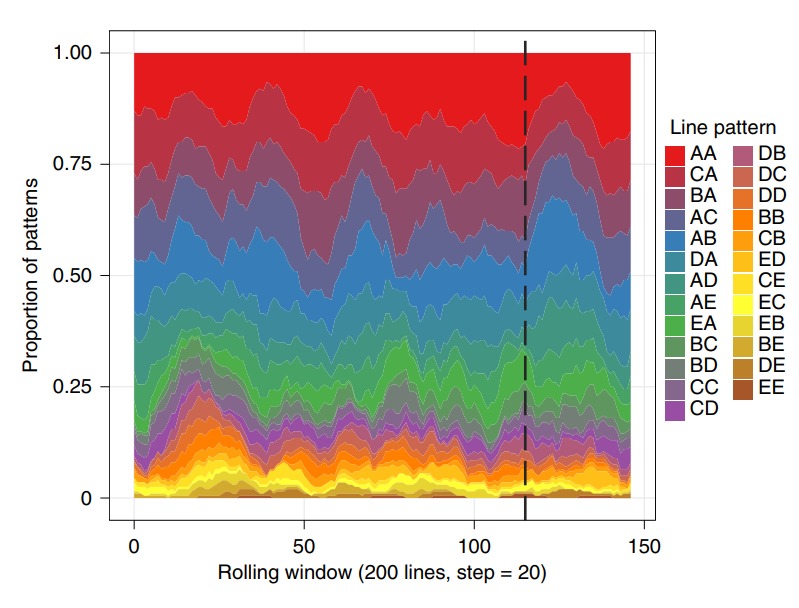
При учете всех возможных метрических схем (25 вместо 5) неоднородность двух частей (до и после пунктирной линии) «Беовульфа» очевидна:
Сложные гапаксы, или почему надо перепроверять код
Одна из отличительных черт древнеанглийский (и в целом древнегерманской) поэзии — сложные слова. Значительная часть из них — это устойчивые перифразы, которые называются «кеннингами»: например, hran-rád («дорога китов») переводится как «море». Найдорф и др. изучили распределение сложных гапаксов (сложных слов, встретившихся всего один раз, т. е. уникальных) и заметили, что их доля в текстах одного автора примерно одинаковая, в текстах разных авторов — разная. Сложные гапаксы в «Беовульфе» распределены равномерно, что говорит в пользу гомогенности поэмы. По этому критерию обнаруживается и сходство «Андрея» с четырьмя другими поэмами Кюненвульфа. Высокая доля совпадения неуникальных сложных слов в предполагаемых частях «Беовульфа» и в «Елене», «Юлиане» и «Андрее» подтверждают эти выводы.
Для анализа сложных гапаксов Найдорф и др. используют тот же метод, что и для анализа метрики, но их снова критикуют: равномерное распределение не обязательно говорит об общем авторе. Так, две части «Елены» оказываются написанными будто разными авторами, а «Елена», «Беовульф» и «Феникс» — одним:
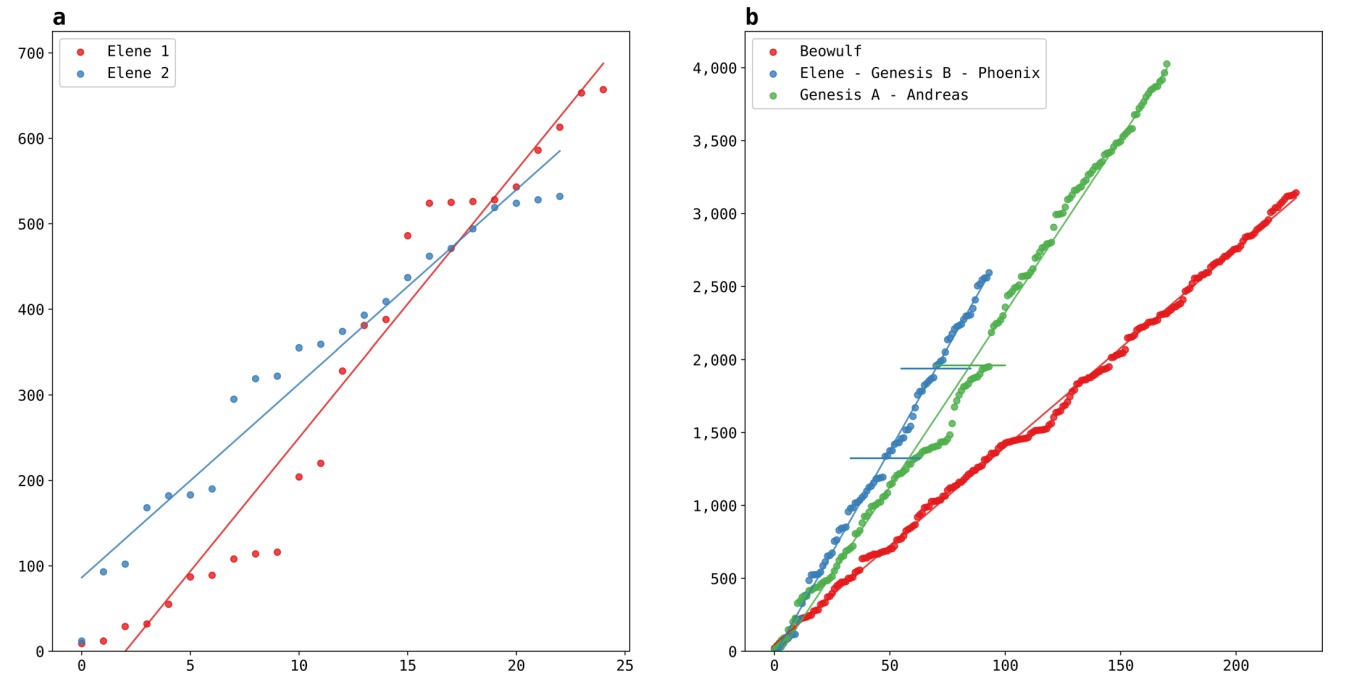
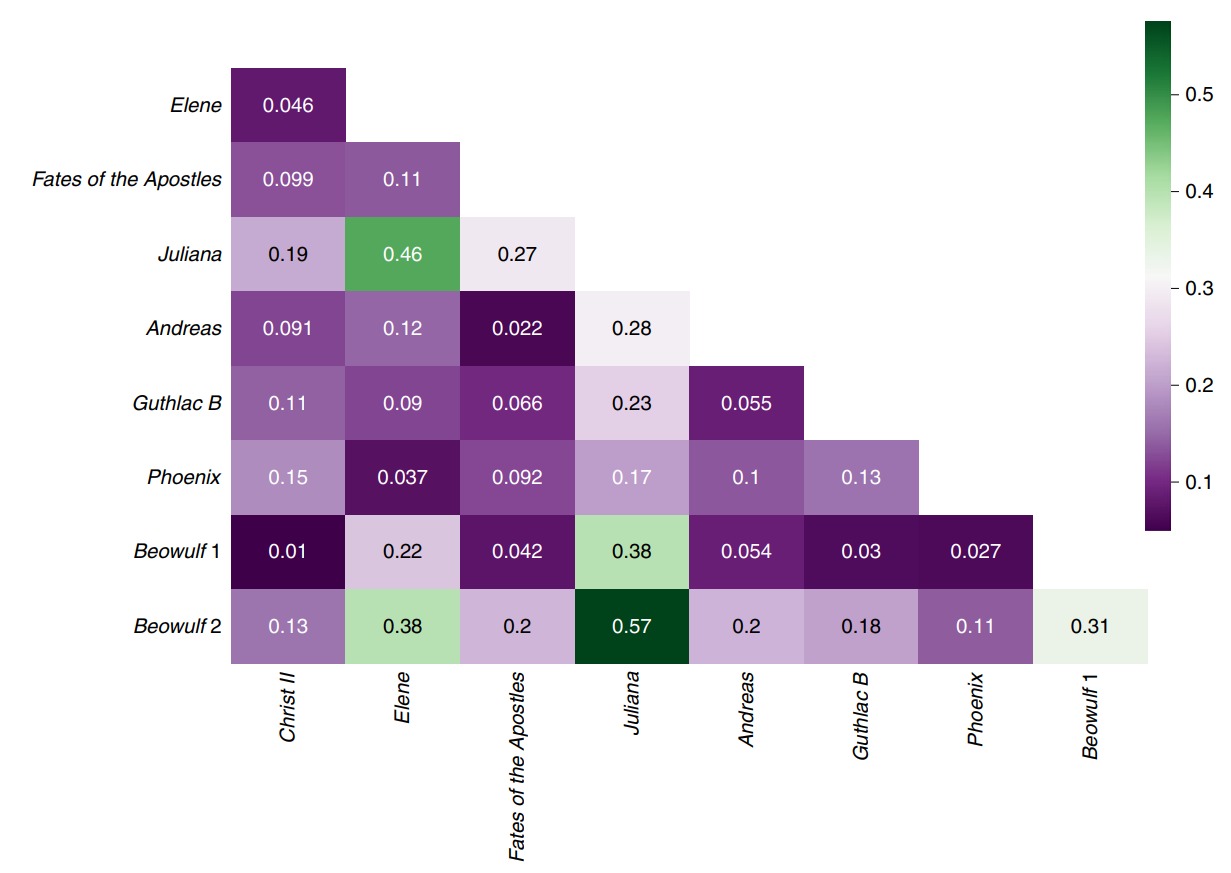
