Античный текст и цифровые технологии
Антиковедение – обширная научная область по изучению древнегреческой и древнеримской культуры. Античностью занимаются историки, филологи, искусствоведы, археологи, историки философии, культурологи…
Один из важнейших источников в антиковедении – текст. Обычно у незнакомых с классической филологией людей возникают такие вопросы:
- Античные тексты были созданы очень давно, значит ли это, что они все уже досконально изучены?
- Классическая филология (наука об античной литературе и языках) – это что-то сложное, скучное и несовременное?
Вовсе нет! Античностью продолжают заниматься, исследования античных текстов не исчерпали себя, и классическая филология не уходит в прошлое. А с появлением компьютеров для изучения древнегреческих и латинских текстов стали применяться цифровые методы.
Классическая филология – одна из первых гуманитарных областей, в которых стали использоваться компьютерные технологии. Считается, что первый проект в области цифрового антиковедения (Digital classics) был создан в 1960-е гг. – это был конкорданс ко всем дошедшим до нас текстам древнеримского историка Тита Ливия [1]. Этот масштабный проект был осуществлен в Гарвардском вычислительном центре при помощи компьютера IBM. Полученный в результате работы индекс слов содержит около 500 000 вхождений в формате KWIC (Keyword-In-Context).

Фрагмент страницы из «A Concordance to Livy» [1]
Для каждого словоупотребления дается контекст – около 20 слов слева и справа – а также номер книги, главы и параграфа, откуда взята строка.
Стилометрия в антиковедении
Тогда же, в 1960-е – 1970-е, появляются и первые работы, посвященные изучению стиля античных произведений при помощи цифровых методов (например, стилометрическое исследование текстов древнегреческого историка Ксенофонта [2]). Стилометрия — это метод статистического анализа стилистики текста. «Системный Блокъ» уже не раз рассказывал об этом подходе, который становится всё более популярным (см. подборку 7 наших статей по стилометрии).
Сейчас стилометрические исследования больше всего известны в области атрибуции, то есть определения авторства, и иногда это настоящие детективные истории. Однако стилометрия не ограничивается только этим: она может помочь и в вопросе датировки текста, и в исследовании индивидуального авторского стиля.
Стилометрия применяется и в области антиковедения. Атрибуция, датировка и стилистика – это ли не основные вопросы, которые стоят перед исследователем античности? Один только «гомеровский вопрос» остается открытым уже многие века: мы до сих пор достоверно не знаем, кто автор эпических поэм «Илиада» и «Одиссея». Примеры количественных исследований на эту тему смотрите в списке литературы ниже [3] – [6].
Не менее интересен и другой «кейс» – Платоновский корпус (Corpus Platonicum). Это собрание произведений, написанных под именем древнегреческого философа Платона. В Платоновский корпус принято включать 36 текстов, организованных по тетралогиям, и несколько произведений спорного авторства, не вошедших в тетралогии. Все ли тексты были созданы самим Платоном, или некоторые написаны его учениками и последователями из Академии? В какой последовательности писались эти произведения? Насколько тексты из Платоновского корпуса стилистически однородны? Всё это вопросы для стилометрических исследований. Кстати, само слово «стилометрия» и основную идею подхода придумали как раз филологи-классики, занимавшиеся хронологией текстов Платона (Винценты Лютославский, Вильгельм Диттенбергер) еще в конце XIX века.
Исследовательская литература, посвященная формированию Платоновского корпуса, очень обширна. Окинуть взглядом современное состояние этой области можно благодаря недавно вышедшей коллективной монографии «The Making of the Platonic Corpus» [7]. В некоторых исследованиях из этого сборника тоже используются цифровые методы.
Метод Дельта
В современной стилометрии зарекомендовал себя «метод измерения стилистической разницы» – Дельта Бёрроуза. Метод основан на подсчете распределения наиболее частотных слов в текстах. Полученные показатели сравниваются и определяется близость текстов из выборки между собой. На достаточно больших текстах близость коррелирует с авторством: тексты одного автора будут ближе друг другу, даже если в эксперименте участвуют другие авторы того же времени, писавшие на схожие темы и т.п. Авторство – не единственный фактор, влияющий на результат: еще влияют жанр, время написания и другие мета-параметры текста.
Дельта уже доказала свою эффективность в изучении литературы нового и новейшего времени, но будет ли она правильно работать с текстами на древнегреческом языке?
Таким вопросом задалась исследовательница Ольга Алиева – филолог-классик, историк философии. Ольга Алиева преподает в НИУ ВШЭ, руководит проектом «Цифровая античность» и греко-латинским клубом Antibarbari HSE, ведет онлайн-курс по программированию «R для антиковедов».
В этом материале «Системный Блокъ» рассказывает о двух её исследованиях, в которых эффективность компьютерных методов тестируется на древнегреческих текстах. Материалы к исследованиям, в частости, код, доступны в репозиториях автора на GitHub (см. ссылки в разделе Источники).

Платон (результат генерации в Shutterstock AI).Изображение © Ольги Алиевой, аватарка Telegram-канала RAntiquity.
Различает ли Дельта древнегреческих авторов
Метод Дельты уже ранее применялся в исследованиях древнегреческих текстов (см., например, статью Т. Кёнтгеса [8]), но таких «испытаний» было немного. Ольга Алиева в статье «Delta Берроуза для древнегреческих авторов: опыт применения» ставит ряд проблемных вопросов, связанных с использованием Дельты.
Основной вопрос: Насколько эффективен метод Дельты Бёрроуза для атрибуции древнегреческих текстов?
Дополнительные методологические вопросы:
- Какое для древнегреческого языка оптимальное количество наиболее частотных слов?
- Какой может быть минимальная длина отрывка?
- Что более показательно для анализа: использование лемм (слов) или отдельных словоформ?
