
Похожие слова
Что это такое
Похожими словами в НКРЯ называют ближайшие семантические ассоциаты. Это могут быть не только синонимы, но и антонимы, слова, обозначающие часть и целое, вещи одного рода или вида и так далее. Например, слова «собака» и «кошка» или «сентябрь» и «октябрь» — это не синонимы, но они будут близки, поскольку встречаются в похожих контекстах и потому ассоциируются друг с другом. Для подбора ассоциатов используется дистрибутивная семантика: значение слов определяется, исходя из контекста, а само слово сводится к его векторному представлению. По такому принципу работает, например, технология Word2Vec.
Как это выглядит в Корпусе
Похожие слова могут меняться от корпуса к корпусу в зависимости от представленных в нем текстов. Например, так выглядят ассоциаты для слова «зенит» в корпусе Региональных СМИ:

Рис. 1. Похожие слова для слова «зенит» в корпусе Региональных СМИ
А так — в Основном:

Рис. 2. Похожие слова для слова «зенит» в Основном корпусе
Основной корпус охватывает весь русский язык Нового времени (начиная с XVIII века), поэтому «зенит» в нем чаще встречается как астрономический термин, чем как футбольная команда. В СМИ же, конечно, гораздо чаще попадают статьи о матчах или игроках.
Как использовать
Инструмент «Похожие слова» — часть «Портрета слова». В НКРЯ он находится отдельно от поиска. На него можно попасть, например, с главной страницы:
Рис. 3. «Портрет слова» — левая кнопка под строкой поиска
Или со страницы поиска после того, как вы ввели интересующий вас запрос:
Рис. 4. Кнопка «Перейти к Портрету слова» в верхнем блоке справа
Для «Портрета слова» можно выбрать корпус так же, как и для поиска. Инструмент «Похожие слова» на июнь 2025 года доступен для девяти корпусов: Основного, двух Газетных, Обучающего, Старорусского, Церковнославянского, Древнерусского, корпусов «Русская классика» и «От 2 до 15».

