
Что такое (интер)текстуальность
Французский ученый Жан Барре в своем недавнем исследовании [1] задался вопросом о формировании текстуальности, какую роль в этом играет интертекстуальность и причем здесь канон и жанр. В самом общем смысле текстуальность [2] — это набор качеств, которые не только отличают текст от других языковых единиц и знаковых систем, но и делают его объектом исследования. В русскоязычном поле понятие «текстуальности» фактически отсутствует, но для исследования Барре нужно понимать, что основной рамкой, в которую вписаны интертекстуальность и ее компоненты (канон и жанр), является именно текстуальность. Текстуальность непосредственно связана со структуралистским и постструктуралистским дискурсами, что, например, объясняет апелляции к Барту, Кристевой и Женетту.
Но что такое интертекстуальность? «Каждый текст — это мозаика цитат, каждый текст — это поглощение и преобразование другого текста», — так сформулировала [3] интертекстуальность Юлия Кристева во второй половине прошлого века. Она же и ввела термин в научный дискурс.
Сама идея интертекстуальности как бы размыкает структурные рамки любого текста, превращая его из закрытой и самодовлеющей системы в хоть и запутанную, но открытую сеть отношений текстов друг с другом.
Подходы к изучению интертекстуальности
Существуют разные подходы к изучению интертекстуальности. Один из них ищет явные цитирования. Цифровые литературоведы начали отслеживать, где и какие тексты цитируются, чтобы понять масштабы литературного влияния или даже рерайтинга.
Другой же подход (Барре считает его слабым на контрасте с предыдущим) состоит в простом поиске аллюзий, тематических и лингвистических сходств между конкретным текстом и массивом других текстов. Этот подход активно развивается в последние годы (подробнее об этом можно почитать в этой работе [4] или в этой [5]).
Барре же рассматривает потенциальные интертексты как эндогенные (т. е. существующие в рамках одной текстовой системы и связанные в ней же с другими текстами) для собранного корпуса и оценивает, являются ли наиболее значимые интертексты частью литературного канона. И здесь мы подходим к двум фундаментально важным для работы Барре понятиям, на которых он строит свое исследование.
Первое: канон определяется как парадигматическая категория. При этом на «каноничность» произведения влияют разные факторы: от включения текстов в школьную программу и до общепризнанного «престижа» текста. Предыдущие исследования (например, вот это [6] или это [7]) уже доказали содержательную разницу между каноническими и неканоническими произведениями, а еще то, что принципы включения в канон соблюдаются в разные эпохи и для разных жанров. В данном случае за косвенный показатель престижности литературы брали романы, которые переиздавались в течение долгого времени. Это логично: если книги переиздавались несколько раз, значит, они либо хорошо продавались, либо считались достаточно важными для перечитывания и/или включения в школьную программу.
Таким образом, канонические тексты функционируют как основополагающие, формирующие нормы и ценности в рамках определенной культурной традиции (Альтиери [8], Андервуд [9]).
Второе: понятие литературного жанра. Согласно Женетту [10], одним из пяти измерений интертекстуальности является архитекстуальность, которая, в свою очередь, относится к взаимосвязи и взаимозависимости различных текстов в рамках литературного жанра. Женетт считает жанр важнейшим компонентом общего смысла произведения, потому что способ, которым тексты ссылаются и соотносятся друг с другом, может раскрывать важные тематические и структурные элементы. В результате интертекстуальность сильнее проявляется между текстами, которые принадлежат к одним и тем же жанрам, а сами жанры являются структурирующим элементом для интертекстуальности.
А можно ли тогда не только узнать, кто и/или что конкретно влияет на развитие интертекстуальной сети, но и однозначно ответить, что важнее — жанр или канон? На этот вопрос, параллельно вырабатывая метод, ищет ответ Жан Барре в своем исследовании. В качестве эмпирических данных взят корпус из более чем 12 тыс. произведений французской художественной литературы.
Основная гипотеза Барре заключается в том, что влияние канонических произведений на интертекстуальность более устойчиво, чем темпы литературного процесса, который в значительной степени представлен конкретными жанрами. Иначе говоря, канон формирует литературную традицию дольше и на длинной дистанции, а вот популярные и актуальные произведения (что выражается в жанре) влияют меньше и на довольно ограниченном отрезке времени.
Моделируя интертекстуальность
Собираем нужный корпус сами
Жан Барре проводил исследование при помощи корпуса, основанного на подкорпусе Fictions littéraires de Gallica [11], представляющим собой 19 240 прозаических текстов 1650–1950 годов, взятых из Gallica (обширная инициатива по оцифровке Национальной библиотеки Франции). Во Франции тексты обычно становятся общественным достоянием через 70 лет после смерти их авторов, поэтому по мере приближения к 1950 году корпус романов значительно уменьшается (большая часть текстов все еще находится под авторским правом).