Анализ совпадающих (неуникальных) сложных слов оказался невоспроизводимым, Плехач и др. используют новый код. Корреляция между двумя частями «Беовульфа» намного меньше заявленной, но и ее можно объяснить их тематическим сходством (если не идентичностью):
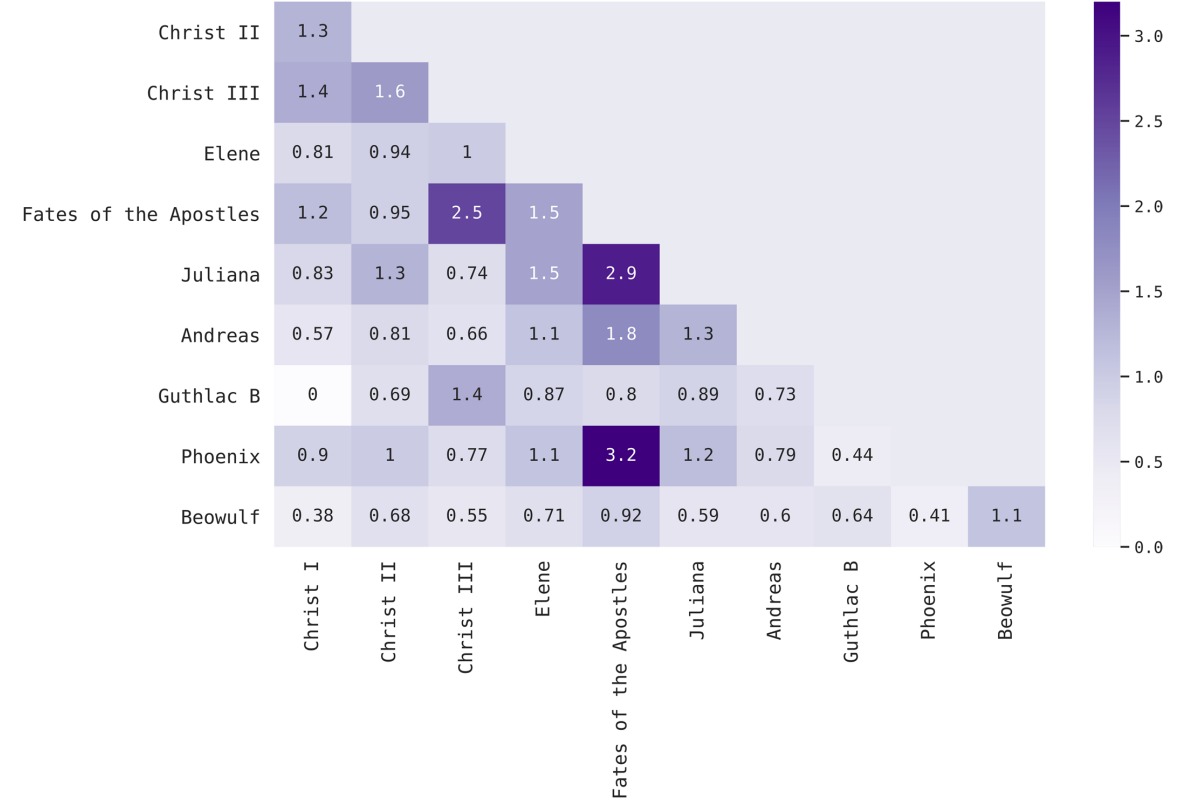
Однако Кригер и др. резко вступаются за свой метод. Они утверждают, что не просто считают корреляции, а применяют пермутационный тест. Чтобы объяснить, что это такое, представим, что мы берем две случайные выборки из какой-то одной совокупности (в статистике ее называют генеральной). Допустим, что характеристики этих двух выборок различаются. Как доказать, что две эти выборки действительно взяты из одной совокупности, а не из разных? Чтобы это проверить, можно повторить эксперимент с двумя выборками несколько сот или тысяч раз. Каждый раз считать их характеристики, а в конце построить их распределение и посмотреть, насколько значимо отличается результат в первой случайной паре от общего распределения. Так и с двумя частями «Беовульфа» — нужно проверить, правда ли его выборки до и после 2300-й строки взяты из одного текста, или же все-таки из разных. «Беовульфа» тестировали так: исследователи делили текст на две части 1000 способами и каждый раз в полученной паре смотрели, насколько постоянной будет доля сложных гапаксов. И смотрели, как оказываются распределены полученные значения корреляции. Разделение «Беовульфа» по 2300-й строке никак значимо не отличается от других разбиений, и вообще эта поэма оказывается достаточно гомогенной относительно других текстов:
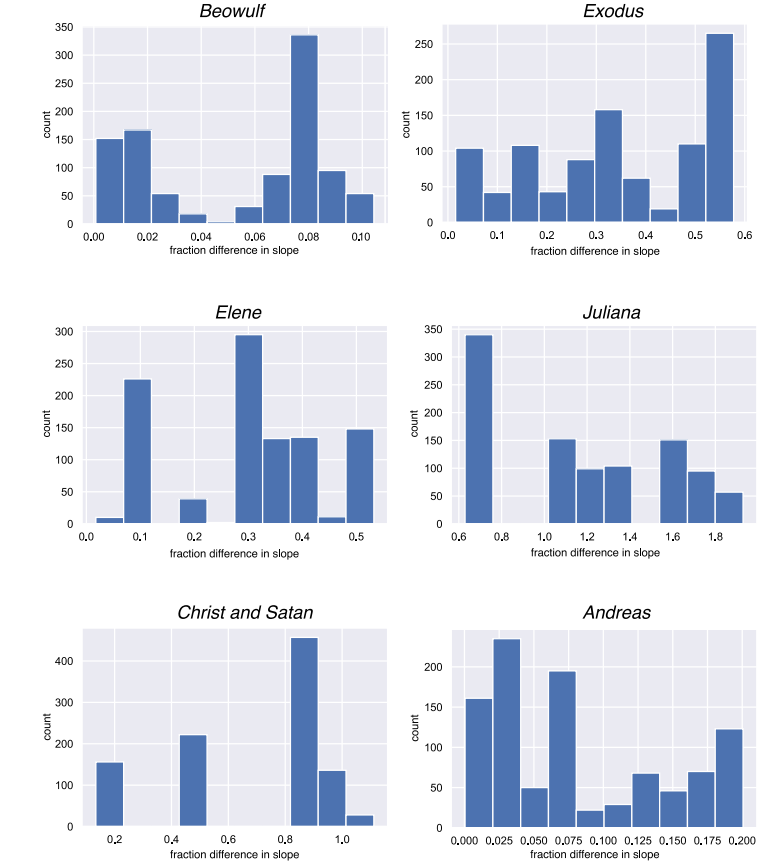
В коде Плехача и др. для анализа сложных существительных Кригер и др. находят несколько типов ошибок: Плехач и др. не учитывают окончания и орфографические варианты, включают в подсчет прилагательные и не различает слова-дублеты (например, «wanhoga» — «anhoga»). Отсюда — иллюзорное снижение однородности «Беовульфа» и разница в подсчетах:
Орфография и статистика
Напоследок Найдорф и др. проанализировали 25 самых частотных би-, три- и тетраграмм. Авторство «Андрея» и гомогенность «Беовульфа» снова подтвердились: на дендрограмме первый оказывается в одном кластере с «Юлианой», «Еленой» и «Судьбами апостолов», обе части второго также оказываются рядом. Использование только первых 25 n-грамм, как отмечают Плехач и др., довольно произвольно и даже при увеличении значения n до 5 точно лишь на 70-86%. Усовершенствованный кластерный анализ (вместо 25 n-грамм берется 1000) делит текст примерно на 1939 строке (а не 2300), там, где меняется пишущий. Однако Кригер и др. отмечают, что даже при минимальном учете Плехачем и др. орфографических вариантов (например, þ/ð и eo/io) уже на графике 3-грамм эта граница становится нечеткой:
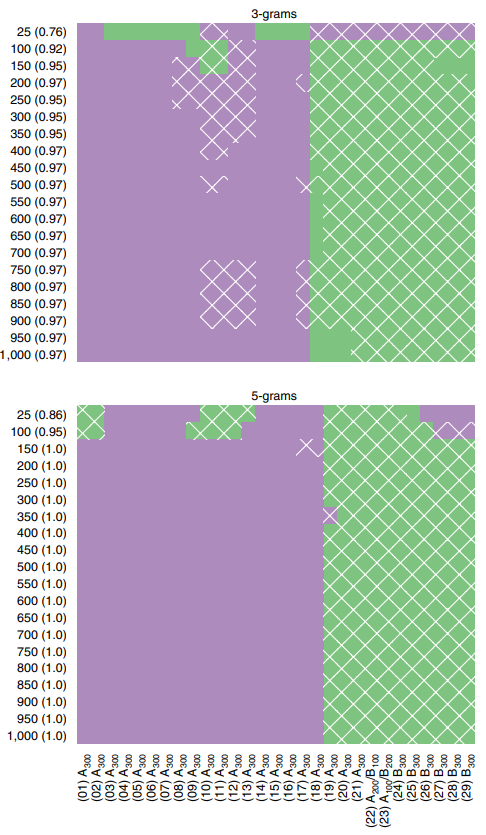
Исследователи используют издание с унифицированной орфографией (Рис. 12) и обнаруживают, что эта граница вовсе исчезает:


Но главное, что отмечают Кригер и др.: вывод Найдорфа и др. об авторстве «Андрея» подтверждается и самим Плехачем и др. (если использовать его код для n-грамм), несмотря на то, что последний используют другую методологию. Значит, центральный тезис оригинальной работы оказался неопровержимым.
Quid est veritas?
На критику двух последних критериев авторы оригинальной статьи отвечают довольно убедительно: им удалось учесть особенности орфографии и недочеты в коде, что повлияло на результаты применения цифровых методов. Первые два критерия остаются противоречивыми чисто с филологической точки зрения: у исследователей разные взгляды на релевантность смысловых пауз и полустиший (или целых стихотворных строк) для древнеанглийской поэзии. Отсюда невозможность прийти к общему мнению. Тем не менее ключевой тезис оригинальной работы об авторстве «Андрея» подтвердился самим Плехачем и др.
«Quid est veritas?» («Что есть истина?») — такое латинское название мог бы получить наш научный «детектив». Тем не менее, этот бурный диспут именно через свою диалогичность позволяет по-новому взглянуть на сущность цифровых методов в филологических исследованиях. Несмотря на всю простоту применения, они должны быть неоднократно проверены на точность и релевантность. Каждый параметр, каждый символ в коде должны иметь значение. Препятствием к получению убедительных результатов может стать обычная невнимательность, но и это повышает необходимость (само)перепроверки и peer-review.