Рис. 5. Похожие слова для слова «музей» в корпусе Региональных СМИ
В Основном корпусе можно также сравнивать два периода и исследовать, как менялось значение слова.
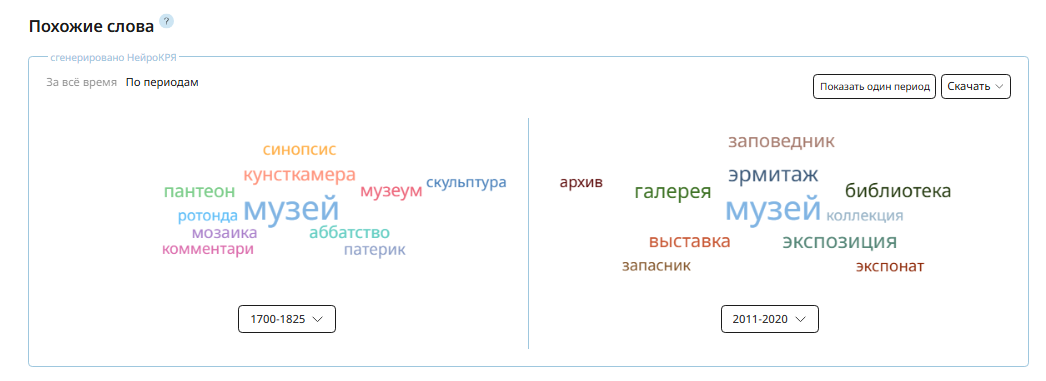
Рис. 6. Похожие слова по запросу «музей» для двух периодов: 1700–1825 и 2011–2020
Для слова «музей» изменения не так велики, а вот из более интересных примеров мы сделали целый тест.
Как это устроено
Для каждого из корпусов была обучена отдельная word2vec модель. Для обучения использован алгоритм Continuous Bag-of-Words (реализация из библиотеки gensim), который предсказывает центральное слово на основе окружающих его. Для всех моделей используется размерность вектора 300 и окно в пять слов.
Модели находятся в свободном доступе на сайте НКРЯ.
Для использования и запуска понадобится библиотека gensim для Python.
Морфологическая разметка
Что это такое
Для слов в Корпусе представлена морфологическая информация: например, лемма — начальная форма слова («кот» для слова «котами» или «писать» для слова «пишет»), часть речи и грамматические категории (время, род, число, падеж и т. п.).
Подробный список помет для НКРЯ есть на соответствующей странице.
Как это выглядит в Корпусе
Посмотрим, как выглядит морфологический разбор слова «пчёлы» из следующего примера:
В пути пчёлы, как правило, проводят не более пяти дней. [Почта доставляет «жужжащие» посылки // «Дмитриевский вестник» (Дмитриевский район Курской области), 19.05.2023]
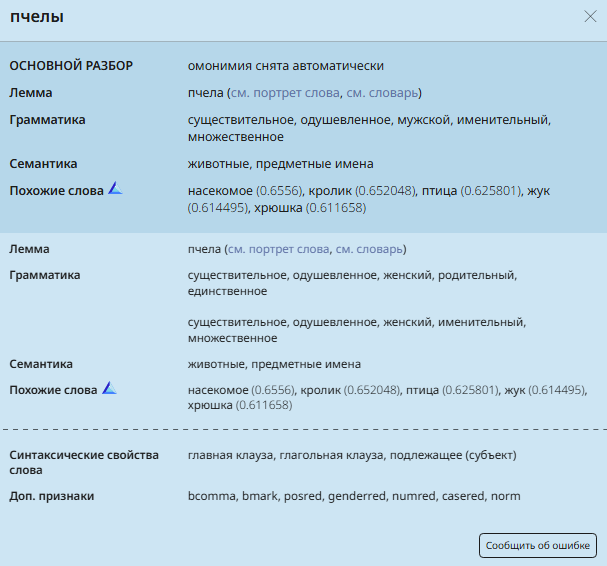
Рис. 7. Морфологический разбор слова «пчёлы» с автоматически снятой омонимией
К морфологической разметке здесь относятся поля «Лемма» и «Грамматика». Можно заметить, что для слов с автоматически снятой омонимией указаны как основной разбор, так и дополнительные: из предложения ясно, что слово стоит в множественном числе и именительном падеже, но форма «пчелы» могла бы быть и родительным падежом единственного числа (кого? пчелы).
Как использовать
Достаточно нажать на любое слово в выдаче — подгрузится информация из карточки выше. Пометы могут незначительно (для обычного пользователя-нелингвиста) варьироваться в зависимости от типа снятия омонимии или вида корпуса.
Как это устроено
Раньше для снятия омонимии использовали морфологический анализатор MyStem. После обновления НКРЯ появилась новая русская модель морфосинтаксической разметки Rubic. В ее задачи входят лемматизация, создание морфологической характеристики для всех токенов, включая определение части речи, а также построение дерева синтаксической зависимости предложения.
Архитектура Rubic основана на архитектуре модели qbic, победившей в соревновании по обработке русского языка GramEval2020. В ней LSTM-энкодер получает векторизованные представления слов из модели sberbank-ai/ruBert, предобученной на 30 Гб данных, и комбинирует их с морфологическими пометами от анализатора PyMorphy2. Эти представления передаются трем декодерам, каждый из которых решает свою задачу классификации:
- один определяет часть речи и грамматические признаки,
- другой — выбирает лемму,
- третий — строит синтаксическое дерево.
Для обучения модели использовались корпусы СинТагРус, UD-Taiga и НКРЯ: в обучающей выборке оказались самые разные тексты, от поэзии до постов из социальных сетей и статей из Википедии [1].
Подробно об архитектуре Rubic можно прочесть в статье об НКРЯ 2.0, а узнать о BERT-подобных нейросетях — в нашем материале.
Морфемный разбор
Что это такое
То же, что и разбор слова по составу. В школьном разборе сначала выделяются окончание и формообразующий суффикс (например, —л— у глаголов прошедшего времени), затем определяется основа слова, в ней выделяются приставки и суффиксы, корень.
Как это выглядит в Корпусе
Функция морфемного разбора доступна в «Портрете слова» — на той же странице, где ранее мы смотрели «Похожие слова». Сейчас она работает для двух корпусов: Основного и Обучающего. Интересно, что при этом разборы могут не совпадать: для разных корпусов используются разные словари.
Основной корпус опирается на принцип словаря А. И. Кузнецовой и Т. Ф. Ефремовой — в нем дробность выделения морфем выше, чем в привычной школьной традиции. Так об этом говорится в статье, посвященной новым инструментам в НКРЯ:
«В исконных словах могут выделяться морфемы, даже если слово без них употребляется маргинально (у-лыб-а-ть-ся, ср. у-смех-а-ть-ся) или если мотивированность этимологии слова для современного носителя неочевидна (на-сек-ом-ое, вос-точ-н-ый). В иностранных словах заимствованные основы членятся (например, ре-волюц-и-я, квит-анци-я), если усматривается семантическое и структурное соответствие между ними и лексемами похожего строения (ср. э-волюц-и-я, рас-квит-а-ть-ся)» [1].
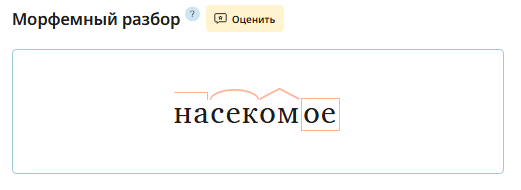
Рис. 8. Пример морфемного разбора для слова из Основного корпуса
Обучающий корпус же следует школьной традиции — ведь он предназначен для преподавания русского языка и литературы в школах. В нем используется соответствующий школьным правилам морфемного разбора словарь А. Н. Тихонова.
Рис. 9. Пример морфемного разбора того же самого слова, но уже из Обучающего корпуса
Благодаря морфемной разметке в Основном корпусе также можно увидеть однокоренные слова.