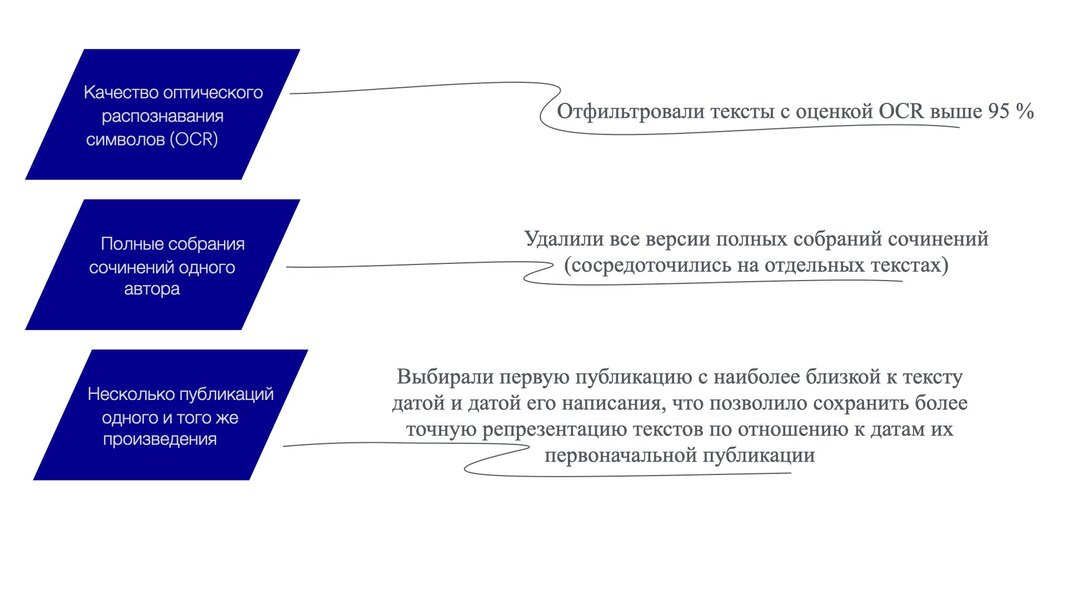
Рис.1. Проблемы в собранном необработанном корпусе и их решения
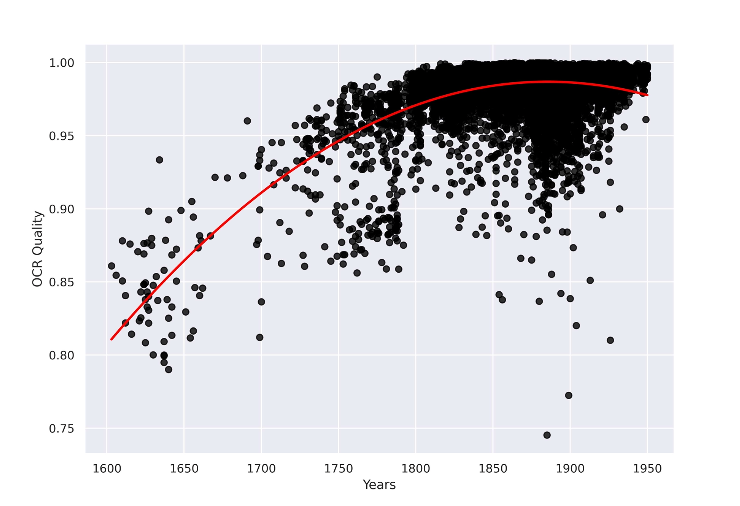
Рис.2. Качество оптического распознавания символов (OCR) с течением времени, основанное на подсчете доли верно распознанных слов в каждом тексте
Зачем это нужно? Чтобы выявить работы, качество OCR которых слишком низкое для вычислительного анализа, то есть чтобы свести погрешности к минимуму. Оценка качества OCR проводилась путем создания словаря французских слов на основе выбранных текстов, исправленных вручную. Каждое слово в этих текстах сравнивалось со словарем, что позволило вычислить приблизительный коэффициент ошибок в словах.
Из графика видно, что тексты до начала XIX века обладают довольно низким качеством OCR. Относительное снижение OCR для текстов конца XIX века может объясняться падением качества бумаги, что негативно влияет на качество оптического распознавания символов.
Отфильтровав тексты с оценкой OCR выше 95%, удалив множественные публикации и полные собрания сочинений, Барре получил список из 12 176 романов.
Построение метаданных
Важнейший для работы Жана Барре дисклеймер: исследователь полагает «канон» и «литературный жанр» не как строго фиксированные структуры, а напротив, видит в них возможности для отслеживания культурно-исторических процессов, присущих конкретной эпохе, динамики создания, а также рецепции литературных произведений.
Помимо самого корпуса текстов, Ж. Барре потребовались дополнительные метаданные. Идея проста: восстановить исторический контекст, пользуясь при этом косвенными признаками литературного процесса, реакцией публики и общим контекстом, актуальным на момент выхода конкретного текста. Проблема сложности поиска релевантных метаданных, на которые можно было бы опереться, решается предыдущим исследованием самого же Барре [12]. В итоге каноническая сторона вопроса имеет следующий вид: в собранном корпусе получили 11 202 неканонических элемента и 1083 канонических.
