Некоторое время назад «Системный Блокъ» уже писал о сетевом анализе драматических произведений (про смерть и про жанровые различия). За прошедшее время были выполнены ещё несколько исследований корпуса русских драматических произведений*, который на момент подготовки материала насчитывал 198 произведений. Для корпуса реализовано API с широким набором функций, позволяющими каждому читателю попробовать себя в роли цифрового литературоведа.
Целью этой статьи было исследование возможности математически выявить главных персонажей пьес (протагонистов), а также попробовать численно разделить персонажей на группы в соответствии с их значимостью.
«Важность» персонажа можно оценить по-разному: например, как количество произнесённых слов или как количество его взаимодействий с другими героями. Мы использовали 8 метрик, чтобы как можно более полно рассмотреть структуру действующих лиц в каждой пьесе. Все эти метрики можно разделить на сетевые (5 штук) и количественные (3 штуки).
Сетевые метрики
Для персонажей каждой пьесы были вычислены 5 сетевых метрик: степень, взвешенная степень, степень близости, степень посредничества и степень влиятельности. Подробно про них было рассказано в предыдущей статье. Каждая из них отражает разные нюансы взаимосвязей между героями. Использовавшиеся сетевые метрики также называются мерами центральности сетей, так как они показывают, насколько центральное положение в графе занимает узел.
Количественные метрики
Сетевой подход не может описать отношения между персонажами в полной мере. Есть немало пьес, в которых все персонажи взаимодействуют между собой и получается, что такой граф персонажей — полный (то есть каждая вершина соединена с каждой) и метрики всех вершин такого графа одинаковы. В подобной ситуации полезно посмотреть на более понятные количественные характеристики. Мы взяли количество слов, произнесенное персонажем, количество реплик персонажа и количество его появлений на сцене.
Как и в случае с сетевыми метриками, эти три значения немного по-разному характеризуют важность персонажа. Есть персонажи, которые произносят много текста, но он заключается в нескольких монологах, а есть те, кто появляется часто на сцене и произносит краткие реплики. В первом случае персонаж может быть тогда и не так важен в пьесе, как это мог бы показать лишь подсчёт слов, в то же время персонаж с малым количеством слов, но более часто появляющийся на сцене, является более значимым.
Все полученные метрики для удобства были переведены в ранговые значения. Для каждой группы измерений была подсчитана средняя позиция персонажа как среднее арифметическое и затем также переведена в ранговые значения. Вот как выглядит данная информация для шестнадцати персонажей пьесы «Ревизор» (герои отсортированы по столбцу «Общая позиция», который является средним арифметическим двух предыдущих столбцов):
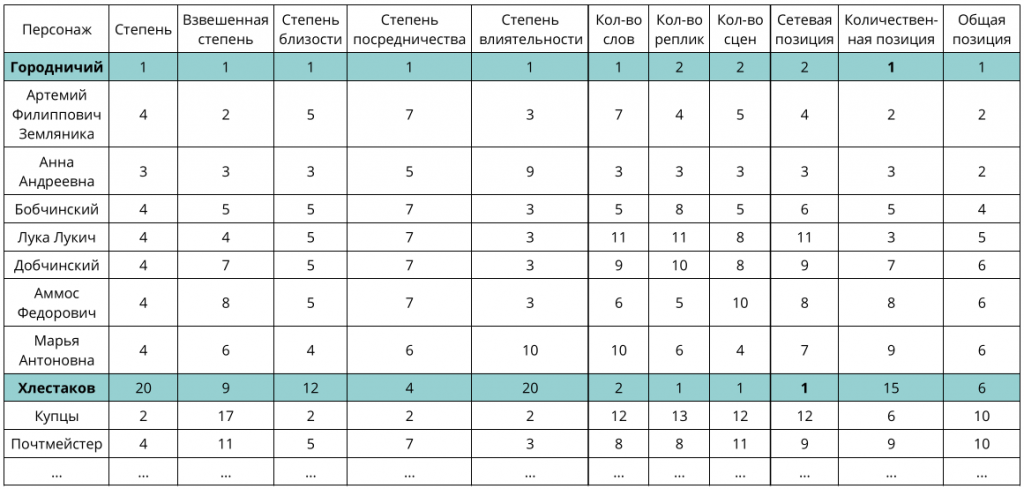
Причём тут «Ревизор»?