Рис. 10. Слова, однокоренные слову «насекомое», согласно разметке Основного корпуса. В заголовке инструмента указано, что это бета-версия — в ней все еще могут встречаться ошибки и неточности
Как использовать
Так же, как и «Похожие слова», «Морфемный разбор» можно найти на странице «Портрета слова», в который заходим с главной страницы или через страницу поисковой выдачи.
Для морфемного разбора и однокоренных слов также можно оценить качество разборов.
Рис. 11. Оценка качества морфемного разбора
Как это устроено
Как мы сказали выше, разборы в разных корпусах используют данные из разных словарей. На их основе для НКРЯ были разработаны свои цифровые словари морфемного анализа — Morphodict-K и Morphodict-T соответственно для Основного и Обучающего корпусов. Для словарных слов используются разборы, данные в морфемном словаре. Если же слово в словаре отсутствует, используется одна из двух моделей для автоматической генерации разбора.

Рис. 12. Пример морфемного разбора, сгенерированного автоматически
Подпись «сгенерировано НейроКРЯ» говорит о том, что морфемный разбор был сделан автоматически. Можно видеть, что в слове «динозаврик» было странным образом выделено два корня. Если наличие двух корней в концепции Основного корпуса еще оправдано (см. цитату о «ре-волюц-и-и» выше), то наличие между ними соединительной гласной уже сомнительно.
Модели отличаются обучающей выборкой: для каждого из корпусов используется свой словарь. Сейчас каждая из них — это модель с архитектурой на основе ансамбля сверточных нейронных сетей, но разработчики Корпуса также экспериментируют с моделью RoRoBERTa.
Модели находятся в свободном доступе на сайте НКРЯ в разделе «Морфемные модели».
Оценка тональности для корпуса социальных сетей
Что это такое
Тональность текста — это его эмоциональная окраска. Например, высказывание «на улице 18 градусов тепла» скорее нейтрально, а высказывание «наконец-то стало потеплее, ура» скорее положительно. В НКРЯ тональность представлена всего в трех вариантах: неопределенная, отрицательная и положительная.
Как это выглядит в Корпусе
Для каждого из текстов в корпусе Социальных сетей указана тональность — ее можно увидеть в карточке текста.


