Выделение событий в тексте — одновременно старая и новая задача. Старая она потому, что над связью событий и других характеристик текста задумывались ещё в начале XX века, а новая — потому что вычислительные мощности для решения подобных задач появились сравнительно недавно.
События и их последовательности влияют на архитектуру сюжета произведения. В 1920-х гг. русские формалисты разделили два связанных понятия: сюжет (то, как литературные события изложены в произведении) и фабулу (хронологическую последовательность событий). Несмотря на кажущееся сходство, нередко сюжет и фабула не совпадают.
Например, в «Герое нашего времени» М. Ю. Лермонтова последняя по хронологии глава — «Максим Максимыч». В ней повествователь встречает Печорина, едущего в Персию, а также получает его записки от Максима Максимыча. События остальных глав происходят задолго до этой встречи. Однако Лермонтов расположил главу «Максим Максимыч» ближе к началу романа. В результате сюжет «Героя нашего времени» не совпадает с его фабульной хронологией.
Вернемся к задаче распознавания событий. Нередко компьютерные лингвисты решают её на материале новостных заметок, а к художественному тексту обращаются реже. Вообще, художественные произведения — сложный материал для такого анализа. Они очень длинные (гораздо длиннее новостей), структура событий в них куда сложнее и запутаннее. Вдобавок к этому нужно помнить и о «цели» этих текстов: в отличие от репортажей, которые пишут для изложения связей между событиями (как хронологических, так и причинно-следственных), в художественном тексте на первый план выходит эмоциональное воздействие на читателя при помощи выбора слов и использования различных языковых инструментов.
Существуют работы, которые исследуют изменения отношений между персонажами, произошедшие вследствие каких-то событий в тексте; работы, которые определяют тональность текста, описывающего эти события; работы, выделяющие события при помощи нейронных сетей разных видов. В основном текст разбивается на предложения, однако в некоторых работах используется и дробление по документам, которое может быть полезно для выявления более крупных элементов структуры текста.
Статья, о которой идёт речь сейчас, поставила себе цель ответить на вопрос «определяют ли события в произведении форму нарратива?», то есть — можем ли мы, имея лишь список событий произведения, определить, из какого текста они взяты — художественного, исторического или новостного?
Данные
Для ответа на этот вопрос авторы собрали корпус на основе текстов, публично доступных на ресурсе Project Gutenberg. В корпусе есть и произведения, относящиеся высокому литературному стилю (например, «Эпоха невинности» Эдит Уортон или «Улисс» Джеймса Джойса), и более массовая литература («Копи царя Соломона» Г. Р. Хаггарда или «Рваный Дик» Горацио Элджера). Все тексты были опубликованы до 1923 г. — такой выбор даты объясняется ограничениями по применению авторского права в США. Бóльшая их часть оказалась написанной в период 1852–1911 гг. Из каждого текста взяты первые 2000 слов, чтобы уравнять все произведения.
Использование произведений разного уровня «художественности» позволяет авторам исследовать более широкий спектр литературной реальности. В корпусе есть как произведения, которые сложны нарративно и стилистически, так и те, что в своей структуре больше похожи на описательные.
Разметка
Большинство классификаций литературных событий так или иначе ссылаются на работу Вендлера [1], в которой выделяются 4 типа глаголов (без которых, конечно, не может быть никаких событий):
- деятельности (activities) — динамические, непредельные процессы («гулять»),
- совершения (achievements) — короткие завершённые действия, моментальные события («лопнуть»),
- достижения (accomplishments) — длительные завершённые действия, предельные процессы («читать книгу»),
- стативы (states) — постоянные состояния, длящиеся в течение какого-то времени и не имеющие конкретной «финальной точки» («быть»).
Некоторые исследователи предлагают разделять события только на состояния и события. Третий подход заключается в том, чтобы помимо самих событий размечать ещё и изменения состояний, потому что они являются динамическими переходами на фоне обычно неизменных стативов.
Авторы сначала объявили, что именно должно попасть в модель разметки. Они решили, что их интересуют события, действительно произошедшие в произведении (realis). При разметке они руководствовались следующими правилами:
- Полярность: размечались только произошедшие события с положительной полярностью. События-отрицания не размечались как произошедшие (то есть, например, событие он не понял не было размечено, так как оно выражено глаголом с отрицанием).
- Грамматическое время: размечались события, выраженные глаголами в настоящем или прошедшем времени.
