
Впервые идея использовать компьютер для автоматизации перевода текстов с одного естественного языка на другой была предложена Уорреном Уивером в 1949 году. В 1954 году возможности машинного перевода продемонстрировал Джорджтаунский эксперимент, в ходе которого с помощью компьютера быстро перевели с русского на английский язык более 60 предложений. Вот несколько примеров из того эксперимента:
Русский
Мы передаем мысли посредством речи
Величина угла определяется отношением длины дуги к радиусу
Международное понимание является важным фактором в решении политических вопросов
English translation
We transmit thoughts by means of speech.
Magnitude of angle is determined by the relation of length of arc to radius.
International understanding constitutes an important factor in decision of political questions.
Удачным этот опыт можно считать лишь с некоторыми оговорками. Система была построена на простом наборе правил, могла переводить только очень небольшой набор фраз и работала очень долго. Однако Джорджтаунский эксперимент привлек внимание к вопросу машинного перевода. Многие поверили, что еще пара лет — и наступит эра искусственного интеллекта. Правительство, военные и частные корпорации начали щедро вливать деньги в разработки.

В течение последующих тридцати лет исследователи развивали машинный перевод на основе правил: предъявленный текст на исходном языке компьютер переводил с помощью правил и предварительно загруженных словарей. Системы дословного перевода, трансферные системы и системы перевода на примерах считаются разновидностями этого подхода.
Отдельного упоминания заслуживают интерлингвистические системы, идея которых заключалась в преобразовании исходного текста в совокупность концептов, общих для всех языков, с последующей конвертацией их в текст на языке перевода. Этот подход к машинному переводу выделялся среди существовавших на тот момент, но развития так и не получил в силу своей сложности.
В 1980-х годах появился машинный перевод на основе статистических моделей (СМП) — компьютер генерировал текст перевода с помощью параллельных корпусов на языках рабочей пары, выискивая наиболее частотные соответствия слов. Параллельный корпус — это множество пар «текст + перевод». Такие тексты можно выравнивать между собой по абзацам или предложениям. Когда это сделано, на текстах можно обучать статистические модели. Скажем, если у вас есть предложения со словом кошка в русских текстах, то будет огромное количество параллельных английских предложений, где это переводится как cat. Постепенно статистическая система сама обучится тому, что кошка — это cat. Более сложные системы учитывали с помощью статистики и контекст — чтобы научиться не переводить слово «кошки» как cats, если предыдущее слово — альпинистские. Статистический машинный перевод играл ключевую роль вплоть до начала XXI века. И на разных этапах развития этого подхода машина переводила по-разному: по словам, по фразам и на основе синтаксиса.
В 1997 году Р. Ньеко и М. Форкада предложили идею применения в машинном переводе модели «кодер-декодер» — исходный текст шифруется в универсальное «представление», а потом расшифровывается на нужном языке. Напоминает интерлингвистические системы, не так ли? В 2003 году группа исследователей из Монреальского университета под руководством Й. Бенджио разработала языковую модель на основе нейросетей, которая помогла преодолеть проблему парсинга данных, характерную для популярных на тот момент статистических систем. Это и послужило отправной точкой для развития нейронного машинного перевода (НМП), который теперь занимает умы разработчиков и переводчиков.
Системы НМП обучаются на крупных корпусах текстов, что придает им сходство с СМП, однако подход к обработке текста у них совершенно иной. В 2013 году Н. Калкбреннер и Ф. Блансом разработали модель, способную с применением сверточной нейросети-кодера преобразовать исходный текст в непрерывный вектор, а затем с помощью рекуррентной нейросети-декодера перевести этот вектор в текст на языке перевода. Год спустя К. Чо с коллегами предложили в качестве кодера использовать рекуррентные нейросети — по их мнению, РНС лучше подходят для обработки текста. Давайте посмотрим, как это работает.
