
Электронный литературный корпус — это большое собрание художественных текстов, которое размещено в открытом доступе в интернете. Такие проекты посвящаются различным писателям, жанрам и переводам. У каждого из корпусов есть свои «фишки», которые помогают как ученым, так и простым читателям. В корпусных текстах и материалах присутствует мета-разметка для поиска нужной информации. Ее также используют в цифровых гуманитарных исследованиях и изучении творчества авторов.
«Байрон в русских переводах 1810-1860-х годов»
Создал корпус Институт Русской литературы (Пушкинский дом) в Санкт-Петербурге. В 2017 году проект получил грант Президента Российской Федерации для государственной поддержки молодых российских ученых-кандидатов наук. Создательницами корпуса стали сотрудницы института Алина Бодрова, Светлана Степина и Антонина Мартыненко. Двумя годами позже они разместили на сайте русские переводы Дж. Г. Байрона с 1810 по 1860-е гг.
В XIX веке эти произведения публиковали различные периодические издания Российской империи. Основными источниками данных стали картотека А. Д. Умикяна и генеральные каталоги различных литературных институтов. К ним исследовательницы добавили указатели содержаний журналов «Современник», «Отечественные записки», «Телескоп», «Московский телеграф» и «Московский вестник». В качестве дополнений использовались библиографический указатель Н. П. Смирнова-Сокольского «Русские литературные альманахи, сборники XVIII–XIX вв.» и картотека Н. Н. Бахтина.