Оказалось, что в пьесе «Ревизор» Н.В. Гоголя, Хлестаков лидирует по количественным метрикам, а Городничий — по сетевым. Если вспомнить сюжет, то объяснение становится очевидным: Городничий как глава города прочно связан с жителями; в то же время Хлестаков постепенно знакомится с жителями и поэтому много говорит с теми, кого уже знает. Ниже приведена сеть персонажей пьесы «Ревизор».
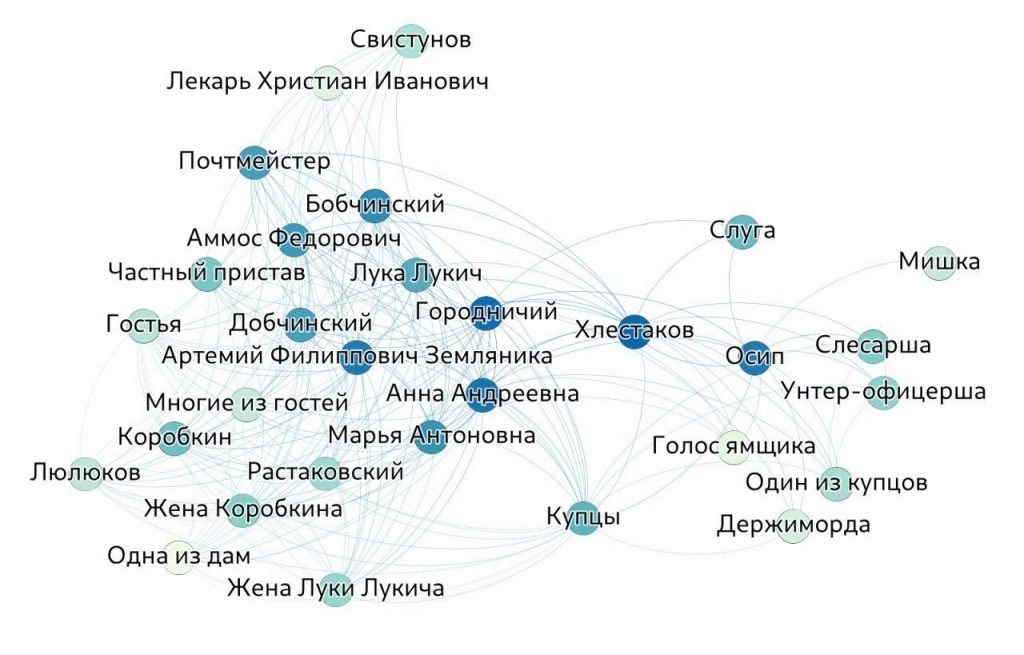
Деление на группы значимости
Чаще всего легко определить главных героев и самых незначительных. Тех же кто оказывается в середине этого субъективного деления распределить по важности уже сложнее. В 1970-х теоретик драмы Манфред Пфистер предложил деление персонажей на четыре группы: главные, второстепенные, незначительные и вспомогательные (функциональные). Мы придерживались этой концепции и разделили персонажей каждой пьесы на четыре группы.
Но вопрос, где именно должны проходить границы между группами, сохранялся: это должно было быть корректно и с литературной точки зрения, и с численной. Мы использовали функцию cut языка программирования R, которая вычисляет разницу между минимальным и максимальным значением и делит эту величину на необходимое число частей (в нашем случае 4). Таким образом получаются интервалы одинаковой длины, но каждому из них принадлежит разное число объектов.
