
В этом посте описаны основные недавние достижения в области обработки естественного языка с помощью нейронных сетей.
Дисклеймер: Около 15 лет плодотворной работы ученых здесь представлены всего восемью важнейшими достижениями, наиболее актуальными на сегодня. В частности, фокус сильно смещен в сторону описания современных нейросетевых подходов. Из-за этого может создаться ложное впечатление, что никакие другие методы не оказывали влияния на развитие автоматической обработки языка. Это не так, просто многие важные события не упомянуты в статье сознательно. Что еще более важно, многие модели нейронных сетей, описанные в этом посте, основаны на достижениях той же эпохи, не связанных с развитием нейросетей. В заключительном разделе специально упомянут один влиятельный труд, заложивший основу последующих успехов нейросетей.
2001 — Нейронные языковые модели
Задача языкового моделирования в узком смысле — спрогнозировать следующее слово в тексте, глядя на предшествующие слова. Вероятно, это самая простая задача в сфере обработки языка, результат решения которой имеет конкретное практическое применение в виде интеллектуальных клавиатур, предложения возможного ответа на электронное письмо (Kannan et al., 2016), автоисправления ошибок и опечаток, и так далее.
Неудивительно, что языковое моделирование имеет богатую историю. В основе классических подходов лежит N-граммная модель; чтобы обработать N-граммы, которые модель не встречала, в них задействуются методы сглаживания (Kneser & Ney, 1995).
Первая нейронная языковая модель, построенная на основе нейросети прямого распространения, была предложена Йошуа Бенжио в 2001 году. Схема ее работы выглядит так:
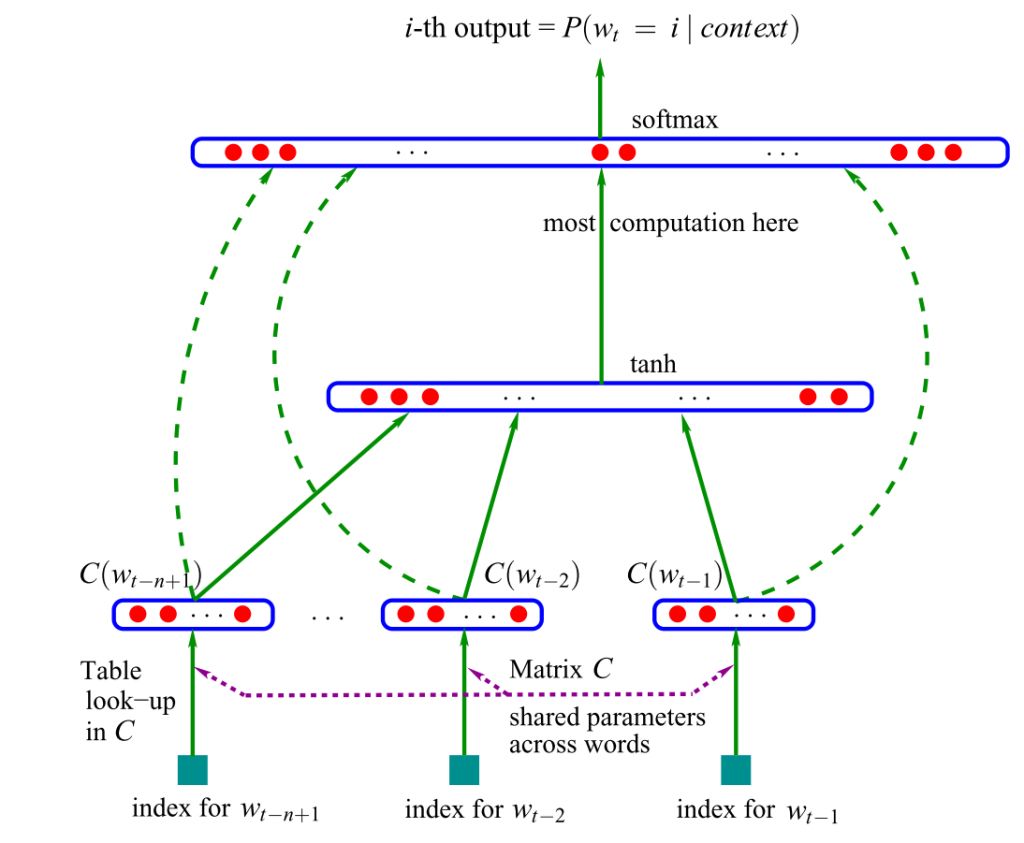
В качестве входных данных эта модель принимает векторные представления n предыдущих слов (Системный Блокъ рассказывал о векторных представлениях слов тут и тут). В настоящее время для таких векторных представлений слов используют сжатый вариант — эмбеддинги (word embedding). Эти сжатые векторы объединяются и передаются в скрытый слой, выходные данные которого затем передаются в softmax слой, где срабатывает функция активации (она решает, какой сигнал пойдет дальше, а какой «потухнет», так определяется и итоговая выдача нейросети).
Позднее для языкового моделирования вместо нейронных сетей с прямой связью стали использоваться рекуррентные нейронные сети (RNN; Mikolov et al., 2010), а также сети с долгой краткосрочной памятью (LSTM-сети; Graves, 2013). В последние годы было предложено много новых языковых моделей, расширяющих возможности классических LSTM-сетей.
Однако классические LSTM-сети сохраняют свои позиции (Melis et al., 2018). Даже обычная нейронная сеть с прямой связью, использованная Бенжио в 2001 году, в некоторых условиях способна составить конкуренцию более сложным моделям, поскольку все они учатся воспринимать только самые близкие предшествующие слова (Daniluk et al., 2017). Отдельные исследования ведутся для того, чтобы понять, какая именно информация позволяет таким языковым моделям работать (Kuncoro et al., 2018; Blevins et al., 2018).
Языковое моделирование — самая подходящая тренировочная площадка для применения RNN. Построение языковой модели относится к задачам обучения без учителя. Один из главных авторитетов в области глубинного обучения Ян Лекун называет это предиктивным или прогностическим обучением и считает его предварительным условием приобретения нейронными сетями здравого смысла. Вероятно, наиболее знаменательная особенность языкового моделирования заключается в том, что, несмотря на его простоту, оно служит основой для многих последующих достижений, обсуждаемых в этом посте:
- Word embeddings (векторные представления слов): цель word2vec (модели векторного представления слов) — упрощение языкового моделирования.
- Модели sequence-to-sequence (seq2seq): такие модели генерируют выходную последовательность, предсказывая по одному слову за раз. При помощи seq2seq-моделей работает машинный перевод, извлечение информации и многие другие актуальные прикладные системы.
- Предварительно обученные языковые модели: эти методы используют представления из языковых моделей для переноса обучения, то есть использования данных одной нейросети для обучения другой.
Таким образом, многие недавние достижения в области обработки естественного языка сводятся к одному из видов языкового моделирования. Однако чтобы добиться настоящего понимания естественного языка, простого обучения на «сырых» необработанных текстах, скорее всего, будет недостаточно — потребуются новые методы и модели.
2008 — Многозадачное обучение
Многозадачное обучение — это общий подход, при котором модели обучаются выполнению различных задач на одних и тех же параметрах. В нейронных сетях этого можно легко добиться, связав веса разных слоев. Идея многозадачного обучения была впервые предложена Ричем Каруаной в 1993 году и применялась для прогнозирования пневмонии, а также для создания системы следования дороге на беспилотных устройствах (Каруана, 1998). Фактически при многозадачном обучении модель стимулируют к созданию внутри себя такого представления данных, которые позволяет выполнить сразу много задач. Это особенно полезно для обучения общим низкоуровневым представлениям, на базе которых потом происходит «концентрация внимания» модели (см. раздел «Внимание» далее в этой статье) или в условиях ограниченного количества обучающих данных.