Уточнена была и жанровая составляющая. Для четкости результатов сосредоточились на «авантюрном романе» как доминирующем жанре конца XIX века (базой послужила работа Летурно [13], в которой сформулированы жанровые константы в промежутке с 1870 по 1930 годы). Затем создали метаданные с помощью бинарного SVM-классификатора [14], обученного на метках Летурно, и в результате выявили 2114 токенов «авантюрный роман» в исследуемом корпусе.
Появляется текстуальность
Основная цель работы Барре — объединить теорию и практику. Компьютерное литературоведение посредством количественных (лексических, семантических, тематических) сравнений устанавливает связь между теоретическим понятием «интертекстуальность» и эмпирическими данными, с помощью которых ее можно «измерить». Кроме этого, цифровые филологи пытаются определять конкретные признаки, по которым можно судить о наличии интертекстуальной сети. Сложность состоит в том, что не существует четкой классификации компонентов текста, к которым апеллируют теоретики интертекстуальности. Проще говоря, мы не всегда знаем, что ищем.
Цифровые филологи стремятся решить эту проблему, используя разные методы извлечения информации из текста: от LDA [15] до BoW [16] и семантических сравнений.
В отношении же такого большого и не всегда определенного массива данных эффективно показали себя текстовый эмбеддинг и метод Paragraph Vectors. Первый способен извлекать сложные текстовые элементы, а второй умеет создавать жанровую кластеризацию. Получается любопытно: методы, суть которых все еще остается для ученых «черным ящиком», помогают искать информацию высокой степени неопределенности, которую необходимо восстановить из текстов.
Жан Барре использует нейросеть-энкодер, обученную на языковой модели с открытым исходным кодом M3-embedding dense (Пекинская академия искусственного интеллекта) [17]. На момент проведения исследования упомянутый алгоритм лидировал в тестах MTEB Benchmark (Massive Text Embedding Benchmark — система, разработанная для оценки производительности моделей текстового эмбеддинга в широком спектре NLP-задач).
Помимо этого, модель удалось точно настроить на литературном французском, что является одним из ключевых аспектов всего исследования. Значительно больший объем лексем (8192 против 512 у BERT, например) позволяет обрабатывать более широкий диапазон данных и идентифицировать больше контекстуальной информации, что сильно улучшает анализ длинных текстовых фрагментов.
Принцип работы выглядит следующим образом:
- Создали обучающий корпус, выбрав 400 тыс. случайных отрывков из исследуемых текстов.
- «Запрос» приводил к абзацу из 10 предложений.
- Для определения «положительной» связи с запросом использовали 10 последующих предложений, для «отрицательной» — 10 случайных предложений из всего корпуса.
- Заменили (при помощи BookNLP-fr [18]) все имена собственные токеном [PROPN], чтобы избежать кластеризации отрывков только на основе имен персонажей.
Таким образом, модель постепенно должна повышать производительность при установлении атрибуции автора, используя различные формальные элементы, тематическое содержание и стилистические особенности.
Далее было необходимо вывести векторное представление для каждого романа в исследуемом корпусе. На этом этапе возникла трудность: энкодер может обрабатывать в контекстном окне максимум 8096 токенов, тогда как в романе их содержится примерно 100 тыс.
Решили так: для каждого романа в корпусе выбрали 100 случайных отрывков и запустили энкодер, настроенный по схеме fine-tuning на каждом отрывке. Из полученных результатов взяли среднее значение эмбеддинга для всех романных отрывков, чтобы представить его как уникальное. Таким образом, получили 12 176 эмбеддингов — по одному для каждого романа.
В качестве метрики расстояния между текстами выбрали часто применяемую в NLP косинусную близость [19].
Результаты
Сходство с течением времени
Для подтверждения эффективности подхода на каждом вычислительном шаге проверяли работоспособность построенией, используя подкорпус из тысячи романов, извлеченный из созданного корпуса (подробно о механизме проверки — здесь [1]).
После получения эмбеддингов для каждого из ∼12 000 романов строится матрица сходства, в которой столько же строк, сколько и столбцов, где измеряется косинусная близость каждого текста со всеми остальными.
Матрица сходства устроена следующим образом:
- В каждой строке произведения одного и того же автора имеют значение NaN (Not a Number — это конкретное значение числового типа данных, которое не определяется как число, например, результат 0/0), чтобы авторский идиолект не искажал анализ.
- Затем для каждого текста вычисляется матрица сходства с каждым годом в корпусе. Для статистической релевантности применяют уменьшение выборки для каждого года, то есть каждый год должен содержать минимум 25 и максимум 50 романов.
- Затем каждый текст выравнивается по году публикации. Год публикации соответствует значению 0 на горизонтальной оси.
- Процесс уменьшения выборки повторяется десять раз, и стандартная ошибка отображается на графике.
Выбрали временной отрезок в 30 лет до и после, т. к. предыдущие исследования показали, что это хороший промежуток для измерения литературных изменений.