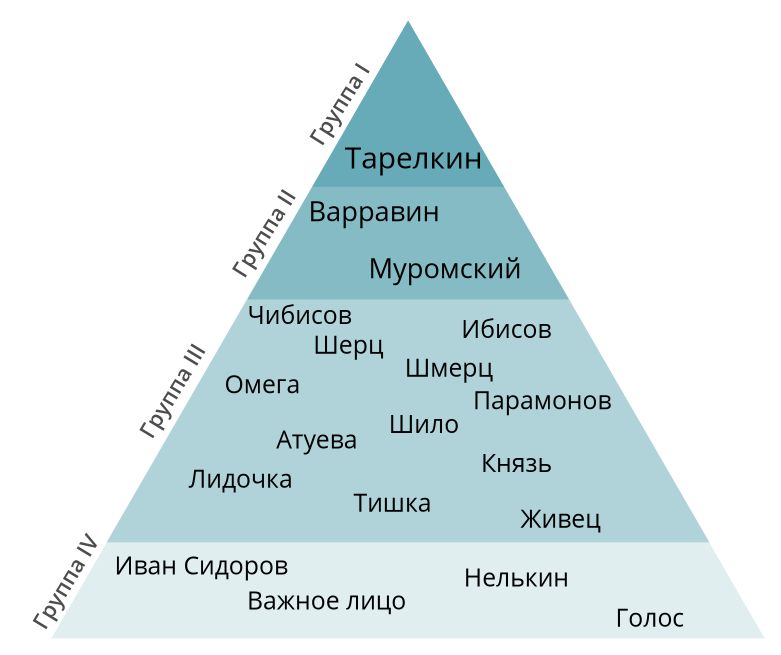
Персонажи каждой пьесы были разделены на четыре группы по каждой из восьми метрик. Вот как выглядит это распределение по степени, показанное в виде пирамиды для пьесы «Дело» А.В. Сухово-Кобылина:
Затем для каждой пьесы посчитали сколько процентов персонажей входят в каждую группу и уже для этих значений посчитали средние величины по всему корпусу. Мы получили процентное распределение групп персонажей по каждой из метрик. Вот оно:
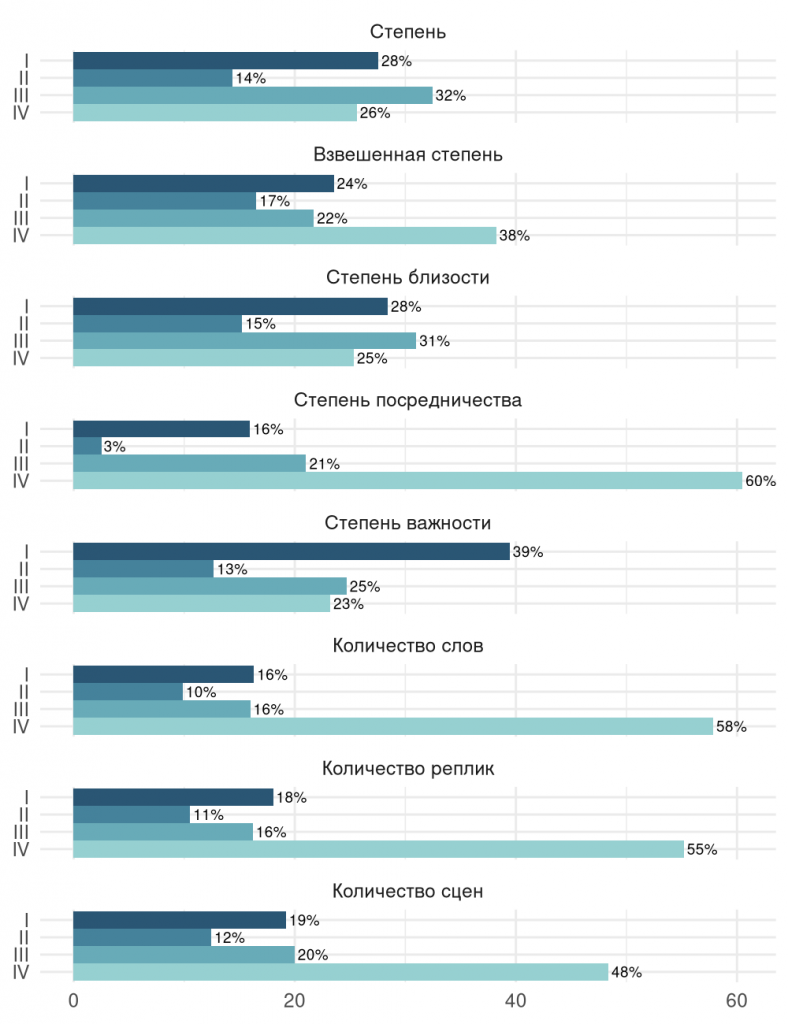
На графике сразу видно визуальное сходство между распределением персонажей по количественным метрикам: большая часть героев мало говорит и проводит на сцене не так много времени.