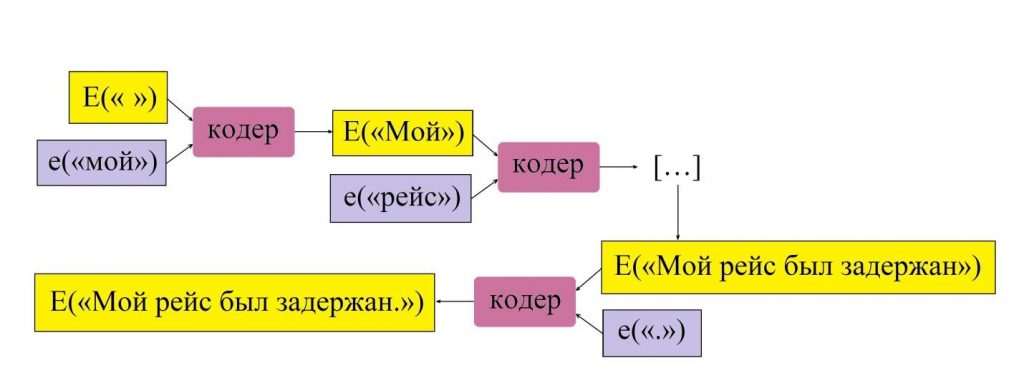
Вообразим, что нам нужно перевести на английский язык фразу «Мой рейс был задержан». Векторное представление для этого предложения автоматический переводчик собирает из последовательности векторных представлений отдельных его компонентов — e(«мой»), e(«рейс»), e(«был»), e(«задержан») и e(«.»). Такие векторные представления слов представляют собой „сжатые“ вектора их контекстов, т.е. частотностей совместного употребления с другими словами. Подробнее о контекстных векторах можно почитать тут. Процедура кодирования текста при помощи векторных представлений состоит из следующих шагов:
1. Нейросеть-кодер добавляет к уже существующему (предварительно полученному) представлению для пробела E(«») представление первого слова e(«мой») и получает E(«Мой»).
2. Затем нейросеть-кодер добавляет к E(«Мой») векторное представление e(«рейс») и получает E(«Мой рейс»).
3. На следующих этапах к E(«Мой рейс») кодер добавляет e(«был») и получает E(«Мой рейс был») — и так до тех пор, пока не выдаст представление всего предложения — E(«Мой рейс был задержан.»).
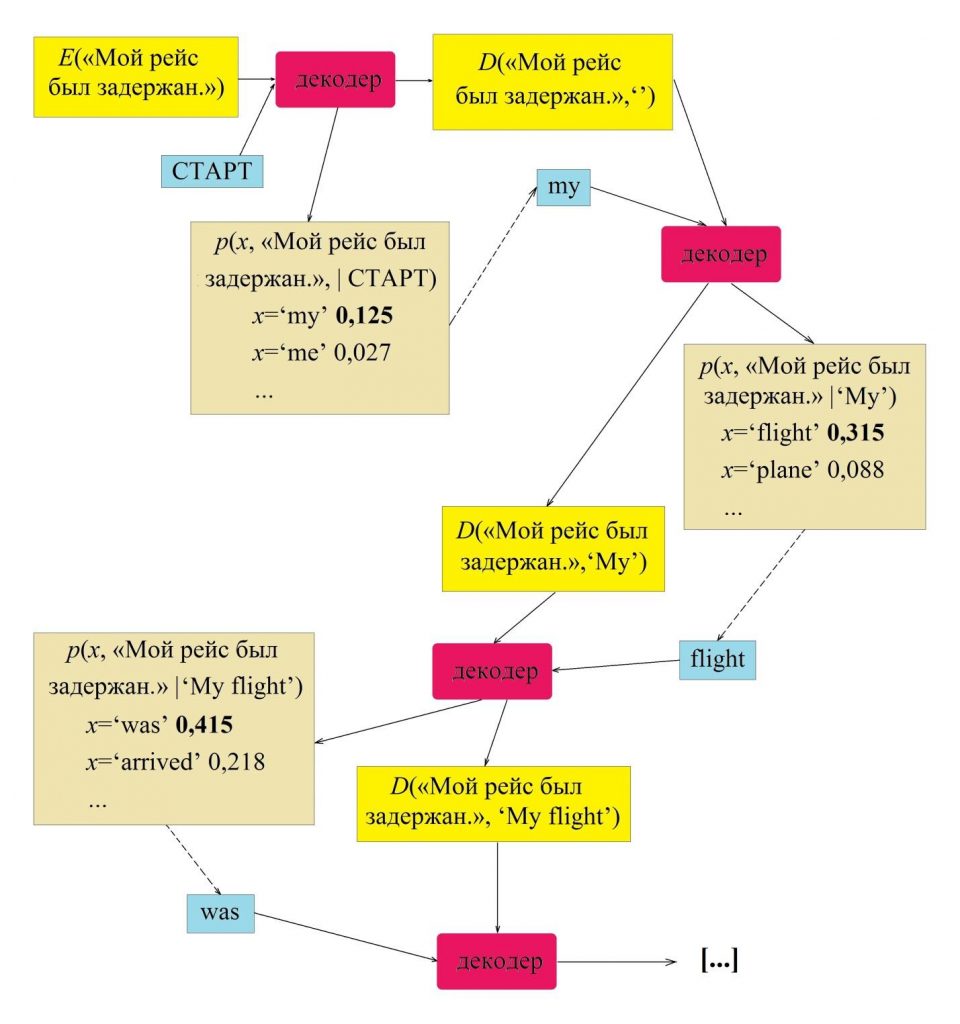
Только после этого система создает текст на целевом языке. Простейший декодер работает следующим образом:
1. Получив зашифрованное представление целого предложения E(«Мой рейс был задержан.»), декодер генерирует два вектора: исходное состояние декодера D(«Мой рейс был задержан.»,‘’), где ‘’ — пока пустая последовательность слов на языке перевода, и вектор, определяющий степень вероятности для всех возможных вариантов x — первого слова в предложении, — p(x|»Мой рейс был задержан.»,‘’). Хорошо обученная нейросеть-декодер присвоит максимальное значение правдоподобия английскому слову x=‘My’.
2. Декодер читает D(«Мой рейс был задержан.»,‘’) и слово ‘My’, и генерирует два вектора: один отражает текущее состояние D(«Мой рейс был задержан.»,‘My’), второй рассчитывает степень вероятности для всех возможных вариантов x — слова, стоящего вторым в предложении, — p(x|»Мой рейс был задержан.»,‘My’). Хорошо обученная нейросеть-декодер присвоит максимальное значение правдоподобия английскому слову ‘flight’.