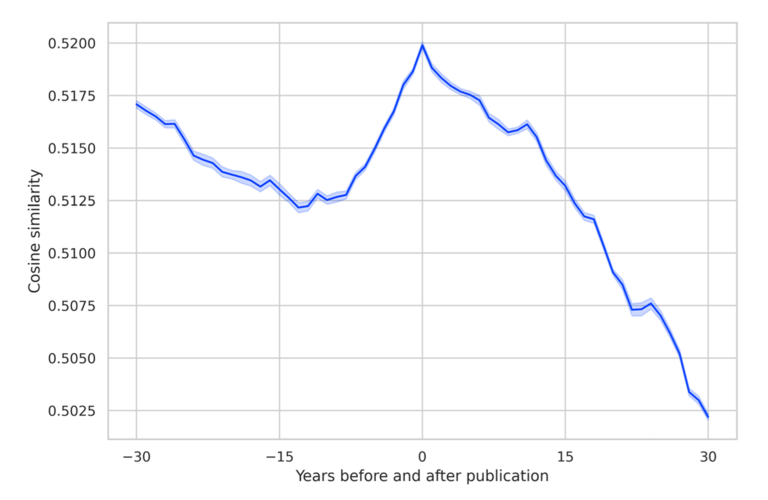
График, отображающий сходство между текстом и контекстом его создания
Явный пик сходства приходится на год публикации романа. Высокое сходство за 30 лет до публикации говорит о том, что ранние работы оказали сильное влияние на развитие автора. По мере приближения к дате публикации это влияние уменьшается, что отражает постепенное отклонение от старых литературных моделей.
От общего к частному
Ж. Барре кроме общих тенденций смог обнаружить и частные (пользуясь все той же матрицей сходства, которая описана выше) на примере нескольких конкретных романов.
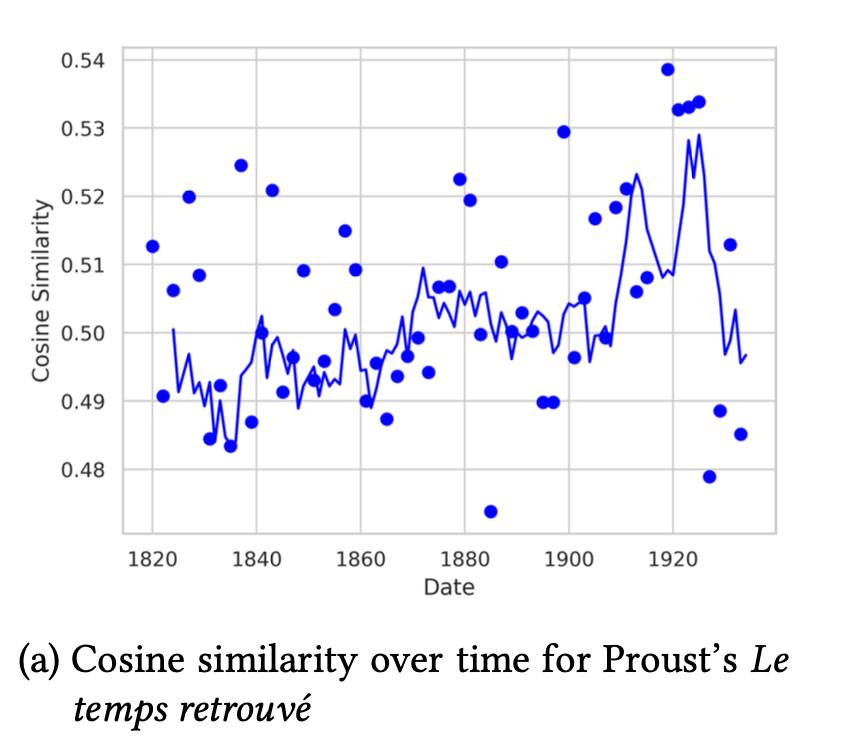
График (а) для романа «Обретенное время» Марселя Пруста
Видно, что пик публикаций приходится на 1927 год, то есть уже после смерти автора. Этот пик совпадает с происходящими в литературном процессе тенденциями. Модернисты сменили фокус с линейного на субъективно воспринимаемое время, и именно это и является предметом исследования Пруста — воспоминания, механизмы восприятия и мышления. Кроме того, из всех графиков именно у романа Пруста самый высокий уровень «шума», что отражает ситуацию диалога между прошлым и модернистским настоящим начала века (подробнее о том, почему так, — A. Compagnon. Proust entre deux siècles).