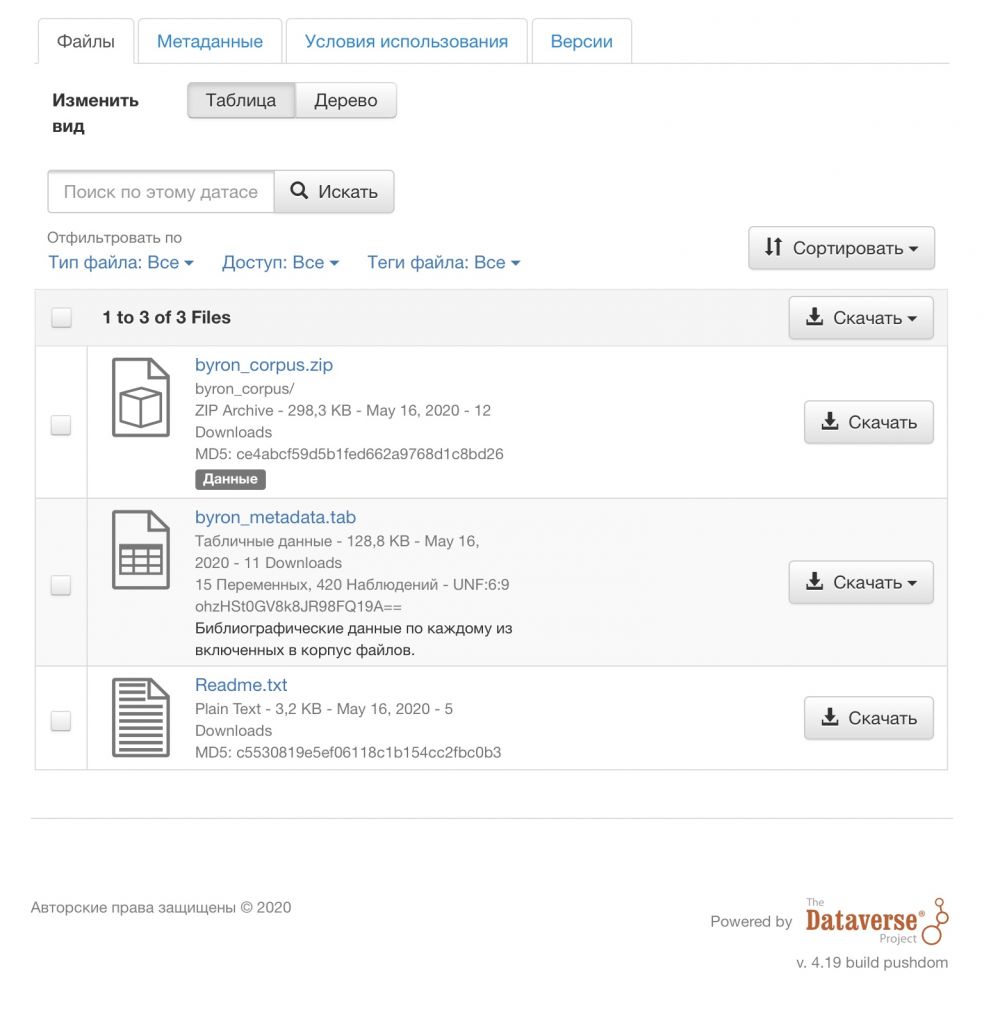
Тексты переводов объединены в zip-архиве как отдельные файлы, которые можно скачать в универсальной кодировке UTF-8 [1]. Название каждого файла начинается с идентификационного номера, далее следует год публикации, название и фамилия переводчика. Метаданные для текстов находятся в специальной таблице и доступны для скачивания. Они включают в себя полные библиографические описания материалов, источники переводов, имена и подписи переводчиков.
«Мир Данте»
Корпус появился в 1996 году благодаря институту передовых технологий гуманитарных наук в университете Вирджинии, США. Вдохновительницей проекта стала Дебора Паркер — профессор итальянского языка в Университете Вирджинии. Дополняют и развивают литературный корпус американские и итальянские исследователи.

«Мир Данте» — инструмент для изучения «Божественной комедии» и биографии Данте Алигьери. Два итальянских издания текста создатели портала закодировали согласно TEI[2]. TEI — это универсальный язык разметки текста на основе XML[3]. Этот язык используется для создания цифровых гуманитарных ресурсов. Он выступает как средство формального кодирования наиболее значимых свойств текста: сведений об авторе, обстоятельств публикации первоисточника и др.