3. На следующем этапе к D(«Мой рейс был задержан.»,‘My’) добавится ‘flight’ — система получит D(«Мой рейс был задержан.», ‘My flight’) и p(x|»Мой рейс был задержан.», ‘My flight’); далее, предположим, наиболее правдоподобным переводом для x система сочтет ‘was’ — тогда к D(«Мой рейс был задержан.», ‘My flight’) нейросеть добавит ‘was’ и получит D(«Мой рейс был задержан.», ‘My flight was’) и p(x|»Мой рейс был задержан.», ‘My flight was’) и т.д.
До тех пор, пока на выходе не получится ‘My flight was delayed’. Следующим наиболее правдоподобным этапом декодер сочтет завершение перевода.
На каждом этапе перевода нейросеть обращается к результатам предыдущего и частично опирается на них, используя релевантные и отбрасывая нерелевантные.
К структуре «кодер-декодер» довольно быстро решили добавить еще один элемент — так называемый «механизм внимания». Благодаря ему декодер учитывает не только последнее представление, предложенное кодером (в нашем примере — E(«Мой рейс был задержан.»)), но и всю последовательность представлений, полученных на этапе кодирования (E(«Мой», E(«Мой рейс«) и т.д.) — за счет дополнительных нейронных связей и слоев. Вообще, в зависимости от характеристик, существующие модели могут по-разному работать с текстом: есть машины, способные учитывать и единицы, следующие за обрабатываемым словом, что делает перевод более точным.
Возможности нейросетей заставляют крупных игроков переключаться на НМП. Еще в сентябре 2016 года Google начал использовать НМП вместо статистического перевода по фразам для пары китайский-английский, а спустя какое-то время добавил еще несколько языков. Любопытно, что Google Translate до сих пор переключается с НМП на СМП для некоторых языковых пар и, поскольку НМП «обращает внимание на контекст», можно узнать, какая именно модель используется в данный момент. В языковых парах, для которых все еще применяется СМП, система подсвечивает отдельные элементы целевого предложения, если навести на него курсор; в случае с языками, для которых подключена нейросеть, предложения подсвечиваются полностью. Из-за этого, кстати, сложнее отследить происхождение ошибок.