В своих исследованиях Алиева пользуется языком программирования R. На R написан пакет Stylo, позволяющий работать с Дельтой. Кстати, о том, как провести свой собственный эксперимент при помощи Stylo, читайте в гайде «Системного Блока».
Данные для эксперимента
В экспериментальный корпус вошли 23 прозаических текста 14-ти древнегреческих авторов. Авторы отобраны так, чтобы тексты, представленные в выборке, отличались диалектами, временем написания и жанрами (научная проза, ораторская проза, историческая проза, философская проза и диалог). Все тексты были взяты из корпуса Diorisis, который позволяет извлекать из файлов в формате XML как леммы (в формате Unicode), так и отдельные словоформы (в Betacode без диакритических знаков).
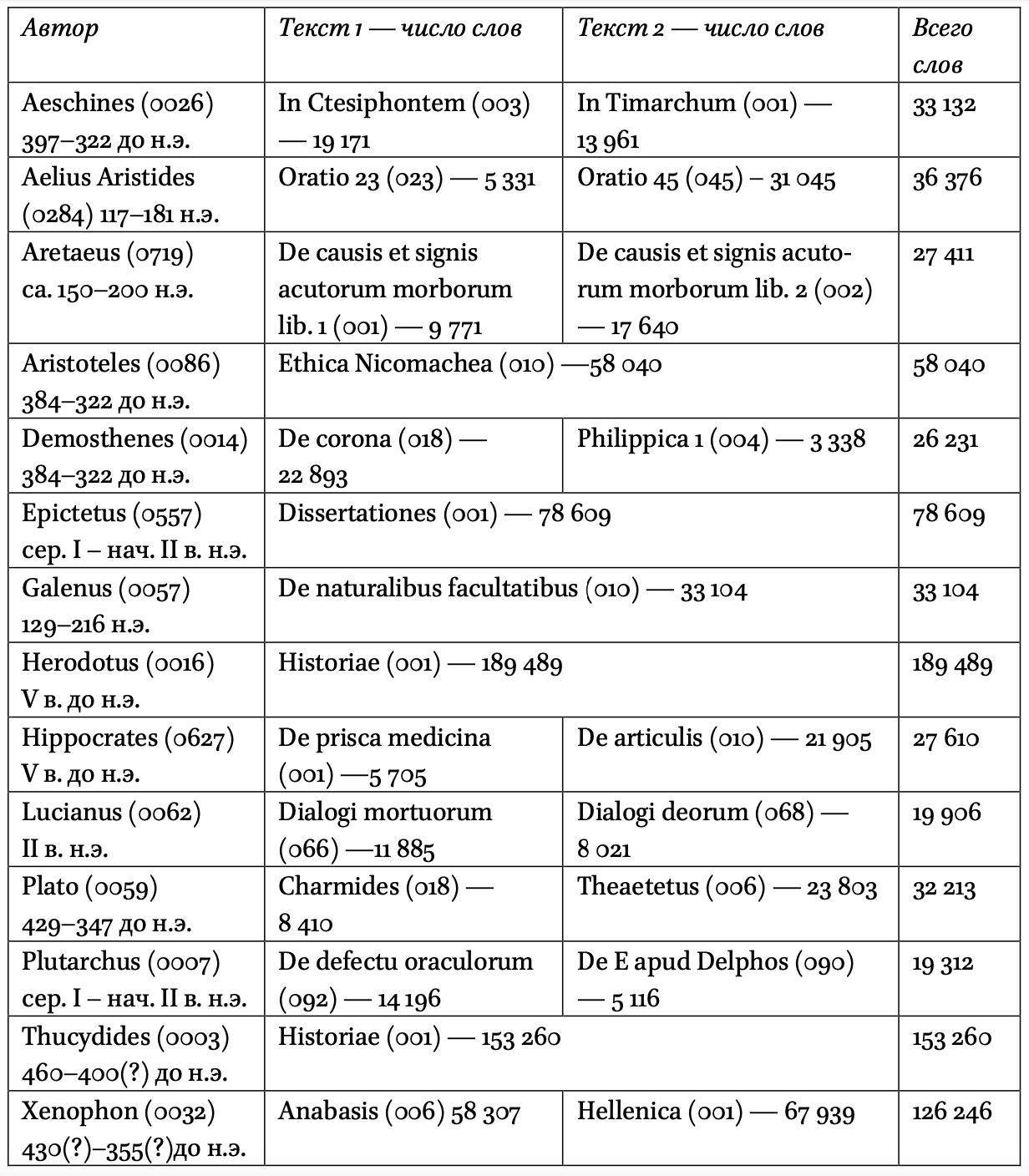
Список авторов и текстов, которые вошли в состав корпуса. Для каждого автора и произведения приведен идентификатор по каталогу Perseus.
Что такое Diorisis?
Это корпус из 820 греческих текстов (от Гомера до начала XV в. н. э.), созданный специально для цифровых лингвистических исследований. Каждое произведение представлено в формате XML (от англ. eXtensible Markup Language – расширяемый язык разметки) и размечено в формате TEI. Также для каждого текста доступны метаданные, например, год написания или жанр. Все слова лемматизированы, то есть приведены к начальной форме, и присутствует морфологическая разметка – можно посмотреть морфологические особенности каждого слова в тексте (часть речи, число, падеж и др).
