
Мы уже писали о NLP — это направление в компьютерных науках, посвященное обработке естественного языка, языка человеческого общения. Именно специалисты NLP развивают возможности по машинному пониманию естественных текста или речи. В числе базовых задач NLP — Named-entity recognition (NER, выделение сущностей) и Entity Typing (ET, классификация сущностей).
NER и ET— важные задачи для индустрий, где нужно обработать большое количество неструктурированной информации: помочь чат-боту понять, что хочет пользователь, автоматически разобрать по папкам задачи в загруженном рабочем e-mail…
А для «цифровых гуманитариев» это важнейшие инструменты исследования текстов. С помощью NER и ET филологи подсчитывают, сколько раз появляется персонаж в тексте, строят сеть связей между героями книг, собирают все прозвища героя, а историки работают с оцифрованными текстами древних рукописей.

Какие люди в Средиземье!
Обычно для классификации сущностей — то есть для выделения особенностей сущности — используются тексты Википедии. Например, программа, получив на вход предложение «В Испании медики выявили самый ранний симптом COVID-19» (REGNUM, 18 июля 2020) может легко понять, что «Испания» — это страна, «медики» — социальная группа, «COVID-19» — вирус. Эту информацию программа получает, «просматривая» статьи Википедии.
Этот метод работает, если нужно разобрать текст о реальном мире: классическая система NER+ET справится. А если мы скормим программе, например, текст «Властелина Колец»? Программа не сможет выдать нам полный результат, т.к. в Википедии не хватает информации о вымышленных вселенных. Компьютер найдет в Википедии статью о Гендальфе, но вот с определением народности персонажа-человека у него могут возникнуть проблемы:
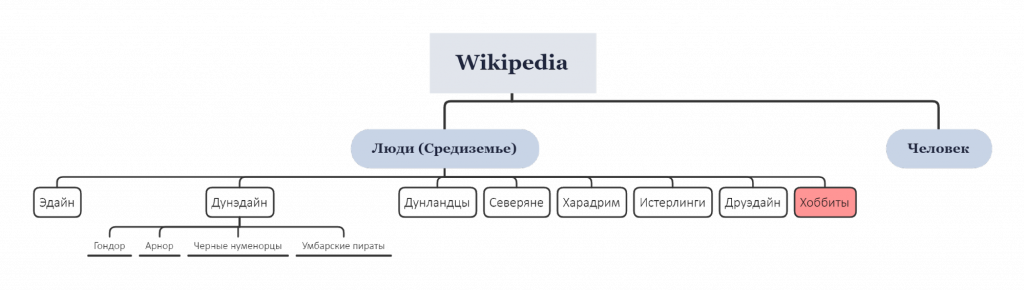
Из Википедии программа получит примерно такое представление о народностях людей мира Толкиена. Она поймет, что статья «Человек» о реальных homo sapiens нерелевантна для нашего запроса. Но вот понять, кто из героев к какой народности относится только на основании информации из Википедии — вряд ли сможет.
Над решением этой задачи работали исследователи из Института Макса Планка, и результатом их работы стала система ENTIFY (ENtity TYping on FIctional texts), которая может работать с художественными текстами, в том числе и фэнтези и science-fiction вселенными: разработчики уделили им особенное внимание.
Хоббит — тоже человек!
В основе ENTYFI лежит тот же принцип, что и в базовых инструментах NLP — поиск и классификация сущностей, но к корпусу текстов из Википедии добавляются размеченные тексты с платформы Wikia. Это платформа, которая позволяет создать отдельные тематические википедии о вселенных из книг, кино, игр и т. д. Сейчас проект сменил название на Fandom и многие новые вики-проекты работают на домене fandom.com, но есть старые, оставшиеся на домене wikia.
ENTYFI обладает более полной информацией о мире, который описывается в тексте и может точнее определить, что перед ней за сущность. Например, поймет и укажет, что «Фродо Бэггинс» — не просто «хоббит», но добавит к перечню его меток (особенностей, «классов») ещё и «мохноног» (harfoot) — одно из племён хоббитов (есть ещё «лесовики»/fallohides и «хваты«/stoors).
Чем плох ENTYFI
Во-первых, нельзя сказать, что на Wikia (Fandom) созданы проекты об абсолютно всех вселенных, которые когда-либо были придуманы. Далеко не все Вики-проекты заполнены — например, нет проекта о «Саге о Форкосиганах». С учетом того, что в корпус ENTYFI входят те вики, где статей более тысячи, это сужает поле возможностей.
Во-вторых, есть проблема с верификацией: на Fandom редактировать статьи может любой человек. В отличие от Википедии здесь нет проверок со стороны редакторов. На Википедии работа редактора позволяет сохранить информацию актуальной и уберечь ее от троллей. Несмотря на стереотип о том, что «Википедию может редактировать любой», внести туда недостоверную информацию, особенно в статьи на крупных языках типа английского и русского, довольно трудно.