Многозадачное обучение нейросетей для обработки естественного языка было впервые применено в 2008 году Коллобером и Уэстоном (Collobert & Weston, 2008). В их модели матрица векторных представлений слов является общей для двух моделей, обучающихся различным задачам:
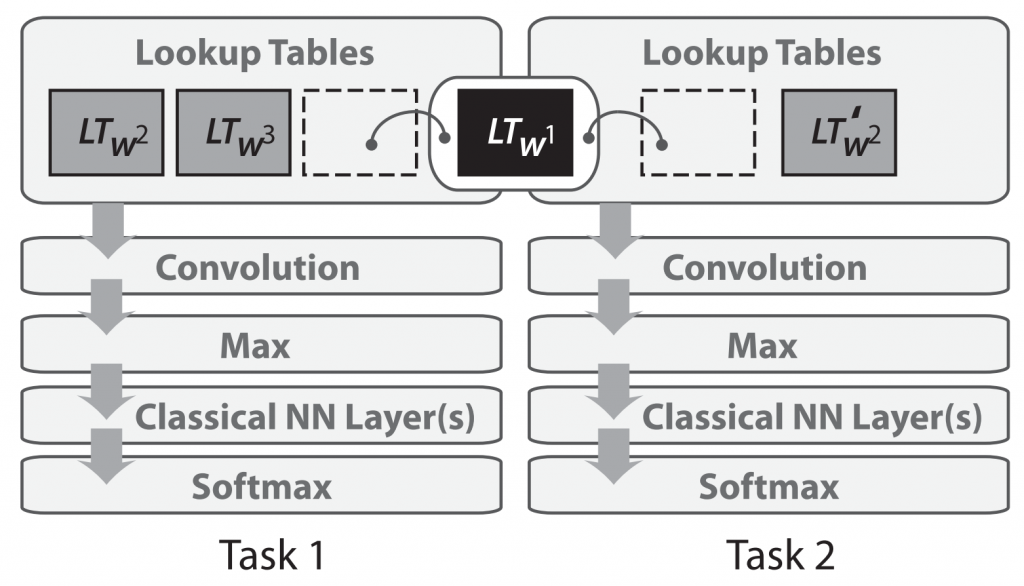
Совместное использование одних и тех же векторных представлений слов позволяет моделям взаимодействовать и обмениваться общей информацией низкоуровневого характера, т.е. некоторыми «базовыми» представлениями об элементах текстов.
Результаты Коллобера и Уэстона после их публикации в 2008 году оказали влияние не только на использование многозадачного обучения. В статье также были выдвинуты такие идеи, как создание предварительно обученных матриц векторных представлений слов и использование сверточных нейронных сетей для работы с текстом — раньше сверточные сети (CNN) использовались только для изображений, и лишь недавно оказалось, что они применимы в NLP. На международной конференции по машинному обучению в 2018 году статья была удостоена награды test-of-time (испытание временем).
Многозадачное обучение теперь используется для самых разных задач обработки естественного языка. Иногда вторая задача, которую заставляют решать многозадачную модель, вообще совершенно искусственная — что-то типа «найти в тексте все упоминания животных». На самом деле нам не нужно их искать: нейросеть обучают и этому тоже просто для того, чтобы улучшить выполнение основной задачи (например, предсказания следующего слова). Удивительно, но это работает: благодаря мультиобучению основная модель получает более хорошие признаки на вход — подробнее см. в (Ruder et al., 2017).
Сейчас модели все чаще оцениваются по результатам решения сразу нескольких задач, по их способности к обобщению. Многозадачное обучение приобретает все большее значение, и для него разрабатывают все больше способов оценки качества (Wang et al., 2018; McCann et al., 2018).
2013 — Word embeddings (векторное представление слов)
Разреженные матрицы векторно представленного текста, так называемая модель «мешка слов», имеет долгую историю в области обработки естественных языков. Плотные векторные представления слов или word embeddings также используются еще с 2001 года, как было сказано выше. Основное нововведение, предложенное в 2013 году Томашом Миколовым и его соавторами, сделало обучение этих векторных представлений слов более эффективным посредством устранения скрытого слоя и аппроксимации цели. Хотя эти изменения были просты по своей природе, они позволили — в совокупности с эффективной реализацией word2vec модели — провести массовое обучение векторных представлений слов.
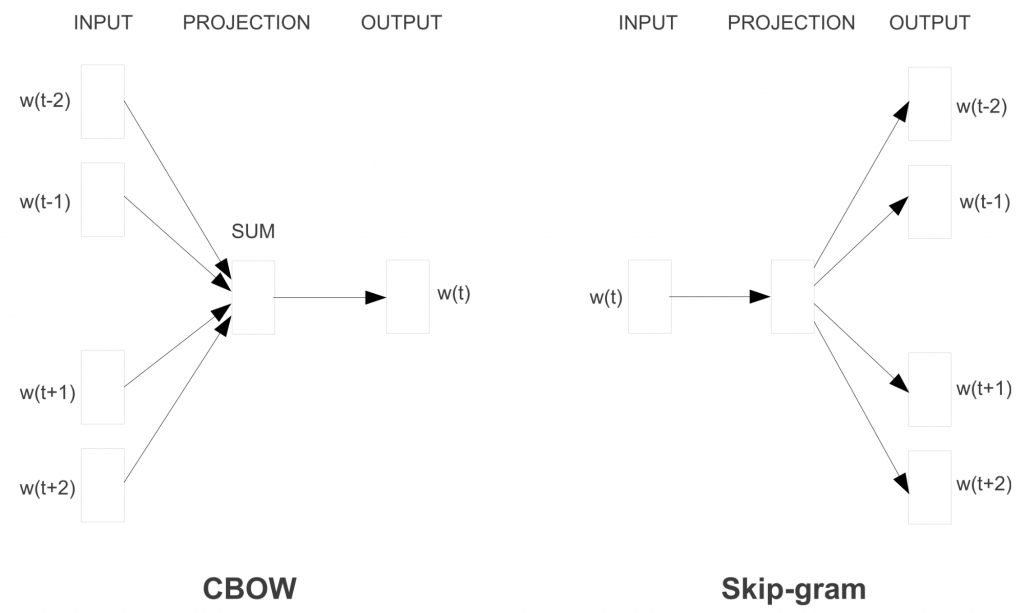
У word2vec модели есть две разновидности, которые можно увидеть на рис. 3 ниже: «непрерывный мешок слов (continuous bag of words)» и «словосочетание с пропуском (skip-gram)». Они различаются по своей цели: первая предсказывает центральное слово на основе окружающих его слов, а вторая выполняет обратное действие.
Хоть эти векторные представления и не отличаются концептуально от тех, которые были обучены посредством нейронной сети с прямой связью, обучение на очень большом корпусе позволяет им научиться приблизительно определять гендерные и видовременные отношения между словами и их формами, а также отношения между страной и ее столицей, что можно увидеть на рис. 4 ниже.
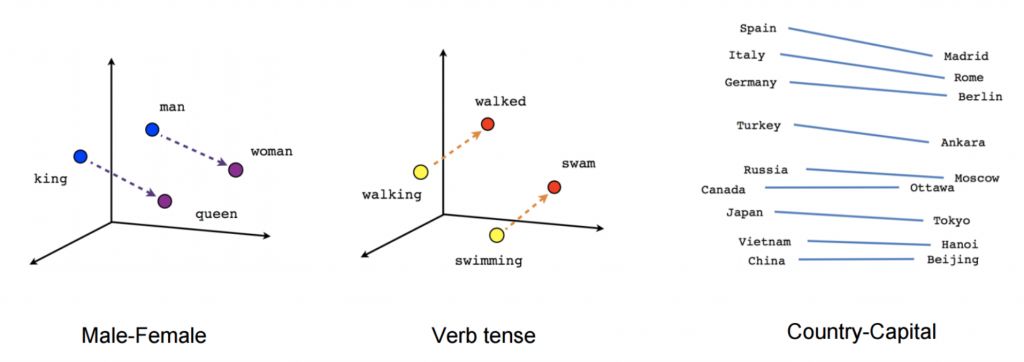
Эти отношения и смыслы, стоящие за ними, и вызвали первоначальный интерес к векторным представлениям слов; многие исследования были посвящены определению происхождения этих линейных отношений (Arora et al., 2016; Mimno & Thompson, 2017; Antoniak & Mimno, 2018; Wendlandt et al., 2018). Однако более поздние исследования показали, что отношения между словами не всегда определяются объективно (Bolukbasi et al., 2016). Развитие векторных представлений слов стало основным направлением в области естественной обработки языка благодаря тому, что использование предварительно обученных представлений для инициализации улучшает результативность решения широкого спектра последующих задач.
Когда-то отношения между словами и их векторными представлениями казались почти волшебными, однако более поздние исследования показали, что в алгоритме word2vec нет ничего особенного: определению таких отношений можно также обучить, применяя методы матричной факторизации (Pennington et al, 2014; Levy & Goldberg, 2014), и при правильной настройке, использование классических подходов к факторизации матрицы, таких как сингулярное разложение и латентно-семантический анализ (LSA; «Системный Блокъ» немного писал об этом здесь), приводит к достижению аналогичных результатов (Levy et al., 2015).
С тех пор была проделана большая работа по изучению различных аспектов векторных представлений слов (о чем свидетельствует огромное количество цитирований оригинальной статьи Миколова и его соавторов). Несмотря на многие нововведения, алгоритм word2vec по-прежнему популярен и широко используется в наше время. Word2vec модели стали использоваться даже за пределами уровня слова: модель «словосочетание с пропуском» с отрицательной выборкой (skip-gram with negative sampling), удобная для обучения векторных представлений на основе локального контекста, использовалась для создания векторных представлений предложений (Mikolov & Le, 2014; Kiros et al., 2015) и даже за пределами области обработки естественного языка: в сетях (Grover & Leskovec, 2016), биологических последовательностях (Asgari & Mofrad, 2015), и других областях.