Подробнее: см. статью создателей корпуса [9]
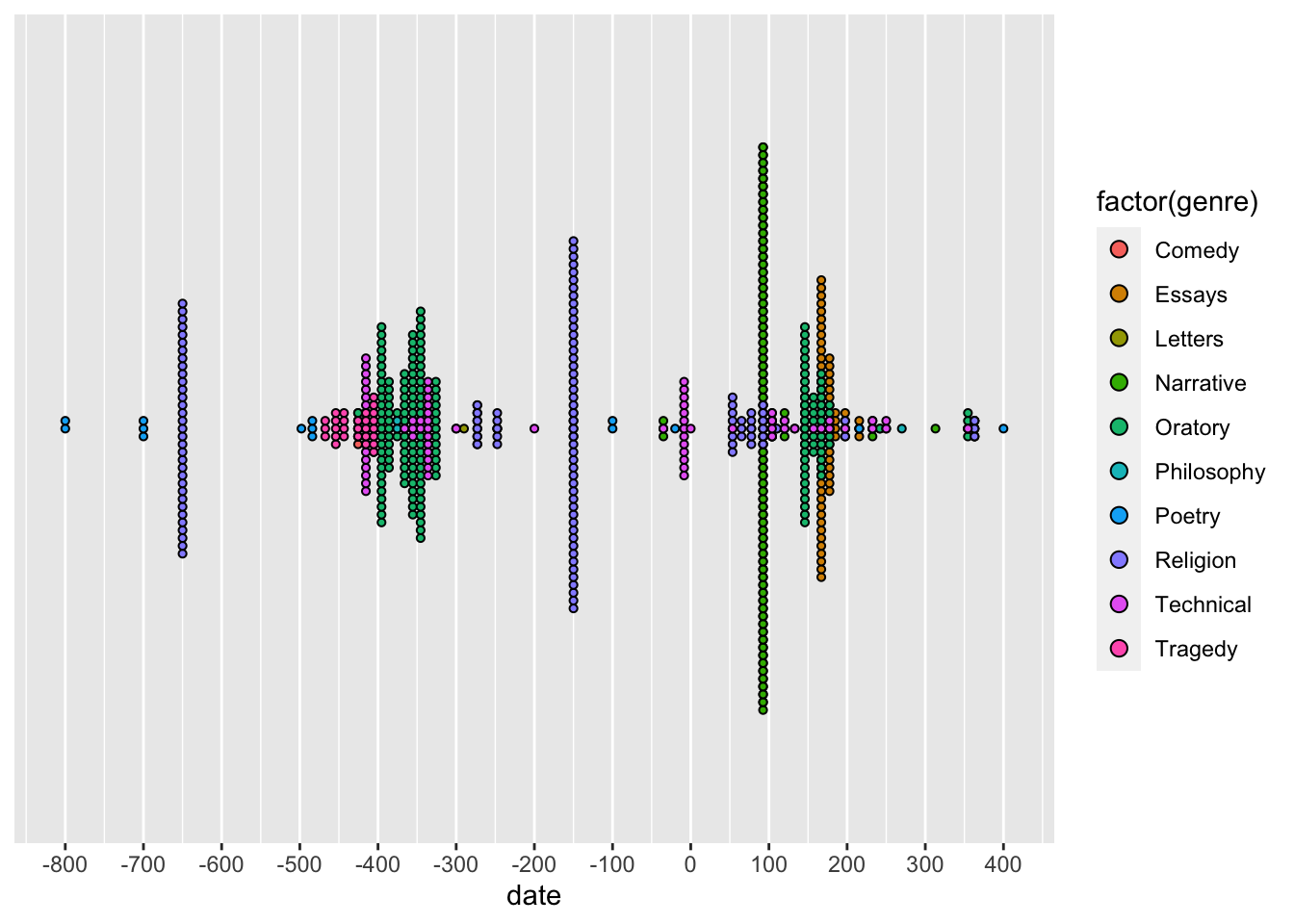
Визуализация содержания корпуса Diorisis: распределение текстов по времени создания, жанру и объему. График Ольги Алиевой
Где ошиблась Дельта
В результате эксперимента подтвердилось, что Дельта неплохо справляется с классификацией древнегреческих текстов. По диаграммам размаха (см. картинку ниже) видно, что медиана точности определения авторства почти во всех случаях близка к единице – то есть почти 100%. При этом точность классификации зависит от длины отрывков: она стабильно повышается при увеличении количества слов с 1000 до 3000, но дальнейшее увеличение до 5000 слов не приносит заметного улучшения. А вот четкой линейной зависимости между точностью атрибуции и количеством наиболее частотных слов (mfw – most frequent words) не прослеживается. Также нет значительной разницы между использованием в анализе лемм или словоформ.
Функция size.penalize из пакета Stylo позволяет получить не только матрицы с данными об успешных классификациях, но и так называемые «матрицы ошибок» (confusion matrices). Благодаря изучению такого рода данных Алиева приходит к еще одному выводу: Дельта каждый раз ошибается на определенной группе авторов. Путаница в определении авторства возникает между текстами ораторов (Эсхина, Аристида и Демосфена), врачей (Гиппократа, Аретея и Галена), а еще «Греческая история» Ксенофонта часто сближается с «Историей» Фукидида. После удаления из выборки текстов Эсхина, Аристида, всех врачей и Ксенофонта точность заметно улучшается, и число успешных классификаций при любых параметрах (длина отрывка и количество частотных слов) приближается к 100%.