В-третьих, иногда и человек не может точно наделить сущность какой-либо меткой/классом: например, до сих пор не всем понятно, можно ли считать хоббитов из «Властелина колец» — народностью людей или же просто «родственной» расой. ENTYFI может ошибаться из-за неточностей, закладываемых в тексты Wikia людьми.
Всем сущностям выйти из сумрака!
Перед тем, как искать особенности сущностей для того, чтобы наделить их метками, статьи Wikia объединяются в группы по принципу отношения к определённой вселенной (Властелин колец, Гарри Поттер, Марвел).
Дальше программа ранжирует массив «каноничных вселенных» по количеству совпадений в статьях Wikia об одной вселенной и анализируемом тексте. Затем с помощью нейросети LSTM (мы рассказывали об устройстве этого типа нейросетей) выделяются сущности. Эта нейросеть может работать с контекстом, запоминая или забывая ту или иную информацию.

Дальше программа ищет найденные в тексте сущности в корпусах Wikia и Википедии. Последняя нужна здесь для случаев пересечения с реальным миром. Например, Кольцо Всевластья это не только могущественный артефакт, созданный Сауроном, но и ювелирное украшение. Для Толкиена и его читателей это очевидный факт, а компьютеру в таких случаях надо помогать, помогая ему найти информацию и о реальном мире.

Текст разберем на метки и префиксы во имя сущностей понимания!
Одновременно с этими процессами проходят еще два: авторы ENTYFI называют их Unsupervised typing и KB lookup. Unsupervised typing — это поиск класса сущности внутри того предложения, в котором сущность найдена.
ET при нахождении сущности подразделяет ее на токены (слова в ней), находит его класс (метку) и добавляет к ним префиксы — элементы разметки текста. В NLP есть несколько систем префиксов, в случае с ENTYFI мы работаем с BIOES-префиксами. Эти префиксы позволяют системе понять, из одного ли слова состоит сущность, а если нет, то где первое его слово, где последнее, что посередине, а что и не сущность вовсе.
- Beginning — первый токен сущности;
- Inside — токены, находящиеся между первым и последним токеном сущности;
- Out — по факту, сам по себе токен, присваивается не сущностям. Существует разметка BIES, где OUT попросту не используется;
- End — последний токен сущности;
- Single — префикс, добавляемый к метке, если сущность состоит из одного слова.
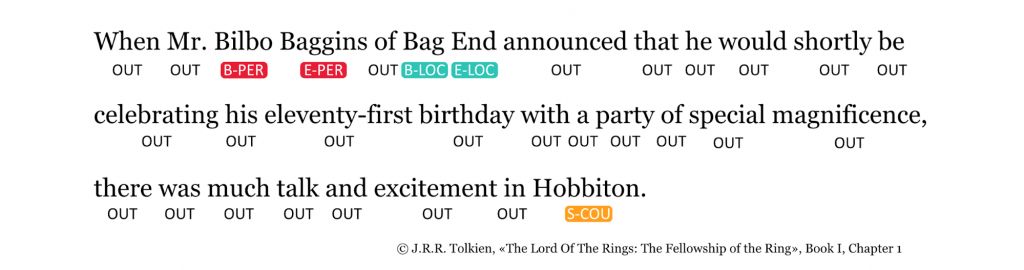
Например, в предложении «The eldest of these, and Bilbo’s favourite, was young Frodo Baggins» программа находит сущность Frodo Baggins. Она разметит «Frodo Baggins» как «B-PER E-PER» и по второй метке (Baggins) определит, что Фродо — родственник Бильбо Бэггинса. Это и есть Unsupervised typing.
KB lookup — метод, позволяющий вычислить класс (метку) сущности через контекст, который есть в анализируемом тексте. Сначала программа анализирует то, что вокруг сущности (не обязательно близко по тексту), выделяет контекст, формирует связи и из этих связей выделяет классы (метки) сущности.