Одним из особенно интересных направлений является проекция векторных представлений слов разных языков в одно и то же пространство для обеспечения межъязыкового перевода (с нуля). Обучение такой проекции хорошего качества полностью без учителя становится все возможнее (по крайней мере, для похожих языков) (Conneau et al., 2018; Artetxe et al., 2018; Søgaard et al., 2018), что находит применение в переводе с низкоресурсных языков и обратно, а также машинном переводе без учителя (Lample et al., 2018; Artetxe et al., 2018).
2013 — Нейронные сети для обработки естественного языка
2013 и 2014 годы ознаменовали начало внедрения нейросетевых моделей в процесс обработки естественного языка. Наиболее широко стали использоваться три основных типа нейронных сетей: рекуррентные нейронные сети, сверточные нейронные сети и рекурсивные нейронные сети.
Рекуррентные нейронные сети
Рекуррентные нейронные сети (RNN) являются очевидным выбором при работе с динамическими входными последовательностями, повсеместно встречающимися при обработке естественного языка. «Ванильные» RNN (Elman, 1990) были быстро заменены классическими LSTM-сетями, то есть сетями с долгой краткосрочной памятью (Hochreiter & Schmidhuber, 1997), которые оказали большее сопротивление возникающей проблеме исчезающего (или взрывного) градиента.
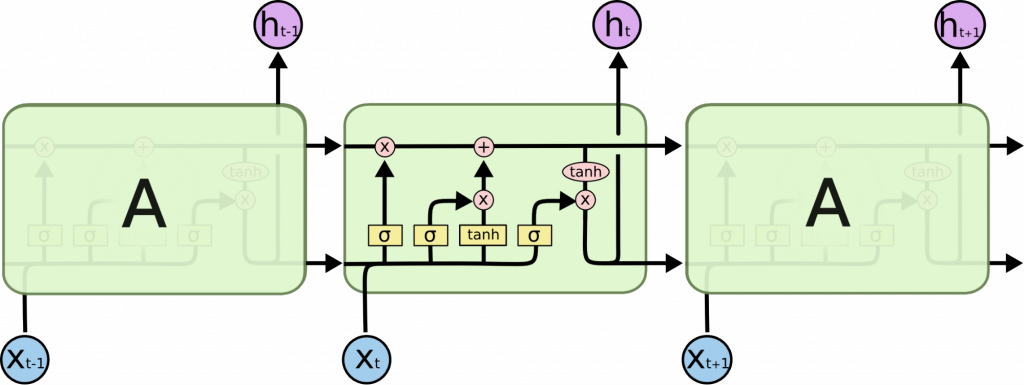
До 2013 года обучение RNN все еще считалось трудной задачей; кандидатская диссертация Ильи Суцкевера (Sutskever, 2013) стала ключевым элементом на пути к изменению сложившейся репутации. Схема ячейки LSTM-сети представлена на рис. 5 ниже. Двунаправленная LSTM-сеть (Graves et al., 2013) обычно используется для работы одновременно с левым (предшествующим единице) и правым (последующим) контекстом.
Сверточные нейронные сети
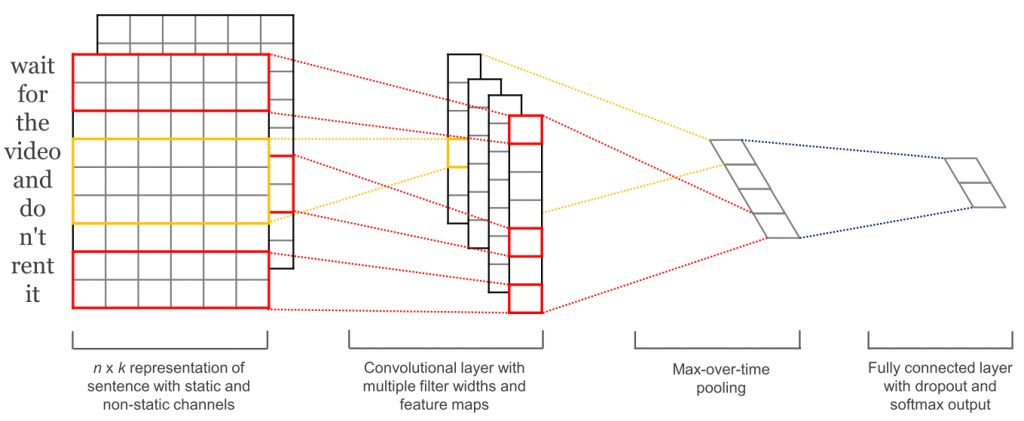
Когда сверточные нейронные сети (CNN) стали широко использоваться в компьютерном зрении, они также начали применяться в обработке языка (Kalchbrenner et al., 2014; Kim et al., 2014). При работе с текстом, параметры сверточной нейросети задаются только в двух измерениях, причем фильтры необходимо перемещать только во временном измерении. На рис. 6 представлена схема типичной сверточной нейросети, использующейся для обработки естественного языка.
Преимущество сверточных нейронных сетей состоит в том, что их можно распараллелить в большей степени, чем РНС, поскольку состояние нейронных элементов на каждом временном шаге зависит только от локального контекста (благодаря операции свертки), а не от всех прошлых состояний, как в РНС. С использованием расширенных свертков, а значит расширением полей восприятия, могут быть расширены и сами СНС, что позволит им охватить более широкий контекст (Kalchbrenner et al., 2016). СНС и LSTM-сети также могут быть объединены и вложены друг в друга (Wang et al., 2016), а свертки могут быть использованы для ускорения LSTM-сетей (Bradbury et al., 2017).
Рекурсивные нейронные сети
И RNN, и CNN рассматривают язык как последовательность слов. Однако с лингвистической точки зрения язык по своей сути иерархичен: слова образуют единицы более высокого порядка, такие как фразы и предложения, которые, в свою очередь, могут рекурсивно объединяться в соответствии с правилами языка. Пришедшая из области лингвистики идея рассматривать предложения как деревья, а не как последовательность слов, порождает рекурсивные нейронные сети (Socher et al., 2013), схему работы которых можно увидеть на рис. 7 ниже.
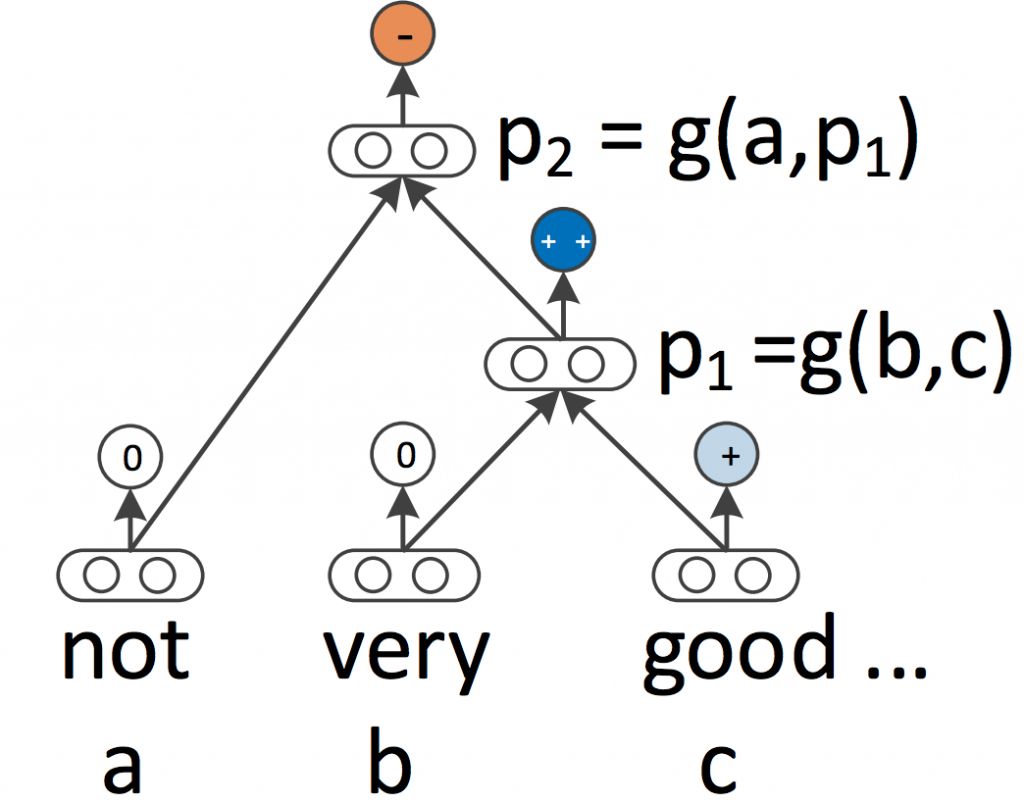
Рекурсивные нейронные сети строят представление последовательности снизу вверх, в отличие от RNN, которые обрабатывают предложение слева направо или справа налево. В каждом узле дерева новое представление вычисляется путем «слияния» представлений дочерних узлов. Поскольку дерево также можно рассматривать как метод, просто изменяющий порядок обработки данных в RNN, LSTM-сети естественным образом были расширены до деревьев (Tai et al., 2015).
