Нейросети, обученные под одну задачу, можно научить решать другие, похожие. Отсюда и название метода трансферного обучения — мы будто «переносим» (от англ. transfer — передача) предыдущий опыт решения проблемы на новую, еще не решенную. Например, зная английский, вам будет легче выучить немецкий, поскольку оба этих языка — западно-германские, а значит, в них присутствуют схожие структуры и закономерности. Так же и нейросеть, обученная решению одной конкретной задачи, может использовать приобретённые знания при решении новой задачи.
Представим, что мы компьютерные лингвисты и хотим обучить языковую модель, генерирующую тексты в стиле Достоевского. Чтобы получить качественную модель, нам бы понадобилось собрать большой корпус текстов Достоевского, для примера — при обучении модели GPT потребовались миллионы текстов. Как можно понять, подготовка подобного корпуса ресурсозатратна и сложна — и даже если бы нам удалось собрать все тексты русского писателя, далеко не факт, что этого объёма было бы достаточно.
Однако зачем обучать модель с «чистого листа», если существует модель, которая уже обучена генерации текстов на русском языке? Так как модель уже «говорит» на русском, обучить её стилю Достоевского намного проще, чем обучать модель, которая даже «не знает» языка. Другими словами достаточно взять готовую русскоязычную версию GPT3, найти в интернете оцифрованные версии произведений Федора Михайловича (например, здесь) и дообучить модель на новых текстах. Эта процедура дообучения и является примером Transfer Learning (трансферного обучения). Теперь подробней рассмотрим, как происходит этот «трансфер» знаний.
Как работает Transfer Learning?
Прежде чем погрузиться в трансферное обучение, нужно вспомнить, что такое нейросеть. Как мы писали ранее, под нейросетью понимается одна из моделей машинного обучения, способная объяснять сложные зависимости в данных. Зависимости — это связи между входными данными и выходными: между изображением и его категорией, между аудиодорожкой и её транскрипцией, между корпусом текстов и векторными представлениями слов.
Нейросеть представляет собой последовательность слоев, где каждый слой — математическое преобразование входных данных. Такую последовательность принято называть архитектурой. Как здания различаются по количеству этажей, их типу — например, есть ли коммерческие этажи или все жилые, так и разным архитектурам присущ свой объем слоев, свои типы и их упорядоченность.

Итак, представим, что мы в бизнес целях хотим научить модель определять по фотографии больна ли клубника. Собрать огромный набор данных по такой узкой задаче было бы дорого и достаточно проблематично, ведь нужны были бы гигабайты специфических картинок с этой ягодой. Вместо этого можно взять уже предобученную на фотографиях ягод модель компьютерного зрения и «настроить» ее на относительно небольшом наборе данных под нашу проблему. То есть нам надо перенести уже полученные, обобщенные знания о ягодах на классификацию клубники.
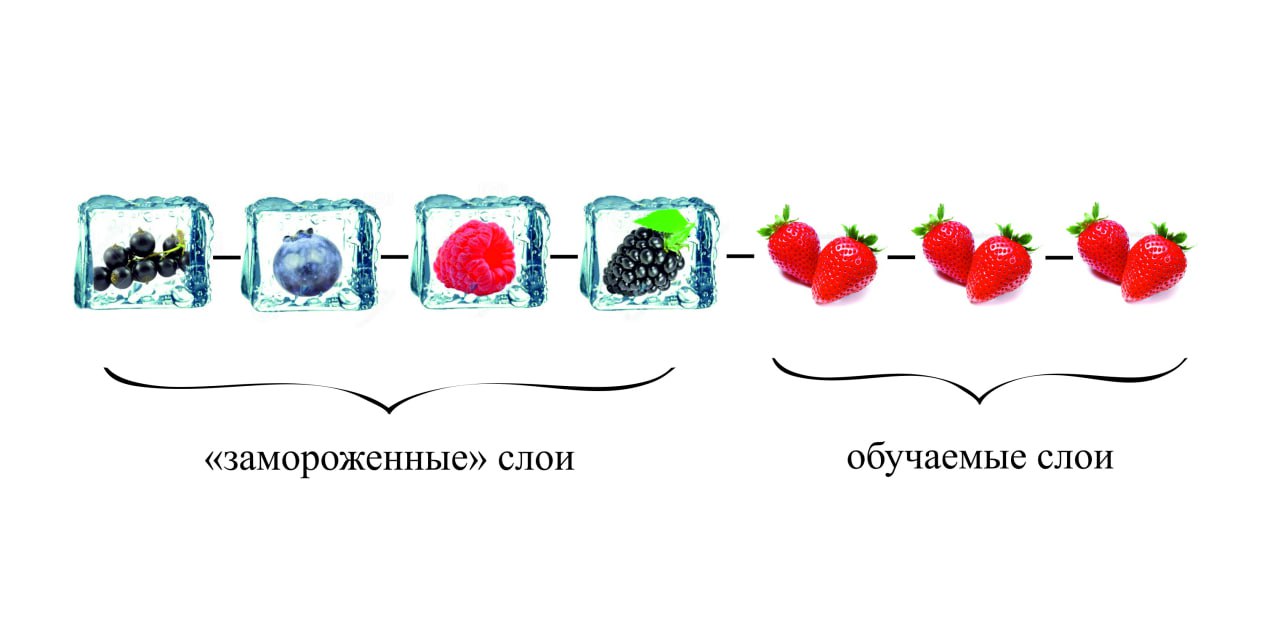