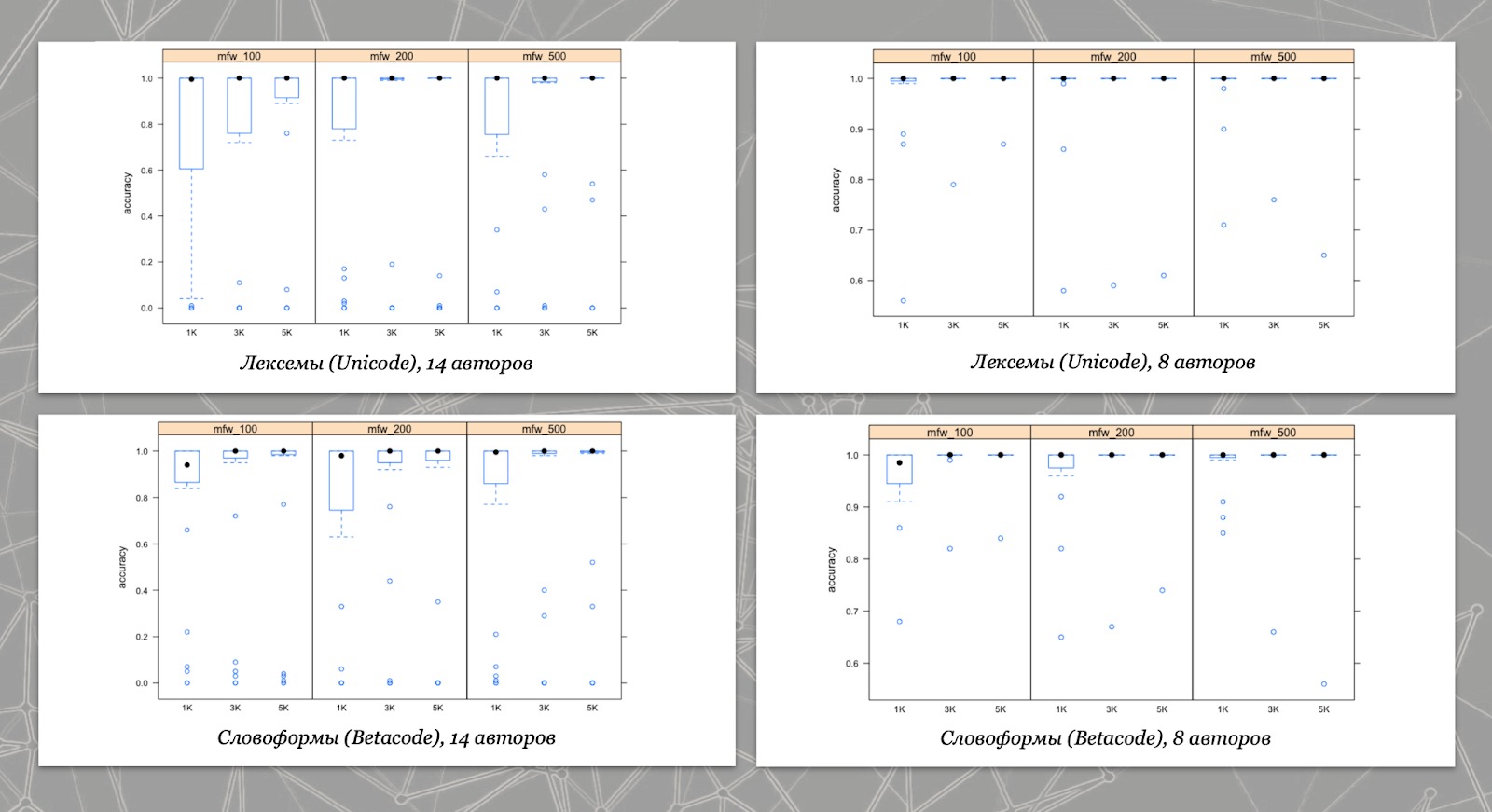
Точность классификации в зависимости от длины отрывка и количества наиболее частотных слов. Результаты представлены в виде графиков типа диаграмма размаха, или «ящик с усами».
Таким образом, больше всего на результат классификации влияет жанровое сходство текстов. Несмотря на хорошие результаты в целом, Дельта оказалась не очень эффективна в определении авторства произведений близких друг другу авторов (такими в корпусе оказались тексты ораторов и врачей). Но ведь именно подобные случаи обычно и интересуют исследователей, когда речь идет о реальных кейсах по атрибуции: выбор кандидатов происходит между очень похожими по стилю авторами.
Однако это не значит, что метод совсем бессилен. Дельта может помочь исследователю, сузив список претендентов на авторство спорного текста. Поэтому в качестве альтернативы Ольга Алиева предлагает составление «шорт-листа». Дельта не обязательно должна присваивать текст одному-единственному возможному автору. Шорт-лист из нескольких позиций позволяет исследователю увидеть наиболее подходящих по результатам анализа кандидатов и сделать свои выводы на основе их интерпретации.
Если не Дельта – то что?
Кроме Дельты Бёрроуза существуют и другие метрики близости текстов. Возможно, они справятся с определением авторства древнегреческих текстов лучше, чем Дельта? Новая статья Ольги Алиевой «Меры расстояний для определения авторства древнегреческих текстов» посвящена обзору и сравнению различных стилометрических метрик.
Основной вопрос: Какие методы стилометрического анализа наиболее эффективны по отношению к древнегреческой прозе?
Дополнительные методологические вопросы:
- Что использовать, чтобы повысить точность атрибуции: словоформы или трехсимвольные n-граммы (с сохранением диакритики)?
- На каких текстах из выборки классификатор чаще всего ошибается?
Методы, эффективность которых тестируется в этом исследовании, известны в англоязычной литературе как distance-based approaches («подходы, основанные на расстоянии»). Дельта тоже один из таких методов, но есть и другие. Все они имеют общий принцип. Представим, что текст (или группа текстов) – это вектор, то есть упорядоченное множество значений. Для каждых двух векторов может быть математически рассчитано расстояние между ними. Чем ближе векторы, тем больше вероятность того, что тексты написаны одним и тем же автором.