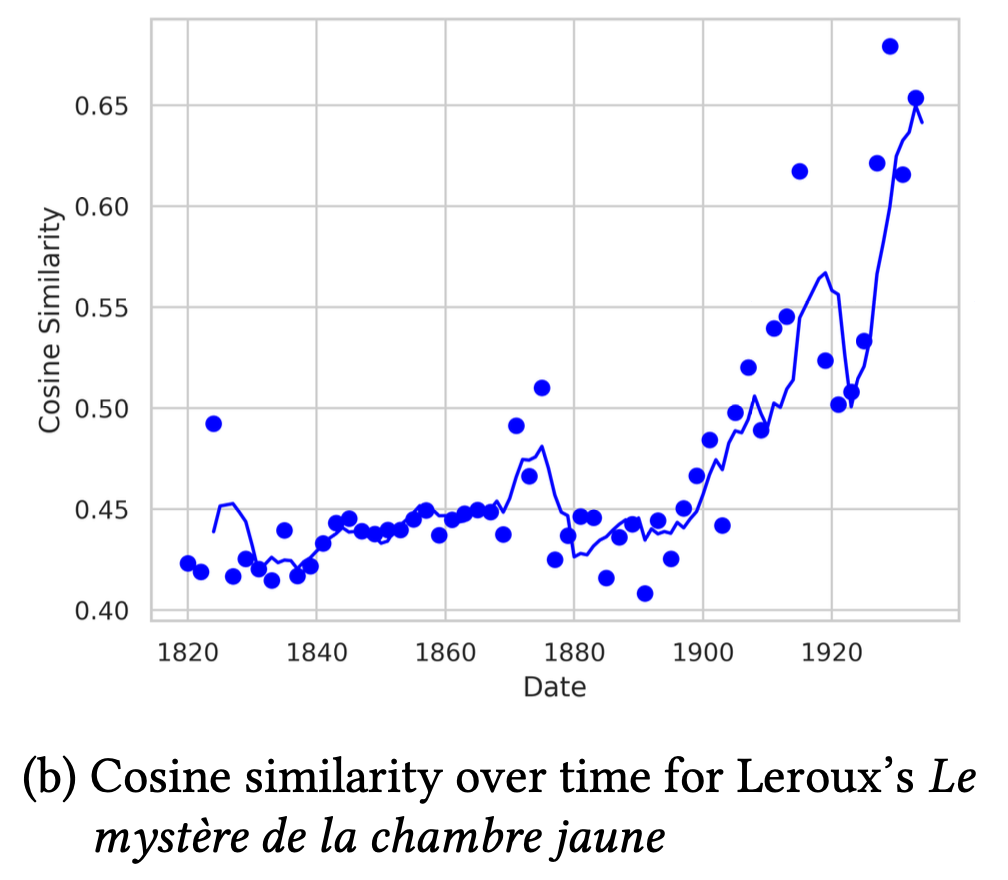
График (b) для романа Гастона Леру «Тайна желтой комнаты»
Роман опубликован в 1907 году, и заметно, как растет косинусная близость с начала века и до конца исследуемого периода. Это объясняется тем, что Леру (наряду с Конан Дойлем) заложил основы одной из самых популярных сюжетных схем в жанре детектива: «Кто это сделал?» (whodunit). График наглядно демонстрирует, что нововведения Леру активно начали использоваться последующими авторами.
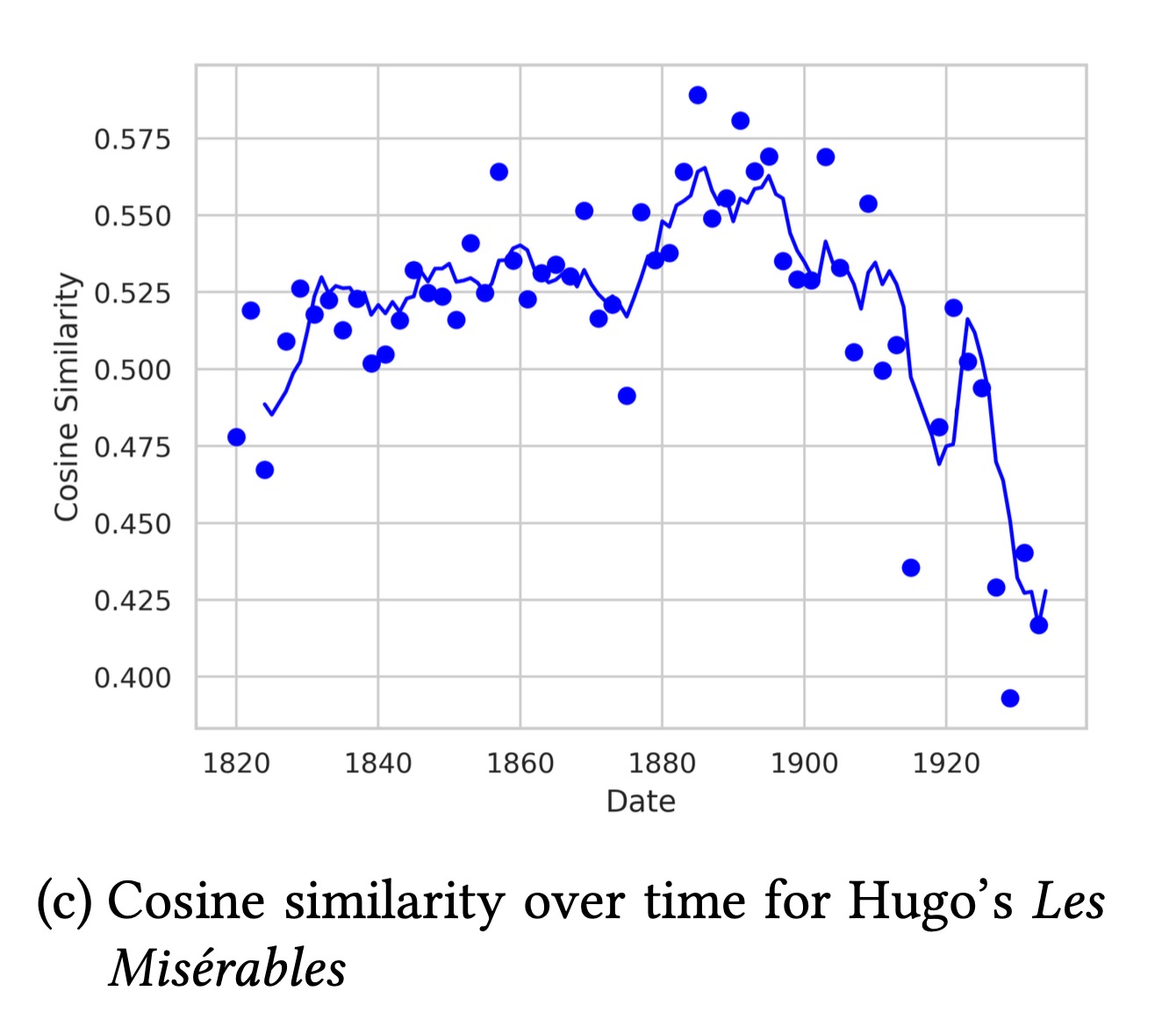
График (c) для «Отверженных» Виктора Гюго
Здесь интересно то, что пик в год публикации (1862) гораздо менее выражен, чем в последующие десятилетия (между 1880 и 1900 годами). Помимо очевидного влияния уже ставшего к концу века классиком Гюго на следующее поколения писателей, что «Отверженные» также неплохо соотносились с идеями натурализма [20]. Падение же в конце графика может быть объяснено лингвистическими и тематическими изменениями, которые слишком значительны, чтобы сохранять высокую текстуальную схожесть.