Не только RNN и LSTM-сети могут быть расширены таким образом для работы с иерархическими структурами. Векторные представления слов также можно обучать, основываясь не только на локальном, но и на грамматическом контексте (Levy & Goldberg, 2014); языковые модели могут генерировать слова на основе синтаксического стека (Dyer et al., 2016); а сверточные нейронные сети на графах могут оперировать деревьями (Bastings et al., 2017).
2014 — Модели sequence-to-sequence (seq2seq)
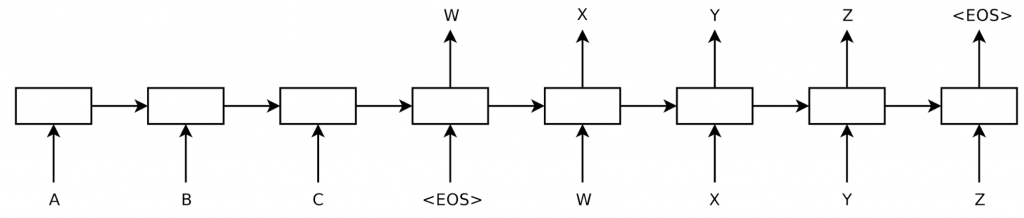
В 2014 году Суцкевер и соавт. предложили новую модель обучения — sequence-to-sequence (из последовательности в последовательность), общей концепцией которой является преобразование одной последовательности в другую с использованием нейронной сети. Механизм ее работы таков: одна нейросеть-кодер (encoder) обрабатывает предложение символ за символом и сжимает данные в векторное представление; а вторая нейросеть-декодер (decoder) затем прогнозирует выходные данные, также посимвольно, основываясь на состоянии кодера, и принимая в качестве входных данных символ, предсказанный на предыдущем шаге. Схему ее работы можно увидеть на рис. 8 ниже.
Применение этой структуры в машинном переводе оказалось очень эффективным. В 2016 году Google объявил, что начинает заменять свои монолитные, основанные на переводе фраз, модели машинного перевода на нейронные модели (Wu et al., 2016). По словам Джеффа Дина, легендарного главного IT-спеца корпорации Google, это означало замену 500 000 строк кода, из которых состояла модель фразового машинного перевода, на 500 строк кода нейронной сети.
Благодаря своей гибкости, в настоящее время эта структура является ключевой для решения задач генерации естественного языка, причем роль кодера и декодера может отводиться различным моделям. Важно отметить, что модель декодера может быть настроена на генерацию не только последовательности, но и произвольных представлений. Это позволяет, например, сгенерировать подпись для картинки на ее основе (Vinyals et al., 2015) (как видно на рис. 9 ниже), текст на основе таблицы (Lebret et al., 2016) описание на основе изменений исходного кода (Loyola et al., 2017), и многое другое.
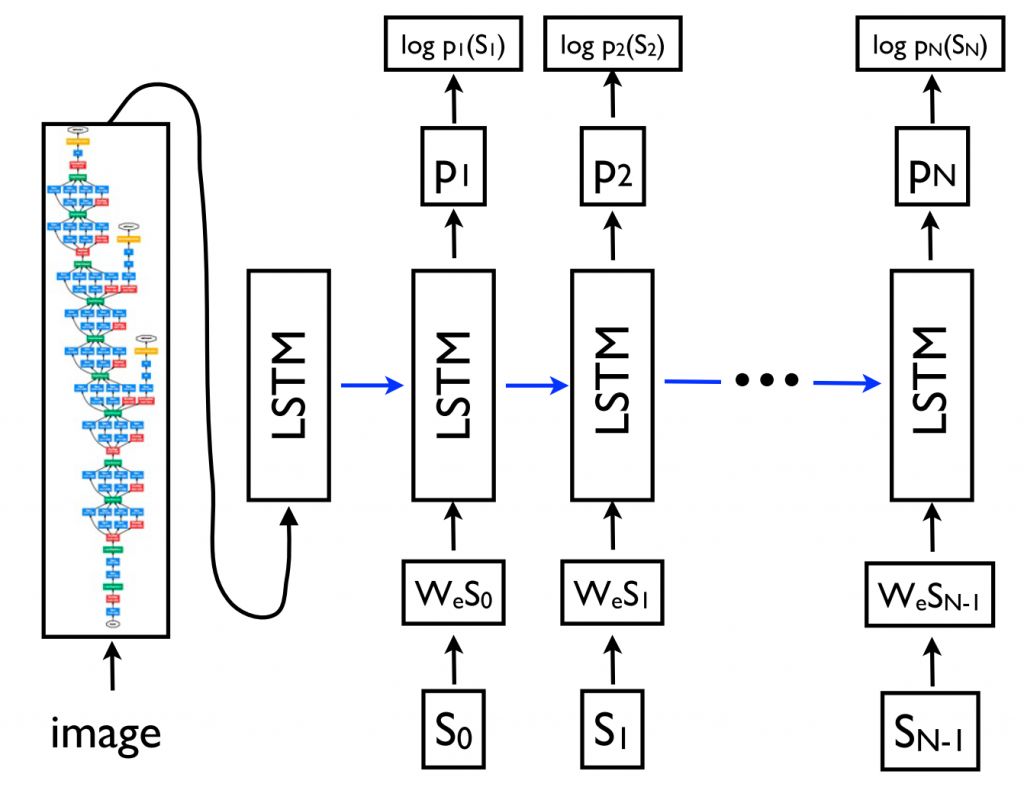
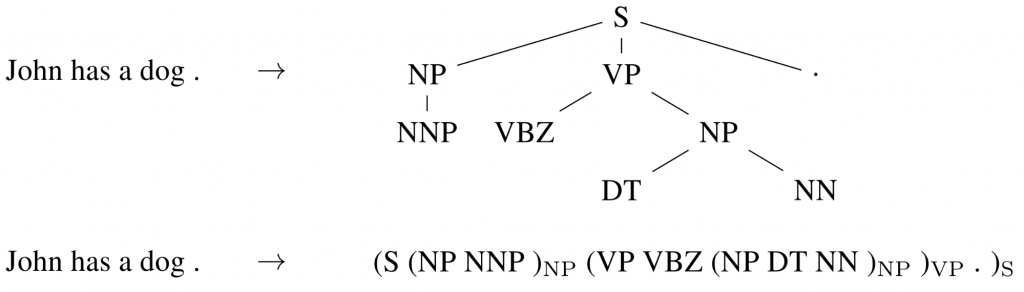
Sequence-to-sequence обучение может даже применяться к частым при обработке естественного языка задачам структурного прогнозирования, когда выходные данные имеют конкретную структуру. Для простоты вывод линеаризован, что можно увидеть на рис. 10 ниже, на котором представлена схема синтаксического анализа предложения на основе грамматики составляющих. При достаточном объеме обучающих данных, нейронные сети продемонстрировали способность непосредственно обучаться производить такой линеаризованный вывод для проведения синтаксического анализа (Vinyals et al, 2015), выделения именованных объектов (Gillick et al., 2016), и др.
Кодеры для последовательностей и декодеры обычно основаны на РНС, но могут использоваться и другие типы моделей. Новые архитектуры в основном появляются из области машинного перевода, которая выступает в качестве чашки Петри для sequence-to-sequence архитектур. Последние модели — это глубокие LSTM-сети (Wu et al., 2016), сверточные кодеры (Kalchbrenner et al., 2016; Gehring et al., 2017), архитектура Transformer (Vaswani et al., 2017), которая будет обсуждаться в следующем разделе, и комбинация LSTM-сети с этой архитектурой (Chen et al., 2018).
2015 — Внимание
Механизм внимания (Bahdanau et al., 2015) — одно из ключевых нововведений в области нейронного машинного перевода. Внимание позволило моделям нейронного машинного перевода превзойти классические системы машинного перевода, основанные на переводе фраз. Основным узким местом в sequence-to-sequence обучении является то, что все содержимое исходной последовательности требуется сжать в вектор фиксированного размера. Внимание облегчает эту задачу, так как позволяет декодеру оглядываться на скрытые состояния исходной последовательности, которые затем в виде средневзвешенного значения предоставляются в качестве дополнительных входных данных в декодер, что можно увидеть на рис. 11 ниже.