Рис. 13. Пример из выдачи по запросу «кот» в подкорпусе с выбранной отрицательной тональностью
Как использовать
Чтобы выбрать только положительные, отрицательные или неопределенные тексты в поиске по корпусу Социальных сетей, нужно зайти в раздел «Отбор подкорпуса».
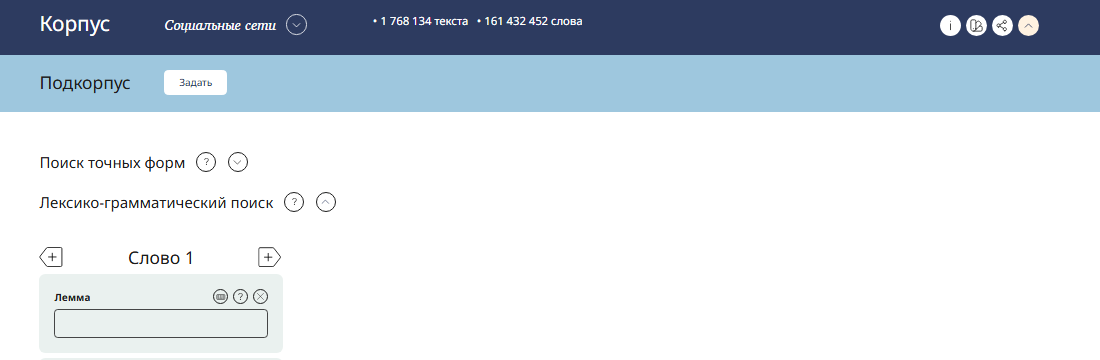
Рис. 14: Из корпуса Социальных сетей в него можно перейти, нажав кнопку «Задать»
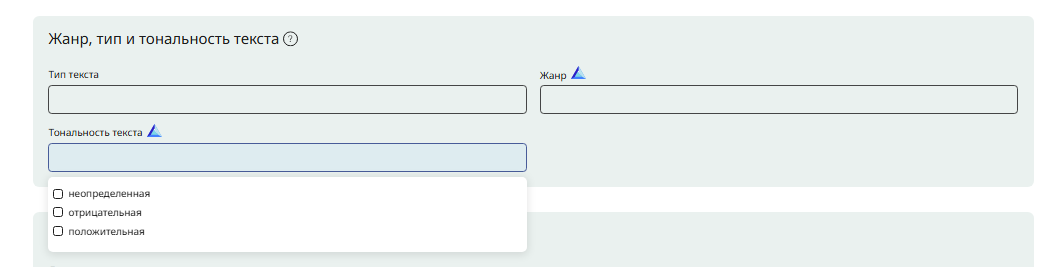
Рис. 15. Выбираем один или несколько вариантов тональности