Вместе с фрагментами произведения читатели найдут упоминания всех мест, персонажей, существ и тексты песен и гимнов. Эту информацию также снабдили разметкой, что облегчает поиск. При этом скачать какие-либо материалы нельзя: понадобятся либо копирование, либо скриншоты.

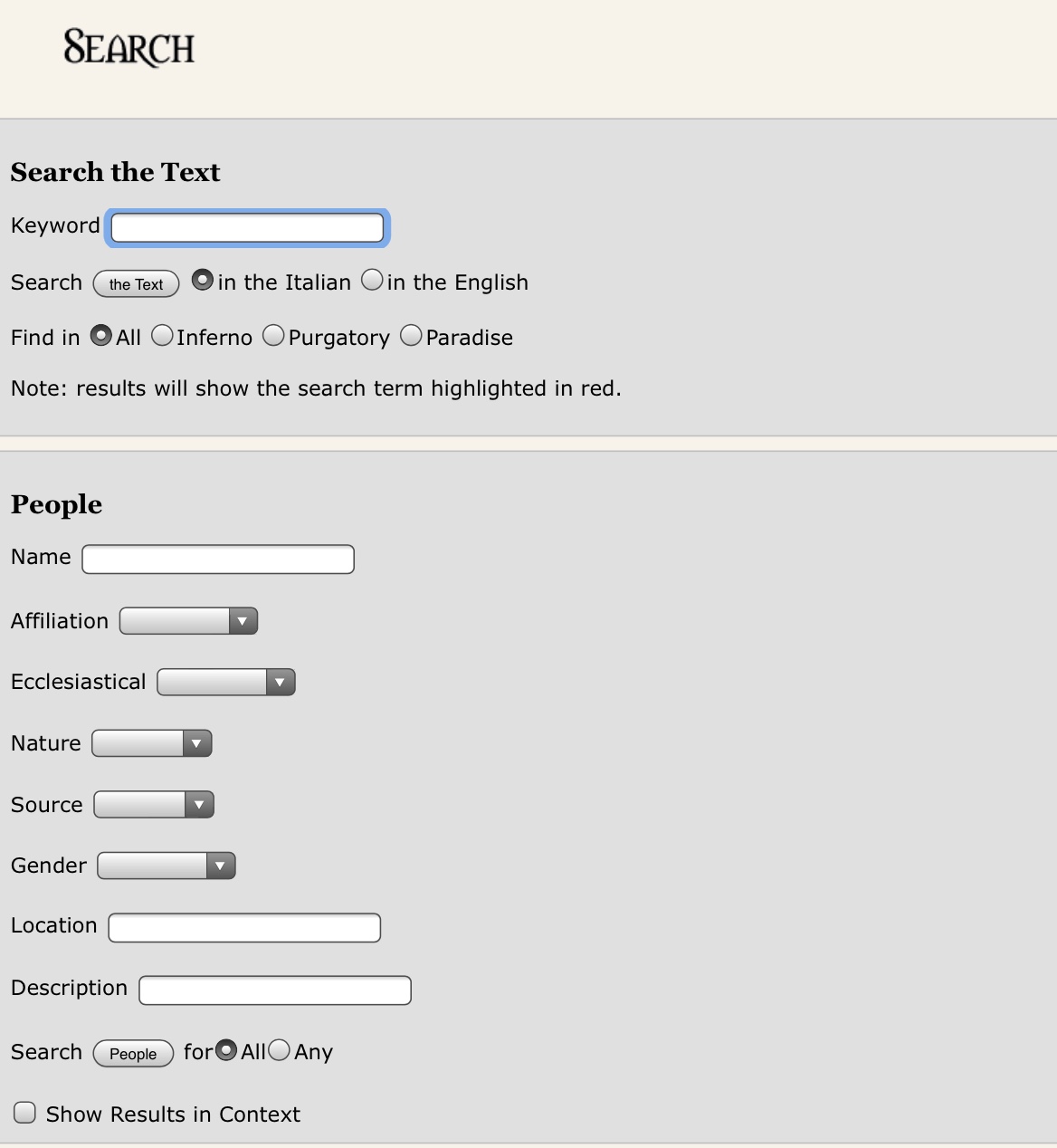
1 — Разметка на примере одного из персонажей. Входные данные: <em class=»f_pe_1″>san Pietro</em>. 2- Фрагмент поиска по тексту на сайте
Особенность платформы заключается в ее мультимедийности и образовательной направленности. Сайт предлагает пользователям изучать «Божественную комедию» через компоненты, которые видны в главном меню. Посетители могут послушать средневековую музыку, увидеть иллюстрации к произведению, ознакомиться с картами и изучить историю Италии и Европы Xlll-XIV веков. Каждый компонент имеет ссылку на фрагменты текста и справочные данные.
«Мир Данте» предлагает материалы и для учителей, которые проводят занятия по творчеству писателя. Они состоят из вопросов по тексту и учебных видео, которые знакомят пользователей с основными компонентами сайта. Функция помогает читателями улучшить понимание произведения и углубиться в тему.