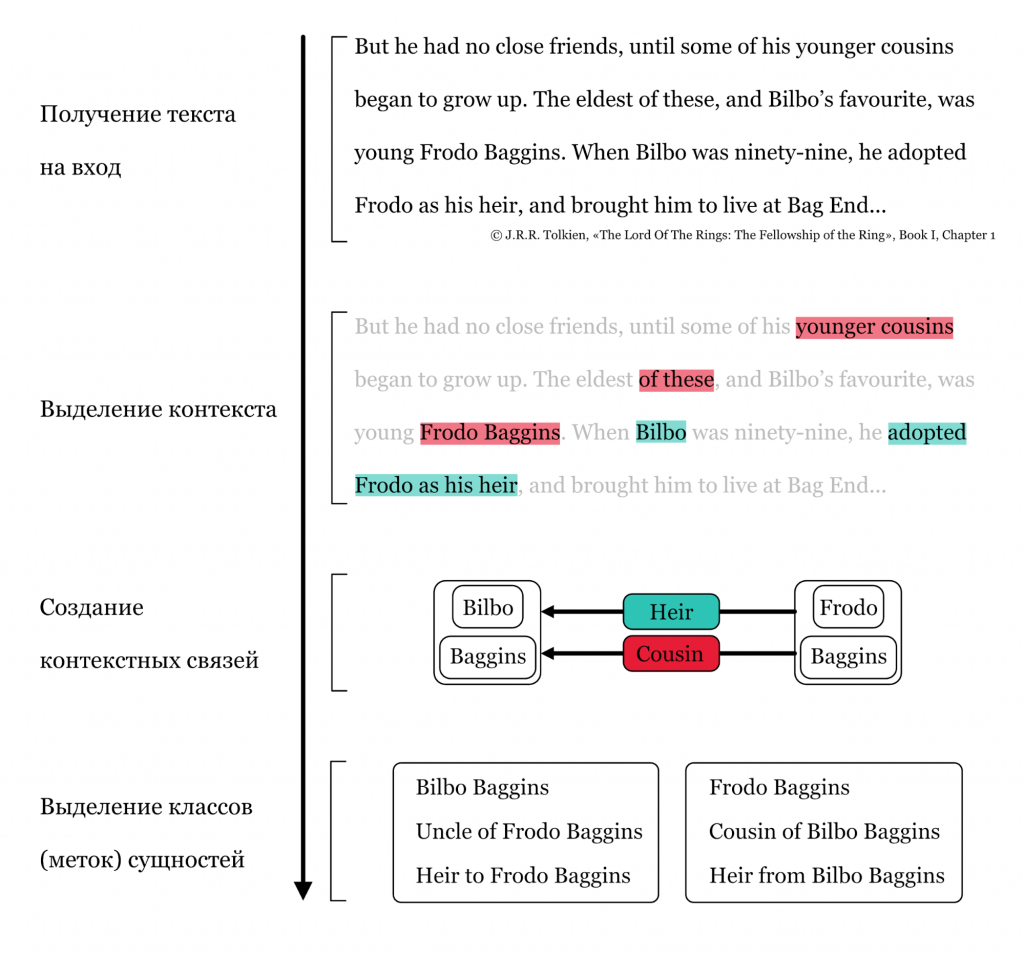
Затем вся полученная информация консолидируется — все выделенные метки сущностей собираются. На данном этапе использовать LSTM и любые другие нейронные сети бесполезно, поэтому работа над консолидацией идет с использованием методов Inductive logic programming — Индуктивного логического программирования. Система перепроверяет метки (классы), которые она присвоила персонажам. Разберем этот метод на примере все тех же Бэггинсов.
Уже в первой главе «Братства Кольца» Фродо сначала называют cousin (кузеном) Бильбо, а затем nephew (племянником). Можно ли быть одновременно кузеном и племянником одному и тому же человеку? На этапе проверки выданных меток с помощью методов индуктивного логического программирования ENTYFI узнает, что Дрого Бэггинс, отец Фродо Бэггинса, ещё и троюродный брат Бильбо Бэггинса по мужской линии; а Примула Брендибак, мать Фродо Бэггинса — двоюродная сестра Бильбо Бэггинса по женской линии. Следовательно, Фродо Бэггинс — дважды племянник Бильбо Бэггинса: двоюродный по матери и троюродный по отцу. Поэтому в «борьбе» меток cousin и nephew победит последняя — потому что Фродо действительно племянник, а не кузен Бильбо.
Сопоставив факты, программа понимает, что «cousin» в тексте означает не совсем кузенов, и четко понимает связи между персонажами-сущностями, и окончательно ставит на Бильбо и Фродо метки «Дядя» и «Племянник» соответственно.
А попробовать можно?
Авторы ENTYFI выложили исходный код программы на Github. Если вы хотите попробовать классификацию сущностей, но вам не обязательно работать именно с художественными текстами, вот прекрасный демонстратор возможностей библиотеки SpaCy для Python.
Источники
- Cuong Xuan Chu, Simon Razniewski, and Gerhard Weikum. 2020. ENTYFI: Entity Typing in Fictional Texts. In Proceedings of the 13th International Conference on Web Search and Data Mining (WSDM ’20). Association for Computing Machinery, New York, NY, USA, 124–132. DOI
- NLP – это весело! Обработка естественного языка на Python
- LSTM – сети долгой краткосрочной памяти
- NLP. Основы. Техники. Саморазвитие. Часть 2: NER
- Введение в машинное обучение