Рис. 16. «Кот» с положительной тональностью
Как это устроено
Для разметки тональности использовалась обучающая выборка на основе датасета RuSentiment и некоторого количества текстов из корпуса Социальных сетей, размеченных вручную. Обучающий датасет был размечен в том числе силами волонтеров — «друзей НКРЯ» — с помощью телеграм-бота.
В корпусе есть три категории текстов: с положительной, отрицательной и неопределенной тональностью. В последнюю категорию попадают тексты не на русском языке, поэзия, любой не авторский текст, а также тексты, сентимент которых сложно определить ввиду сильной зашумленности. Разметка была сделана с помощью модели RuRoBERTa-large, дообученной на собранной выборке. Для оценки качества работы модели была проведена кросс-валидация и ручная проверка на небольшом наборе данных — этим занимались эксперты НКРЯ.
Ключевые слова
Что это такое
Все читатели «Системного Блока» с ними сталкивались — в конце концов, у наших статей тоже есть теги, в которых отмечена тематика. Изданиям теги и ключевые слова нужны для навигации: с их помощью читателям легче найти статьи на интересующую тематику. А для компьютерных лингвистов выделение ключевых слов — это классическая задача, примерно настолько же популярная, как суммаризация или классификация текстов.
В НКРЯ ключевые слова представлены пока только в корпусе Региональных СМИ — короткие публицистические тексты легче всего описать набором тегов. Хотя, признаться честно, посмотреть на ключевые слова в стихах, личных письмах или анекдотах тоже было бы любопытно.
Как это выглядит в Корпусе

Рис. 17. Пример набора ключевых слов для статьи о художественной выставке в Череповце
Ключевые слова извлекаются из каждой статьи. При этом облако тегов достаточно обширно: в него входят общие понятия (живопись, выставки), специфические для описываемой темы детали (Пикассо, Художественный музей), а также дополнительная информация, не относящаяся к теме статьи напрямую. В данном примере «февраль» и «череповец» — это время и место проведения выставки.
Ключевые слова может и выглядят разномастными, зато для целей отбора подкорпуса подходят идеально.
Как использовать
Ключевые слова — часть метаразметки, поэтому их можно найти в карточке текста или при отборе подкорпуса.
В корпусе Региональных СМИ вводим нужное слово или словосочетание в блок «Ключевые слова» (он в интерфейсе идет сразу после «Основных параметров»):
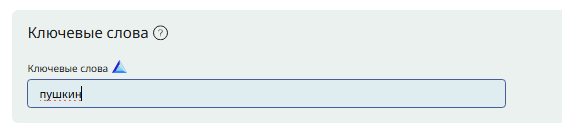
Рис. 18. Блок «Ключевые слова»
Смотрим на выдачу:

Рис. 19. Пример выдачи по ключевому слову «Пушкин»
Благодаря разнообразию ключевых слов можно находить и более конкретные истории: например, если вас интересуют постановки по Пушкину, нужно выбрать «Пушкин» и «театр».

Рис. 20. Пример выдачи по ключевым словам «Пушкин» и «театр»
Как это устроено
Для извлечения ключевых слов на основе заранее заданных правил используется библиотека RuTermExtract. Кроме того, для работы были добавлены правила предобработки (например, правило объединения биграмм в кавычках, таких как «Комсомольская правда», в одну униграмму), исправлены некоторые ошибки лемматизации и удалены однокоренные униграммы.
Хотите больше узнать об НКРЯ?
Вы можете подписаться на новости Корпуса, а также ознакомиться с публикациями о других его возможностях на сайте. Корпусу посвящены и многие материалы «Системного Блока».
Работы по пополнению Регионального и Обучающих корпусов и корпуса Русская классика в 2024–2025 гг. поддержаны Благотворительным фондом содействия образованию «ДАР».
Источники
- Bonch-Osmolovskaya A. A. et al. Russian National Сorpus 2.0: corpus platform, analysis tools, neural network models of data markup (full version) // Компьютерная лингвистика и интеллектуальные технологии. Выпуск 23.
- Morozov D. et al. Automatic Morpheme Segmentation for Russian: Can an Algorithm Re-place Experts? //Journal of Language and Education. – 2024. – Т. 10. – №. 4. – С. 71–84.
- rutermextract (библиотека Python). URL: https://github.com/igor-shevchenko/rutermextract (дата обращения: 10.07.2025).
- НКРЯ Национальный корпус русского языка (телеграм-канал). URL: https://t.me/ruscorpora (дата обращения: 10.07.2025).
- Савчук С. О. и др. Национальный корпус русского языка 2.0: новые возможности и перспективы развития //Вопросы языкознания. – 2024. – Т. 2. – С. 7–34.