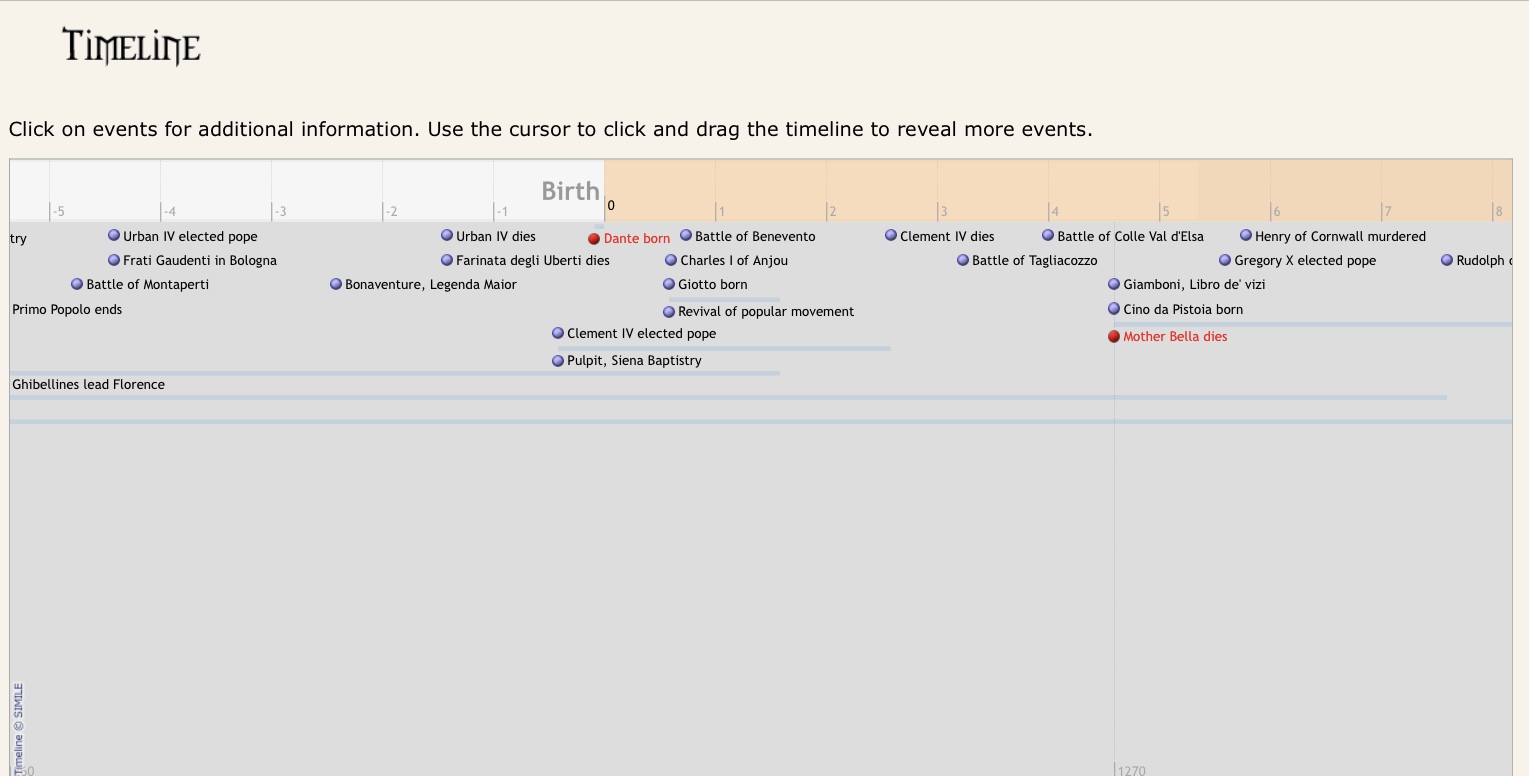

1 — Фрагмент таймлайна до и после рождения Данте. 2 — Одно из наглядных изображений кругов Ада в «Божественной комедии». 3 — Представление галереи
Проект «Марк Твен Онлайн»
История литературного корпуса Марка Твена началась в 1967 году с критических статей о творчестве и жизни писателя. Постепенно исследователи стали не только корректировать и редактировать тексты, но и переводить их в электронную версию. Спустя 40 лет цифровое собрание материалов Твена стало главной задачей для создателей. Проект получил поддержку The Bancroft Library в Беркли и Калифорнийского университета, в отделе библиотечных систем которого размещён сайт.
В начале 2000-х часть текстов писателя закодировали по стандарту TEI на XML. Благодаря ему на сайте появились неопубликованные письма Твена и 30 ранее изданных томов. Доступ к материалам не ограничен, однако их невозможно скачать.