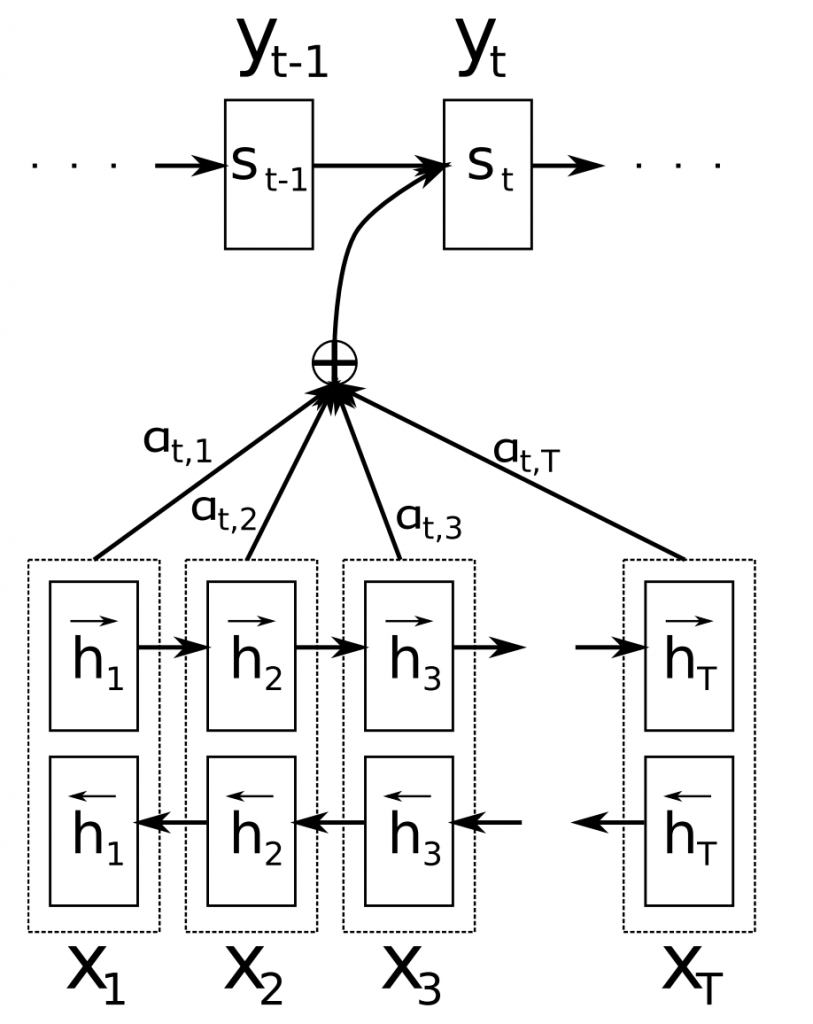
Доступны разные формы внимания (Luong et al., 2015). Внимание широко применимо и потенциально полезно при решении любой задачи, которая требует принятия решений на основе определенных компонентов входных данных. Оно применялось в синтаксическом анализе предложения на основе грамматики составляющих (Vinyals et al., 2015), чтении с пониманием прочитанного (Hermann et al., 2015), обучении на одном примере (Vinyals et al., 2016) и многих других. Входные данные даже не обязательно должны быть последовательностью, а могут состоять из других представлений, как в случае создания подписи для изображения (Xu et al., 2015), что можно увидеть на рис. 12 ниже. Полезный побочный эффект внимания заключается в том, что оно обеспечивает редкое, пусть даже и поверхностное, представление о внутренней работе модели: основываясь на весах внимания, можно узнать, какие компоненты входных данных имеют отношение к конкретному выходному результату.

Внимание также не сводится только к просмотру входной последовательности; Внимание к себе можно использовать для просмотра окружающих слов в предложении или документе, чтобы получить более контекстно-зависимые представления слов. Многоуровневое внимание к себе лежит в основе архитектуры Transformer (Vaswani et al., 2017), на данный момент передовой модели, использующейся для нейронного машинного перевода.
2015 — Нейронные сети с ассоциативной памятью
Внимание можно рассматривать как форму нечеткой памяти, состоящей из прошлых скрытых состояний модели; причем модель самостоятельно решает, что именно извлекать из памяти. Однако, было предложено много моделей и с более эксплицитной памятью. Есть много разных вариаций, например, нейронная машина Тьюринга (Graves et al., 2014), сети памяти (MemNN) (Weston et al., 2015) и сквозные сети памяти (MemN2N) (Sukhbaatar et al., 2015), сети динамической памяти ( Kumar et al., 2015), дифференцируемый нейрокомпьютер (Graves et al., 2016) и рекуррентная сущностная сеть (Henaff et al., 2017).
Обращение к памяти подобно вниманию и часто осуществляется на основе сходства, ассоциации, с текущим состоянием; память, как правило, может записываться и считываться. Модели отличаются тем, как у них устроена память и как они ее используют. Например, сквозные сети памяти обрабатывают входные данные несколько раз и каждый раз обновляют память, чтобы сделать процесс умозаключения многоступенчатым. Память нейронных машин Тьюринга умеет запоминать относительные пути, что позволяет им обучаться простым алгоритмам (компьютерным программам), таким как сортировка. Модели с ассоциативной памятью, как правило, применяются в решении задач, для которых полезно хранить информацию в течение длительного времени, например, в языковом моделировании или чтении с пониманием прочитанного. Концепция памяти очень универсальна: в качестве памяти может функционировать база знаний или таблица, также она может быть заполнена на основе всех входных данных или отдельных их компонентов.
2018 — Предварительно обученные языковые модели
Предварительно обученные векторные представления слов не зависят от контекста, который анализируется в данный момент, и используются только для инициализации весов первого слоя в наших моделях. В последние месяцы целый ряд задач обучения с учителем использовался для предварительного обучения нейронных сетей (Conneau et al., 2017; McCann et al., 2017; Subramanian et al., 2018). Для обучения языковым моделям требуется лишь неразмеченный текст; и таким образом, масштабы обучения могут достигать миллиардов токенов, новых доменов и новых языков.
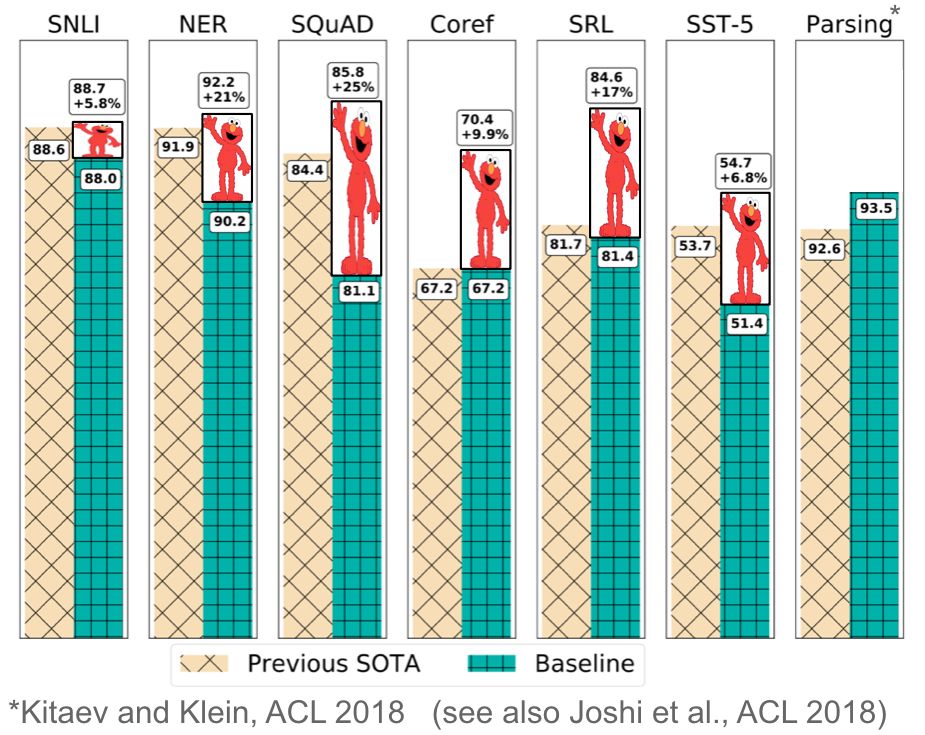
Предварительно подготовленные языковые модели были впервые предложены в 2015 году (Dai & Le, 2015), но только недавно их полезность при решении самых разных задач была доказана. Встроенные языковые модели могут использоваться как составляющие целевой модели (Peters et al., 2018), или языковая модель может быть точно настроена на данные задачи-адресата (Ramachandran et al., 2017; Howard & Ruder, 2018). Встраивание языковой модели значительно улучшает даже самые передовые решения множества различных задач, что показано на рис. 13 ниже.