В эксперименте сравнивались несколько методов, которые ранее уже успешно применялись в стилометрии. В первую очередь, манхэттенское расстояние, которое лежит в основе Дельты Бёрроуза, а также следующие:
- евклидово расстояние
- косинусное сходство
- расстояние Танимото
- канберрское расстояние
- расстояние Кларка
- расхождение Джеффриса
- расстояние Лаббе
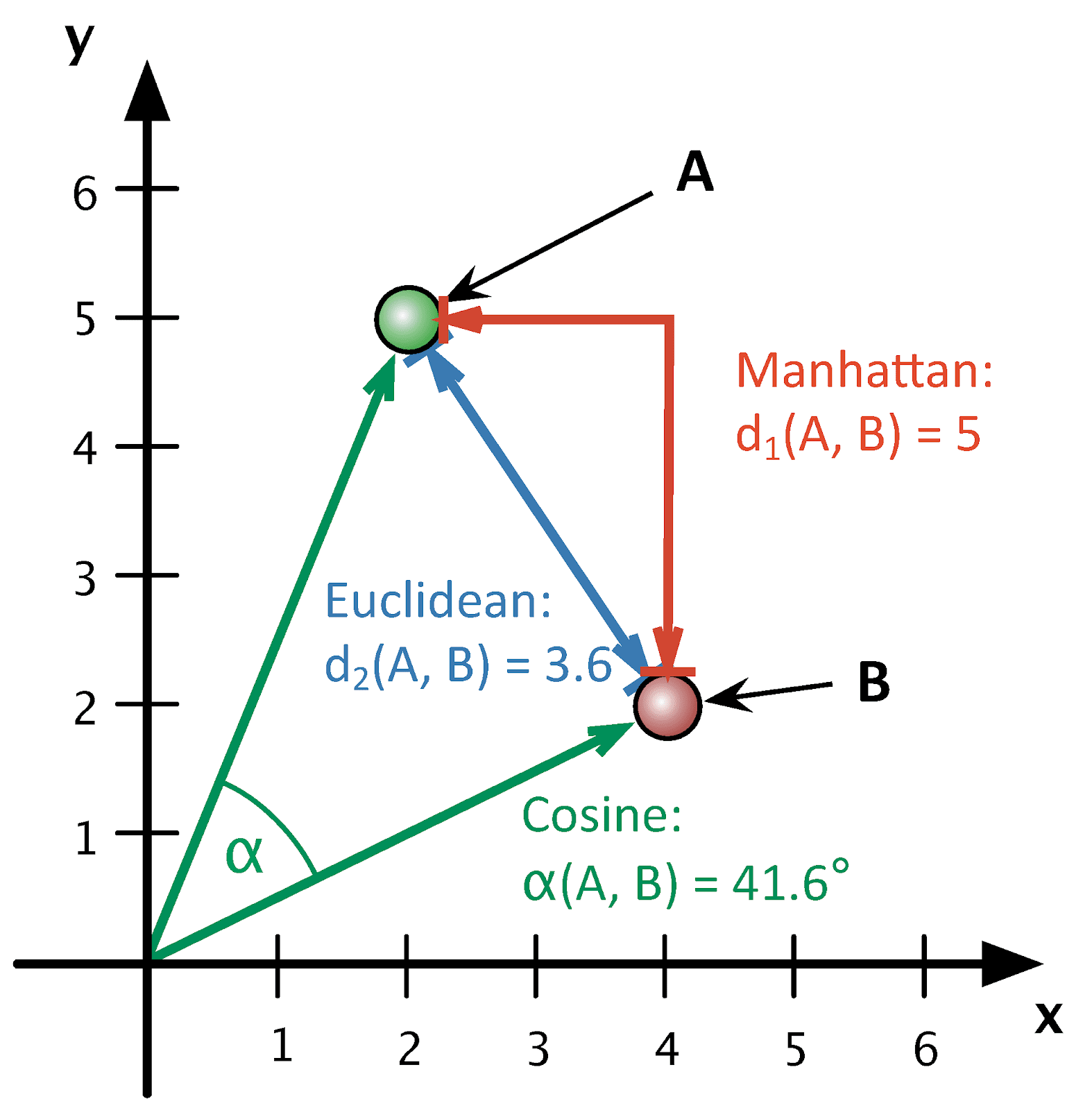
Источник: Outliers or Key Profiles? Understanding Distance Measures for Authorship Attribution
Можно попробовать представить методы, основанные на расстоянии, геометрически. Расстояние между двумя точками в 2D пространстве можно вычислить разными способами: на картинке изображены манхэттенское, евклидово и косинусное расстояния. Только стилометрические методы работают не в двухмерном, а в многомерном пространстве!
Экспериментальный корпус содержит 57 древнегреческих прозаических текстов 17-ти авторов – это 694 тысячи слов. Состав получившегося корпуса расширился по сравнению с выборкой, которая была представлена в предыдущем исследовании. Однако он достаточно несбалансированный, что видно из графика ниже. У некоторых авторов в корпусе представлено больше произведений, чем у других, а также сами тексты различны по объему. Все тексты были взяты в формате XML из библиотеки Perseus.