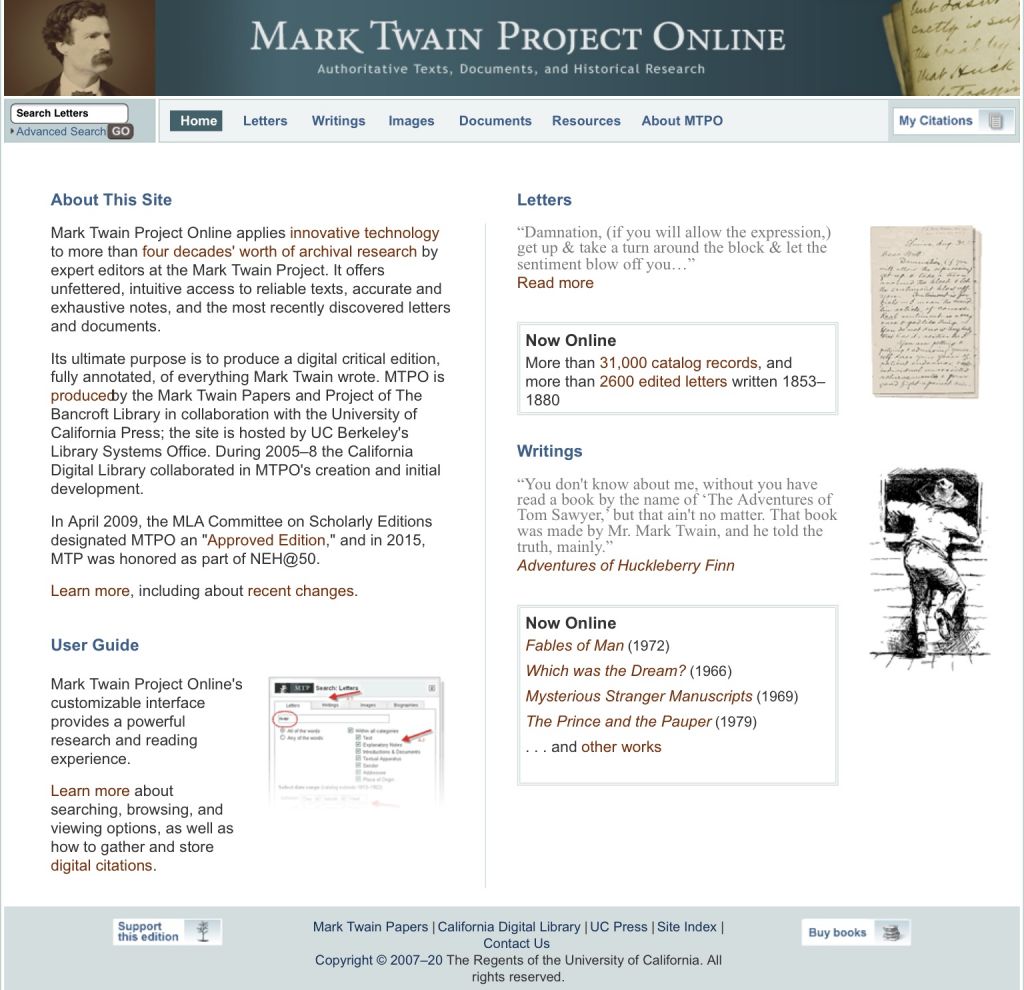
Сейчас корпус состоит из более чем 31 000 записей каталога и более 2600 отредактированных писем периода между 1853 и 1880 гг. Портал содержит ссылки на руководство для посетителей, ранние исследования, биографию писателя, описание материалов и их хронологический список. Часть текстов имеет отсканированные факсимиле, которые можно сравнить с работой редакторов.
Инструменты писем предлагают читателям настраивать целевой поиск, задавать его параметры и временные диапазоны. Система фокусируется на определенных коллекциях и выдает результаты, которые можно сортировать. Возможен поиск отдельных записей по вводным словам и страницам текстов.