- Универсальность: все универсальные события, описывающие обыденные действия, которые могли бы выглядеть и быть описаны абсолютно так же в другом произведении (например, собаки лаяли) не размечались. Интерес для авторов представляли специфические события, произошедшие единожды в определённом месте в определённое время.
- Модальность: размечались только те события, о которых говорилось с уверенностью. Остальные модальности — гипотезы, желания и т.д. — не попали в разметку.
Помимо самих событий, авторы также размечали триггеры к ним — минимальное количество текста (в этом исследовании — одно слово), которое может описать событие. Триггеры могли быть выражены глаголом, именем прилагательным или именем существительным. Так, в предложении «The studio was filled with a rich odour of roses» [The Picture of Dorian Gray] таким триггером считалось слово odour. В разметке именно оно помечалось как событие.
В результате такой разметки оказалось, что большинство событий можно разбить на четыре категории: разговор, движение, восприятие и обладание. Таблица ниже показывает, как часто встречались слова из этих категорий.
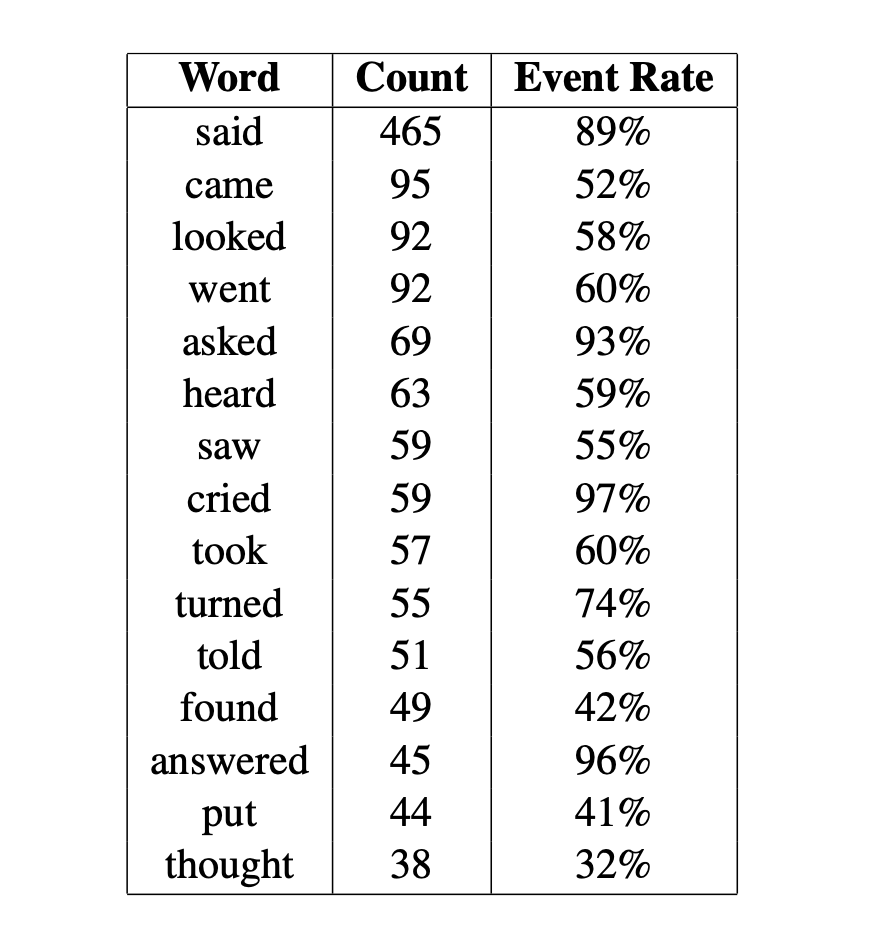
Нередко оказывалось, что событие выражалось метафорой, выражалось в условном наклонении (которое, по идее, не должно было попадать в разметку) или было сформулировано так, что вне контекста определить, действительно ли произошло событие, представлялось не очень возможным.
В результате в корпусе из 210 532 токенов-слов у исследователей получилось 7 849 событий; результат разметки находится в открытом доступе.
Попробуем скормить получившуюся информацию компьютерным мозгам?
Дальше авторы сделали из полученного датасета два набора признаковых описаний: в одном из них использовалось векторное описание слов (подробнее об этом можно прочитать в этой статье СБ{ъ} [2]), в другом, помимо векторного описания, были лингвистические признаки: часть речи, информация о контексте, информация о семантике слова, полученная при помощи WordNet и специфическая информация о конкретном слове (например, если это bare plural — существительное во множественном числе, которое используется в основном для того, чтобы фраза получила универсальное прочтение, например, «Кошки любят молоко» или «Работа врачей очень тяжёлая»).