Предварительно обученные языковые модели доказали возможность обучения на значительно меньшем количестве данных. Поскольку для языковых моделей требуются лишь неразмеченные данные, они особенно полезны при работе с малоресурсными языками с дефицитом размеченных данных («Системный Блокъ» недавно рассказывал о других способах работы с малоресурсными языками).
Другие достижения
Есть и другие достижения, которые распространены менее, чем все уже упомянутые выше, но все же имеют довольно широкий спектр применения.
Символьные представления
Использование СНС или LSTM-сетей при обработке символов для получения символьного представления слов в настоящее время довольно распространено, особенно для работы с языками с развитой системой морфологических форм, а также при решении задач, где важна морфологическая информация или с большим количеством неизвестных слов. Символьные представления были впервые использованы для морфологической (частеречной) разметки и языкового моделирования (Ling et al., 2015), и синтаксического анализа на основе грамматики зависимостей (Ballesteros et al., 2015). Позднее они стали основным компонентом моделей для категоризации членов последовательностей (Lample et al., 2016; Plank et al., 2016) и языкового моделирования (Kim et al., 2016). Символьные представления устраняют необходимость работы с фиксированным словарем c дополнительными вычислительными затратами и позволяют применять полностью символьный нейронный машинный перевод (Ling et al., 2016; Lee et al., 2017).
Состязательное обучение
Состязательные методы взяли штурмом область машинного обучения и также стали использоваться в различных формах обработки естественного языка. Состязательные примеры все шире используются не только в качестве инструмента для исследования моделей и выяснения причин неудач в обучении, но и для того, чтобы сделать модели более надежными и устойчивыми (Jia & Liang, 2017). (Смоделированное) состязательное обучение, то есть создание экстремальных отклонений от нормы (Miyato et al., 2017; Yasunaga et al., 2018) или доменно-состязательных потерь (Ganin et al., 2016; Kim et al., 2017) является успешной формой регуляризации, которая также повышает надежность и устойчивость модели. Генеративные состязательные сети еще не слишком эффективны для генерации естественного языка (Semeniuta et al., 2018), но полезны, например, при парном распределении (Conneau et al., 2018).
Обучение с подкреплением
Обучение с подкреплением оказалось полезным для решения задач с временной зависимостью друг от друга, таких как выбор данных во время обучения (Fang et al., 2017; Wu et al., 2018) и моделирование диалога (Liu et al., 2018). Обучение с подкреплением эффективно для прямой недифференцируемой оптимизации конечных метрик, таких как ROUGE или BLEU, вместо оптимизации суррогатной функции потерь, например, перекрестной энтропии при суммировании (Paulus et al, 2018; Celikyilmaz et al., 2018), а также для машинного перевода (Ranzato et al., 2016). Точно так же, обучение с отрицательным подкреплением может быть полезно в ситуациях, когда вознаграждение слишком сложно, чтобы его указывать, например, в визуальном повествовании (Wang et al., 2018).
Достижения не из области нейронауки
В 1998 году был представлен проект FrameNet (Baker et al., 1998), который привел к возникновению задачи присвоения семантических ролей, одной из форм поверхностного семантико-синтаксического анализа, которая до сих пор активно исследуется. В начале 2000-х годов общие задачи, организованные совместно с CoNLL (конференцией по машинному обучению обработке естественного языка), послужили катализатором для исследований основных задач из этой области, таких как чанкинг (частичный синтаксический разбор, метод, который заключается в разбиении текста на синтаксически связанные фрагменты текста — чанки) (Tjong Kim Sang et al., 2000), распознавание именованных сущностей (Tjong Kim Sang et al. , 2003), синтаксический анализ на основе грамматики зависимостей (Buchholz et al., 2006), и многих других. Многие из наборов данных общих задач CoNLL по-прежнему являются стандартом для оценки работы моделей.
В 2001 году были представлены условные случайные поля (CRF; Lafferty et al., 2001), один из наиболее влиятельных классов методов разметки последовательностей, который получил награду test-of-time (испытание временем) на международной конференции по машинному обучению (ICML) 2011. Слой условных случайных полей является основой современных передовых моделей, решающих проблемы разметки последовательностей взаимосвязанных объектов в таких задачах, как распознавание именованных сущностей (Lample et al., 2016).
В 2002 году была предложена BLEU, метрика двуязычного анализа (BLEU; Papineni et al., 2002), которая позволила увеличить производительность систем машинного перевода и до сих пор остается стандартной метрикой для оценки машинного перевода. В том же году был представлен структурный перцептрон (Collins, 2002), который заложил основу для работы в области структурированного восприятия. На той же конференции было представлено решение задачи анализа тональности текста, одной из самых популярных и широко изучаемых задач в области обработки естественного языка (Pang et al., 2002). Все три проекта были удостоены награды Test-of-time (испытание временем) на конференции NAACL 2018. Кроме того, в том же году был представлен лингвистический ресурс PropBank (Kingsbury & Palmer, 2002). PropBank похож на FrameNet, но фокусируется на глаголах. Этот ресурс часто используется при решения задачи присвоения семантических ролей.
В 2003 году был представлен метод латентного размещения Дирихле (LDA; Blei et al., 2003), ставший одним из наиболее широко используемых методов в машинном обучении, который до сих пор является стандартным способом тематического моделирования. В 2004 году были предложены новые модели классификации данных с максимальным зазором, которые лучше подходят для прослеживания взаимосвязей структурированных данных, чем метод опорных векторов (Taskar et al., 2004a; 2004b).
В 2006 году был представлен проект OntoNotes, большой многоязычный корпус с множественными аннотациями, прекрасно согласованными между собой (Hovy et al., 2006). OntoNotes использовался для обучения различных задач, таких как синтаксический анализ на основе грамматики зависимостей и разрешение кореференции, а также для их оценки. Милн и Виттен в 2008 году описали, как Википедия может быть использована для обогащения методов машинного обучения. На сегодняшний день Википедия является одним из наиболее полезных ресурсов для обучения моделей, будь то связывание сущностей и устранение неоднозначности, языковое моделирование, выступающее в качестве базы знаний, или множество других задач.
В 2009 году была предложена идея дистанционного наблюдения (Mintz et al., 2009). Дистанционное наблюдение использует информацию из уже существующих баз знаний или добытую эвристическими методами для создания моделей шума, которые можно использовать для автоматического извлечения примеров из больших корпусов. Дистанционное наблюдение стало широко использоваться и на данный момент является распространенным методом при решении задач извлечения отношений и информации, анализа тональности текста, и других.
В 2016 году был представлен проект Universal Dependencies (Nivre et al., 2016), представляющий из себя многоязычное собрание синтаксических деревьев. Это открытый проект, вокруг которого сложилось большое сообщество исследователей и разработчиков. Цель Universal Dependencies — создание согласованных аннотаций на основе грамматики зависимостей для многих языков. По состоянию на январь 2019 года Universal Dependencies включает в себя более 100 синтаксических деревьев на более чем 70 языках.
Оригинал: A Review of the Neural History of Natural Language Processing
Источники
- Antoniak, M., & Mimno, D. (2018). Evaluating the Stability of Embedding-based Word Similarities. Transactions of the Association for Computational Linguistics, 6, 107–119.
- Arora, S., Li, Y., Liang, Y., Ma, T., & Risteski, A. (2016). A Latent Variable Model Approach to PMI-based Word Embeddings. TACL, 4, 385–399.
- Artetxe, M., Labaka, G., & Agirre, E. (2018). A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings. In Proceedings of ACL 2018.
- Artetxe, M., Labaka, G., Agirre, E., & Cho, K. (2018). Unsupervised Neural Machine Translation. In Proceedings of ICLR 2018.
- Asgari, E., & Mofrad, M. R. (2015). Continuous distributed representation of biological sequences for deep proteomics and genomics. PloS one, 10(11), e0141287.
- Bahdanau, D., Cho, K., & Bengio, Y. (2015). Neural Machine Translation by Jointly Learning to Align and Translate. In ICLR 2015.
- Baker, C. F., Fillmore, C. J., & Lowe, J. B. (1998, August). The berkeley framenet project. In Proceedings of the 17th international conference on Computational linguistics-Volume 1 (pp. 86-90). Association for Computational Linguistics.
- Ballesteros, M., Dyer, C., & Smith, N. A. (2015). Improved Transition-Based Parsing by Modeling Characters instead of Words with LSTMs. In Proceedings of EMNLP 2015.
- Bastings, J., Titov, I., Aziz, W., Marcheggiani, D., & Sima’an, K. (2017). Graph Convolutional Encoders for Syntax-aware Neural Machine Translation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing.
- Bengio, Y., Ducharme, R., & Vincent, P. (2001). Proceedings of NIPS.
- Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of machine Learning research, 3(Jan), 993-1022.