В машинном обучении мы можем выбирать, какие слои нейросети нам обучать, а какие нет. Если мы не хотим обновлять, то есть обучать, какие-то слои, в терминологии глубинного обучения — мы их «замораживаем». В случае с предобученной моделью, мы должны «заморозить» нижние слои, в то время как верхние будут обновляться. Если вспомнить метафору о языках из первого абзаца, можно сказать, что при изучении немецкого вы не учите заново всю структуру языка — в вашей голове уже есть «скелет» языка, вы знаете о корнях слов, окончаниях, падежах. Все, что остается запомнить — это особенности, характерные для конкретного языка. Так и здесь архитектура нейросети напоминает этот процесс: на нижних слоях модели хранятся базовые, общие знания, а на верхних — специфические закономерности.
Наша «ягодная» модель уже знает очертания, характерные не только для клубники, но и в целом для любых ягод: это и есть нижние слои нейросети. Они не будут обучаться на нашем маленьком наборе фотографий — эти слои остаются такими же, как и в предобученной модели. Обучение происходит только на верхних слоях, которые и выучат образ, силуэт, характерный для клубники, а также признаки, характерные для больной клубники.
Реальные применения Transfer Learning
Еще в 2016 году известный исследователь машинного обучения Эндрю Ын предсказывал, что трансферное обучение станет новым двигателем коммерческого успеха сферы искусственного интеллекта. Действительно, компаниям очень выгодно использовать этот подход, поскольку он экономит и время, и деньги.
Как пример интеграции трансферного обучения в бизнес процессы, можно привести анализ тональности для оценки удовлетворенности покупателями товаром: вместо создания нейросети с нуля берется готовая классификационная языковая модель, которая может определять тональность текста, и «дообучается» на выборке отзывов компании. Трансферное обучение скрыто и в нашей повседневной жизни: смартфон, который использует детекцию лица вместо пароля дообучается на лице конкретного пользователя; модераторы сайтов используют нейросети для блокировки неприемлемых постов или видео, как это, например, делает YouTube — их модель постоянно дообучается на новых наборах токсичных данных, чтобы лучше распознавать негативный контент.
Одна модель, чтобы править всеми решать всё: почему Transfer Learning важен не только для бизнеса?
Одна из главных задач сферы глубинного обучения на данный момент — максимальная оптимизация процесса переноса знаний. Исследователи движутся не только в сторону уменьшения требуемого объема наборов данных, нужных для дообучения под новые задачи, но и в сторону создания такой модели, которая будет способна выполнять их вообще без дообучения. Так, если бы наша «ягодная» модель обладала подобными способностями (такие модели называют «zero-shot» моделями), то она бы сразу умела распознавать больную клубнику.
В эпоху заботы об экологии даже в IT-сфере есть своего рода переработка, только вместо пластика мы повторно используем полученные знания, делая процесс изучения новых задач более быстрым и эффекивным. Ученые, как и экологи, пытаются извлечь из старого продукта максимальную пользу в новом контексте, а также создать такую систему, которая вообще не будет требовать никаких дополнительных материалов, то есть, «zero-shot» нейросеть.
Реальный пример мощной zero-shot модели — недавно запущенная ChatGPT от OpenAI. Она может ответить на любой вопрос, сгенерировать текст любой эмоциональной тональности и даже написать рабочий код на Python, хотя не обучалась решать конкретно эти задачи.