Также интересно распределение персонажей по степени близости. Только 15% персонажей находятся в положении, обеспечивающим им высокий показатель близости, и это соотносится с тем, как всё обстоит на самом деле: в сети не может быть много узлов с высоким показателем степени близости.
Любопытно, что по остальным сетевым метрикам (степени, взвешенной степени, степени близости и степени важности) распределение по группам более равномерное. Получается, что выделяется группа главных персонажей — в среднем от 24% до 39% от общего количества героев.
Изменение доли главных персонажей с течением времени
Разделив действующих лиц на группы в соответствии с их значимостью, мы посмотрели, как со временем менялась доля главных персонажей. На графике ниже представлена зависимость доли персонажей первой группы (определённой по степени персонажа) от времени создания пьесы.
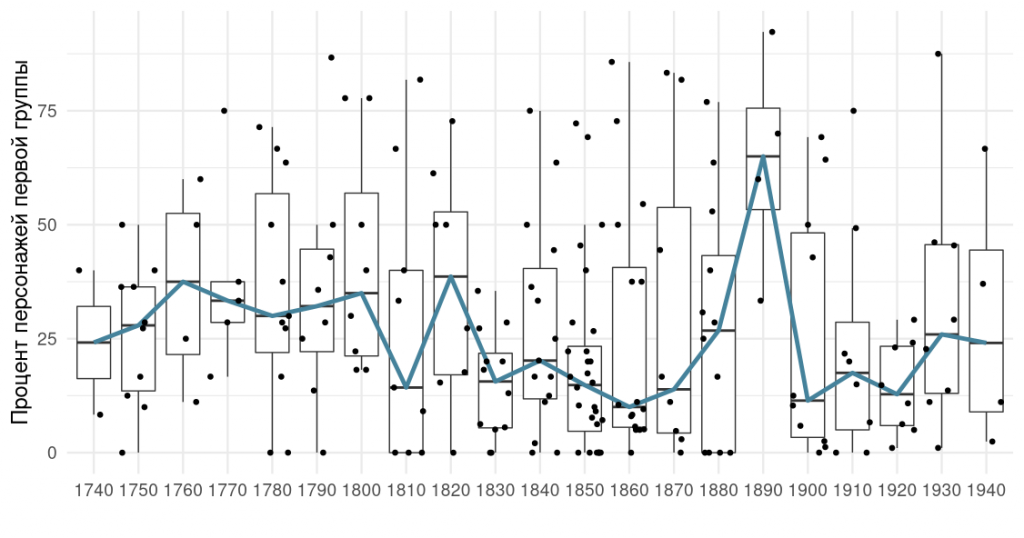
На графике сразу заметен пик, приходящийся на 1890-е годы. В это десятилетие корпус представлен четырьмя произведениями А.П. Чехова: «Дядя Ваня», «Юбилей», «Чайка» и «Свадьба». Пьесы Чехова действительно выделяются, так как в них почти все персонажи общаются со всеми (что подтверждается тем, что средняя длина пути в графах этих пьес приблизительно равна 1) . Возможно, это связано с происходящим в те годы постепенным разрушением сословных границ и изменением общества в целом.
Заключение
Пока в исследовании использовались лишь деления по отдельным метрикам и нельзя однозначно сказать, какая из них лучше подходит для ранжирования персонажей. Подсчитанное среднее значение является лишь примерным показателем и не претендует на полноту описания концепции «важности» персонажа. Однако было бы интересно попробовать разработать такую метрику, которая бы учитывала нюансы текста и позволяла бы объективно распределить героев по важности.