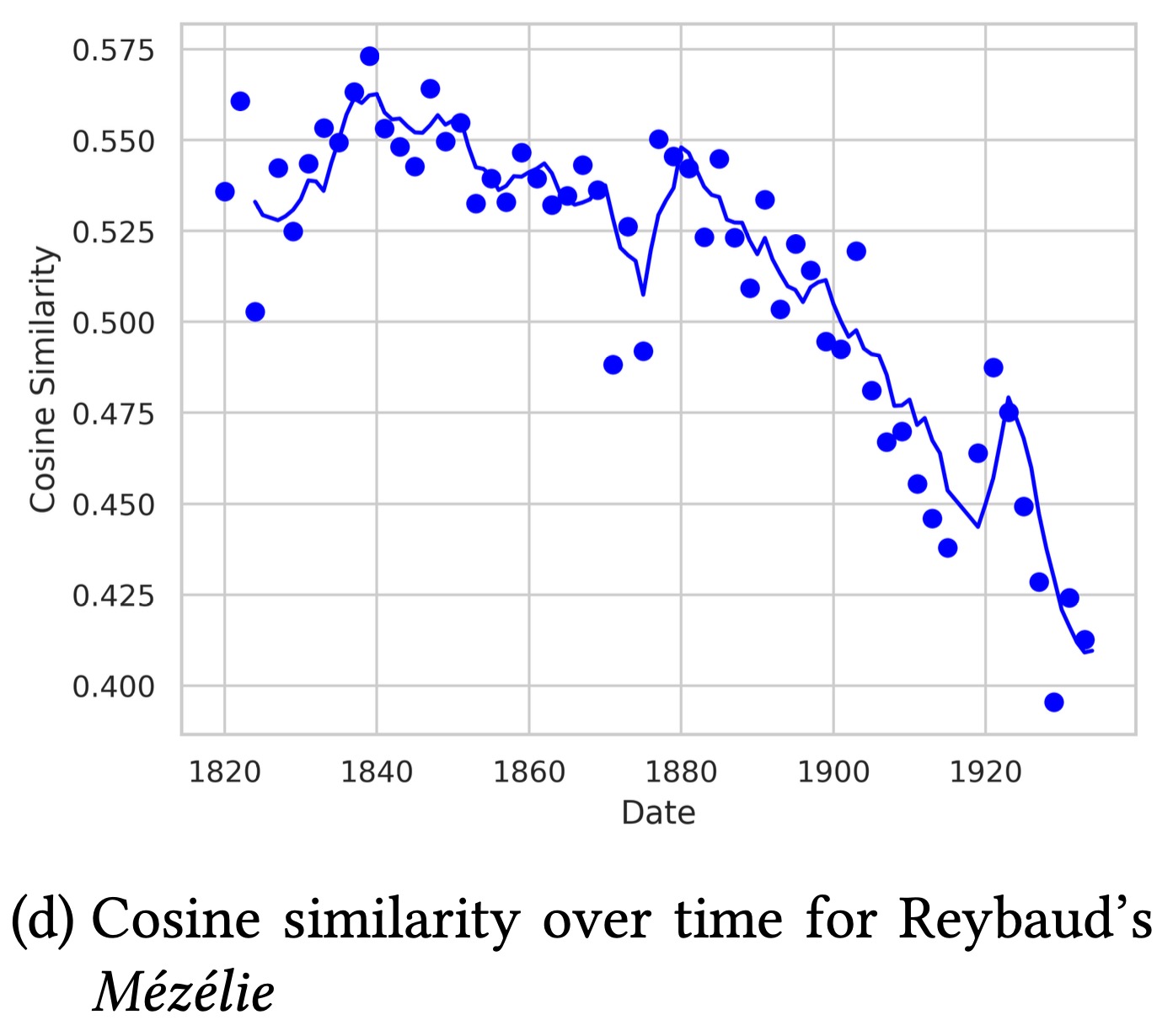
График (d) для «Мезели» мадам Шарль Рейбо
Явно контрастирующий с предыдущими график, демонстрирующий ситуацию, когда успех во время публикации (1839), далее шел на спад. Со временем работы Рейбо и вовсе ушли в библиотечные архивы.