Сейчас архитектура «кодер-декодер» на основе РНС, встроенный механизм внимания и длительная кратковременная память (LSTM) — обязательный минимум для среднестатистического онлайн-переводчика (хотя в июне 2017 года появилась новая модель, в которой используются только механизмы внимания). Кроме того, в некоторых системах стали внедрять механизм краудсорсинга. Тот же Google Translate предлагает пользователю отметить наиболее удачный вариант перевода и запоминает самые часто выбираемые из них.
Чтобы сравнить СМП и НМП, в 2016 году провели эксперимент на параллельном корпусе ООН — это 15 языковых пар и 30 направлений перевода. Результаты оценивали с помощью шкалы BLEU (оценивает близость машинного перевода к эталонному человеческому, выполненному профессиональным переводчиком), и по качеству перевода нейросеть не уступала или превосходила СМП во всех 30 направлениях. Исследователи пришли к выводу, что нейросеть делает меньше морфологических и синтаксических ошибок.
Несмотря на все преимущества НМП, ошибки все еще неизбежны, да и процесс обучения нейросетей занимает много времени. К тому же у статистических моделей тоже есть свои сильные стороны. Поэтому в последнее время исследователи комбинируют различные подходы к автоматизации перевода: в попытке добиться более естественного текста рождаются гибридные системы машинного перевода. За примером такой машины далеко ходить не нужно: это всем знакомый Яндекс.Переводчик.

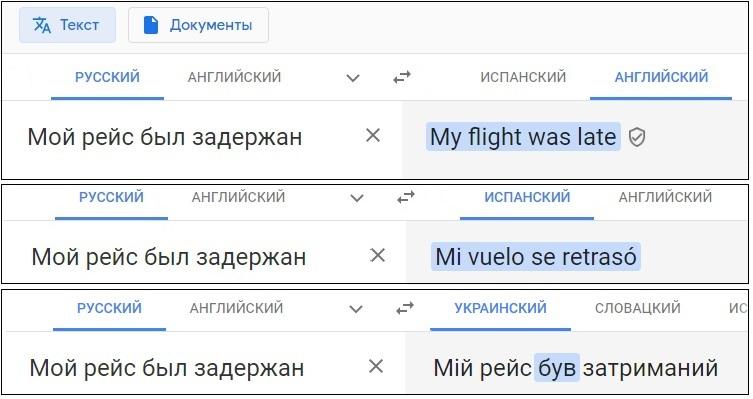
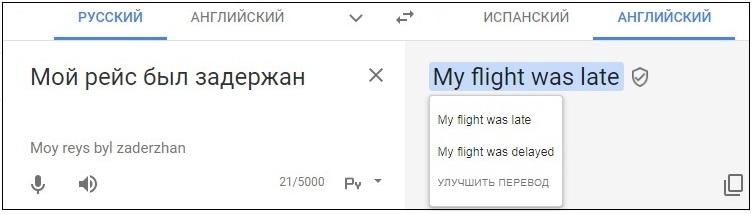
В Яндекс.Переводчике свои варианты перевода генерируют обе модели, а потом специальный алгоритм оценивает/отбирает/комбинирует их и выдает результат. Эксперименты показывают, что переключение модели часто зависит от длины текста и того, есть ли в нем полные предложения — на совсем коротких примерах нейросети иногда еще проигрывают классической статистике. Легкий способ переключиться с обычной статистической модели на нейросеть — добавить точку:

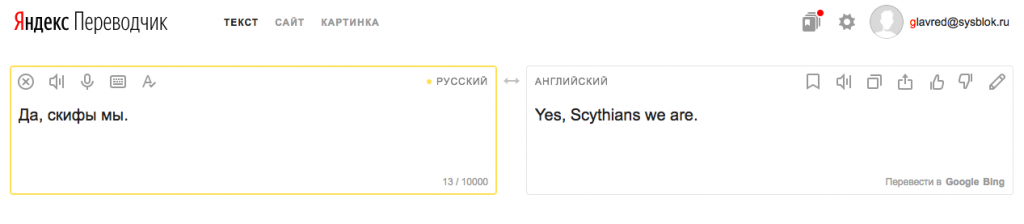
Вполне возможно, что в обозримом будущем именно гибридные системы будут править бал.
Источники
- Машинный перевод: От холодной войны до диплёрнинга
- Машинный перевод с применением графического процессора (Части 1, 2, 3 на русском языке)
- Как работает нейронный машинный перевод?
- History and Frontier of the Neural Machine Translation
- Making sense of neural machine translation