- Blevins, T., Levy, O., & Zettlemoyer, L. (2018). Deep RNNs Encode Soft Hierarchical Syntax. In Proceedings of ACL 2018. Retrieved from http://arxiv.org/abs/1805.04218
- Bolukbasi, T., Chang, K.-W., Zou, J., Saligrama, V., & Kalai, A. (2016). Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. In 30th Conference on Neural Information Processing Systems (NIPS 2016).
- Bradbury, J., Merity, S., Xiong, C., & Socher, R. (2017). Quasi-Recurrent Neural Networks. In ICLR 2017. Retrieved from http://arxiv.org/abs/1611.01576
- Buchholz, S., & Marsi, E. (2006, June). CoNLL-X shared task on multilingual dependency parsing. In Proceedings of the tenth conference on computational natural language learning (pp. 149-164). Association for Computational Linguistics.
- Caruana, R. (1993). Multitask learning: A knowledge-based source of inductive bias. In Proceedings of the Tenth International Conference on Machine Learning.
- Caruana, R. (1998). Multitask Learning. Autonomous Agents and Multi-Agent Systems, 27(1), 95–133.
- Celikyilmaz, A., Bosselut, A., He, X., & Choi, Y. (2018). Deep communicating agents for abstractive summarization. In Proceedings of NAACL-HLT 2018.
- Chen, M. X., Foster, G., & Parmar, N. (2018). The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation. In Proceedings of ACL 2018.
- Collins, M. (2002, July). Discriminative training methods for hidden markov models: Theory and experiments with perceptron algorithms. In Proceedings of the ACL-02 conference on Empirical methods in natural language processing-Volume 10 (pp. 1-8). Association for Computational Linguistics.
- Collobert, R., & Weston, J. (2008). A unified architecture for natural language processing. In Proceedings of the 25th International Conference on Machine Learning (pp. 160–167).
- Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., & Kuksa, P. (2011). Natural Language Processing (almost) from Scratch. Journal of Machine Learning Research, 12(Aug), 2493–2537.
- Conneau, A., Kiela, D., Schwenk, H., Barrault, L., & Bordes, A. (2017). Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing.
- Conneau, A., Lample, G., Ranzato, M., Denoyer, L., & Jégou, H. (2018). Word Translation Without Parallel Data. In Proceedings of ICLR 2018.
- Conneau, A., Lample, G., Ranzato, M., Denoyer, L., & Jégou, H. (2018). Word Translation Without Parallel Data. In Proceedings of ICLR 2018.
- Dai, A. M., & Le, Q. V. (2015). Semi-supervised Sequence Learning. Advances in Neural Information Processing Systems (NIPS ’15).
- Daniluk, M., Rocktäschel, T., Weibl, J., & Riedel, S. (2017). Frustratingly Short Attention Spans in Neural Language Modeling. In Proceedings of ICLR 2017.
- Dyer, C., Kuncoro, A., Ballesteros, M., & Smith, N. A. (2016). Recurrent Neural Network Grammars. In NAACL. Retrieved from http://arxiv.org/abs/1602.07776
- Elman, J. L. (1990). Finding structure in time. Cognitive science, 14(2), 179-211.
- Fang, M., Li, Y., & Cohn, T. (2017). Learning how to Active Learn: A Deep Reinforcement Learning Approach. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing.
- Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., … Lempitsky, V. (2016). Domain-Adversarial Training of Neural Networks. Journal of Machine Learning Research, 17.
- Gehring, J., Auli, M., Grangier, D., Yarats, D., & Dauphin, Y. N. (2017). Convolutional Sequence to Sequence Learning. ArXiv Preprint ArXiv:1705.03122.
- Gillick, D., Brunk, C., Vinyals, O., & Subramanya, A. (2016). Multilingual Language Processing From Bytes. In NAACL (pp. 1296–1306).
- Graves, A. (2013). Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850.
- Graves, A., Jaitly, N., & Mohamed, A. R. (2013, December). Hybrid speech recognition with deep bidirectional LSTM. In Automatic Speech Recognition and Understanding (ASRU), 2013 IEEE Workshop on (pp. 273-278). IEEE.
- Graves, A., Wayne, G., & Danihelka, I. (2014). Neural turing machines. arXiv preprint arXiv:1410.5401.
- Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., Grabska-Barwińska, A., … Hassabis, D. (2016). Hybrid computing using a neural network with dynamic external memory. Nature.
- Grover, A., & Leskovec, J. (2016, August). node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 855-864). ACM.
- Henaff, M., Weston, J., Szlam, A., Bordes, A., & LeCun, Y. (2017). Tracking the World State with Recurrent Entity Networks. In Proceedings of ICLR 2017.
- Hermann, K. M., Kočiský, T., Grefenstette, E., Espeholt, L., Kay, W., Suleyman, M., & Blunsom, P. (2015). Teaching Machines to Read and Comprehend. Advances in Neural Information Processing Systems.
- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
- Hovy, E., Marcus, M., Palmer, M., Ramshaw, L., & Weischedel, R. (2006, June). OntoNotes: the 90% solution. In Proceedings of the human language technology conference of the NAACL, Companion Volume: Short Papers (pp. 57-60). Association for Computational Linguistics.
- Howard, J., & Ruder, S. (2018). Universal Language Model Fine-tuning for Text Classification. In Proceedings of ACL 2018.
- Jia, R., & Liang, P. (2017). Adversarial Examples for Evaluating Reading Comprehension Systems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing.
- Kalchbrenner, N., Espeholt, L., Simonyan, K., Oord, A. van den, Graves, A., & Kavukcuoglu, K. (2016). Neural Machine Translation in Linear Time. ArXiv Preprint
- Kalchbrenner, N., Espeholt, L., Simonyan, K., Oord, A. van den, Graves, A., & Kavukcuoglu, K. (2016). Neural Machine Translation in Linear Time. ArXiv Preprint
- Kalchbrenner, N., Grefenstette, E., & Blunsom, P. (2014). A Convolutional Neural Network for Modelling Sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (pp. 655–665).
- Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the Conference on Empirical Methods in Natural Language Processing, 1746–1751.
- Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the Conference on Empirical Methods in Natural Language Processing, 1746–1751.
- Kim, Y., Jernite, Y., Sontag, D., & Rush, A. M. (2016). Character-Aware Neural Language Models. In Proceedings of AAAI 2016
- Kim, Y., Stratos, K., & Kim, D. (2017). Adversarial Adaptation of Synthetic or Stale Data. In Proceedings of ACL (pp. 1297–1307).
- Kingsbury, P., & Palmer, M. (2002, May). From TreeBank to PropBank. In LREC (pp. 1989-1993).
- Kiros, R., Zhu, Y., Salakhutdinov, R., Zemel, R. S., Torralba, A., Urtasun, R., & Fidler, S. (2015). Skip-Thought Vectors. In Proceedings of NIPS 2015.
- Kneser, R., & Ney, H. (1995, May). Improved backing-off for m-gram language modeling. In icassp (Vol. 1, p. 181e4).
- Kumar, A., Irsoy, O., Ondruska, P., Iyyer, M., Bradbury, J., Gulrajani, I., … & Socher, R. (2016, June). Ask me anything: Dynamic memory networks for natural language processing. In International Conference on Machine Learning (pp. 1378-1387).
- Kuncoro, A., Dyer, C., Hale, J., Yogatama, D., Clark, S., & Blunsom, P. (2018). LSTMs Can Learn Syntax-Sensitive Dependencies Well, But Modeling Structure Makes Them Better. In Proceedings of ACL 2018 (pp. 1–11).
- Lafferty, J., McCallum, A., & Pereira, F. C. (2001). Conditional random fields: Probabilistic models for segmenting and labeling sequence data.
- Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K., & Dyer, C. (2016). Neural Architectures for Named Entity Recognition. In NAACL-HLT 2016.
- Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K., & Dyer, C. (2016). Neural Architectures for Named Entity Recognition. In NAACL-HLT 2016.
- Lample, G., Denoyer, L., & Ranzato, M. (2018). Unsupervised Machine Translation Using Monolingual Corpora Only. In Proceedings of ICLR 2018.
- Le, Q. V., & Mikolov, T. (2014). Distributed Representations of Sentences and Documents. International Conference on Machine Learning — ICML 2014, 32, 1188–1196.
- Lebret, R., Grangier, D., & Auli, M. (2016). Generating Text from Structured Data with Application to the Biography Domain. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing.
- Lee, J., Cho, K., & Bengio, Y. (2017). Fully Character-Level Neural Machine Translation without Explicit Segmentation. In Transactions of the Association for Computational Linguistics.
- Levy, O., & Goldberg, Y. (2014). Dependency-Based Word Embeddings. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Short Papers) (pp. 302–308).