Внедрение цифровых методов в гуманитарные науки навсегда изменило и способ коммуникации исследователей: он тоже стал комплексным, междисциплинарным. Теперь филолог должен взаимодействовать не только с программистами, коллегами- филологами, но и с другими учеными. То, что раньше было противостоянием «физиков и лириков», стало их союзом, и, перефразируя поэта Б. Слуцкого, можно уверенно сказать, что логарифмы стали неотъемлемым инструментом, а не врагом филологов.
Среди авторов оригинальной статьи есть ученые-биологи, далекие от теории литературы, но разбирающиеся в структуре живых организмов (к которым относятся и тексты) лучше любого филолога. Несомненно, такой междисциплинарный диалог однажды и поможет раскрыть тайну «Беовульфа», сколько бы авторов ни было у этой поэмы.
Источники
• Krieger, M.S., Chaudhuri, P. & Dexter, J.P. Reply to: Beowulf single-authorship claim is unsupported. Nat Hum Behav 5, 1484–1486 (2021). DOI
• Neidorf, L., Krieger, M.S., Yakubek, M. et al. Large-scale quantitative profiling of the Old English verse tradition. Nat Hum Behav 3, 560–567 (2019). DOI
• P. Plecháč, A. Cooper, B. Nagy, A. Šeļa. Beowulf single-authorship claim is unsupported. Nat Hum Behav 5, 1481–1483 (2021). DOI
• Replication code for Authors’ Response to Reply to: Beowulf single-authorship claim is unsupported by P. Plecháč et al.
• Replication code for Beowulf single-authorship claim is unsupported by P. Plecháč et al.• Репозиторий к: Large-scale quantitative profiling of the Old English verse tradition.