От частного — снова к общему
В заключительных экспериментах применялась та же матрица сходства, которая была описана выше, однако фокус был на жанрах и каноничности. Основная задача заключалась в том, чтобы выяснить, насколько эти два фактора влияют на интертекстуальность.
Сначала сформировали две пары текстовых выборок: канон vs архив и приключенческий роман vs другие жанры. Затем для сравнения сделали стратифицированную выборку (опираясь на уже упомянутые метаданные). Случайным образом отобрали элементы из разножанровой и архивной выборки, чтобы они соответствовали аналогичным в приключенческой и канонической выборках, сохраняя при этом распределение по десятилетиям в рассматриваемых группах.
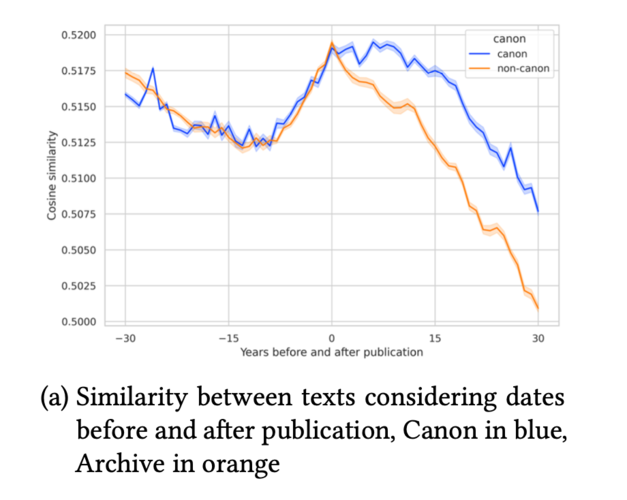
Косинусная близость между каноническими и архивными текстами до и после публикации
На графике (a) показано, что если до публикации для канонических и архивных романов наблюдается схожая тенденция, то после публикации кривые заметно расходятся. Особенно ярко это проявляется в том, что у канонических произведений показатели сходства с более поздними публикациями выше, чем у архивных. Этот тренд сохраняется с течением времени, указывая на то, что канонические произведения оказывают более продолжительное влияние на интертекстуальную сеть, в то время как неканонические произведения имеют ограниченное и краткое воздействие.
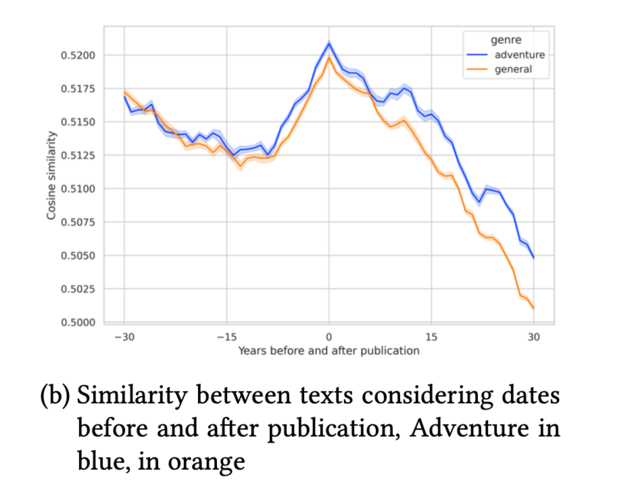
Косинусная близость между текстами приключенческого жанра и остальными (до и после публикации)
График (b) демонстрирует менее яркую картину, но все равно является любопытным и статистически достоверным. Обе кривые следуют в одном направлении до публикации, но начинают расходиться примерно за 10 лет до и вплоть до пяти лет после даты публикации. Эта закономерность позволяет предположить, что жанры имеют точное контекстуальное существование в конкретный исторический момент. Вслед за уменьшением сходства мы наблюдаем, что приключенческие романы сохраняют сильное сходство с более поздними текстами (от +10 до +30 лет).
Выводы
В ходе исследования подтвердились первоначальные предположения: и то, которое рассматривает канон и жанр как действующие элементы интертекстуальности, и то, которое говорило о влиянии интертекстуальности на формирование текстуальности.
Кроме того, были выявлены новые модели текстового сходства на основе корпуса текстов французской литературы.
Из исследования точно можно сделать два вывода. Во-первых, канонические произведения глубже интегрированы в интертекстуальную сеть после их публикации, что, в свою очередь, подтверждает мысль о канонических текстах как структурах, которые формируют культурные рамки. Во-вторых, выяснилось, что тексты одного жанра имеют явные текстуальные сходства в течение короткого периода, когда жанр только определяется.