- Levy, O., & Goldberg, Y. (2014). Neural Word Embedding as Implicit Matrix Factorization. Advances in Neural Information Processing Systems (NIPS), 2177–2185. Retrieved from http://papers.nips.cc/paper/5477-neural-word-embedding-as-implicit-matrix-factorization
- Levy, O., Goldberg, Y., & Dagan, I. (2015). Improving Distributional Similarity with Lessons Learned from Word Embeddings. Transactions of the Association for Computational Linguistics, 3, 211–225.
- Ling, W., Luis, T., Marujo, L., Astudillo, R. F., Amir, S., Dyer, C., … Trancoso, I. (2015). Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation. In Proceedings of EMNLP 2015 (pp. 1520–1530).
- Ling, W., Trancoso, I., Dyer, C., & Black, A. (2016). Character-based Neural Machine Translation. In ICLR.
- Liu, B., Tür, G., Hakkani-Tür, D., Shah, P., & Heck, L. (2018). Dialogue Learning with Human Teaching and Feedback in End-to-End Trainable Task-Oriented Dialogue Systems. In Proceedings of NAACL-HLT 2018.
- Loyola, P., Marrese-Taylor, E., & Matsuo, Y. (2017). A Neural Architecture for Generating Natural Language Descriptions from Source Code Changes. In ACL 2017.
- Luong, M.-T., Pham, H., & Manning, C. D. (2015). Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of EMNLP 2015. Retrieved from http://arxiv.org/abs/1508.04025
- McCann, B., Bradbury, J., Xiong, C., & Socher, R. (2017). Learned in Translation: Contextualized Word Vectors. In Advances in Neural Information Processing Systems.
- McCann, B., Keskar, N. S., Xiong, C., & Socher, R. (2018). The Natural Language Decathlon: Multitask Learning as Question Answering.
- Melis, G., Dyer, C., & Blunsom, P. (2018). On the State of the Art of Evaluation in Neural Language Models. In Proceedings of ICLR 2018.
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems.
- Mikolov, T., Corrado, G., Chen, K., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. Proceedings of the International Conference on Learning Representations (ICLR 2013).
- Mikolov, T., Karafiát, M., Burget, L., Černocký, J., & Khudanpur, S. (2010). Recurrent neural network based language model. In Eleventh Annual Conference of the International Speech Communication Association.
- Milne, D., & Witten, I. H. (2008, October). Learning to link with wikipedia. In Proceedings of the 17th ACM conference on Information and knowledge management (pp. 509-518). ACM.
- Mimno, D., & Thompson, L. (2017). The strange geometry of skip-gram with negative sampling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (pp. 2863–2868).
- Mintz, M., Bills, S., Snow, R., & Jurafsky, D. (2009, August). Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2-Volume 2 (pp. 1003-1011). Association for Computational Linguistics.
- Miyato, T., Dai, A. M., & Goodfellow, I. (2017). Adversarial Training Methods for Semi-supervised Text Classification. In Proceedings of ICLR 2017.
- Nivre, J., De Marneffe, M. C., Ginter, F., Goldberg, Y., Hajic, J., Manning, C. D., … & Tsarfaty, R. (2016, May). Universal Dependencies v1: A Multilingual Treebank Collection. In LREC.
- Pang, B., Lee, L., & Vaithyanathan, S. (2002, July). Thumbs up?: sentiment classification using machine learning techniques. In Proceedings of the ACL-02 conference on Empirical methods in natural language processing-Volume 10 (pp. 79-86). Association for Computational Linguistics.
- Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002, July). BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting on association for computational linguistics (pp. 311-318). Association for Computational Linguistics.
- Paulus, R., Xiong, C., & Socher, R. (2018). A deep reinforced model for abstractive summarization. In Proceedings of ICLR 2018.
- Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global Vectors for Word Representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 1532–1543.
- Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. In Proceedings of NAACL-HLT 2018.
- Plank, B., Søgaard, A., & Goldberg, Y. (2016). Multilingual Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Models and Auxiliary Loss. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics.
- Ramachandran, P., Liu, P. J., & Le, Q. V. (2017). Unsupervised Pretraining for Sequence to Sequence Learning. In Proceedings of EMNLP 2017.
- Ranzato, M. A., Chopra, S., Auli, M., & Zaremba, W. (2016). Sequence level training with recurrent neural networks. In Proceedings of ICLR 2016.
- Ruder, S., Bingel, J., Augenstein, I., & Søgaard, A. (2017). Learning what to share between loosely related tasks. ArXiv Preprint ArXiv:1705.08142. Retrieved from http://arxiv.org/abs/1705.08142
- Ruder, S., Vulić, I., & Søgaard, A. (2018). A Survey of Cross-lingual Word Embedding Models. To be published in Journal of Artificial Intelligence Research. Retrieved from http://arxiv.org/abs/1706.04902
- Semeniuta, S., Severyn, A., & Gelly, S. (2018). On Accurate Evaluation of GANs for Language Generation. Retrieved from http://arxiv.org/abs/1806.04936
- Socher, R., Perelygin, A., & Wu, J. (2013). Recursive deep models for semantic compositionality over a sentiment treebank. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 1631–1642.
- Søgaard, A., Ruder, S., & Vulić, I. (2018). On the Limitations of Unsupervised Bilingual Dictionary Induction. In Proceedings of ACL 2018.
- Subramanian, S., Trischler, A., Bengio, Y., & Pal, C. J. (2018). Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning. In Proceedings of ICLR 2018.
- Sukhbaatar, S., Szlam, A., Weston, J., & Fergus, R. (2015). End-To-End Memory Networks. In Proceedings of NIPS 2015. Retrieved from http://arxiv.org/abs/1503.08895
- Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems.
- Tai, K. S., Socher, R., & Manning, C. D. (2015). Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks. Acl-2015, 1556–1566.
- Taskar, B., Guestrin, C., & Koller, D. (2004). Max-margin Markov networks. In Advances in neural information processing systems (pp. 25-32).
- Taskar, B., Klein, D., Collins, M., Koller, D., & Manning, C. (2004). Max-margin parsing. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing.
- Tjong Kim Sang, E. F., & Buchholz, S. (2000, September). Introduction to the CoNLL-2000 shared task: Chunking. In Proceedings of the 2nd workshop on Learning language in logic and the 4th conference on Computational natural language learning-Volume 7 (pp. 127-132). Association for Computational Linguistics.
- Tjong Kim Sang, E. F., & De Meulder, F. (2003, May). Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. In Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003-Volume 4 (pp. 142-147). Association for Computational Linguistics.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention Is All You Need. In Advances in Neural Information Processing Systems.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention Is All You Need. In Advances in Neural Information Processing Systems.
- Vinyals, O., Blundell, C., Lillicrap, T., Kavukcuoglu, K., & Wierstra, D. (2016). Matching Networks for One Shot Learning. In Advances in Neural Information Processing Systems 29 (NIPS 2016). Retrieved from http://arxiv.org/abs/1606.04080
- Vinyals, O., Kaiser, L., Koo, T., Petrov, S., Sutskever, I., & Hinton, G. (2015). Grammar as a Foreign Language. Advances in Neural Information Processing Systems.
- Vinyals, O., Kaiser, L., Koo, T., Petrov, S., Sutskever, I., & Hinton, G. (2015). Grammar as a Foreign Language. Advances in Neural Information Processing Systems.
- Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. (2015). Show and tell: A neural image caption generator. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3156-3164).
- Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2018). GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding.
- Wang, J., Yu, L., Lai, K. R., & Zhang, X. (2016). Dimensional Sentiment Analysis Using a Regional CNN-LSTM Model. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016), 225–230.
- Wang, X., Chen, W., Wang, Y.-F., & Wang, W. Y. (2018). No Metrics Are Perfect: Adversarial Reward Learning for Visual Storytelling. In Proceedings of ACL 2018. Retrieved from http://arxiv.org/abs/1804.09160
- Wendlandt, L., Kummerfeld, J. K., & Mihalcea, R. (2018). Factors Influencing the Surprising Instability of Word Embeddings. In Proceedings of NAACL-HLT 2018.
- Weston, J., Chopra, S., & Bordes, A. (2015). Memory Networks. In Proceedings of ICLR 2015.
- Wu, J., Li, L., & Wang, W. Y. (2018). Reinforced Co-Training. In Proceedings of NAACL-HLT 2018.
- Wu, Y., Schuster, M., Chen, Z., Le, Q. V, Norouzi, M., Macherey, W., … Dean, J. (2016). Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. ArXiv Preprint ArXiv:1609.08144.
- Wu, Y., Schuster, M., Chen, Z., Le, Q. V, Norouzi, M., Macherey, W., … Dean, J. (2016). Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. ArXiv Preprint ArXiv:1609.08144.
- Xu, K., Courville, A., Zemel, R. S., & Bengio, Y. (2015). Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of ICML 2015.
- Yasunaga, M., Kasai, J., & Radev, D. (2018). Robust Multilingual Part-of-Speech Tagging via Adversarial Training. In Proceedings of NAACL 2018.