Исследователи определили свою задачу как выявление связи между рассматриваемым словом и событием. Для этого использовались нейронные сети двух различных архитектур — одно- и двунаправленная LSTM (long short-term memory network, долгая краткосрочная сеть) и свёрточная нейронная сеть (CNN). Первая сеть скорее специализируется на предсказании вероятностей, основываясь на данных и их последовательности (которой здесь может быть контекст). Вторая обнаруживает пространственные связи в подаваемых данных, поэтому «свёртки» нередко используются для обработки изображений.
В итоге лучшей комбинацией стала двунаправленная LSTM-сеть, в которой векторное описание слов было получено при помощи BERT — модели, которая для вычисления вектора слова учитывает ещё и его контекст. Такая модель выделила события с F-мерой 73.9.
Дальнее чтение корпуса: что можно узнать после того, как тексты были пропущены через компьютер
Полученные результаты позволили узнать кое-что новое об исходном материале. Так как корпус состоит из текстов разного уровня художественности (см. «Данные»), авторы решили посмотреть, отличаются ли предсказания сети для текстов разного уровня литературного мастерства.
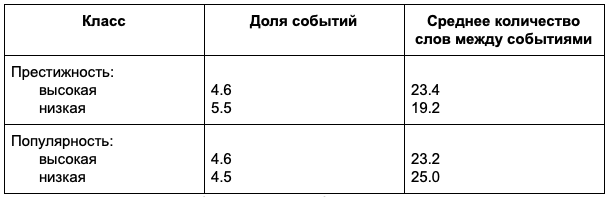
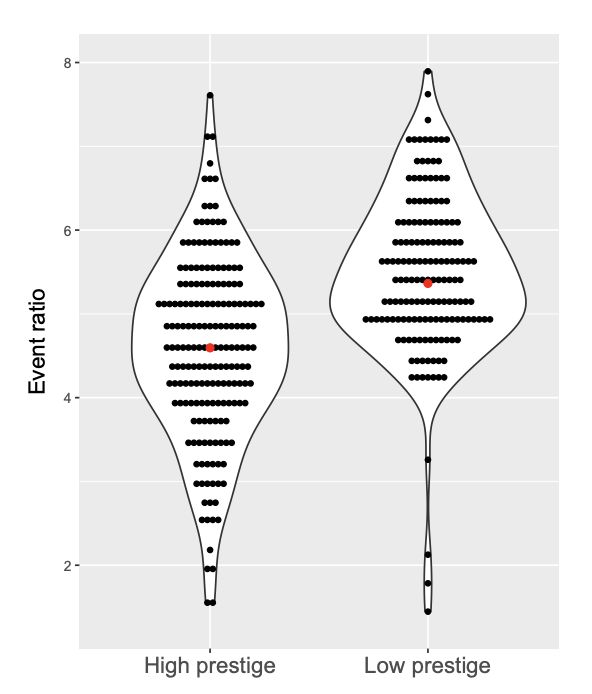
Оказалось, что в среднем в высокохудожественных произведениях было чуть меньше событий (4.6% против 5.5%), которые были чуть более подробно описаны — в среднем между двумя найденными событиями более «элитного» текста помещалось 23.4 слова, когда как в менее элитарных текстах два события отделяет 19.2 слова. Получается, что в менее престижных текстах всегда что-то происходит, они более насыщены событиями. Также авторы обнаружили, что тексты высокой литературы более вариативны.
Также авторы сравнили произведения, разделив их по популярности — её измеряли по количеству переизданий произведения за период, который исследователи выбрали для изучения. Здесь вариации оказались менее значимыми: оказалось, что и в более популярных, и в менее популярных текстах в среднем случалось около 4.5% событий примерно одной длины.
Конечно, исследования престижности — не единственное, что можно сделать с таким корпусом. Помимо самого подсчёта событий, можно исследовать насыщенность на единицу времени в повествовании или на время чтения (сколько событий происходит за треть книги? за половину? а может, в последней четверти начинается всё самое активное?), частотность событий (есть ли безусловные лидеры?) и многое другое.
Ссылки
Источник
Источник текстов для корпуса: Project Gutenberg
Другие ссылки в тексте
[1] Vendler, Zeno. «Verbs and Times.» The Philosophical Review 66, no. 2 (1957): 143-60. doi:10.2307/2182371.
[2] Статья СБ{ъ} — Word2Vec: покажи мне свой контекст, и я скажу, кто ты.