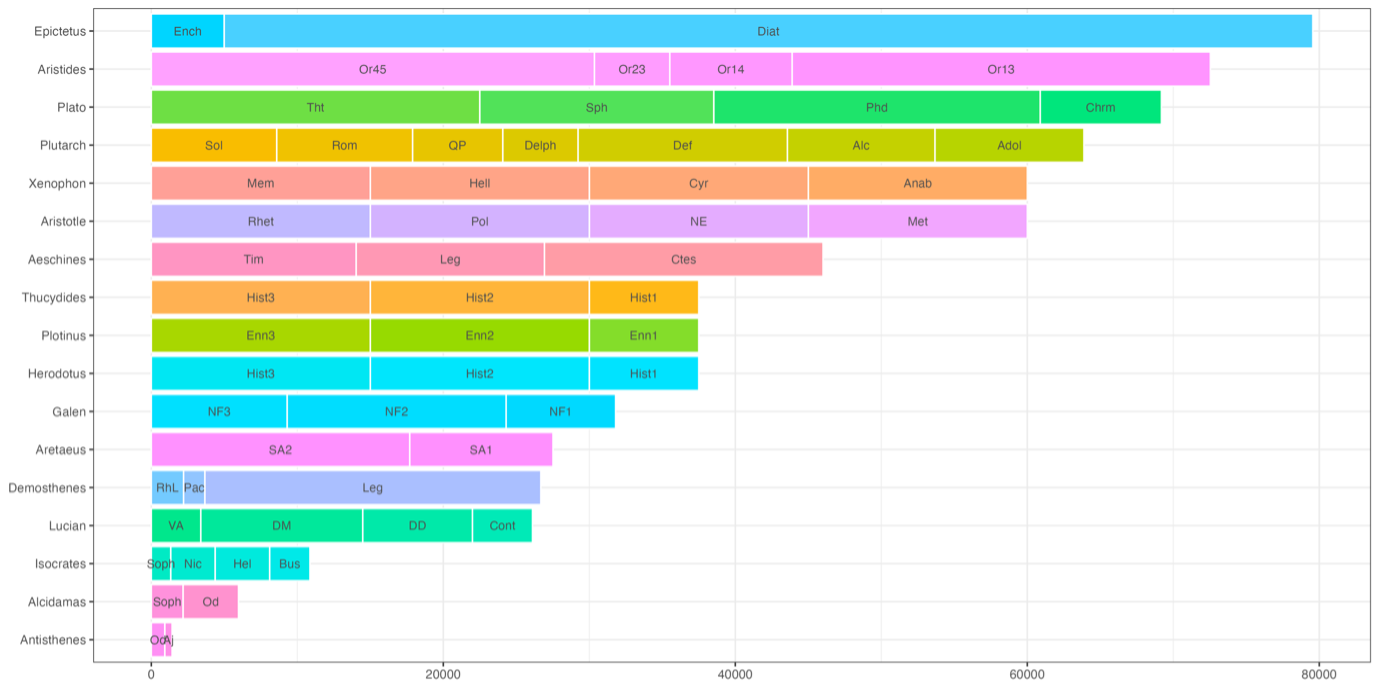
Состав корпуса: визуализировано количество текстов и слов на автора
Что такое Perseus?
Это электронная библиотека, дающая открытый доступ к множеству античных произведений. Первоначально проект был ориентирован на древнегреческие и латинские тексты, но впоследствии коллекция расширилась за счет присоединения корпусов на других языках.
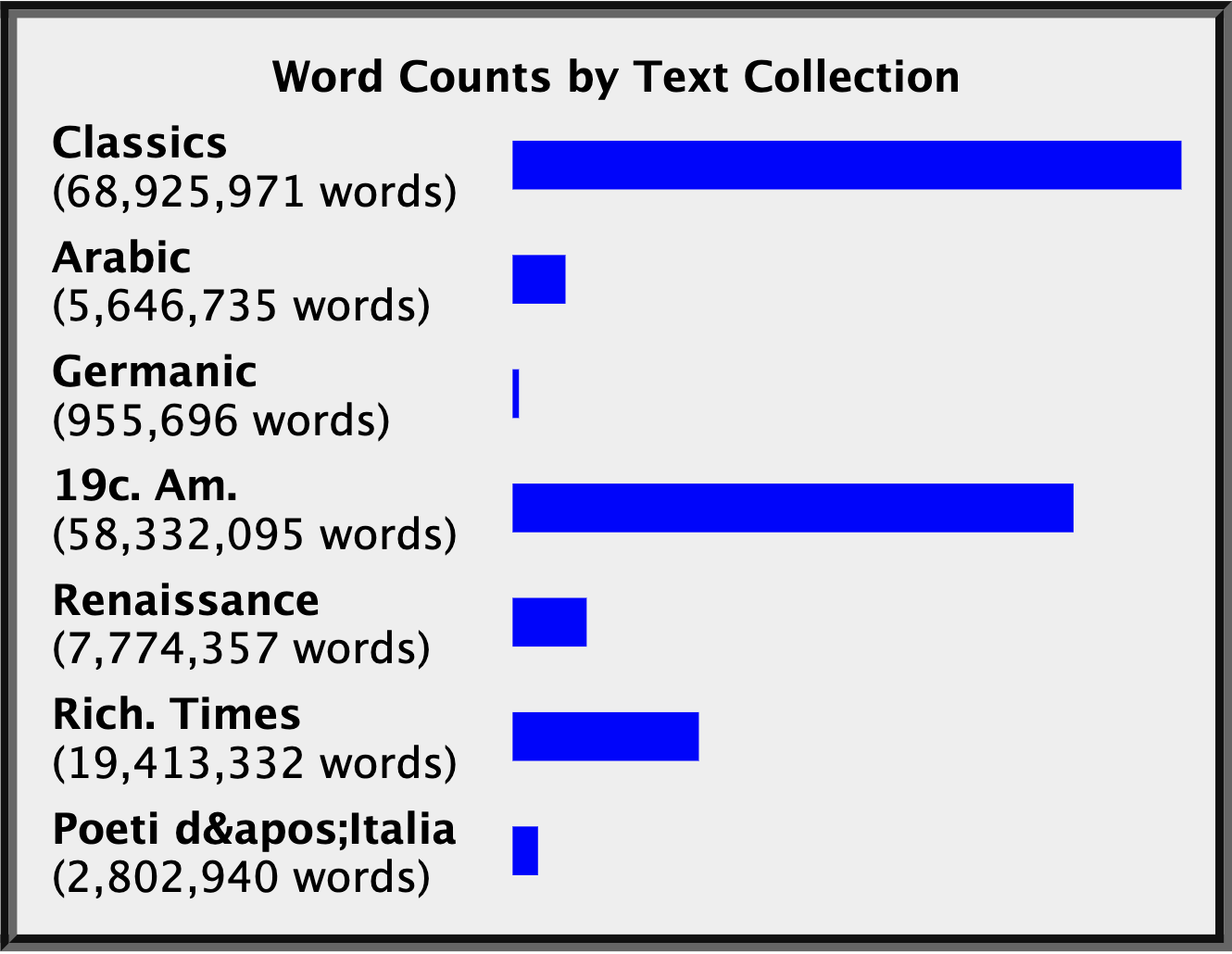
Объем корпусов в библиотеке Perseus.