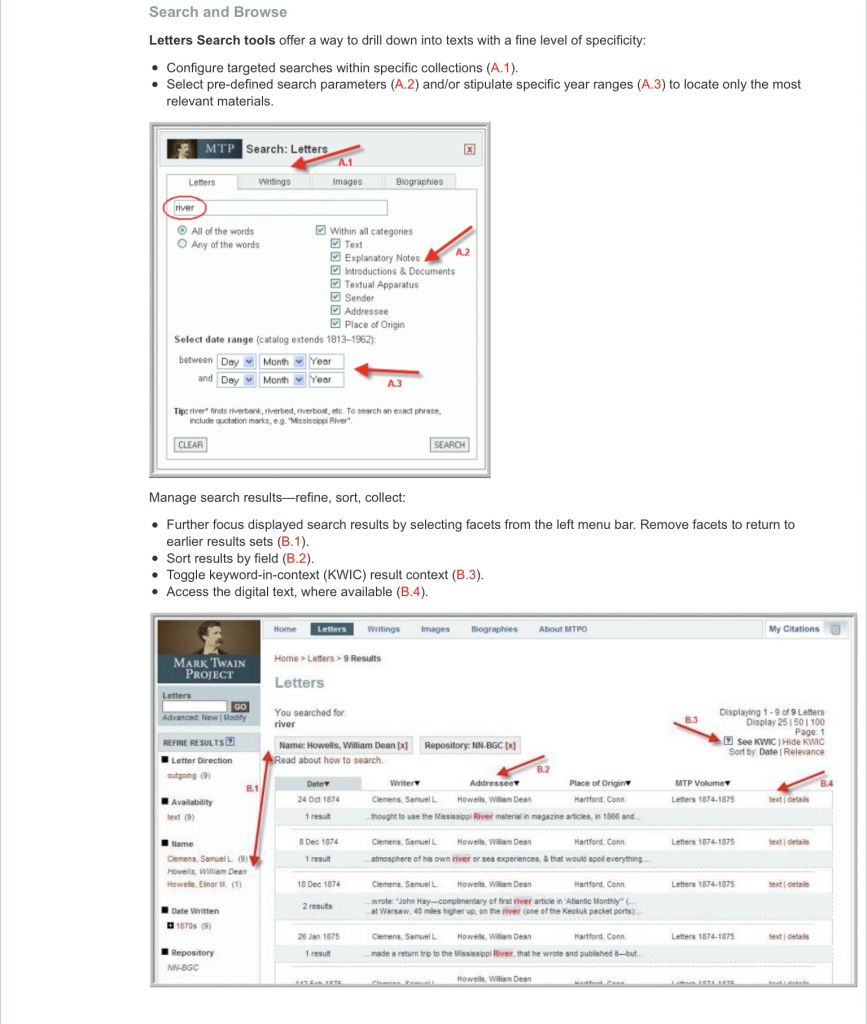
1 — Фрагмент оцифрованного письма и цитата. 2 — Подпись к фотографии Твена с друзьями. 3 — Подробное объяснение работы инструментов для читателей корпуса
Материалы пользователей сохраняются в My Citations. Этот инструмент позволяет хранить цитаты, ссылки, части документов, изображения и другие ресурсы. Получить заметки в личное пользование можно только с помощью электронной почты.
Примечания
- [1] Формат преобразования Юникода, 8-бит (UTF-8) — распространённый стандарт кодирования символов. Он позволяет более компактно хранить и передавать символы при использовании переменного количества байт (от 1 до 4).
- [2] TEI расшифровывается как «Инициатива по кодированию текстов» — это сообщество практиков, которые занимаются цифровыми гуманитарными науками. Поподробнее про TEI можно прочитать тут и на официальном сайте инициативы
- [3] XML — расширяемый пользователем язык с простым формальным синтаксисом, который удобен для создания и обработки документов программами. Он также помогает в чтении и создании документов с целью использования информации в Интернете.