В конечном счете, как канонические, так и жанровые произведения создают набор общих референсов и ожиданий, которые направляют написание и восприятие последующих текстов, а также способствуют формированию общего культурного поля.
Источники
- Barré, J. “Latent Structures of Intertextuality in French Fiction: How Literary recognition and subgenres are framing textuality”. [Электронный ресурс] // Proceedings of the Workshop on Computational Humanities Research (CHR 2024). Vol.3834 CEUR Workshop Proceedings, 2024. pp. 21–36. URL: https://ceur-ws.org/Vol-3834/paper97.pdf (дата обращения: 25.02.2025).
- De Angelis, R. (2020). Textuality [Электронный ресурс] // Oxford Research Encyclopedia of Literature / 28 September 2020. URL: https://doi.org/10.1093/acrefore/9780190201098.013.1098 (дата обращения: 25.02.2025)
- Kristeva, J. Sèméiotikè: recherches pour une sémanalyse. Points. Paris: Éditions Point, 2017.
- Ganascia, J.-G. “Détection automatique de phénomènes intertextuels”. [Электронный ресурс] // Genesis, 51. 2020. pp. 63–77. URL: https://doi.org/10.4000/genesis.5671 (дата обращения: 25.02.2025)
- Manjavacas, E., Karsdorp, F. and Kestemont, M. “A Statistical Foray into Contextual Aspects of Intertextuality”. [Электронный ресурс] // Proceedings of the Workshop on Computational Humanities Research (CHR 2020). Vol. 2723. CEUR Workshop Proceedings, 2020, pp. 77–96. URL: https://ceur-ws.org/Vol-2723/long28.pdf (дата обращения: 25.02.2025).
- Algee-Hewitt, M., Allison, S., Gemma, M., Heuser, R., Walser, H., and Moretti, F. “Canon/Archive. Large-scale Dynamics in the Literary Field”. [Электронный ресурс] // Pamphlets of the Stanford Literary Lab 11 (2016). URL: https://litlab.stanford.edu/LiteraryLabPamphlet11.pdf (дата обращения: 25.02.2025).
- Barré, J.and Poibeau, T. “Beyond Canonicity: Modeling Canon/Archive Literary Change in French Fiction”. [Электронный ресурс] // CEUR Workshop Proceedings CHR2023. 2023, pp. 814–830. URL: https://ceur-ws.org/Vol-3558/paper9925.pdf (дата обращения 25.02.2025)
- Altieri, C. (1983). An Idea and Ideal of a Literary Canon. Critical Inquiry, 10(1), 37–60. URL: http://www.jstor.org/stable/1343405 (дата обращения: 25.02.2025).
- Underwood, T. Distant horizons: digital evidence and literary change. Chicago: The University of Chicago Press, 2019. 206 pp.
- Genette, G. “Introduction à l’architexte”. In: Théorie des genres. Ed. by G. Genette and T. Todorov. Points 181. Paris: Éd. du Seuil, 1986, pp. 110–148.
- Langlais, P.-C. Fictions littéraires de Gallica [Электронный ресурс] / Literary fictions of Gallica. Version 1. 2021. URL: https://zenodo.org/records/4751204 (дата обращения: 25.02.2025).
- Barré, J., et al. “Operationalizing Canonicity: A Quantitative Study of French 19th and 20th Century Literature.” [Электронный ресурс] // Journal of Cultural Analytics, vol. 8, no. 3, Oct. 2023, URL: https://doi.org/10.22148/001c.88113 (дата обращения: 25.02.2025).
- Letourneux, M. Le roman d’aventures: 1870–1930. Limoges: Presses Universitaires de Limoges et du Limousin, 2010.
- Pedregosa, F., Varoquaux, G., Gramfort, F., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E. “Scikit-learn: Machine Learning in Python”. [Электронный ресурс] // Journal of Machine Learning Research 12 (2011), pp. 2825–2830. URL: https://www.jmlr.org/papers/volume12/pedregosa11a/pedregosa11a.pdf (дата обращения 25.02.2025).
- Системный Блокъ: как понять, о чем текст, не читая его?
- Bag-of-words model. Wikipedia, The free encyclopedia. [Электронный ресурс] // https://en.wikipedia.org/wiki/Bag-of-words_model (дата обращения: 25.02.2025).
- Chen, J., Xiao, S., Zhang, P., Luo, K., Lian, D., and Liu, Z. M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. 2024. [электронный ресурс] // URL: arXiv:2402.03216 (дата обращения: 25.02.2025).
- Mélanie-Becquet, F. Barré, J., Seminck, O., Plancq, C., Naguib, M., Pastor, M., and Poibeau, T. “BookNLP-fr, the French Versant of BookNLP. A Tailored Pipeline for 19th and 20th Century French Literature”. [Электронный ресурс] // Journal of computational literary studies 3(1), 1–34.2024. URL: https://doi.org/10.48694/jcls.3924 (дата обращения: 25.02.2025).
- Системный Блокъ: что такое косинусная близость?
- Britannica, T. Editors of Encyclopaedia (2024, September 5). naturalism. Encyclopedia Britannica.[Электронный ресурс] // URL: https://www.britannica.com/topic/naturalism-art (дата обращения: 25.02.2025).