Источник: раздел Collections/Texts
С материалами Perseus можно работать пользуясь и веб-версией каталога, и XML документами, размеченными по TEI. На сайте проекта есть возможность искать слова по выбранному корпусу, смотреть морфологическую разметку, читать оригинальные тексты с параллельным переводом, смотреть значение слов в словарях и многое другое. А доступ к файлам XML позволяет скачивать античные тексты в удобном формате и проводить с ними собственные исследования.
Как выглядит XML документ из библиотеки Perseus, размеченный в формате TEI
Не все метрики близости одинаково полезны
Итак, в результате ряда экспериментов выяснилось, что на любой длине отрывке и при любом количестве наиболее частотных слов лучшие показатели точности на этом корпусе имеют косинусное сходство, расстояние Лаббе и расстояние Танимото.
Самым эффективным методом из них оказалось косинусное расстояние. При этом расстояние Лаббе показывает высокую эффективность на бóльших отрывках (от 3000 слов), а расстояние Танимото лучше работает на коротких отрывках. А вот Дельта (манхэттенское расстояние) показала себя чуть хуже и поэтому не вошла в ТОП-3 – её точность атрибуции примерно на 10% ниже, чем у косинусного расстояния, и она делит 4 место в «рейтинге» с расхождением Джеффриса.
Эксперимент показал, что оптимальное число наиболее частотных слов для применения косинусного расстояния и расстояния Танимото должно быть > 200. А также оказалось, что использование трехсимвольных n-грамм стабильно ухудшает показатели точности, что может быть связано с особенностями древнегреческой диакритики. Поэтому для более точного результата лучше использовать словоформы.
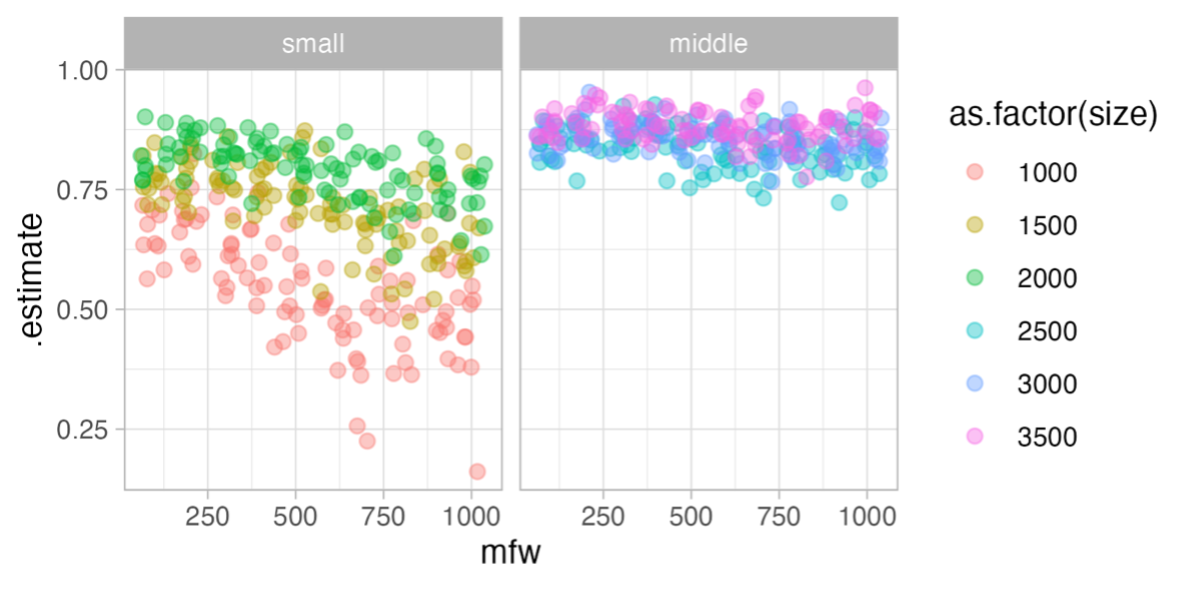
Результаты тестирования метода Дельты Бёрроуза: точность классификации на небольших и средних отрывках в зависимости от количества наиболее частотных слов. Чем выше точки на графике (ближе к единице), тем лучше точность.
Самые «непредсказуемые» авторы
Какие тексты вызывают сложности при классификации? Для рассматриваемых наиболее успешных методов самые «непредсказуемые» авторы совпадают – это Аристотель, Демосфен и Аристид. Если же посмотреть отдельно на матрицу ошибок у Дельты, то можно заметить, что эта метрика в целом плохо справляется с атрибуцией текстов Антисфена, а также путает Исократа с Алкидамантом, Ксенофонта – с Фукидидом и Плутархом, а Эпиктета – с Плутархом. Ольга Алиева предполагает, что такие ошибки происходят чаще всего между текстами, которые близки по жанру. Такой же эффект был и в предыдущем исследовании.
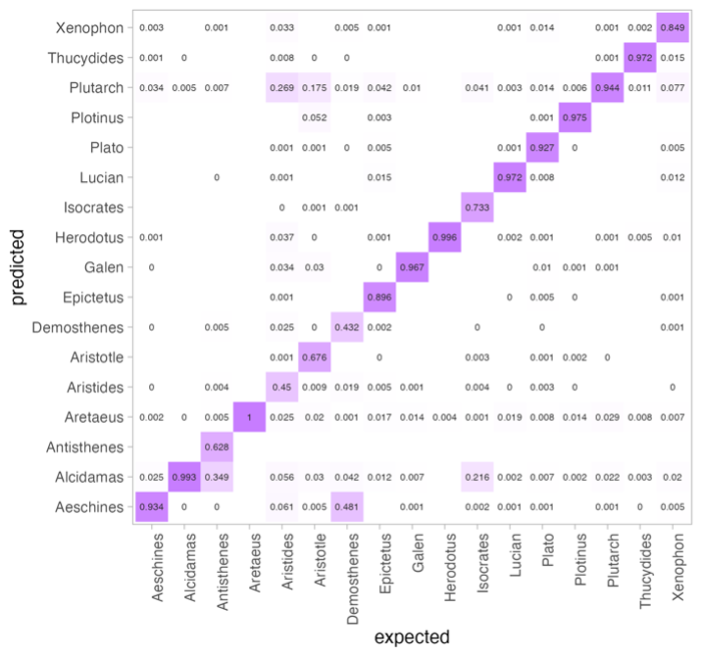
Тепловая диаграмма, на которой видно, на текстах каких авторов Дельта ошибается. Ровная диагональ посередине графика – это случаи, когда авторы определены верно. Но когда фиолетовые квадратики появляются за пределами диагонали – это значит, что Дельта путает авторов (имена авторов – в строках и столбцах).
Стилометрия и древнегреческие тексты: итоги
Оба исследования доказывают, что стилометрия может быть применена к текстам на древнегреческом языке. И Дельта Бёрроуза, и некоторые другие метрики стилометрической близости способны с высокой вероятностью верно определять авторов древнегреческий произведений.
- Дельта более эффективна на объемных отрывках (ок. 3000 слов), чем на коротких фрагментах.
- Дельта не очень хорошо справляется с древнегреческими произведениями одного жанра, так как жанровый сигнал может «перебивать» авторский.
- В спорных случаях вместо одного кандидата на авторство Дельта может предложить шорт-лист из нескольких «подозреваемых».
- Самая эффективная метрика по результатам экспериментов – косинусное сходство. Также высокую точность атрибуции показывают расстояние Лаббе и расстояние Танимото.
- Тексты для анализа лучше всего разбивать на леммы или словоформы, а вот использование символьных n-грамм снижает точность.
Не стоит забывать, что цифровые методы не всесильны, они не могут ответить на все вопросы и разрешить все научные споры. Чтобы провести настоящее стилометрическое исследование, недостаточно одного компьютера – нужен еще и ученый, который сможет грамотно воспользоваться электронным функционалом: выдвинуть гипотезу, отобрать материал для исследования и интерпретировать полученные результаты. Ведь даже получив от классификатора ответ на вопрос «А автор кто?», мы не можем уверенно утверждать, что так оно и есть. Тем более, когда речь идет о древних авторах. Ольга Алиева завершает свою статью так:
«Таким образом, оптимистичные показатели точности не должны нас вводить в заблуждение, причем это касается не только описанных в этой статье методов, но и других, вероятно более совершенных. Авторитет традиции действителен до тех пор, пока не опровергнут, в то время как подтвердить его статистически не представляется возможным»
Источники
Алиева О. В. Delta Берроуза для древнегреческих авторов: опыт применения // Schole. Философское антиковедение и классическая традиция. 2022. Т. 16. № 2. С. 693–705. URL: https://cyberleninka.ru/article/n/delta-berrouza-dlya-drevnegrecheskih-avtorov-opyt-primeneniya
- Ссылка на GitHub проекта
Алиева О. В. Меры расстояния для определения авторства древнегреческих текстов // Препринт. URL: https://github.com/locusclassicus/compareDist/blob/master/текст%20статьи/CompareDist_0912023.pdf
- Ссылка на GitHub проекта
Литература
- A Concordance to Livy: in 4 vols. / Ed. by D. W. Packard. Cambridge, Mass.: Harvard University Press, 1968. URL: Volume 1, Volume 4
- Thompson N. D. A Computer Investigation in Stylometry with Particular Reference to the Works of Xenophon. St. Andrews, 1966. 73 pp. URL: http://hdl.handle.net/10023/22652
- Jones F. P., Gray F. E. Hexameter Patterns, Statistical Inference, and the Homeric Question: An Analysis of the La Roche Data // Transactions and Proceedings of the American Philological Association. 103. Johns Hopkins University Press, 1972. 187–209 pp. DOI: https://doi.org/10.2307/2935975
- Janko R. Homer, Hesiod and the Hymns: Diachronic Development in Epic Diction. Cambridge University Press, 2007. URL: https://books.google.ru/books?id=DhJwIikYB_0C&printsec=frontcover&hl=ru&source=gbs_ge_summary_r&cad=0#v=onepage&q&f=false
- Bozzone Ch., Sandell R. One or Many Homers? Using Quantitative Authorship Analysis to Study the Homeric Question // Proceedings of the 32nd Annual UCLA Indo-European Conference: November 5th, 6th, and 7th, 2021 / Ed. by D. M. Goldstein, S. W. Jamison, B. Vine. Hamburg: Helmut Buske Verlag, 2023. 21–48 pp. URL: https://books.google.it/books?id=io-sEAAAQBAJ&pg=PA21&hl=ru&source=gbs_toc_r&cad=2#v=onepage&q&f=false
- Ссылка на GitHub проекта
- Pavlopoulos J., Konstantinidou M. Computational Authorship Analysis of the Homeric Poems. // International Journal of Digital Humanities. 5. 2023. 45–64 pp. DOI: https://doi.org/10.1007/s42803-022-00046-7
- The Making of the Platonic Corpus / Ed. by O. Alieva, D. Nails and H. Tarrant. Leiden: Brill; Schöningh, 2023. 263 pp. DOI: https://doi.org/10.30965/9783657793891
- Koentges Th. The Un-Platonic Menexenus: A Stylometric Analysis with More Data // Greek, Roman, and Byzantine Studies. Vol. 60. 2020. 211–241 pp. URL: https://grbs.library.duke.edu/index.php/grbs/article/view/16197 Ссылка на GitHub проекта
- McGillivray B., Vatri A. The Diorisis Ancient Greek Corpus // Research Data Journal for the Humanities and Social Sciences. 3 (1). 2018. DOI: https://doi.org/10.1163/24523666-01000013